




Tạo video AI chuyển sang kiểm soát hoàn toàn
Các mô hình nền tảng video như Hunyuan và Wan 2.1 đã đạt được những tiến bộ đáng kể, nhưng chúng thường không đáp ứng được yêu cầu kiểm soát chi tiết trong sản xuất phim và truyền hình, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong các studio VFX chuyên nghiệp, những mô hình này, cùng với các mô hình dựa trên hình ảnh trước đó như Stable Diffusion, Kandinsky và Flux, được sử dụng kết hợp với một bộ công cụ được thiết kế để tinh chỉnh đầu ra nhằm đáp ứng các nhu cầu sáng tạo cụ thể. Khi một đạo diễn yêu cầu điều chỉnh, nói điều gì đó như, "Trông tuyệt vời, nhưng chúng ta có thể làm nó thêm chút [n] không?", chỉ nói rằng mô hình thiếu độ chính xác để thực hiện các điều chỉnh như vậy là không đủ.
Thay vào đó, một đội ngũ AI VFX sẽ sử dụng kết hợp giữa CGI truyền thống và các kỹ thuật tổng hợp, cùng với các quy trình làm việc được phát triển tùy chỉnh, để vượt qua giới hạn của tổng hợp video. Cách tiếp cận này tương tự như sử dụng một trình duyệt web mặc định như Chrome; nó hoạt động ngay từ đầu, nhưng để thực sự tùy chỉnh theo nhu cầu của bạn, bạn sẽ cần cài đặt một số plugin.
Những người kiểm soát chi tiết
Trong lĩnh vực tổng hợp hình ảnh dựa trên khuếch tán, một trong những hệ thống bên thứ ba quan trọng nhất là ControlNet. Kỹ thuật này mang lại khả năng kiểm soát có cấu trúc cho các mô hình tạo sinh, cho phép người dùng định hướng việc tạo hình ảnh hoặc video bằng cách sử dụng các đầu vào bổ sung như bản đồ cạnh, bản đồ độ sâu, hoặc thông tin tư thế.
 *Các phương pháp đa dạng của ControlNet cho phép chuyển đổi từ độ sâu sang hình ảnh (hàng trên), phân đoạn ngữ nghĩa sang hình ảnh (dưới bên trái) và tạo hình ảnh định hướng tư thế của con người và động vật (dưới bên trái).*
*Các phương pháp đa dạng của ControlNet cho phép chuyển đổi từ độ sâu sang hình ảnh (hàng trên), phân đoạn ngữ nghĩa sang hình ảnh (dưới bên trái) và tạo hình ảnh định hướng tư thế của con người và động vật (dưới bên trái).*
ControlNet không chỉ dựa vào các gợi ý văn bản; nó sử dụng các nhánh mạng nơ-ron riêng biệt, hoặc bộ điều hợp, để xử lý các tín hiệu điều kiện này trong khi vẫn duy trì khả năng tạo sinh của mô hình cơ bản. Điều này cho phép tạo ra các đầu ra tùy chỉnh cao, phù hợp chặt chẽ với thông số kỹ thuật của người dùng, khiến nó trở nên vô giá đối với các ứng dụng yêu cầu kiểm soát chính xác về bố cục, cấu trúc hoặc chuyển động.
 *Với tư thế dẫn đường, nhiều loại đầu ra chính xác có thể được tạo ra thông qua ControlNet.* Nguồn: https://arxiv.org/pdf/2302.05543
*Với tư thế dẫn đường, nhiều loại đầu ra chính xác có thể được tạo ra thông qua ControlNet.* Nguồn: https://arxiv.org/pdf/2302.05543
Tuy nhiên, các hệ thống dựa trên bộ điều hợp, hoạt động bên ngoài trên một tập hợp các quá trình nơ-ron tập trung nội bộ, đi kèm với một số nhược điểm. Các bộ điều hợp được huấn luyện độc lập, có thể dẫn đến xung đột nhánh khi nhiều bộ điều hợp được kết hợp, thường dẫn đến chất lượng tạo sinh thấp hơn. Chúng cũng gây ra dư thừa tham số, yêu cầu thêm tài nguyên tính toán và bộ nhớ cho mỗi bộ điều hợp, khiến việc mở rộng trở nên kém hiệu quả. Hơn nữa, mặc dù linh hoạt, các bộ điều hợp thường cho kết quả không tối ưu so với các mô hình được tinh chỉnh hoàn toàn cho việc tạo sinh đa điều kiện. Những vấn đề này có thể khiến các phương pháp dựa trên bộ điều hợp kém hiệu quả đối với các nhiệm vụ yêu cầu tích hợp liền mạch nhiều tín hiệu kiểm soát.
Lý tưởng nhất, các khả năng của ControlNet sẽ được tích hợp nguyên bản vào mô hình theo cách mô-đun, cho phép các đổi mới trong tương lai như tạo video/âm thanh đồng thời hoặc khả năng đồng bộ môi tự nhiên. Hiện tại, mỗi tính năng bổ sung hoặc trở thành một nhiệm vụ hậu kỳ hoặc một quy trình không nguyên bản phải điều hướng các trọng số nhạy cảm của mô hình nền tảng.
FullDiT
Giới thiệu FullDiT, một cách tiếp cận mới từ Trung Quốc tích hợp các tính năng kiểu ControlNet trực tiếp vào một mô hình video tạo sinh trong quá trình huấn luyện, thay vì coi chúng như một suy nghĩ sau cùng.
 *Từ bài báo mới: cách tiếp cận FullDiT có thể tích hợp áp đặt danh tính, độ sâu và chuyển động máy quay vào một quá trình tạo sinh nguyên bản, và có thể gọi ra bất kỳ sự kết hợp nào của những yếu tố này cùng một lúc.* Nguồn: https://arxiv.org/pdf/2503.19907
*Từ bài báo mới: cách tiếp cận FullDiT có thể tích hợp áp đặt danh tính, độ sâu và chuyển động máy quay vào một quá trình tạo sinh nguyên bản, và có thể gọi ra bất kỳ sự kết hợp nào của những yếu tố này cùng một lúc.* Nguồn: https://arxiv.org/pdf/2503.19907
FullDiT, như được nêu trong bài báo có tiêu đề **FullDiT: Mô hình nền tảng tạo sinh video đa nhiệm với sự chú ý đầy đủ**, tích hợp các điều kiện đa nhiệm như chuyển giao danh tính, lập bản đồ độ sâu, và chuyển động máy quay vào lõi của một mô hình video tạo sinh đã được huấn luyện. Các tác giả đã phát triển một mô hình nguyên mẫu và các đoạn video đi kèm có sẵn tại một trang web dự án.
**Nhấp để phát. Ví dụ về áp đặt người dùng kiểu ControlNet chỉ với một mô hình nền tảng được huấn luyện nguyên bản.** Nguồn: https://fulldit.github.io/
Các tác giả giới thiệu FullDiT như một bằng chứng khái niệm cho các mô hình văn bản sang video (T2V) và hình ảnh sang video (I2V) cung cấp cho người dùng nhiều quyền kiểm soát hơn chỉ một gợi ý hình ảnh hoặc văn bản. Vì không có mô hình tương tự nào tồn tại, các nhà nghiên cứu đã tạo ra một chuẩn mực mới gọi là **FullBench** để đánh giá các video đa nhiệm, tuyên bố đạt hiệu suất tiên tiến trong các bài kiểm tra do họ thiết kế. Tuy nhiên, tính khách quan của FullBench, do chính các tác giả thiết kế, vẫn chưa được kiểm chứng, và bộ dữ liệu gồm 1.400 trường hợp có thể quá hạn chế để đưa ra kết luận rộng hơn.
