
















 Lar
LarA geração de vídeo da IA se move para o controle completo
Modelos de fundação de vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas muitas vezes ficam aquém quando se trata do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Em estúdios profissionais de VFX, esses modelos, junto com modelos anteriores baseados em imagens como Stable Diffusion, Kandinsky e Flux, são usados em conjunto com um conjunto de ferramentas projetadas para refinar sua saída para atender a demandas criativas específicas. Quando um diretor solicita um ajuste, dizendo algo como, "Isso parece ótimo, mas podemos torná-lo um pouco mais [n]?", não é suficiente simplesmente afirmar que o modelo carece da precisão para fazer tais ajustes.
Em vez disso, uma equipe de VFX com IA empregará uma combinação de CGI tradicional e técnicas de composição, juntamente com fluxos de trabalho desenvolvidos sob medida, para expandir os limites da síntese de vídeo. Essa abordagem é semelhante ao uso de um navegador web padrão como o Chrome; ele é funcional imediatamente, mas para realmente adaptá-lo às suas necessidades, você precisará instalar alguns plugins.
Control Freaks
No campo da síntese de imagens baseada em difusão, um dos sistemas de terceiros mais cruciais é o ControlNet. Essa técnica introduz controle estruturado aos modelos generativos, permitindo que os usuários guiem a geração de imagens ou vídeos usando entradas adicionais, como mapas de borda, mapas de profundidade ou informações de pose.
 *Os vários métodos do ControlNet permitem geração de profundidade>imagem (linha superior), segmentação semântica>imagem (inferior à esquerda) e geração de imagens guiada por pose de humanos e animais (inferior à esquerda).*
*Os vários métodos do ControlNet permitem geração de profundidade>imagem (linha superior), segmentação semântica>imagem (inferior à esquerda) e geração de imagens guiada por pose de humanos e animais (inferior à esquerda).*
O ControlNet não depende apenas de prompts de texto; ele emprega ramos de redes neurais separados, ou adaptadores, para processar esses sinais de condicionamento enquanto mantém as capacidades generativas do modelo base. Isso permite saídas altamente personalizadas que se alinham estreitamente com as especificações do usuário, tornando-o inestimável para aplicações que exigem controle preciso sobre composição, estrutura ou movimento.
 *Com uma pose de guia, uma variedade de tipos de saída precisos pode ser obtida via ControlNet.* Fonte: https://arxiv.org/pdf/2302.05543
*Com uma pose de guia, uma variedade de tipos de saída precisos pode ser obtida via ControlNet.* Fonte: https://arxiv.org/pdf/2302.05543
No entanto, esses sistemas baseados em adaptadores, que operam externamente em um conjunto de processos neurais focados internamente, apresentam várias desvantagens. Os adaptadores são treinados independentemente, o que pode levar a conflitos de ramos quando vários adaptadores são combinados, frequentemente resultando em gerações de menor qualidade. Eles também introduzem redundância de parâmetros, exigindo recursos computacionais e memória adicionais para cada adaptador, tornando a escalabilidade ineficiente. Além disso, apesar de sua flexibilidade, os adaptadores muitas vezes produzem resultados subótimos em comparação com modelos totalmente ajustados para geração multi-condicional. Esses problemas podem tornar os métodos baseados em adaptadores menos eficazes para tarefas que exigem a integração perfeita de múltiplos sinais de controle.
Idealmente, as capacidades do ControlNet seriam integradas nativamente ao modelo de forma modular, permitindo inovações futuras como geração simultânea de vídeo/áudio ou capacidades nativas de sincronização labial. Atualmente, cada recurso adicional torna-se uma tarefa de pós-produção ou um procedimento não nativo que deve navegar pelos pesos sensíveis do modelo de fundação.
FullDiT
Apresentamos o FullDiT, uma nova abordagem da China que integra recursos no estilo do ControlNet diretamente em um modelo generativo de vídeo durante o treinamento, em vez de tratá-los como uma reflexão tardia.
 *Do novo artigo: a abordagem FullDiT pode incorporar imposição de identidade, profundidade e movimento de câmera em uma geração nativa, e pode evocar qualquer combinação desses de uma só vez.* Fonte: https://arxiv.org/pdf/2503.19907
*Do novo artigo: a abordagem FullDiT pode incorporar imposição de identidade, profundidade e movimento de câmera em uma geração nativa, e pode evocar qualquer combinação desses de uma só vez.* Fonte: https://arxiv.org/pdf/2503.19907
O FullDiT, conforme descrito no artigo intitulado **FullDiT: Modelo de Fundação Generativa de Vídeo Multitarefa com Atenção Completa**, integra condições multitarefas, como transferência de identidade, mapeamento de profundidade e movimento de câmera, no núcleo de um modelo generativo de vídeo treinado. Os autores desenvolveram um modelo protótipo e clipes de vídeo acompanhantes disponíveis em um site do projeto.
**Clique para reproduzir. Exemplos de imposição de usuário no estilo ControlNet com apenas um modelo de fundação treinado nativamente.** Fonte: https://fulldit.github.io/
Os autores apresentam o FullDiT como uma prova de conceito para modelos nativos de texto para vídeo (T2V) e imagem para vídeo (I2V) que oferecem aos usuários mais controle do que apenas uma imagem ou prompt de texto. Como não existem modelos semelhantes, os pesquisadores criaram um novo benchmark chamado **FullBench** para avaliar vídeos multitarefas, reivindicando desempenho de ponta em seus testes concebidos. No entanto, a objetividade do FullBench, projetado pelos próprios autores, permanece não testada, e seu conjunto de dados de 1.400 casos pode ser muito limitado para conclusões mais amplas.
