
















 집
집AI 비디오 생성은 완전한 제어로 이동합니다
비디오 기반 모델인 훈위안(Hunyuan)과 완 2.1(Wan 2.1)은 상당한 발전을 이루었지만, 영화 및 TV 제작에서 요구되는 세밀한 제어, 특히 시각 효과(VFX) 분야에서는 종종 부족함을 드러냅니다. 전문 VFX 스튜디오에서는 이러한 모델과 함께 스테이블 디퓨전(Stable Diffusion), 칸딘스키(Kandinsky), 플럭스(Flux)와 같은 초기 이미지 기반 모델을 사용하여 특정 창의적 요구를 충족하도록 출력을 정제하는 도구 세트를 활용합니다. 감독이 “멋지게 보이는데, 조금 더 [n]하게 만들어 줄 수 있나요?”라고 요청할 때, 모델이 그러한 조정을 위한 정밀도를 부족하다고 단순히 말하는 것만으로는 충분하지 않습니다.
대신, AI VFX 팀은 전통적인 CGI와 구성 기술을 조합하고, 맞춤 개발된 워크플로우를 사용하여 비디오 합성의 경계를 더욱 확장합니다. 이 접근 방식은 크롬(Chrome)과 같은 기본 웹 브라우저를 사용하는 것과 유사합니다. 기본적으로 기능적이지만, 진정으로 필요에 맞게 조정하려면 몇 가지 플러그인을 설치해야 합니다.
컨트롤 프릭스
확산 기반 이미지 합성 분야에서 가장 중요한 제3자 시스템 중 하나는 컨트롤넷(ControlNet)입니다. 이 기술은 생성 모델에 구조적 제어를 도입하여 사용자가 엣지 맵, 깊이 맵, 또는 포즈 정보와 같은 추가 입력을 사용하여 이미지나 비디오 생성을 안내할 수 있게 합니다.
 *컨트롤넷의 다양한 방법은 깊이>이미지(상단 행), 의미적 분할>이미지(하단 좌측), 그리고 인간과 동물의 포즈 기반 이미지 생성(하단 좌측)을 가능하게 합니다.*
*컨트롤넷의 다양한 방법은 깊이>이미지(상단 행), 의미적 분할>이미지(하단 좌측), 그리고 인간과 동물의 포즈 기반 이미지 생성(하단 좌측)을 가능하게 합니다.*
컨트롤넷은 텍스트 프롬프트에만 의존하지 않습니다. 별도의 신경망 브랜치 또는 어댑터를 사용하여 이러한 조건 신호를 처리하면서 기본 모델의 생성 능력을 유지합니다. 이를 통해 사용자의 사양에 밀접하게 맞춘 고도로 맞춤화된 출력을 가능하게 하며, 구성, 구조, 또는 모션에 대한 정밀한 제어가 필요한 응용 분야에서 매우 유용합니다.
 *안내 포즈를 사용하면 컨트롤넷을 통해 다양한 정확한 출력 유형을 얻을 수 있습니다.* Source: https://arxiv.org/pdf/2302.05543
*안내 포즈를 사용하면 컨트롤넷을 통해 다양한 정확한 출력 유형을 얻을 수 있습니다.* Source: https://arxiv.org/pdf/2302.05543
그러나 내부에 초점을 맞춘 신경망 프로세스 집합에서 외부적으로 작동하는 이러한 어댑터 기반 시스템에는 몇 가지 단점이 있습니다. 어댑터는 독립적으로 훈련되므로 여러 어댑터를 결합할 때 브랜치 충돌이 발생하여 생성 품질이 저하될 수 있습니다. 또한 각 어댑터마다 추가적인 계산 자원과 메모리가 필요하여 매개변수 중복을 초래하고, 확장이 비효율적입니다. 더욱이, 유연성에도 불구하고 어댑터는 다중 조건 생성을 위해 완전히 미세 조정된 모델에 비해 종종 최적이 아닌 결과를 산출합니다. 이러한 문제로 인해 다중 제어 신호의 원활한 통합이 필요한 작업에서 어댑터 기반 방법은 덜 효과적일 수 있습니다.