Khía cạnh hấp dẫn nhất của kiến trúc FullDiT là tiềm năng tích hợp các loại kiểm soát mới. Các tác giả lưu ý:
**‘Trong nghiên cứu này, chúng tôi chỉ khám phá các điều kiện kiểm soát của máy quay, danh tính và thông tin độ sâu. Chúng tôi chưa nghiên cứu thêm các điều kiện và phương thức khác như âm thanh, giọng nói, đám mây điểm, hộp giới hạn đối tượng, luồng quang học, v.v. Mặc dù thiết kế của FullDiT có thể tích hợp liền mạch các phương thức khác với sự thay đổi kiến trúc tối thiểu, làm thế nào để nhanh chóng và hiệu quả về chi phí điều chỉnh các mô hình hiện có cho các điều kiện và phương thức mới vẫn là một câu hỏi quan trọng cần được khám phá thêm.'**
Mặc dù FullDiT đại diện cho một bước tiến trong việc tạo video đa nhiệm, nó được xây dựng dựa trên các kiến trúc hiện có thay vì giới thiệu một mô hình hoàn toàn mới. Tuy nhiên, nó nổi bật như là mô hình nền tảng video duy nhất với các tính năng kiểu ControlNet được tích hợp nguyên bản, và kiến trúc của nó được thiết kế để phù hợp với các đổi mới trong tương lai.
**Nhấp để phát. Ví dụ về các chuyển động máy quay do người dùng kiểm soát, từ trang web dự án.**
Bài báo, được viết bởi chín nhà nghiên cứu từ Kuaishou Technology và Đại học Hồng Kông Trung Quốc, có tiêu đề **FullDiT: Mô hình nền tảng tạo sinh video đa nhiệm với sự chú ý đầy đủ**. Trang dự án và dữ liệu chuẩn mực mới có sẵn tại Hugging Face.
Phương pháp
Cơ chế chú ý thống nhất của FullDiT được thiết kế để nâng cao khả năng học biểu diễn đa phương thức bằng cách nắm bắt cả mối quan hệ không gian và thời gian giữa các điều kiện.
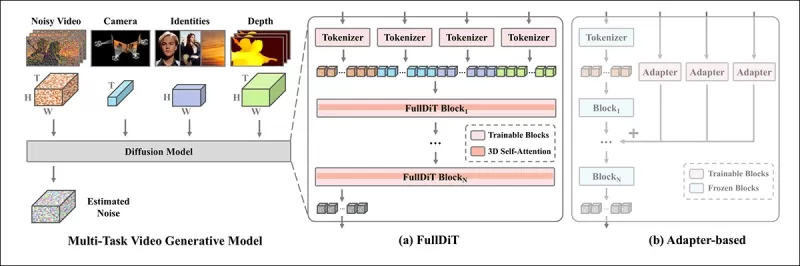 *Theo bài báo mới, FullDiT tích hợp nhiều điều kiện đầu vào thông qua sự chú ý tự đầy đủ, chuyển đổi chúng thành một chuỗi thống nhất. Ngược lại, các mô hình dựa trên bộ điều hợp (bên trái nhất ở trên) sử dụng các mô-đun riêng biệt cho mỗi đầu vào, dẫn đến dư thừa, xung đột và hiệu suất yếu hơn.*
*Theo bài báo mới, FullDiT tích hợp nhiều điều kiện đầu vào thông qua sự chú ý tự đầy đủ, chuyển đổi chúng thành một chuỗi thống nhất. Ngược lại, các mô hình dựa trên bộ điều hợp (bên trái nhất ở trên) sử dụng các mô-đun riêng biệt cho mỗi đầu vào, dẫn đến dư thừa, xung đột và hiệu suất yếu hơn.*
Không giống như các thiết lập dựa trên bộ điều hợp xử lý từng luồng đầu vào riêng biệt, cấu trúc chú ý chia sẻ của FullDiT tránh xung đột nhánh và giảm chi phí tham số. Các tác giả tuyên bố rằng kiến trúc này có thể mở rộng cho các loại đầu vào mới mà không cần thiết kế lại lớn và rằng lược đồ mô hình cho thấy dấu hiệu khái quát hóa cho các tổ hợp điều kiện chưa thấy trong quá trình huấn luyện, chẳng hạn như liên kết chuyển động máy quay với danh tính nhân vật.
**Nhấp để phát. Ví dụ về tạo danh tính từ trang web dự án.**
Trong kiến trúc của FullDiT, tất cả các đầu vào điều kiện—như văn bản, chuyển động máy quay, danh tính và độ sâu—đầu tiên được chuyển đổi thành định dạng token thống nhất. Các token này sau đó được nối thành một chuỗi dài duy nhất, được xử lý qua một chồng các lớp transformer sử dụng sự chú ý tự đầy đủ. Cách tiếp cận này tuân theo các công trình trước như Open-Sora Plan và Movie Gen.
Thiết kế này cho phép mô hình học các mối quan hệ thời gian và không gian đồng thời trên tất cả các điều kiện. Mỗi khối transformer hoạt động trên toàn bộ chuỗi, cho phép tương tác động giữa các phương thức mà không phụ thuộc vào các mô-đun riêng biệt cho mỗi đầu vào. Kiến trúc được thiết kế để có thể mở rộng, giúp dễ dàng tích hợp các tín hiệu kiểm soát bổ sung trong tương lai mà không cần thay đổi cấu trúc lớn.
Sức mạnh của ba
FullDiT chuyển đổi mỗi tín hiệu kiểm soát thành định dạng token chuẩn hóa để tất cả các điều kiện có thể được xử lý cùng nhau trong một khung chú ý thống nhất. Đối với chuyển động máy quay, mô hình mã hóa một chuỗi các tham số ngoại tại—như vị trí và hướng—cho mỗi khung hình. Các tham số này được gắn dấu thời gian và chiếu vào các vector nhúng phản ánh bản chất thời gian của tín hiệu.
Thông tin danh tính được xử lý khác nhau, vì nó vốn là không gian hơn là thời gian. Mô hình sử dụng bản đồ danh tính chỉ ra nhân vật nào xuất hiện ở phần nào của mỗi khung hình. Các bản đồ này được chia thành các mảnh, với mỗi mảnh được chiếu vào một nhúng nắm bắt các tín hiệu danh tính không gian, cho phép mô hình liên kết các vùng cụ thể của khung hình với các thực thể cụ thể.
Độ sâu là một tín hiệu không thời gian, và mô hình xử lý nó bằng cách chia các video độ sâu thành các mảnh 3D trải dài cả không gian và thời gian. Các mảnh này sau đó được nhúng theo cách bảo toàn cấu trúc của chúng qua các khung hình.
Khi đã được nhúng, tất cả các token điều kiện (máy quay, danh tính và độ sâu) được nối thành một chuỗi dài duy nhất, cho phép FullDiT xử lý chúng cùng nhau bằng sự chú ý tự đầy đủ. Biểu diễn chia sẻ này cho phép mô hình học các tương tác giữa các phương thức và qua thời gian mà không phụ thuộc vào các luồng xử lý riêng biệt.
Dữ liệu và Kiểm tra
Cách tiếp cận huấn luyện của FullDiT dựa trên các bộ dữ liệu được chú thích có chọn lọc phù hợp với từng loại điều kiện, thay vì yêu cầu tất cả các điều kiện phải có mặt đồng thời.
Đối với các điều kiện văn bản, sáng kiến này tuân theo cách tiếp cận chú thích có cấu trúc được nêu trong dự án MiraData.
 *Quy trình thu thập và chú thích video từ dự án MiraData.* Nguồn: https://arxiv.org/pdf/2407.06358
*Quy trình thu thập và chú thích video từ dự án MiraData.* Nguồn: https://arxiv.org/pdf/2407.06358
Đối với chuyển động máy quay, bộ dữ liệu RealEstate10K là nguồn dữ liệu chính, do các chú thích ground-truth chất lượng cao của nó về các tham số máy quay. Tuy nhiên, các tác giả nhận thấy rằng việc huấn luyện chỉ trên các bộ dữ liệu máy quay cảnh tĩnh như RealEstate10K có xu hướng làm giảm chuyển động của các đối tượng động và con người trong các video được tạo ra. Để khắc phục điều này, họ đã tiến hành tinh chỉnh bổ sung bằng các bộ dữ liệu nội bộ bao gồm nhiều chuyển động máy quay động hơn.