O aspecto mais intrigante da arquitetura do FullDiT é seu potencial para incorporar novos tipos de controle. Os autores observam:
**‘Neste trabalho, exploramos apenas condições de controle da câmera, identidades e informações de profundidade. Não investigamos mais a fundo outras condições e modalidades, como áudio, fala, nuvem de pontos, caixas delimitadoras de objetos, fluxo óptico, etc. Embora o design do FullDiT possa integrar outras modalidades com modificação mínima na arquitetura, como adaptar rapidamente e de forma econômica modelos existentes a novas condições e modalidades ainda é uma questão importante que merece exploração adicional.’**
Embora o FullDiT represente um passo adiante na geração de vídeos multitarefas, ele se baseia em arquiteturas existentes, em vez de introduzir um novo paradigma. No entanto, destaca-se como o único modelo de fundação de vídeo com recursos no estilo ControlNet integrados nativamente, e sua arquitetura é projetada para acomodar inovações futuras.
**Clique para reproduzir. Exemplos de movimentos de câmera controlados pelo usuário, do site do projeto.**
O artigo, de autoria de nove pesquisadores da Kuaishou Technology e da The Chinese University of Hong Kong, é intitulado **FullDiT: Modelo de Fundação Generativa de Vídeo Multitarefa com Atenção Completa**. A página do projeto e os dados do novo benchmark estão disponíveis no Hugging Face.
Método
O mecanismo de atenção unificada do FullDiT é projetado para aprimorar o aprendizado de representação cross-modal, capturando relações espaciais e temporais entre as condições.
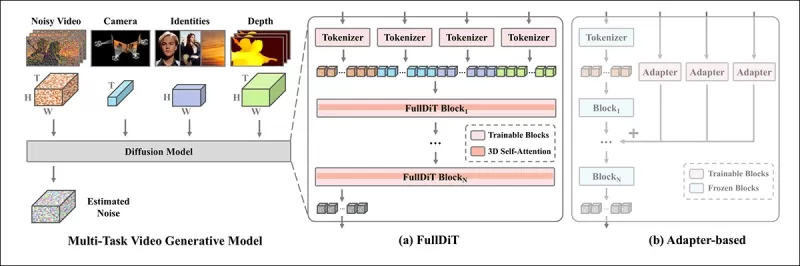 *De acordo com o novo artigo, o FullDiT integra múltiplas condições de entrada por meio de atenção completa, convertendo-as em uma sequência unificada. Em contraste, modelos baseados em adaptadores (mais à esquerda acima) usam módulos separados para cada entrada, levando a redundância, conflitos e desempenho mais fraco.*
*De acordo com o novo artigo, o FullDiT integra múltiplas condições de entrada por meio de atenção completa, convertendo-as em uma sequência unificada. Em contraste, modelos baseados em adaptadores (mais à esquerda acima) usam módulos separados para cada entrada, levando a redundância, conflitos e desempenho mais fraco.*
Diferentemente das configurações baseadas em adaptadores que processam cada fluxo de entrada separadamente, a estrutura de atenção compartilhada do FullDiT evita conflitos de ramos e reduz a sobrecarga de parâmetros. Os autores afirmam que a arquitetura pode escalar para novos tipos de entrada sem grandes reformulações e que o esquema do modelo mostra sinais de generalização para combinações de condições não vistas durante o treinamento, como vincular movimento de câmera com identidade de personagem.
**Clique para reproduzir. Exemplos de geração de identidade do site do projeto.**
Na arquitetura do FullDiT, todas as entradas de condicionamento — como texto, movimento de câmera, identidade e profundidade — são primeiro convertidas em um formato de token unificado. Esses tokens são então concatenados em uma única sequência longa, processada por uma pilha de camadas de transformadores usando atenção completa. Essa abordagem segue trabalhos anteriores como Open-Sora Plan e Movie Gen.
Esse design permite que o modelo aprenda relações temporais e espaciais conjuntamente em todas as condições. Cada bloco de transformador opera sobre a sequência inteira, possibilitando interações dinâmicas entre modalidades sem depender de módulos separados para cada entrada. A arquitetura é projetada para ser extensível, facilitando a incorporação de sinais de controle adicionais no futuro sem grandes mudanças estruturais.
O Poder dos Três
O FullDiT converte cada sinal de controle em um formato de token padronizado para que todas as condições possam ser processadas juntas em um framework de atenção unificado. Para o movimento de câmera, o modelo codifica uma sequência de parâmetros extrínsecos — como posição e orientação — para cada quadro. Esses parâmetros são marcados com carimbos de tempo e projetados em vetores de incorporação que refletem a natureza temporal do sinal.
As informações de identidade são tratadas de maneira diferente, pois são inerentemente espaciais, e não temporais. O modelo usa mapas de identidade que indicam quais personagens estão presentes em quais partes de cada quadro. Esses mapas são divididos em patches, com cada patch projetado em uma incorporação que captura pistas espaciais de identidade, permitindo que o modelo associe regiões específicas do quadro a entidades específicas.
A profundidade é um sinal espaço-temporal, e o modelo a trata dividindo vídeos de profundidade em patches 3D que abrangem espaço e tempo. Esses patches são então incorporados de maneira a preservar sua estrutura entre os quadros.
Uma vez incorporados, todos esses tokens de condição (câmera, identidade e profundidade) são concatenados em uma única sequência longa, permitindo que o FullDiT os processe juntos usando atenção completa. Essa representação compartilhada permite que o modelo aprenda interações entre modalidades e ao longo do tempo sem depender de fluxos de processamento isolados.
Dados e Testes
A abordagem de treinamento do FullDiT baseou-se em conjuntos de dados anotados seletivamente, adaptados a cada tipo de condicionamento, em vez de exigir que todas as condições estivessem presentes simultaneamente.