이상적으로, 컨트롤넷의 기능은 모듈 방식으로 모델에 기본적으로 통합되어 동시 비디오/오디오 생성이나 기본 립싱크 기능과 같은 미래 혁신을 가능하게 해야 합니다. 현재는 각 추가 기능이 후반 작업이 되거나, 기본 모델의 민감한 가중치를 조정해야 하는 비기본 절차가 됩니다.
FullDiT
중국에서 개발된 새로운 접근 방식인 FullDiT는 컨트롤넷 스타일의 기능을 사후 처리로 취급하지 않고 훈련 중에 생성 비디오 모델에 직접 통합합니다.
 *새 논문에 따르면, FullDiT 접근 방식은 신원 부여, 깊이, 카메라 움직임을 기본 생성에 통합할 수 있으며, 이들을 동시에 조합하여 호출할 수 있습니다.* Source: https://arxiv.org/pdf/2503.19907
*새 논문에 따르면, FullDiT 접근 방식은 신원 부여, 깊이, 카메라 움직임을 기본 생성에 통합할 수 있으며, 이들을 동시에 조합하여 호출할 수 있습니다.* Source: https://arxiv.org/pdf/2503.19907
**FullDiT: 다중 작업 비디오 생성 기반 모델과 완전 주의**라는 제목의 논문에 설명된 FullDiT는 신원 전송, 깊이 매핑, 카메라 움직임과 같은 다중 작업 조건을 훈련된 생성 비디오 모델의 핵심에 통합합니다. 저자들은 프로토타입 모델과 프로젝트 사이트에서 제공되는 동반 비디오 클립을 개발했습니다.
**재생하려면 클릭하세요. 기본 훈련된 기반 모델만으로 컨트롤넷 스타일의 사용자 부여 사례.** Source: https://fulldit.github.io/
저자들은 FullDiT를 이미지 또는 텍스트 프롬프트 이상의 제어를 제공하는 텍스트-투-비디오(T2V) 및 이미지-투-비디오(I2V) 모델의 개념 증명으로 제시합니다. 유사한 모델이 존재하지 않으므로 연구자들은 다중 작업 비디오 평가를 위한 새로운 벤치마크인 **FullBench**를 만들었으며, 그들이 고안한 테스트에서 최첨단 성능을 달성했다고 주장합니다. 그러나 저자들이 설계한 FullBench의 객관성은 아직 검증되지 않았으며, 1,400개의 사례로 구성된 데이터셋은 더 광범위한 결론을 내리기에는 너무 제한적일 수 있습니다.
FullDiT 아키텍처의 가장 흥미로운 측면은 새로운 제어 유형을 통합할 가능성입니다. 저자들은 다음과 같이 언급합니다:
**‘이 연구에서는 카메라, 신원, 깊이 정보만을 제어 조건으로 탐구했습니다. 오디오, 음성, 포인트 클라우드, 객체 경계 상자, 광학 흐름 등 다른 조건과 모달리티는 추가로 조사하지 않았습니다. FullDiT의 설계는 최소한의 아키텍처 수정으로 다른 모달리티를 원활히 통합할 수 있지만, 기존 모델을 새로운 조건과 모달리티에 빠르고 비용 효율적으로 적응시키는 방법은 여전히 중요한 질문으로, 추가 탐구가 필요합니다.’**
FullDiT는 다중 작업 비디오 생성에서 한 걸음 나아간 발전을 나타내지만, 기존 아키텍처를 기반으로 하여 새로운 패러다임을 도입하지는 않습니다. 그럼에도 불구하고, 컨트롤넷 스타일 기능을 기본적으로 통합한 유일한 비디오 기반 모델로 돋보이며, 그 아키텍처는 미래 혁신을 수용하도록 설계되었습니다.
**재생하려면 클릭하세요. 프로젝트 사이트에서 제공하는 사용자 제어 카메라 움직임 사례.**
이 논문은 Kuaishou Technology와 홍콩중문대학의 9명의 연구자가 작성했으며, 제목은 **FullDiT: 다중 작업 비디오 생성 기반 모델과 완전 주의**입니다. 프로젝트 페이지와 새로운 벤치마크 데이터는 Hugging Face에서 확인할 수 있습니다.
방법
FullDiT의 통합 주의 메커니즘은 조건 간의 공간적 및 시간적 관계를 포착하여 교차 모달 표현 학습을 향상시키도록 설계되었습니다.