Các chú thích danh tính được tạo ra bằng quy trình phát triển cho dự án ConceptMaster, cho phép lọc và trích xuất thông tin danh tính chi tiết một cách hiệu quả.
 *Khung ConceptMaster được thiết kế để giải quyết các vấn đề tách biệt danh tính trong khi bảo toàn tính trung thực của khái niệm trong các video tùy chỉnh.* Nguồn: https://arxiv.org/pdf/2501.04698
*Khung ConceptMaster được thiết kế để giải quyết các vấn đề tách biệt danh tính trong khi bảo toàn tính trung thực của khái niệm trong các video tùy chỉnh.* Nguồn: https://arxiv.org/pdf/2501.04698
Các chú thích độ sâu được lấy từ bộ dữ liệu Panda-70M bằng cách sử dụng Depth Anything.
Tối ưu hóa thông qua sắp xếp dữ liệu
Các tác giả cũng triển khai một lịch trình huấn luyện tiến bộ, đưa các điều kiện khó hơn vào sớm trong quá trình huấn luyện để đảm bảo mô hình đạt được các biểu diễn mạnh mẽ trước khi các nhiệm vụ đơn giản hơn được thêm vào. Thứ tự huấn luyện tiến hành từ văn bản đến các điều kiện máy quay, sau đó là danh tính, và cuối cùng là độ sâu, với các nhiệm vụ dễ hơn thường được giới thiệu muộn hơn và với ít ví dụ hơn.
Các tác giả nhấn mạnh giá trị của việc sắp xếp khối lượng công việc theo cách này:
**‘Trong giai đoạn huấn luyện trước, chúng tôi nhận thấy rằng các nhiệm vụ khó hơn đòi hỏi thời gian huấn luyện kéo dài và nên được giới thiệu sớm hơn trong quá trình học. Những nhiệm vụ khó khăn này liên quan đến các phân phối dữ liệu phức tạp khác biệt đáng kể so với video đầu ra, đòi hỏi mô hình phải có đủ khả năng để nắm bắt và biểu diễn chúng một cách chính xác.**
**‘Ngược lại, việc giới thiệu các nhiệm vụ dễ hơn quá sớm có thể khiến mô hình ưu tiên học chúng trước, vì chúng cung cấp phản hồi tối ưu hóa ngay lập tức, làm cản trở sự hội tụ của các nhiệm vụ khó hơn.'**
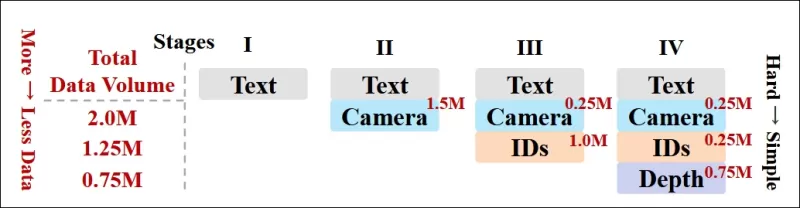 *Hình minh họa về thứ tự huấn luyện dữ liệu được các nhà nghiên cứu áp dụng, với màu đỏ biểu thị khối lượng dữ liệu lớn hơn.*
*Hình minh họa về thứ tự huấn luyện dữ liệu được các nhà nghiên cứu áp dụng, với màu đỏ biểu thị khối lượng dữ liệu lớn hơn.*
Sau giai đoạn huấn luyện trước ban đầu, một giai đoạn tinh chỉnh cuối cùng đã tiếp tục tinh chỉnh mô hình để cải thiện chất lượng hình ảnh và động lực chuyển động. Sau đó, quá trình huấn luyện tuân theo khung khuếch tán tiêu chuẩn: nhiễu được thêm vào các ẩn video, và mô hình học cách dự đoán và loại bỏ nó, sử dụng các token điều kiện nhúng làm hướng dẫn.
Để đánh giá hiệu quả FullDiT và cung cấp sự so sánh công bằng với các phương pháp hiện có, và trong điều kiện không có chuẩn mực phù hợp nào khác, các tác giả đã giới thiệu **FullBench**, một bộ chuẩn mực được chọn lọc gồm 1.400 trường hợp kiểm tra riêng biệt.
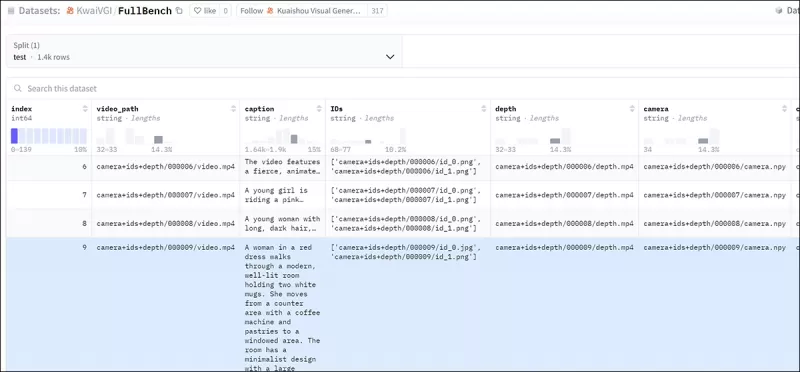 *Một phiên bản trình khám phá dữ liệu cho chuẩn mực FullBench mới.* Nguồn: https://huggingface.co/datasets/KwaiVGI/FullBench
*Một phiên bản trình khám phá dữ liệu cho chuẩn mực FullBench mới.* Nguồn: https://huggingface.co/datasets/KwaiVGI/FullBench
Mỗi điểm dữ liệu cung cấp các chú thích ground-truth cho các tín hiệu điều kiện khác nhau, bao gồm chuyển động máy quay, danh tính và độ sâu.
Số liệu
Các tác giả đã đánh giá FullDiT bằng mười số liệu bao gồm năm khía cạnh hiệu suất chính: căn chỉnh văn bản, kiểm soát máy quay, độ tương đồng danh tính, độ chính xác độ sâu và chất lượng video tổng quát.
Căn chỉnh văn bản được đo bằng độ tương đồng CLIP, trong khi kiểm soát máy quay được đánh giá qua lỗi xoay (RotErr), lỗi dịch chuyển (TransErr), và tính nhất quán chuyển động máy quay (CamMC), theo cách tiếp cận của CamI2V (trong dự án CameraCtrl).
Độ tương đồng danh tính được đánh giá bằng DINO-I và CLIP-I, và độ chính xác kiểm soát độ sâu được định lượng bằng Sai số Tuyệt đối Trung bình (MAE).
Chất lượng video được đánh giá bằng ba số liệu từ MiraData: độ tương đồng CLIP cấp khung hình cho độ mượt mà; khoảng cách chuyển động dựa trên luồng quang học cho động lực; và điểm thẩm mỹ LAION-Aesthetic cho sức hấp dẫn hình ảnh.
Huấn luyện
Các tác giả đã huấn luyện FullDiT bằng một mô hình khuếch tán văn bản sang video nội bộ (không được tiết lộ) chứa khoảng một tỷ tham số. Họ cố ý chọn kích thước tham số khiêm tốn để duy trì sự công bằng trong so sánh với các phương pháp trước đó và đảm bảo khả năng tái tạo.
Vì các video huấn luyện khác nhau về độ dài và độ phân giải, các tác giả đã chuẩn hóa mỗi lô bằng cách thay đổi kích thước và đệm các video thành một độ phân giải chung, lấy mẫu 77 khung hình cho mỗi chuỗi, và sử dụng các mặt nạ chú ý và tổn thất được áp dụng để tối ưu hóa hiệu quả huấn luyện.
Trình tối ưu hóa Adam được sử dụng với tốc độ học 1×10−5 trên một cụm 64 GPU NVIDIA H800, với tổng cộng 5.120GB VRAM (hãy xem xét rằng trong các cộng đồng tổng hợp đam mê, 24GB trên RTX 3090 vẫn được coi là tiêu chuẩn xa xỉ).
Mô hình được huấn luyện trong khoảng 32.000 bước, kết hợp tối đa ba danh tính cho mỗi video, cùng với 20 khung hình điều kiện máy quay và 21 khung hình điều kiện độ sâu, cả hai được lấy mẫu đều từ tổng số 77 khung hình.