Para condições textuais, a iniciativa segue a abordagem de legendagem estruturada descrita no projeto MiraData.
 *Pipeline de coleta e anotação de vídeos do projeto MiraData.* Fonte: https://arxiv.org/pdf/2407.06358
*Pipeline de coleta e anotação de vídeos do projeto MiraData.* Fonte: https://arxiv.org/pdf/2407.06358
Para movimento de câmera, o conjunto de dados RealEstate10K foi a principal fonte de dados, devido às suas anotações de alta qualidade de parâmetros de câmera. No entanto, os autores observaram que treinar exclusivamente em conjuntos de dados de câmera de cena estática como o RealEstate10K tendia a reduzir movimentos de objetos dinâmicos e humanos nos vídeos gerados. Para contrabalançar isso, eles realizaram ajustes adicionais usando conjuntos de dados internos que incluíam movimentos de câmera mais dinâmicos.
As anotações de identidade foram geradas usando o pipeline desenvolvido para o projeto ConceptMaster, que permitiu filtragem e extração eficientes de informações de identidade detalhadas.
 *O framework ConceptMaster é projetado para abordar questões de desacoplamento de identidade enquanto preserva a fidelidade do conceito em vídeos personalizados.* Fonte: https://arxiv.org/pdf/2501.04698
*O framework ConceptMaster é projetado para abordar questões de desacoplamento de identidade enquanto preserva a fidelidade do conceito em vídeos personalizados.* Fonte: https://arxiv.org/pdf/2501.04698
As anotações de profundidade foram obtidas do conjunto de dados Panda-70M usando Depth Anything.
Otimização por Ordenação de Dados
Os autores também implementaram um cronograma de treinamento progressivo, introduzindo condições mais desafiadoras no início do treinamento para garantir que o modelo adquirisse representações robustas antes que tarefas mais simples fossem adicionadas. A ordem de treinamento passou de texto para condições de câmera, depois identidades e, finalmente, profundidade, com tarefas mais fáceis geralmente introduzidas mais tarde e com menos exemplos.
Os autores enfatizam o valor de ordenar a carga de trabalho dessa maneira:
**‘Durante a fase de pré-treinamento, notamos que tarefas mais desafiadoras exigem tempo de treinamento prolongado e devem ser introduzidas mais cedo no processo de aprendizado. Essas tarefas desafiadoras envolvem distribuições de dados complexas que diferem significativamente do vídeo de saída, exigindo que o modelo possua capacidade suficiente para capturar e representar com precisão.**
**‘Por outro lado, introduzir tarefas mais fáceis muito cedo pode levar o modelo a priorizar seu aprendizado primeiro, já que elas fornecem feedback de otimização mais imediato, o que prejudica a convergência de tarefas mais desafiadoras.’**
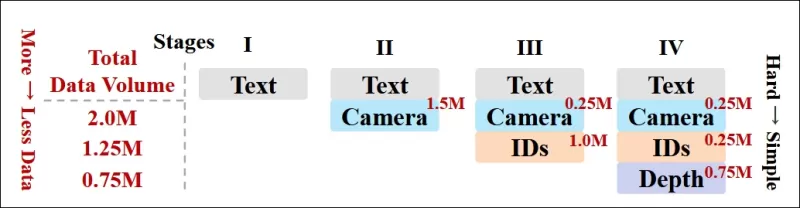 *Uma ilustração da ordem de treinamento de dados adotada pelos pesquisadores, com vermelho indicando maior volume de dados.*
*Uma ilustração da ordem de treinamento de dados adotada pelos pesquisadores, com vermelho indicando maior volume de dados.*
Após o pré-treinamento inicial, uma etapa final de ajuste fino refinou ainda mais o modelo para melhorar a qualidade visual e a dinâmica de movimento. A partir daí, o treinamento seguiu o de um framework de difusão padrão: ruído adicionado a latentes de vídeo, e o modelo aprendendo a prever e remover, usando os tokens de condição incorporados como guia.
Para avaliar o FullDiT de forma eficaz e fornecer uma comparação justa com métodos existentes, e na ausência de qualquer outro benchmark apropriado, os autores introduziram o **FullBench**, um conjunto de benchmark curado composto por 1.400 casos de teste distintos.
 *Uma instância de explorador de dados para o novo benchmark FullBench.* Fonte: https://huggingface.co/datasets/KwaiVGI/FullBench
*Uma instância de explorador de dados para o novo benchmark FullBench.* Fonte: https://huggingface.co/datasets/KwaiVGI/FullBench
Cada ponto de dados fornecia anotações de verdade absoluta para vários sinais de condicionamento, incluindo movimento de câmera, identidade e profundidade.
Métricas
Os autores avaliaram o FullDiT usando dez métricas cobrindo cinco aspectos principais de desempenho: alinhamento de texto, controle de câmera, similaridade de identidade, precisão de profundidade e qualidade geral do vídeo.
O alinhamento de texto foi medido usando similaridade CLIP, enquanto o controle de câmera foi avaliado por meio de erro de rotação (RotErr), erro de translação (TransErr) e consistência de movimento de câmera (CamMC), seguindo a abordagem do CamI2V (no projeto CameraCtrl).
A similaridade de identidade foi avaliada usando DINO-I e CLIP-I, e a precisão de controle de profundidade foi quantificada usando Erro Absoluto Médio (MAE).
A qualidade do vídeo foi julgada com três métricas do MiraData: similaridade CLIP em nível de quadro para suavidade; distância de movimento baseada em fluxo óptico para dinâmica; e pontuações LAION-Aesthetic para apelo visual.