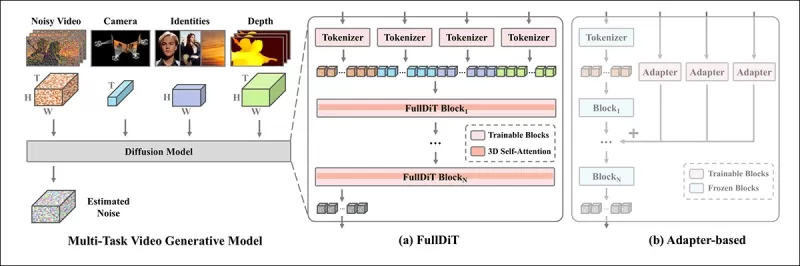 *새 논문에 따르면, FullDiT는 완전 자가 주의를 통해 다중 입력 조건을 통합하여 단일 시퀀스로 변환합니다. 반면, 어댑터 기반 모델(가장 왼쪽 위)은 각 입력에 대해 별도의 모듈을 사용하여 중복, 충돌, 그리고 더 약한 성능을 초래합니다.*
*새 논문에 따르면, FullDiT는 완전 자가 주의를 통해 다중 입력 조건을 통합하여 단일 시퀀스로 변환합니다. 반면, 어댑터 기반 모델(가장 왼쪽 위)은 각 입력에 대해 별도의 모듈을 사용하여 중복, 충돌, 그리고 더 약한 성능을 초래합니다.*
각 입력 스트림을 별도로 처리하는 어댑터 기반 설정과 달리, FullDiT의 공유 주의 구조는 브랜치 충돌을 피하고 매개변수 오버헤드를 줄입니다. 저자들은 이 아키텍처가 주요 재설계 없이 새로운 입력 유형으로 확장 가능하며, 모델 스키마가 훈련 중에 보지 못한 조건 조합(예: 카메라 모션과 캐릭터 신원 연결)에 일반화할 수 있는 조짐을 보인다고 주장합니다.
**재생하려면 클릭하세요. 프로젝트 사이트에서 제공하는 신원 생성 사례.**
FullDiT의 아키텍처에서는 텍스트, 카메라 모션, 신원, 깊이와 같은 모든 조건 입력이 먼저 통합 토큰 형식으로 변환됩니다. 이러한 토큰은 단일 긴 시퀀스로 연결되어 완전 자가 주의를 사용하는 트랜스포머 레이어 스택을 통해 처리됩니다. 이 접근 방식은 Open-Sora Plan 및 Movie Gen과 같은 선행 작업을 따릅니다.
이 설계는 모델이 모든 조건에 걸쳐 시간적 및 공간적 관계를 공동으로 학습할 수 있게 합니다. 각 트랜스포머 블록은 전체 시퀀스에 대해 작동하여, 각 입력에 대해 별도의 모듈에 의존하지 않고 모달리티 간의 동적 상호작용을 가능하게 합니다. 이 아키텍처는 확장 가능하도록 설계되어, 주요 구조적 변경 없이 향후 추가 제어 신호를 통합하기가 더 쉬워집니다.
세 가지의 힘
FullDiT는 각 제어 신호를 표준화된 토큰 형식으로 변환하여 모든 조건이 통합 주의 프레임워크에서 함께 처리될 수 있도록 합니다. 카메라 모션의 경우, 모델은 각 프레임에 대해 위치 및 방향과 같은 외부 매개변수 시퀀스를 인코딩합니다. 이러한 매개변수는 타임스탬프가 지정되고 신호의 시간적 특성을 반영하는 임베딩 벡터로 투영됩니다.
신원 정보는 본질적으로 시간적이지 않고 공간적이기 때문에 다르게 처리됩니다. 모델은 각 프레임의 어떤 부분에 어떤 캐릭터가 존재하는지를 나타내는 신원 맵을 사용합니다. 이러한 맵은 패치로 나뉘며, 각 패치는 공간적 신원 단서를 포착하는 임베딩으로 투영되어 모델이 프레임의 특정 영역을 특정 엔티티와 연관시킬 수 있게 합니다.
깊이는 시공간적 신호로, 모델은 깊이 비디오를 공간과 시간을 아우르는 3D 패치로 나누어 처리합니다. 이러한 패치는 프레임 간 구조를 보존하는 방식으로 임베딩됩니다.