Đối với suy luận, mô hình tạo ra các video ở độ phân giải 384×672 pixel (khoảng năm giây ở 15 khung hình mỗi giây) với 50 bước suy luận khuếch tán và thang hướng dẫn không phân loại là năm.
Các phương pháp trước
Đối với đánh giá từ máy quay sang video, các tác giả đã so sánh FullDiT với MotionCtrl, CameraCtrl và CamI2V, với tất cả các mô hình được huấn luyện bằng bộ dữ liệu RealEstate10k để đảm bảo tính nhất quán và công bằng.
Trong việc tạo sinh điều kiện danh tính, vì không có mô hình đa danh tính mã nguồn mở tương đương nào, mô hình được chuẩn hóa so với mô hình ConceptMaster 1B tham số, sử dụng cùng dữ liệu huấn luyện và kiến trúc.
Đối với các nhiệm vụ từ độ sâu sang video, các so sánh được thực hiện với Ctrl-Adapter và ControlVideo.
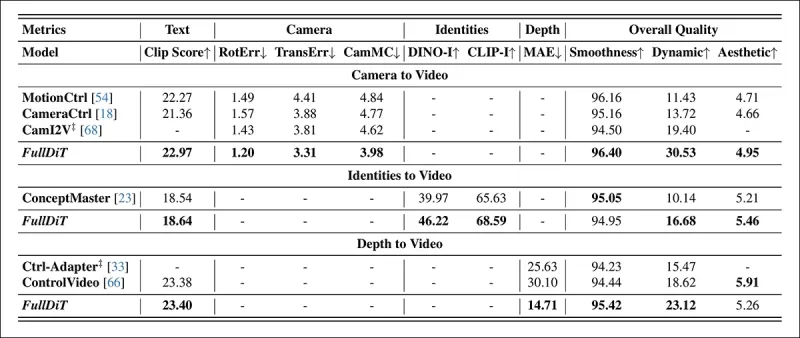 *Kết quả định lượng cho việc tạo video đơn nhiệm. FullDiT được so sánh với MotionCtrl, CameraCtrl và CamI2V cho việc tạo từ máy quay sang video; ConceptMaster (phiên bản 1B tham số) cho việc tạo từ danh tính sang video; và Ctrl-Adapter và ControlVideo cho việc tạo từ độ sâu sang video. Tất cả các mô hình được đánh giá bằng cài đặt mặc định của chúng. Để đảm bảo tính nhất quán, 16 khung hình được lấy mẫu đều từ mỗi phương pháp, phù hợp với độ dài đầu ra của các mô hình trước đó.*
*Kết quả định lượng cho việc tạo video đơn nhiệm. FullDiT được so sánh với MotionCtrl, CameraCtrl và CamI2V cho việc tạo từ máy quay sang video; ConceptMaster (phiên bản 1B tham số) cho việc tạo từ danh tính sang video; và Ctrl-Adapter và ControlVideo cho việc tạo từ độ sâu sang video. Tất cả các mô hình được đánh giá bằng cài đặt mặc định của chúng. Để đảm bảo tính nhất quán, 16 khung hình được lấy mẫu đều từ mỗi phương pháp, phù hợp với độ dài đầu ra của các mô hình trước đó.*
Kết quả cho thấy FullDiT, mặc dù xử lý nhiều tín hiệu điều kiện đồng thời, đã đạt được hiệu suất tiên tiến trong các số liệu liên quan đến văn bản, chuyển động máy quay, danh tính và kiểm soát độ sâu.
Trong các số liệu chất lượng tổng thể, hệ thống thường vượt trội hơn các phương pháp khác, mặc dù độ mượt mà của nó thấp hơn một chút so với ConceptMaster. Ở đây, các tác giả nhận xét:
**‘Độ mượt mà của FullDiT thấp hơn một chút so với ConceptMaster vì việc tính toán độ mượt mà dựa trên độ tương đồng CLIP giữa các khung hình liền kề. Vì FullDiT thể hiện động lực lớn hơn đáng kể so với ConceptMaster, số liệu độ mượt mà bị ảnh hưởng bởi các biến đổi lớn giữa các khung hình liền kề.**
**‘Đối với điểm thẩm mỹ, vì mô hình đánh giá ưu tiên các hình ảnh theo phong cách hội họa và ControlVideo thường tạo ra các video theo phong cách này, nó đạt được điểm cao về thẩm mỹ.'**
Về so sánh định tính, có lẽ nên tham khảo các video mẫu tại trang web dự án FullDiT, vì các ví dụ trong PDF không thể tránh khỏi là tĩnh (và cũng quá lớn để tái tạo toàn bộ ở đây).
 *Phần đầu tiên của kết quả định tính được tái tạo trong PDF. Vui lòng tham khảo bài báo nguồn để xem các ví dụ bổ sung, quá rộng để tái tạo ở đây.*
*Phần đầu tiên của kết quả định tính được tái tạo trong PDF. Vui lòng tham khảo bài báo nguồn để xem các ví dụ bổ sung, quá rộng để tái tạo ở đây.*
Các tác giả nhận xét:
**‘FullDiT thể hiện khả năng bảo toàn danh tính vượt trội và tạo ra các video với động lực và chất lượng hình ảnh tốt hơn so với [ConceptMaster]. Vì ConceptMaster và FullDiT được huấn luyện trên cùng một nền tảng, điều này làm nổi bật hiệu quả của việc tiêm điều kiện với sự chú ý đầy đủ.**
**‘…Các kết quả [khác] thể hiện khả năng kiểm soát và chất lượng tạo sinh vượt trội của FullDiT so với các phương pháp từ độ sâu sang video và từ máy quay sang video hiện có.'**
 *Một phần của các ví dụ trong PDF về đầu ra của FullDiT với nhiều tín hiệu. Vui lòng tham khảo bài báo nguồn và trang web dự án để xem các ví dụ bổ sung.*
*Một phần của các ví dụ trong PDF về đầu ra của FullDiT với nhiều tín hiệu. Vui lòng tham khảo bài báo nguồn và trang web dự án để xem các ví dụ bổ sung.*
Kết luận
FullDiT đại diện cho một bước tiến thú vị hướng tới một mô hình nền tảng video toàn diện hơn, nhưng câu hỏi vẫn là liệu nhu cầu về các tính năng kiểu ControlNet có đủ để biện minh cho việc triển khai chúng ở quy mô lớn, đặc biệt đối với các dự án mã nguồn mở. Những dự án này sẽ phải vật lộn để có được sức mạnh xử lý GPU rộng lớn cần thiết nếu không có sự hỗ trợ thương mại.
Thách thức chính là việc sử dụng các hệ thống như Độ sâu và Tư thế thường đòi hỏi sự quen thuộc không tầm thường với các giao diện người dùng phức tạp như ComfyUI. Do đó, một mô hình mã nguồn mở hoạt động của loại này rất có thể được phát triển bởi các công ty VFX nhỏ hơn thiếu nguồn lực hoặc động lực để tự quản lý và huấn luyện một mô hình như vậy.
Mặt khác, các hệ thống 'thuê AI' dựa trên API có thể được thúc đẩy mạnh mẽ để phát triển các phương pháp diễn giải đơn giản và thân thiện hơn với người dùng cho các mô hình với các hệ thống kiểm soát phụ trợ được huấn luyện trực tiếp.