Treinamento
Os autores treinaram o FullDiT usando um modelo interno (não divulgado) de difusão de texto para vídeo contendo aproximadamente um bilhão de parâmetros. Eles escolheram intencionalmente um tamanho de parâmetro modesto para manter a equidade nas comparações com métodos anteriores e garantir reprodutibilidade.
Como os vídeos de treinamento variavam em duração e resolução, os autores padronizaram cada lote redimensionando e preenchendo os vídeos para uma resolução comum, amostrando 77 quadros por sequência e usando máscaras de atenção e perda aplicadas para otimizar a eficácia do treinamento.
O otimizador Adam foi usado com uma taxa de aprendizado de 1×10−5 em um cluster de 64 GPUs NVIDIA H800, para um total combinado de 5.120 GB de VRAM (considere que nas comunidades de síntese entusiastas, 24 GB em uma RTX 3090 ainda é considerado um padrão luxuoso).
O modelo foi treinado por cerca de 32.000 passos, incorporando até três identidades por vídeo, junto com 20 quadros de condições de câmera e 21 quadros de condições de profundidade, ambos amostrados uniformemente do total de 77 quadros.
Para inferência, o modelo gerou vídeos com uma resolução de 384×672 pixels (aproximadamente cinco segundos a 15 quadros por segundo) com 50 passos de inferência de difusão e uma escala de orientação sem classificador de cinco.
Métodos Anteriores
Para avaliação de câmera para vídeo, os autores compararam o FullDiT contra MotionCtrl, CameraCtrl e CamI2V, com todos os modelos treinados usando o conjunto de dados RealEstate10k para garantir consistência e equidade.
Na geração condicionada por identidade, como não havia modelos de código aberto comparáveis com múltiplas identidades disponíveis, o modelo foi comparado ao modelo ConceptMaster de 1 bilhão de parâmetros, usando os mesmos dados de treinamento e arquitetura.
Para tarefas de profundidade para vídeo, comparações foram feitas com Ctrl-Adapter e ControlVideo.
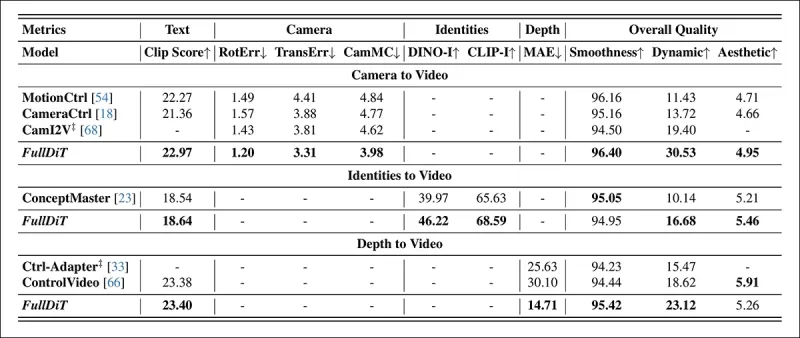 *Resultados quantitativos para geração de vídeo de tarefa única. O FullDiT foi comparado ao MotionCtrl, CameraCtrl e CamI2V para geração de câmera para vídeo; ConceptMaster (versão de 1 bilhão de parâmetros) para identidade para vídeo; e Ctrl-Adapter e ControlVideo para profundidade para vídeo. Todos os modelos foram avaliados usando suas configurações padrão. Para consistência, 16 quadros foram amostrados uniformemente de cada método, correspondendo à duração de saída dos modelos anteriores.*
*Resultados quantitativos para geração de vídeo de tarefa única. O FullDiT foi comparado ao MotionCtrl, CameraCtrl e CamI2V para geração de câmera para vídeo; ConceptMaster (versão de 1 bilhão de parâmetros) para identidade para vídeo; e Ctrl-Adapter e ControlVideo para profundidade para vídeo. Todos os modelos foram avaliados usando suas configurações padrão. Para consistência, 16 quadros foram amostrados uniformemente de cada método, correspondendo à duração de saída dos modelos anteriores.*
Os resultados indicam que o FullDiT, apesar de lidar com múltiplos sinais de condicionamento simultaneamente, alcançou desempenho de ponta em métricas relacionadas a texto, movimento de câmera, identidade e controles de profundidade.
Nas métricas de qualidade geral, o sistema geralmente superou outros métodos, embora sua suavidade tenha sido ligeiramente inferior à do ConceptMaster. Aqui, os autores comentam:
**‘A suavidade do FullDiT é ligeiramente inferior à do ConceptMaster, já que o cálculo da suavidade é baseado na similaridade CLIP entre quadros adjacentes. Como o FullDiT exibe dinâmica significativamente maior em comparação com o ConceptMaster, a métrica de suavidade é impactada pelas grandes variações entre quadros adjacentes.**
**‘Para a pontuação estética, como o modelo de classificação favorece imagens no estilo de pintura e o ControlVideo normalmente gera vídeos nesse estilo, ele alcança uma alta pontuação em estética.’**
Em relação à comparação qualitativa, pode ser preferível consultar os vídeos de amostra no site do projeto FullDiT, já que os exemplos em PDF são inevitavelmente estáticos (e também grandes demais para serem reproduzidos inteiramente aqui).