임베딩된 후, 카메라, 신원, 깊이와 같은 모든 조건 토큰은 단일 긴 시퀀스로 연결되어 FullDiT가 완전 자가 주의를 사용하여 함께 처리할 수 있도록 합니다. 이 공유 표현은 모델이 독립된 처리 스트림에 의존하지 않고 모달리티 간 및 시간에 걸친 상호작용을 학습할 수 있게 합니다.
데이터 및 테스트
FullDiT의 훈련 접근 방식은 모든 조건이 동시에 존재해야 하는 대신 각 조건 유형에 맞춘 선택적으로 주석이 달린 데이터셋에 의존했습니다.
텍스트 조건의 경우, MiraData 프로젝트에서 설명된 구조적 캡션 접근 방식을 따릅니다.
 *MiraData 프로젝트의 비디오 수집 및 주석 파이프라인.* Source: https://arxiv.org/pdf/2407.06358
*MiraData 프로젝트의 비디오 수집 및 주석 파이프라인.* Source: https://arxiv.org/pdf/2407.06358
카메라 모션의 경우, 고품질의 카메라 매개변수 주석이 포함된 RealEstate10K 데이터셋이 주요 데이터 소스였습니다. 그러나 저자들은 RealEstate10K와 같은 정적 장면 카메라 데이터셋만으로 훈련하면 생성된 비디오에서 동적 객체 및 인간 움직임이 감소하는 경향이 있음을 관찰했습니다. 이를 해결하기 위해 더 동적인 카메라 모션을 포함한 내부 데이터셋을 사용하여 추가 미세 조정을 수행했습니다.
신원 주석은 ConceptMaster 프로젝트를 위해 개발된 파이프라인을 사용하여 생성되었으며, 이는 세밀한 신원 정보를 효율적으로 필터링하고 추출할 수 있게 했습니다.
 *ConceptMaster 프레임워크는 맞춤형 비디오에서 신원 분리 문제를 해결하면서 개념 충실도를 보존하도록 설계되었습니다.* Source: https://arxiv.org/pdf/2501.04698
*ConceptMaster 프레임워크는 맞춤형 비디오에서 신원 분리 문제를 해결하면서 개념 충실도를 보존하도록 설계되었습니다.* Source: https://arxiv.org/pdf/2501.04698
깊이 주석은 Panda-70M 데이터셋에서 Depth Anything을 사용하여 얻었습니다.
데이터 순서화를 통한 최적화
저자들은 또한 점진적 훈련 일정을 구현하여 더 도전적인 조건을 훈련 초기에 도입함으로써 모델이 더 단순한 작업이 추가되기 전에 견고한 표현을 습득하도록 했습니다. 훈련 순서는 텍스트에서 카메라 조건, 신원, 그리고 마지막으로 깊이로 진행되었으며, 쉬운 작업은 일반적으로 나중에 더 적은 사례로 도입되었습니다.
저자들은 이러한 작업 순서화의 가치를 다음과 같이 강조합니다:
**‘사전 훈련 단계에서, 더 도전적인 작업은 더 긴 훈련 시간을 요구하며 학습 과정 초기에 도입되어야 한다는 점을 확인했습니다. 이러한 도전적인 작업은 출력 비디오와 크게 다른 복잡한 데이터 분포를 포함하며, 모델이 이를 정확히 포착하고 표현할 수 있는 충분한 용량을 필요로 합니다.’**
**‘반대로, 쉬운 작업을 너무 일찍 도입하면 모델이 즉각적인 최적화 피드백을 제공하는 쉬운 작업을 먼저 학습하는 데 우선순위를 두게 되어 더 도전적인 작업의 수렴을 방해할 수 있습니다.’**
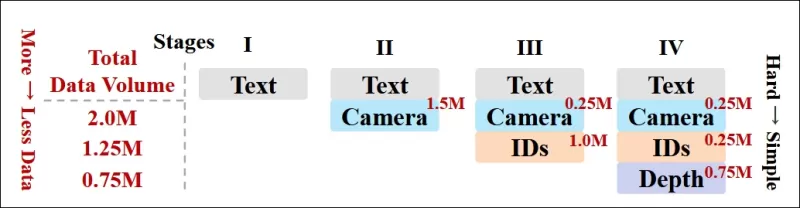 *연구자들이 채택한 데이터 훈련 순서를 보여주는 그림으로, 빨간색은 더 많은 데이터 양을 나타냅니다.*
*연구자들이 채택한 데이터 훈련 순서를 보여주는 그림으로, 빨간색은 더 많은 데이터 양을 나타냅니다.*
초기 사전 훈련 후, 최종 미세 조정 단계에서 시각적 품질과 모션 역학을 개선했습니다. 이후 훈련은 표준 확산 프레임워크를 따랐습니다: 비디오 잠재 변수에 노이즈를 추가하고, 모델이 임베딩된 조건 토큰을 안내로 사용하여 이를 예측하고 제거하도록 학습했습니다.