**Nhấp để phát. Kiểm soát Độ sâu+Văn bản được áp đặt lên một quá trình tạo video bằng FullDiT.**
*Các tác giả không chỉ định bất kỳ mô hình cơ bản nào đã biết (tức là, SDXL, v.v.)*
**Được xuất bản lần đầu vào thứ Năm, ngày 27 tháng 3 năm 2025**
Bài viết liên quan
 Công bố sửa đổi AI tinh tế nhưng có tác động trong nội dung video đích thực
Vào năm 2019, một video lừa đảo của Nancy Pelosi, sau đó là Chủ tịch Hạ viện Hoa Kỳ, lưu hành rộng rãi. Video, được chỉnh sửa để làm cho cô ấy xuất hiện say sưa, là một lời nhắc nhở rõ ràng về việc phương tiện truyền thông dễ dàng có thể đánh lừa công chúng như thế nào. Mặc dù sự đơn giản của nó, sự cố này đã làm nổi bật t
Openai có kế hoạch đưa máy phát video của Sora đến Chatgpt
OpenAI có kế hoạch tích hợp công cụ tạo video AI của mình, Sora, vào Chatbot tiêu dùng phổ biến của nó, Chatgpt. Điều này đã được tiết lộ bởi các nhà lãnh đạo công ty trong một phiên làm việc gần đây về Discord. Hiện tại, Sora chỉ có thể truy cập thông qua một ứng dụng web chuyên dụng do Openai đưa ra vào tháng 12, cho phép người dùng
Bytedance tham gia thị trường video Deepfake AI
Bytedance, những người đứng sau Tiktok, vừa thể hiện sự sáng tạo AI mới nhất của họ, Omnihuman-1, và nó khá tuyệt vời. Hệ thống mới này có thể đánh bật các video siêu thực tế và tất cả những gì nó cần chỉ là một hình ảnh tham chiếu duy nhất và một số âm thanh. Điều tuyệt vời là bạn có thể điều chỉnh tỷ lệ khung hình của video và
Nhận xét (1)
0/200
Công bố sửa đổi AI tinh tế nhưng có tác động trong nội dung video đích thực
Vào năm 2019, một video lừa đảo của Nancy Pelosi, sau đó là Chủ tịch Hạ viện Hoa Kỳ, lưu hành rộng rãi. Video, được chỉnh sửa để làm cho cô ấy xuất hiện say sưa, là một lời nhắc nhở rõ ràng về việc phương tiện truyền thông dễ dàng có thể đánh lừa công chúng như thế nào. Mặc dù sự đơn giản của nó, sự cố này đã làm nổi bật t
Openai có kế hoạch đưa máy phát video của Sora đến Chatgpt
OpenAI có kế hoạch tích hợp công cụ tạo video AI của mình, Sora, vào Chatbot tiêu dùng phổ biến của nó, Chatgpt. Điều này đã được tiết lộ bởi các nhà lãnh đạo công ty trong một phiên làm việc gần đây về Discord. Hiện tại, Sora chỉ có thể truy cập thông qua một ứng dụng web chuyên dụng do Openai đưa ra vào tháng 12, cho phép người dùng
Bytedance tham gia thị trường video Deepfake AI
Bytedance, những người đứng sau Tiktok, vừa thể hiện sự sáng tạo AI mới nhất của họ, Omnihuman-1, và nó khá tuyệt vời. Hệ thống mới này có thể đánh bật các video siêu thực tế và tất cả những gì nó cần chỉ là một hình ảnh tham chiếu duy nhất và một số âm thanh. Điều tuyệt vời là bạn có thể điều chỉnh tỷ lệ khung hình của video và
Nhận xét (1)
0/200
![DonaldLee]() DonaldLee
DonaldLee
 08:20:02 GMT+07:00 Ngày 28 tháng 7 năm 2025
08:20:02 GMT+07:00 Ngày 28 tháng 7 năm 2025
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥


 0
0
Các mô hình nền tảng video như Hunyuan và Wan 2.1 đã đạt được những tiến bộ đáng kể, nhưng chúng thường không đáp ứng được yêu cầu kiểm soát chi tiết trong sản xuất phim và truyền hình, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong các studio VFX chuyên nghiệp, những mô hình này, cùng với các mô hình dựa trên hình ảnh trước đó như Stable Diffusion, Kandinsky và Flux, được sử dụng kết hợp với một bộ công cụ được thiết kế để tinh chỉnh đầu ra nhằm đáp ứng các nhu cầu sáng tạo cụ thể. Khi một đạo diễn yêu cầu điều chỉnh, nói điều gì đó như, "Trông tuyệt vời, nhưng chúng ta có thể làm nó thêm chút [n] không?", chỉ nói rằng mô hình thiếu độ chính xác để thực hiện các điều chỉnh như vậy là không đủ.
Thay vào đó, một đội ngũ AI VFX sẽ sử dụng kết hợp giữa CGI truyền thống và các kỹ thuật tổng hợp, cùng với các quy trình làm việc được phát triển tùy chỉnh, để vượt qua giới hạn của tổng hợp video. Cách tiếp cận này tương tự như sử dụng một trình duyệt web mặc định như Chrome; nó hoạt động ngay từ đầu, nhưng để thực sự tùy chỉnh theo nhu cầu của bạn, bạn sẽ cần cài đặt một số plugin.
Những người kiểm soát chi tiết
Trong lĩnh vực tổng hợp hình ảnh dựa trên khuếch tán, một trong những hệ thống bên thứ ba quan trọng nhất là ControlNet. Kỹ thuật này mang lại khả năng kiểm soát có cấu trúc cho các mô hình tạo sinh, cho phép người dùng định hướng việc tạo hình ảnh hoặc video bằng cách sử dụng các đầu vào bổ sung như bản đồ cạnh, bản đồ độ sâu, hoặc thông tin tư thế.
*Các phương pháp đa dạng của ControlNet cho phép chuyển đổi từ độ sâu sang hình ảnh (hàng trên), phân đoạn ngữ nghĩa sang hình ảnh (dưới bên trái) và tạo hình ảnh định hướng tư thế của con người và động vật (dưới bên trái).*
ControlNet không chỉ dựa vào các gợi ý văn bản; nó sử dụng các nhánh mạng nơ-ron riêng biệt, hoặc bộ điều hợp, để xử lý các tín hiệu điều kiện này trong khi vẫn duy trì khả năng tạo sinh của mô hình cơ bản. Điều này cho phép tạo ra các đầu ra tùy chỉnh cao, phù hợp chặt chẽ với thông số kỹ thuật của người dùng, khiến nó trở nên vô giá đối với các ứng dụng yêu cầu kiểm soát chính xác về bố cục, cấu trúc hoặc chuyển động.
*Với tư thế dẫn đường, nhiều loại đầu ra chính xác có thể được tạo ra thông qua ControlNet.* Nguồn: https://arxiv.org/pdf/2302.05543
Tuy nhiên, các hệ thống dựa trên bộ điều hợp, hoạt động bên ngoài trên một tập hợp các quá trình nơ-ron tập trung nội bộ, đi kèm với một số nhược điểm. Các bộ điều hợp được huấn luyện độc lập, có thể dẫn đến xung đột nhánh khi nhiều bộ điều hợp được kết hợp, thường dẫn đến chất lượng tạo sinh thấp hơn. Chúng cũng gây ra dư thừa tham số, yêu cầu thêm tài nguyên tính toán và bộ nhớ cho mỗi bộ điều hợp, khiến việc mở rộng trở nên kém hiệu quả. Hơn nữa, mặc dù linh hoạt, các bộ điều hợp thường cho kết quả không tối ưu so với các mô hình được tinh chỉnh hoàn toàn cho việc tạo sinh đa điều kiện. Những vấn đề này có thể khiến các phương pháp dựa trên bộ điều hợp kém hiệu quả đối với các nhiệm vụ yêu cầu tích hợp liền mạch nhiều tín hiệu kiểm soát.
Lý tưởng nhất, các khả năng của ControlNet sẽ được tích hợp nguyên bản vào mô hình theo cách mô-đun, cho phép các đổi mới trong tương lai như tạo video/âm thanh đồng thời hoặc khả năng đồng bộ môi tự nhiên. Hiện tại, mỗi tính năng bổ sung hoặc trở thành một nhiệm vụ hậu kỳ hoặc một quy trình không nguyên bản phải điều hướng các trọng số nhạy cảm của mô hình nền tảng.
FullDiT
Giới thiệu FullDiT, một cách tiếp cận mới từ Trung Quốc tích hợp các tính năng kiểu ControlNet trực tiếp vào một mô hình video tạo sinh trong quá trình huấn luyện, thay vì coi chúng như một suy nghĩ sau cùng.