 *A primeira seção dos resultados qualitativos reproduzidos no PDF. Consulte o artigo fonte para os exemplos adicionais, que são muito extensos para serem reproduzidos aqui.*
*A primeira seção dos resultados qualitativos reproduzidos no PDF. Consulte o artigo fonte para os exemplos adicionais, que são muito extensos para serem reproduzidos aqui.*
Os autores comentam:
**‘O FullDiT demonstra preservação de identidade superior e gera vídeos com melhor dinâmica e qualidade visual em comparação com [ConceptMaster]. Como o ConceptMaster e o FullDiT são treinados na mesma estrutura, isso destaca a eficácia da injeção de condições com atenção completa.**
**‘…Os [outros] resultados demonstram a controlabilidade e qualidade de geração superiores do FullDiT em comparação com os métodos existentes de profundidade para vídeo e câmera para vídeo.’**
 *Uma seção dos exemplos do PDF da saída do FullDiT com múltiplos sinais. Consulte o artigo fonte e o site do projeto para exemplos adicionais.*
*Uma seção dos exemplos do PDF da saída do FullDiT com múltiplos sinais. Consulte o artigo fonte e o site do projeto para exemplos adicionais.*
Conclusão
O FullDiT representa um passo empolgante em direção a um modelo de fundação de vídeo mais abrangente, mas a questão permanece se a demanda por recursos no estilo ControlNet justifica sua implementação em escala, especialmente para projetos de código aberto. Esses projetos teriam dificuldade para obter o vasto poder de processamento de GPU necessário sem suporte comercial.
O principal desafio é que o uso de sistemas como Depth e Pose geralmente exige uma familiaridade não trivial com interfaces de usuário complexas como o ComfyUI. Portanto, um modelo funcional de código aberto desse tipo é mais provável de ser desenvolvido por pequenas empresas de VFX que carecem de recursos ou motivação para curar e treinar tal modelo privadamente.
Por outro lado, sistemas de ‘aluguel de IA’ orientados por API podem estar bem motivados para desenvolver métodos interpretativos mais simples e amigáveis ao usuário para modelos com sistemas de controle auxiliares treinados diretamente.
**Clique para reproduzir. Controles de Profundidade+Texto impostos em uma geração de vídeo usando FullDiT.**
*Os autores não especificam nenhum modelo base conhecido (ou seja, SDXL, etc.)*
**Publicado pela primeira vez na quinta-feira, 27 de março de 2025**
Artigo relacionado
 YouTube testa recurso de pesquisa baseado em IA com respostas guiadas
Muitos usuários recorrem ao YouTube quando procuram receitas ou planos de viagem, em busca de vídeos relevantes. Agora, a plataforma está lançando uma ferramenta de pesquisa interativa baseada em IA q
Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
Recomendações de tópicos especiais relacionados
Negócios
YouTube testa recurso de pesquisa baseado em IA com respostas guiadas
Muitos usuários recorrem ao YouTube quando procuram receitas ou planos de viagem, em busca de vídeos relevantes. Agora, a plataforma está lançando uma ferramenta de pesquisa interativa baseada em IA q
Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (3)
Comentários (3)
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
Modelos de fundação de vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas muitas vezes ficam aquém quando se trata do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Em estúdios profissionais de VFX, esses modelos, junto com modelos anteriores baseados em imagens como Stable Diffusion, Kandinsky e Flux, são usados em conjunto com um conjunto de ferramentas projetadas para refinar sua saída para atender a demandas criativas específicas. Quando um diretor solicita um ajuste, dizendo algo como, "Isso parece ótimo, mas podemos torná-lo um pouco mais [n]?", não é suficiente simplesmente afirmar que o modelo carece da precisão para fazer tais ajustes.
Em vez disso, uma equipe de VFX com IA empregará uma combinação de CGI tradicional e técnicas de composição, juntamente com fluxos de trabalho desenvolvidos sob medida, para expandir os limites da síntese de vídeo. Essa abordagem é semelhante ao uso de um navegador web padrão como o Chrome; ele é funcional imediatamente, mas para realmente adaptá-lo às suas necessidades, você precisará instalar alguns plugins.
Control Freaks
No campo da síntese de imagens baseada em difusão, um dos sistemas de terceiros mais cruciais é o ControlNet. Essa técnica introduz controle estruturado aos modelos generativos, permitindo que os usuários guiem a geração de imagens ou vídeos usando entradas adicionais, como mapas de borda, mapas de profundidade ou informações de pose.
*Os vários métodos do ControlNet permitem geração de profundidade>imagem (linha superior), segmentação semântica>imagem (inferior à esquerda) e geração de imagens guiada por pose de humanos e animais (inferior à esquerda).*
O ControlNet não depende apenas de prompts de texto; ele emprega ramos de redes neurais separados, ou adaptadores, para processar esses sinais de condicionamento enquanto mantém as capacidades generativas do modelo base. Isso permite saídas altamente personalizadas que se alinham estreitamente com as especificações do usuário, tornando-o inestimável para aplicações que exigem controle preciso sobre composição, estrutura ou movimento.
*Com uma pose de guia, uma variedade de tipos de saída precisos pode ser obtida via ControlNet.* Fonte: https://arxiv.org/pdf/2302.05543
No entanto, esses sistemas baseados em adaptadores, que operam externamente em um conjunto de processos neurais focados internamente, apresentam várias desvantagens. Os adaptadores são treinados independentemente, o que pode levar a conflitos de ramos quando vários adaptadores são combinados, frequentemente resultando em gerações de menor qualidade. Eles também introduzem redundância de parâmetros, exigindo recursos computacionais e memória adicionais para cada adaptador, tornando a escalabilidade ineficiente. Além disso, apesar de sua flexibilidade, os adaptadores muitas vezes produzem resultados subótimos em comparação com modelos totalmente ajustados para geração multi-condicional. Esses problemas podem tornar os métodos baseados em adaptadores menos eficazes para tarefas que exigem a integração perfeita de múltiplos sinais de controle.
Idealmente, as capacidades do ControlNet seriam integradas nativamente ao modelo de forma modular, permitindo inovações futuras como geração simultânea de vídeo/áudio ou capacidades nativas de sincronização labial. Atualmente, cada recurso adicional torna-se uma tarefa de pós-produção ou um procedimento não nativo que deve navegar pelos pesos sensíveis do modelo de fundação.