*Từ bài báo mới: cách tiếp cận FullDiT có thể tích hợp áp đặt danh tính, độ sâu và chuyển động máy quay vào một quá trình tạo sinh nguyên bản, và có thể gọi ra bất kỳ sự kết hợp nào của những yếu tố này cùng một lúc.* Nguồn: https://arxiv.org/pdf/2503.19907
FullDiT, như được nêu trong bài báo có tiêu đề **FullDiT: Mô hình nền tảng tạo sinh video đa nhiệm với sự chú ý đầy đủ**, tích hợp các điều kiện đa nhiệm như chuyển giao danh tính, lập bản đồ độ sâu, và chuyển động máy quay vào lõi của một mô hình video tạo sinh đã được huấn luyện. Các tác giả đã phát triển một mô hình nguyên mẫu và các đoạn video đi kèm có sẵn tại một trang web dự án.
**Nhấp để phát. Ví dụ về áp đặt người dùng kiểu ControlNet chỉ với một mô hình nền tảng được huấn luyện nguyên bản.** Nguồn: https://fulldit.github.io/
Các tác giả giới thiệu FullDiT như một bằng chứng khái niệm cho các mô hình văn bản sang video (T2V) và hình ảnh sang video (I2V) cung cấp cho người dùng nhiều quyền kiểm soát hơn chỉ một gợi ý hình ảnh hoặc văn bản. Vì không có mô hình tương tự nào tồn tại, các nhà nghiên cứu đã tạo ra một chuẩn mực mới gọi là **FullBench** để đánh giá các video đa nhiệm, tuyên bố đạt hiệu suất tiên tiến trong các bài kiểm tra do họ thiết kế. Tuy nhiên, tính khách quan của FullBench, do chính các tác giả thiết kế, vẫn chưa được kiểm chứng, và bộ dữ liệu gồm 1.400 trường hợp có thể quá hạn chế để đưa ra kết luận rộng hơn.
Khía cạnh hấp dẫn nhất của kiến trúc FullDiT là tiềm năng tích hợp các loại kiểm soát mới. Các tác giả lưu ý:
**‘Trong nghiên cứu này, chúng tôi chỉ khám phá các điều kiện kiểm soát của máy quay, danh tính và thông tin độ sâu. Chúng tôi chưa nghiên cứu thêm các điều kiện và phương thức khác như âm thanh, giọng nói, đám mây điểm, hộp giới hạn đối tượng, luồng quang học, v.v. Mặc dù thiết kế của FullDiT có thể tích hợp liền mạch các phương thức khác với sự thay đổi kiến trúc tối thiểu, làm thế nào để nhanh chóng và hiệu quả về chi phí điều chỉnh các mô hình hiện có cho các điều kiện và phương thức mới vẫn là một câu hỏi quan trọng cần được khám phá thêm.'**
Mặc dù FullDiT đại diện cho một bước tiến trong việc tạo video đa nhiệm, nó được xây dựng dựa trên các kiến trúc hiện có thay vì giới thiệu một mô hình hoàn toàn mới. Tuy nhiên, nó nổi bật như là mô hình nền tảng video duy nhất với các tính năng kiểu ControlNet được tích hợp nguyên bản, và kiến trúc của nó được thiết kế để phù hợp với các đổi mới trong tương lai.
**Nhấp để phát. Ví dụ về các chuyển động máy quay do người dùng kiểm soát, từ trang web dự án.**
Bài báo, được viết bởi chín nhà nghiên cứu từ Kuaishou Technology và Đại học Hồng Kông Trung Quốc, có tiêu đề **FullDiT: Mô hình nền tảng tạo sinh video đa nhiệm với sự chú ý đầy đủ**. Trang dự án và dữ liệu chuẩn mực mới có sẵn tại Hugging Face.
Phương pháp
Cơ chế chú ý thống nhất của FullDiT được thiết kế để nâng cao khả năng học biểu diễn đa phương thức bằng cách nắm bắt cả mối quan hệ không gian và thời gian giữa các điều kiện.
*Theo bài báo mới, FullDiT tích hợp nhiều điều kiện đầu vào thông qua sự chú ý tự đầy đủ, chuyển đổi chúng thành một chuỗi thống nhất. Ngược lại, các mô hình dựa trên bộ điều hợp (bên trái nhất ở trên) sử dụng các mô-đun riêng biệt cho mỗi đầu vào, dẫn đến dư thừa, xung đột và hiệu suất yếu hơn.*
Không giống như các thiết lập dựa trên bộ điều hợp xử lý từng luồng đầu vào riêng biệt, cấu trúc chú ý chia sẻ của FullDiT tránh xung đột nhánh và giảm chi phí tham số. Các tác giả tuyên bố rằng kiến trúc này có thể mở rộng cho các loại đầu vào mới mà không cần thiết kế lại lớn và rằng lược đồ mô hình cho thấy dấu hiệu khái quát hóa cho các tổ hợp điều kiện chưa thấy trong quá trình huấn luyện, chẳng hạn như liên kết chuyển động máy quay với danh tính nhân vật.
**Nhấp để phát. Ví dụ về tạo danh tính từ trang web dự án.**
Trong kiến trúc của FullDiT, tất cả các đầu vào điều kiện—như văn bản, chuyển động máy quay, danh tính và độ sâu—đầu tiên được chuyển đổi thành định dạng token thống nhất. Các token này sau đó được nối thành một chuỗi dài duy nhất, được xử lý qua một chồng các lớp transformer sử dụng sự chú ý tự đầy đủ. Cách tiếp cận này tuân theo các công trình trước như Open-Sora Plan và Movie Gen.
Thiết kế này cho phép mô hình học các mối quan hệ thời gian và không gian đồng thời trên tất cả các điều kiện. Mỗi khối transformer hoạt động trên toàn bộ chuỗi, cho phép tương tác động giữa các phương thức mà không phụ thuộc vào các mô-đun riêng biệt cho mỗi đầu vào. Kiến trúc được thiết kế để có thể mở rộng, giúp dễ dàng tích hợp các tín hiệu kiểm soát bổ sung trong tương lai mà không cần thay đổi cấu trúc lớn.
Sức mạnh của ba
FullDiT chuyển đổi mỗi tín hiệu kiểm soát thành định dạng token chuẩn hóa để tất cả các điều kiện có thể được xử lý cùng nhau trong một khung chú ý thống nhất. Đối với chuyển động máy quay, mô hình mã hóa một chuỗi các tham số ngoại tại—như vị trí và hướng—cho mỗi khung hình. Các tham số này được gắn dấu thời gian và chiếu vào các vector nhúng phản ánh bản chất thời gian của tín hiệu.
Thông tin danh tính được xử lý khác nhau, vì nó vốn là không gian hơn là thời gian. Mô hình sử dụng bản đồ danh tính chỉ ra nhân vật nào xuất hiện ở phần nào của mỗi khung hình. Các bản đồ này được chia thành các mảnh, với mỗi mảnh được chiếu vào một nhúng nắm bắt các tín hiệu danh tính không gian, cho phép mô hình liên kết các vùng cụ thể của khung hình với các thực thể cụ thể.
Độ sâu là một tín hiệu không thời gian, và mô hình xử lý nó bằng cách chia các video độ sâu thành các mảnh 3D trải dài cả không gian và thời gian. Các mảnh này sau đó được nhúng theo cách bảo toàn cấu trúc của chúng qua các khung hình.
Khi đã được nhúng, tất cả các token điều kiện (máy quay, danh tính và độ sâu) được nối thành một chuỗi dài duy nhất, cho phép FullDiT xử lý chúng cùng nhau bằng sự chú ý tự đầy đủ. Biểu diễn chia sẻ này cho phép mô hình học các tương tác giữa các phương thức và qua thời gian mà không phụ thuộc vào các luồng xử lý riêng biệt.
Dữ liệu và Kiểm tra
Cách tiếp cận huấn luyện của FullDiT dựa trên các bộ dữ liệu được chú thích có chọn lọc phù hợp với từng loại điều kiện, thay vì yêu cầu tất cả các điều kiện phải có mặt đồng thời.
Đối với các điều kiện văn bản, sáng kiến này tuân theo cách tiếp cận chú thích có cấu trúc được nêu trong dự án MiraData.
*Quy trình thu thập và chú thích video từ dự án MiraData.* Nguồn: https://arxiv.org/pdf/2407.06358
Đối với chuyển động máy quay, bộ dữ liệu RealEstate10K là nguồn dữ liệu chính, do các chú thích ground-truth chất lượng cao của nó về các tham số máy quay. Tuy nhiên, các tác giả nhận thấy rằng việc huấn luyện chỉ trên các bộ dữ liệu máy quay cảnh tĩnh như RealEstate10K có xu hướng làm giảm chuyển động của các đối tượng động và con người trong các video được tạo ra. Để khắc phục điều này, họ đã tiến hành tinh chỉnh bổ sung bằng các bộ dữ liệu nội bộ bao gồm nhiều chuyển động máy quay động hơn.
Các chú thích danh tính được tạo ra bằng quy trình phát triển cho dự án ConceptMaster, cho phép lọc và trích xuất thông tin danh tính chi tiết một cách hiệu quả.
*Khung ConceptMaster được thiết kế để giải quyết các vấn đề tách biệt danh tính trong khi bảo toàn tính trung thực của khái niệm trong các video tùy chỉnh.* Nguồn: https://arxiv.org/pdf/2501.04698
Các chú thích độ sâu được lấy từ bộ dữ liệu Panda-70M bằng cách sử dụng Depth Anything.
Tối ưu hóa thông qua sắp xếp dữ liệu
Các tác giả cũng triển khai một lịch trình huấn luyện tiến bộ, đưa các điều kiện khó hơn vào sớm trong quá trình huấn luyện để đảm bảo mô hình đạt được các biểu diễn mạnh mẽ trước khi các nhiệm vụ đơn giản hơn được thêm vào. Thứ tự huấn luyện tiến hành từ văn bản đến các điều kiện máy quay, sau đó là danh tính, và cuối cùng là độ sâu, với các nhiệm vụ dễ hơn thường được giới thiệu muộn hơn và với ít ví dụ hơn.
Các tác giả nhấn mạnh giá trị của việc sắp xếp khối lượng công việc theo cách này:
**‘Trong giai đoạn huấn luyện trước, chúng tôi nhận thấy rằng các nhiệm vụ khó hơn đòi hỏi thời gian huấn luyện kéo dài và nên được giới thiệu sớm hơn trong quá trình học. Những nhiệm vụ khó khăn này liên quan đến các phân phối dữ liệu phức tạp khác biệt đáng kể so với video đầu ra, đòi hỏi mô hình phải có đủ khả năng để nắm bắt và biểu diễn chúng một cách chính xác.**
**‘Ngược lại, việc giới thiệu các nhiệm vụ dễ hơn quá sớm có thể khiến mô hình ưu tiên học chúng trước, vì chúng cung cấp phản hồi tối ưu hóa ngay lập tức, làm cản trở sự hội tụ của các nhiệm vụ khó hơn.'**
*Hình minh họa về thứ tự huấn luyện dữ liệu được các nhà nghiên cứu áp dụng, với màu đỏ biểu thị khối lượng dữ liệu lớn hơn.*
Sau giai đoạn huấn luyện trước ban đầu, một giai đoạn tinh chỉnh cuối cùng đã tiếp tục tinh chỉnh mô hình để cải thiện chất lượng hình ảnh và động lực chuyển động. Sau đó, quá trình huấn luyện tuân theo khung khuếch tán tiêu chuẩn: nhiễu được thêm vào các ẩn video, và mô hình học cách dự đoán và loại bỏ nó, sử dụng các token điều kiện nhúng làm hướng dẫn.
Để đánh giá hiệu quả FullDiT và cung cấp sự so sánh công bằng với các phương pháp hiện có, và trong điều kiện không có chuẩn mực phù hợp nào khác, các tác giả đã giới thiệu **FullBench**, một bộ chuẩn mực được chọn lọc gồm 1.400 trường hợp kiểm tra riêng biệt.
*Một phiên bản trình khám phá dữ liệu cho chuẩn mực FullBench mới.* Nguồn: https://huggingface.co/datasets/KwaiVGI/FullBench
Mỗi điểm dữ liệu cung cấp các chú thích ground-truth cho các tín hiệu điều kiện khác nhau, bao gồm chuyển động máy quay, danh tính và độ sâu.
Số liệu
Các tác giả đã đánh giá FullDiT bằng mười số liệu bao gồm năm khía cạnh hiệu suất chính: căn chỉnh văn bản, kiểm soát máy quay, độ tương đồng danh tính, độ chính xác độ sâu và chất lượng video tổng quát.
Căn chỉnh văn bản được đo bằng độ tương đồng CLIP, trong khi kiểm soát máy quay được đánh giá qua lỗi xoay (RotErr), lỗi dịch chuyển (TransErr), và tính nhất quán chuyển động máy quay (CamMC), theo cách tiếp cận của CamI2V (trong dự án CameraCtrl).
Độ tương đồng danh tính được đánh giá bằng DINO-I và CLIP-I, và độ chính xác kiểm soát độ sâu được định lượng bằng Sai số Tuyệt đối Trung bình (MAE).
Chất lượng video được đánh giá bằng ba số liệu từ MiraData: độ tương đồng CLIP cấp khung hình cho độ mượt mà; khoảng cách chuyển động dựa trên luồng quang học cho động lực; và điểm thẩm mỹ LAION-Aesthetic cho sức hấp dẫn hình ảnh.
Huấn luyện
Các tác giả đã huấn luyện FullDiT bằng một mô hình khuếch tán văn bản sang video nội bộ (không được tiết lộ) chứa khoảng một tỷ tham số. Họ cố ý chọn kích thước tham số khiêm tốn để duy trì sự công bằng trong so sánh với các phương pháp trước đó và đảm bảo khả năng tái tạo.
Vì các video huấn luyện khác nhau về độ dài và độ phân giải, các tác giả đã chuẩn hóa mỗi lô bằng cách thay đổi kích thước và đệm các video thành một độ phân giải chung, lấy mẫu 77 khung hình cho mỗi chuỗi, và sử dụng các mặt nạ chú ý và tổn thất được áp dụng để tối ưu hóa hiệu quả huấn luyện.
Trình tối ưu hóa Adam được sử dụng với tốc độ học 1×10−5 trên một cụm 64 GPU NVIDIA H800, với tổng cộng 5.120GB VRAM (hãy xem xét rằng trong các cộng đồng tổng hợp đam mê, 24GB trên RTX 3090 vẫn được coi là tiêu chuẩn xa xỉ).
Mô hình được huấn luyện trong khoảng 32.000 bước, kết hợp tối đa ba danh tính cho mỗi video, cùng với 20 khung hình điều kiện máy quay và 21 khung hình điều kiện độ sâu, cả hai được lấy mẫu đều từ tổng số 77 khung hình.
Đối với suy luận, mô hình tạo ra các video ở độ phân giải 384×672 pixel (khoảng năm giây ở 15 khung hình mỗi giây) với 50 bước suy luận khuếch tán và thang hướng dẫn không phân loại là năm.
Các phương pháp trước
Đối với đánh giá từ máy quay sang video, các tác giả đã so sánh FullDiT với MotionCtrl, CameraCtrl và CamI2V, với tất cả các mô hình được huấn luyện bằng bộ dữ liệu RealEstate10k để đảm bảo tính nhất quán và công bằng.
Trong việc tạo sinh điều kiện danh tính, vì không có mô hình đa danh tính mã nguồn mở tương đương nào, mô hình được chuẩn hóa so với mô hình ConceptMaster 1B tham số, sử dụng cùng dữ liệu huấn luyện và kiến trúc.
Đối với các nhiệm vụ từ độ sâu sang video, các so sánh được thực hiện với Ctrl-Adapter và ControlVideo.