FullDiT
Apresentamos o FullDiT, uma nova abordagem da China que integra recursos no estilo do ControlNet diretamente em um modelo generativo de vídeo durante o treinamento, em vez de tratá-los como uma reflexão tardia.
*Do novo artigo: a abordagem FullDiT pode incorporar imposição de identidade, profundidade e movimento de câmera em uma geração nativa, e pode evocar qualquer combinação desses de uma só vez.* Fonte: https://arxiv.org/pdf/2503.19907
O FullDiT, conforme descrito no artigo intitulado **FullDiT: Modelo de Fundação Generativa de Vídeo Multitarefa com Atenção Completa**, integra condições multitarefas, como transferência de identidade, mapeamento de profundidade e movimento de câmera, no núcleo de um modelo generativo de vídeo treinado. Os autores desenvolveram um modelo protótipo e clipes de vídeo acompanhantes disponíveis em um site do projeto.
**Clique para reproduzir. Exemplos de imposição de usuário no estilo ControlNet com apenas um modelo de fundação treinado nativamente.** Fonte: https://fulldit.github.io/
Os autores apresentam o FullDiT como uma prova de conceito para modelos nativos de texto para vídeo (T2V) e imagem para vídeo (I2V) que oferecem aos usuários mais controle do que apenas uma imagem ou prompt de texto. Como não existem modelos semelhantes, os pesquisadores criaram um novo benchmark chamado **FullBench** para avaliar vídeos multitarefas, reivindicando desempenho de ponta em seus testes concebidos. No entanto, a objetividade do FullBench, projetado pelos próprios autores, permanece não testada, e seu conjunto de dados de 1.400 casos pode ser muito limitado para conclusões mais amplas.
O aspecto mais intrigante da arquitetura do FullDiT é seu potencial para incorporar novos tipos de controle. Os autores observam:
**‘Neste trabalho, exploramos apenas condições de controle da câmera, identidades e informações de profundidade. Não investigamos mais a fundo outras condições e modalidades, como áudio, fala, nuvem de pontos, caixas delimitadoras de objetos, fluxo óptico, etc. Embora o design do FullDiT possa integrar outras modalidades com modificação mínima na arquitetura, como adaptar rapidamente e de forma econômica modelos existentes a novas condições e modalidades ainda é uma questão importante que merece exploração adicional.’**
Embora o FullDiT represente um passo adiante na geração de vídeos multitarefas, ele se baseia em arquiteturas existentes, em vez de introduzir um novo paradigma. No entanto, destaca-se como o único modelo de fundação de vídeo com recursos no estilo ControlNet integrados nativamente, e sua arquitetura é projetada para acomodar inovações futuras.
**Clique para reproduzir. Exemplos de movimentos de câmera controlados pelo usuário, do site do projeto.**
O artigo, de autoria de nove pesquisadores da Kuaishou Technology e da The Chinese University of Hong Kong, é intitulado **FullDiT: Modelo de Fundação Generativa de Vídeo Multitarefa com Atenção Completa**. A página do projeto e os dados do novo benchmark estão disponíveis no Hugging Face.
Método
O mecanismo de atenção unificada do FullDiT é projetado para aprimorar o aprendizado de representação cross-modal, capturando relações espaciais e temporais entre as condições.
*De acordo com o novo artigo, o FullDiT integra múltiplas condições de entrada por meio de atenção completa, convertendo-as em uma sequência unificada. Em contraste, modelos baseados em adaptadores (mais à esquerda acima) usam módulos separados para cada entrada, levando a redundância, conflitos e desempenho mais fraco.*
Diferentemente das configurações baseadas em adaptadores que processam cada fluxo de entrada separadamente, a estrutura de atenção compartilhada do FullDiT evita conflitos de ramos e reduz a sobrecarga de parâmetros. Os autores afirmam que a arquitetura pode escalar para novos tipos de entrada sem grandes reformulações e que o esquema do modelo mostra sinais de generalização para combinações de condições não vistas durante o treinamento, como vincular movimento de câmera com identidade de personagem.
**Clique para reproduzir. Exemplos de geração de identidade do site do projeto.**
Na arquitetura do FullDiT, todas as entradas de condicionamento — como texto, movimento de câmera, identidade e profundidade — são primeiro convertidas em um formato de token unificado. Esses tokens são então concatenados em uma única sequência longa, processada por uma pilha de camadas de transformadores usando atenção completa. Essa abordagem segue trabalhos anteriores como Open-Sora Plan e Movie Gen.
Esse design permite que o modelo aprenda relações temporais e espaciais conjuntamente em todas as condições. Cada bloco de transformador opera sobre a sequência inteira, possibilitando interações dinâmicas entre modalidades sem depender de módulos separados para cada entrada. A arquitetura é projetada para ser extensível, facilitando a incorporação de sinais de controle adicionais no futuro sem grandes mudanças estruturais.
O Poder dos Três
O FullDiT converte cada sinal de controle em um formato de token padronizado para que todas as condições possam ser processadas juntas em um framework de atenção unificado. Para o movimento de câmera, o modelo codifica uma sequência de parâmetros extrínsecos — como posição e orientação — para cada quadro. Esses parâmetros são marcados com carimbos de tempo e projetados em vetores de incorporação que refletem a natureza temporal do sinal.
As informações de identidade são tratadas de maneira diferente, pois são inerentemente espaciais, e não temporais. O modelo usa mapas de identidade que indicam quais personagens estão presentes em quais partes de cada quadro. Esses mapas são divididos em patches, com cada patch projetado em uma incorporação que captura pistas espaciais de identidade, permitindo que o modelo associe regiões específicas do quadro a entidades específicas.
A profundidade é um sinal espaço-temporal, e o modelo a trata dividindo vídeos de profundidade em patches 3D que abrangem espaço e tempo. Esses patches são então incorporados de maneira a preservar sua estrutura entre os quadros.
Uma vez incorporados, todos esses tokens de condição (câmera, identidade e profundidade) são concatenados em uma única sequência longa, permitindo que o FullDiT os processe juntos usando atenção completa. Essa representação compartilhada permite que o modelo aprenda interações entre modalidades e ao longo do tempo sem depender de fluxos de processamento isolados.
Dados e Testes
A abordagem de treinamento do FullDiT baseou-se em conjuntos de dados anotados seletivamente, adaptados a cada tipo de condicionamento, em vez de exigir que todas as condições estivessem presentes simultaneamente.
Para condições textuais, a iniciativa segue a abordagem de legendagem estruturada descrita no projeto MiraData.
*Pipeline de coleta e anotação de vídeos do projeto MiraData.* Fonte: https://arxiv.org/pdf/2407.06358
Para movimento de câmera, o conjunto de dados RealEstate10K foi a principal fonte de dados, devido às suas anotações de alta qualidade de parâmetros de câmera. No entanto, os autores observaram que treinar exclusivamente em conjuntos de dados de câmera de cena estática como o RealEstate10K tendia a reduzir movimentos de objetos dinâmicos e humanos nos vídeos gerados. Para contrabalançar isso, eles realizaram ajustes adicionais usando conjuntos de dados internos que incluíam movimentos de câmera mais dinâmicos.
As anotações de identidade foram geradas usando o pipeline desenvolvido para o projeto ConceptMaster, que permitiu filtragem e extração eficientes de informações de identidade detalhadas.
*O framework ConceptMaster é projetado para abordar questões de desacoplamento de identidade enquanto preserva a fidelidade do conceito em vídeos personalizados.* Fonte: https://arxiv.org/pdf/2501.04698
As anotações de profundidade foram obtidas do conjunto de dados Panda-70M usando Depth Anything.
Otimização por Ordenação de Dados
Os autores também implementaram um cronograma de treinamento progressivo, introduzindo condições mais desafiadoras no início do treinamento para garantir que o modelo adquirisse representações robustas antes que tarefas mais simples fossem adicionadas. A ordem de treinamento passou de texto para condições de câmera, depois identidades e, finalmente, profundidade, com tarefas mais fáceis geralmente introduzidas mais tarde e com menos exemplos.
Os autores enfatizam o valor de ordenar a carga de trabalho dessa maneira:
**‘Durante a fase de pré-treinamento, notamos que tarefas mais desafiadoras exigem tempo de treinamento prolongado e devem ser introduzidas mais cedo no processo de aprendizado. Essas tarefas desafiadoras envolvem distribuições de dados complexas que diferem significativamente do vídeo de saída, exigindo que o modelo possua capacidade suficiente para capturar e representar com precisão.**
**‘Por outro lado, introduzir tarefas mais fáceis muito cedo pode levar o modelo a priorizar seu aprendizado primeiro, já que elas fornecem feedback de otimização mais imediato, o que prejudica a convergência de tarefas mais desafiadoras.’**
*Uma ilustração da ordem de treinamento de dados adotada pelos pesquisadores, com vermelho indicando maior volume de dados.*
Após o pré-treinamento inicial, uma etapa final de ajuste fino refinou ainda mais o modelo para melhorar a qualidade visual e a dinâmica de movimento. A partir daí, o treinamento seguiu o de um framework de difusão padrão: ruído adicionado a latentes de vídeo, e o modelo aprendendo a prever e remover, usando os tokens de condição incorporados como guia.
Para avaliar o FullDiT de forma eficaz e fornecer uma comparação justa com métodos existentes, e na ausência de qualquer outro benchmark apropriado, os autores introduziram o **FullBench**, um conjunto de benchmark curado composto por 1.400 casos de teste distintos.
*Uma instância de explorador de dados para o novo benchmark FullBench.* Fonte: https://huggingface.co/datasets/KwaiVGI/FullBench
Cada ponto de dados fornecia anotações de verdade absoluta para vários sinais de condicionamento, incluindo movimento de câmera, identidade e profundidade.
Métricas
Os autores avaliaram o FullDiT usando dez métricas cobrindo cinco aspectos principais de desempenho: alinhamento de texto, controle de câmera, similaridade de identidade, precisão de profundidade e qualidade geral do vídeo.
O alinhamento de texto foi medido usando similaridade CLIP, enquanto o controle de câmera foi avaliado por meio de erro de rotação (RotErr), erro de translação (TransErr) e consistência de movimento de câmera (CamMC), seguindo a abordagem do CamI2V (no projeto CameraCtrl).
A similaridade de identidade foi avaliada usando DINO-I e CLIP-I, e a precisão de controle de profundidade foi quantificada usando Erro Absoluto Médio (MAE).
A qualidade do vídeo foi julgada com três métricas do MiraData: similaridade CLIP em nível de quadro para suavidade; distância de movimento baseada em fluxo óptico para dinâmica; e pontuações LAION-Aesthetic para apelo visual.
Treinamento
Os autores treinaram o FullDiT usando um modelo interno (não divulgado) de difusão de texto para vídeo contendo aproximadamente um bilhão de parâmetros. Eles escolheram intencionalmente um tamanho de parâmetro modesto para manter a equidade nas comparações com métodos anteriores e garantir reprodutibilidade.
Como os vídeos de treinamento variavam em duração e resolução, os autores padronizaram cada lote redimensionando e preenchendo os vídeos para uma resolução comum, amostrando 77 quadros por sequência e usando máscaras de atenção e perda aplicadas para otimizar a eficácia do treinamento.