*Kết quả định lượng cho việc tạo video đơn nhiệm. FullDiT được so sánh với MotionCtrl, CameraCtrl và CamI2V cho việc tạo từ máy quay sang video; ConceptMaster (phiên bản 1B tham số) cho việc tạo từ danh tính sang video; và Ctrl-Adapter và ControlVideo cho việc tạo từ độ sâu sang video. Tất cả các mô hình được đánh giá bằng cài đặt mặc định của chúng. Để đảm bảo tính nhất quán, 16 khung hình được lấy mẫu đều từ mỗi phương pháp, phù hợp với độ dài đầu ra của các mô hình trước đó.*
Kết quả cho thấy FullDiT, mặc dù xử lý nhiều tín hiệu điều kiện đồng thời, đã đạt được hiệu suất tiên tiến trong các số liệu liên quan đến văn bản, chuyển động máy quay, danh tính và kiểm soát độ sâu.
Trong các số liệu chất lượng tổng thể, hệ thống thường vượt trội hơn các phương pháp khác, mặc dù độ mượt mà của nó thấp hơn một chút so với ConceptMaster. Ở đây, các tác giả nhận xét:
**‘Độ mượt mà của FullDiT thấp hơn một chút so với ConceptMaster vì việc tính toán độ mượt mà dựa trên độ tương đồng CLIP giữa các khung hình liền kề. Vì FullDiT thể hiện động lực lớn hơn đáng kể so với ConceptMaster, số liệu độ mượt mà bị ảnh hưởng bởi các biến đổi lớn giữa các khung hình liền kề.**
**‘Đối với điểm thẩm mỹ, vì mô hình đánh giá ưu tiên các hình ảnh theo phong cách hội họa và ControlVideo thường tạo ra các video theo phong cách này, nó đạt được điểm cao về thẩm mỹ.'**
Về so sánh định tính, có lẽ nên tham khảo các video mẫu tại trang web dự án FullDiT, vì các ví dụ trong PDF không thể tránh khỏi là tĩnh (và cũng quá lớn để tái tạo toàn bộ ở đây).
*Phần đầu tiên của kết quả định tính được tái tạo trong PDF. Vui lòng tham khảo bài báo nguồn để xem các ví dụ bổ sung, quá rộng để tái tạo ở đây.*
Các tác giả nhận xét:
**‘FullDiT thể hiện khả năng bảo toàn danh tính vượt trội và tạo ra các video với động lực và chất lượng hình ảnh tốt hơn so với [ConceptMaster]. Vì ConceptMaster và FullDiT được huấn luyện trên cùng một nền tảng, điều này làm nổi bật hiệu quả của việc tiêm điều kiện với sự chú ý đầy đủ.**
**‘…Các kết quả [khác] thể hiện khả năng kiểm soát và chất lượng tạo sinh vượt trội của FullDiT so với các phương pháp từ độ sâu sang video và từ máy quay sang video hiện có.'**
*Một phần của các ví dụ trong PDF về đầu ra của FullDiT với nhiều tín hiệu. Vui lòng tham khảo bài báo nguồn và trang web dự án để xem các ví dụ bổ sung.*
Kết luận
FullDiT đại diện cho một bước tiến thú vị hướng tới một mô hình nền tảng video toàn diện hơn, nhưng câu hỏi vẫn là liệu nhu cầu về các tính năng kiểu ControlNet có đủ để biện minh cho việc triển khai chúng ở quy mô lớn, đặc biệt đối với các dự án mã nguồn mở. Những dự án này sẽ phải vật lộn để có được sức mạnh xử lý GPU rộng lớn cần thiết nếu không có sự hỗ trợ thương mại.
Thách thức chính là việc sử dụng các hệ thống như Độ sâu và Tư thế thường đòi hỏi sự quen thuộc không tầm thường với các giao diện người dùng phức tạp như ComfyUI. Do đó, một mô hình mã nguồn mở hoạt động của loại này rất có thể được phát triển bởi các công ty VFX nhỏ hơn thiếu nguồn lực hoặc động lực để tự quản lý và huấn luyện một mô hình như vậy.
Mặt khác, các hệ thống 'thuê AI' dựa trên API có thể được thúc đẩy mạnh mẽ để phát triển các phương pháp diễn giải đơn giản và thân thiện hơn với người dùng cho các mô hình với các hệ thống kiểm soát phụ trợ được huấn luyện trực tiếp.
**Nhấp để phát. Kiểm soát Độ sâu+Văn bản được áp đặt lên một quá trình tạo video bằng FullDiT.**
*Các tác giả không chỉ định bất kỳ mô hình cơ bản nào đã biết (tức là, SDXL, v.v.)*
**Được xuất bản lần đầu vào thứ Năm, ngày 27 tháng 3 năm 2025**










 Công bố sửa đổi AI tinh tế nhưng có tác động trong nội dung video đích thực
Vào năm 2019, một video lừa đảo của Nancy Pelosi, sau đó là Chủ tịch Hạ viện Hoa Kỳ, lưu hành rộng rãi. Video, được chỉnh sửa để làm cho cô ấy xuất hiện say sưa, là một lời nhắc nhở rõ ràng về việc phương tiện truyền thông dễ dàng có thể đánh lừa công chúng như thế nào. Mặc dù sự đơn giản của nó, sự cố này đã làm nổi bật t
Công bố sửa đổi AI tinh tế nhưng có tác động trong nội dung video đích thực
Vào năm 2019, một video lừa đảo của Nancy Pelosi, sau đó là Chủ tịch Hạ viện Hoa Kỳ, lưu hành rộng rãi. Video, được chỉnh sửa để làm cho cô ấy xuất hiện say sưa, là một lời nhắc nhở rõ ràng về việc phương tiện truyền thông dễ dàng có thể đánh lừa công chúng như thế nào. Mặc dù sự đơn giản của nó, sự cố này đã làm nổi bật t
 Openai có kế hoạch đưa máy phát video của Sora đến Chatgpt
OpenAI có kế hoạch tích hợp công cụ tạo video AI của mình, Sora, vào Chatbot tiêu dùng phổ biến của nó, Chatgpt. Điều này đã được tiết lộ bởi các nhà lãnh đạo công ty trong một phiên làm việc gần đây về Discord. Hiện tại, Sora chỉ có thể truy cập thông qua một ứng dụng web chuyên dụng do Openai đưa ra vào tháng 12, cho phép người dùng
Openai có kế hoạch đưa máy phát video của Sora đến Chatgpt
OpenAI có kế hoạch tích hợp công cụ tạo video AI của mình, Sora, vào Chatbot tiêu dùng phổ biến của nó, Chatgpt. Điều này đã được tiết lộ bởi các nhà lãnh đạo công ty trong một phiên làm việc gần đây về Discord. Hiện tại, Sora chỉ có thể truy cập thông qua một ứng dụng web chuyên dụng do Openai đưa ra vào tháng 12, cho phép người dùng
 Bytedance tham gia thị trường video Deepfake AI
Bytedance, những người đứng sau Tiktok, vừa thể hiện sự sáng tạo AI mới nhất của họ, Omnihuman-1, và nó khá tuyệt vời. Hệ thống mới này có thể đánh bật các video siêu thực tế và tất cả những gì nó cần chỉ là một hình ảnh tham chiếu duy nhất và một số âm thanh. Điều tuyệt vời là bạn có thể điều chỉnh tỷ lệ khung hình của video và
08:20:02 GMT+07:00 Ngày 28 tháng 7 năm 2025
Bytedance tham gia thị trường video Deepfake AI
Bytedance, những người đứng sau Tiktok, vừa thể hiện sự sáng tạo AI mới nhất của họ, Omnihuman-1, và nó khá tuyệt vời. Hệ thống mới này có thể đánh bật các video siêu thực tế và tất cả những gì nó cần chỉ là một hình ảnh tham chiếu duy nhất và một số âm thanh. Điều tuyệt vời là bạn có thể điều chỉnh tỷ lệ khung hình của video và
08:20:02 GMT+07:00 Ngày 28 tháng 7 năm 2025
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0