O otimizador Adam foi usado com uma taxa de aprendizado de 1×10−5 em um cluster de 64 GPUs NVIDIA H800, para um total combinado de 5.120 GB de VRAM (considere que nas comunidades de síntese entusiastas, 24 GB em uma RTX 3090 ainda é considerado um padrão luxuoso).
O modelo foi treinado por cerca de 32.000 passos, incorporando até três identidades por vídeo, junto com 20 quadros de condições de câmera e 21 quadros de condições de profundidade, ambos amostrados uniformemente do total de 77 quadros.
Para inferência, o modelo gerou vídeos com uma resolução de 384×672 pixels (aproximadamente cinco segundos a 15 quadros por segundo) com 50 passos de inferência de difusão e uma escala de orientação sem classificador de cinco.
Métodos Anteriores
Para avaliação de câmera para vídeo, os autores compararam o FullDiT contra MotionCtrl, CameraCtrl e CamI2V, com todos os modelos treinados usando o conjunto de dados RealEstate10k para garantir consistência e equidade.
Na geração condicionada por identidade, como não havia modelos de código aberto comparáveis com múltiplas identidades disponíveis, o modelo foi comparado ao modelo ConceptMaster de 1 bilhão de parâmetros, usando os mesmos dados de treinamento e arquitetura.
Para tarefas de profundidade para vídeo, comparações foram feitas com Ctrl-Adapter e ControlVideo.
*Resultados quantitativos para geração de vídeo de tarefa única. O FullDiT foi comparado ao MotionCtrl, CameraCtrl e CamI2V para geração de câmera para vídeo; ConceptMaster (versão de 1 bilhão de parâmetros) para identidade para vídeo; e Ctrl-Adapter e ControlVideo para profundidade para vídeo. Todos os modelos foram avaliados usando suas configurações padrão. Para consistência, 16 quadros foram amostrados uniformemente de cada método, correspondendo à duração de saída dos modelos anteriores.*
Os resultados indicam que o FullDiT, apesar de lidar com múltiplos sinais de condicionamento simultaneamente, alcançou desempenho de ponta em métricas relacionadas a texto, movimento de câmera, identidade e controles de profundidade.
Nas métricas de qualidade geral, o sistema geralmente superou outros métodos, embora sua suavidade tenha sido ligeiramente inferior à do ConceptMaster. Aqui, os autores comentam:
**‘A suavidade do FullDiT é ligeiramente inferior à do ConceptMaster, já que o cálculo da suavidade é baseado na similaridade CLIP entre quadros adjacentes. Como o FullDiT exibe dinâmica significativamente maior em comparação com o ConceptMaster, a métrica de suavidade é impactada pelas grandes variações entre quadros adjacentes.**
**‘Para a pontuação estética, como o modelo de classificação favorece imagens no estilo de pintura e o ControlVideo normalmente gera vídeos nesse estilo, ele alcança uma alta pontuação em estética.’**
Em relação à comparação qualitativa, pode ser preferível consultar os vídeos de amostra no site do projeto FullDiT, já que os exemplos em PDF são inevitavelmente estáticos (e também grandes demais para serem reproduzidos inteiramente aqui).
*A primeira seção dos resultados qualitativos reproduzidos no PDF. Consulte o artigo fonte para os exemplos adicionais, que são muito extensos para serem reproduzidos aqui.*
Os autores comentam:
**‘O FullDiT demonstra preservação de identidade superior e gera vídeos com melhor dinâmica e qualidade visual em comparação com [ConceptMaster]. Como o ConceptMaster e o FullDiT são treinados na mesma estrutura, isso destaca a eficácia da injeção de condições com atenção completa.**
**‘…Os [outros] resultados demonstram a controlabilidade e qualidade de geração superiores do FullDiT em comparação com os métodos existentes de profundidade para vídeo e câmera para vídeo.’**
*Uma seção dos exemplos do PDF da saída do FullDiT com múltiplos sinais. Consulte o artigo fonte e o site do projeto para exemplos adicionais.*
Conclusão
O FullDiT representa um passo empolgante em direção a um modelo de fundação de vídeo mais abrangente, mas a questão permanece se a demanda por recursos no estilo ControlNet justifica sua implementação em escala, especialmente para projetos de código aberto. Esses projetos teriam dificuldade para obter o vasto poder de processamento de GPU necessário sem suporte comercial.
O principal desafio é que o uso de sistemas como Depth e Pose geralmente exige uma familiaridade não trivial com interfaces de usuário complexas como o ComfyUI. Portanto, um modelo funcional de código aberto desse tipo é mais provável de ser desenvolvido por pequenas empresas de VFX que carecem de recursos ou motivação para curar e treinar tal modelo privadamente.
Por outro lado, sistemas de ‘aluguel de IA’ orientados por API podem estar bem motivados para desenvolver métodos interpretativos mais simples e amigáveis ao usuário para modelos com sistemas de controle auxiliares treinados diretamente.
**Clique para reproduzir. Controles de Profundidade+Texto impostos em uma geração de vídeo usando FullDiT.**
*Os autores não especificam nenhum modelo base conhecido (ou seja, SDXL, etc.)*
**Publicado pela primeira vez na quinta-feira, 27 de março de 2025**










 YouTube testa recurso de pesquisa baseado em IA com respostas guiadas
Muitos usuários recorrem ao YouTube quando procuram receitas ou planos de viagem, em busca de vídeos relevantes. Agora, a plataforma está lançando uma ferramenta de pesquisa interativa baseada em IA q
YouTube testa recurso de pesquisa baseado em IA com respostas guiadas
Muitos usuários recorrem ao YouTube quando procuram receitas ou planos de viagem, em busca de vídeos relevantes. Agora, a plataforma está lançando uma ferramenta de pesquisa interativa baseada em IA q
 Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
 A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