FullDiT를 효과적으로 평가하고 기존 방법과 공정한 비교를 제공하기 위해, 저자들은 적절한 다른 벤치마크가 없는 상황에서 1,400개의 고유한 테스트 사례로 구성된 선별된 벤치마크 스위트인 **FullBench**를 도입했습니다.
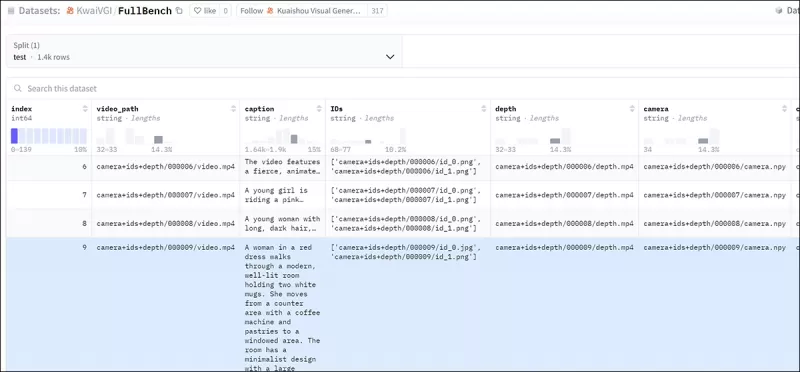 *새로운 FullBench 벤치마크를 위한 데이터 탐색기 인스턴스.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
*새로운 FullBench 벤치마크를 위한 데이터 탐색기 인스턴스.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
각 데이터 포인트는 카메라 모션, 신원, 깊이를 포함한 다양한 조건 신호에 대한 참값 주석을 제공했습니다.
메트릭
저자들은 텍스트 정렬, 카메라 제어, 신원 유사성, 깊이 정확도, 일반 비디오 품질의 다섯 가지 주요 성능 측면을 다루는 10개의 메트릭을 사용하여 FullDiT를 평가했습니다.
텍스트 정렬은 CLIP 유사성을 사용하여 측정되었으며, 카메라 제어는 CameraCtrl 프로젝트의 CamI2V 접근 방식을 따라 회전 오류(RotErr), 변환 오류(TransErr), 카메라 모션 일관성(CamMC)을 통해 평가되었습니다.
신원 유사성은 DINO-I와 CLIP-I를 사용하여 평가되었으며, 깊이 제어 정확도는 평균 절대 오차(MAE)를 사용하여 정량화되었습니다.
비디오 품질은 MiraData의 세 가지 메트릭으로 판단되었습니다: 부드러움을 위한 프레임 수준 CLIP 유사성; 역학을 위한 광학 흐름 기반 모션 거리; 시각적 매력을 위한 LAION-Aesthetic 점수.
훈련
저자들은 약 10억 개의 매개변수를 포함하는 내부(공개되지 않은) 텍스트-투-비디오 확산 모델을 사용하여 FullDiT를 훈련했습니다. 이전 방법과의 비교에서 공정성을 유지하고 재현 가능성을 보장하기 위해 의도적으로 적당한 매개변수 크기를 선택했습니다.
훈련 비디오의 길이와 해상도가 다양했기 때문에, 저자들은 각 배치를 공통 해상도로 크기를 조정하고 패딩하여 표준화했으며, 시퀀스당 77개의 프레임을 샘플링하고 주의 및 손실 마스크를 적용하여 훈련 효과를 최적화했습니다.
Adam 옵티마이저는 64개의 NVIDIA H800 GPU 클러스터에서 1×10−5의 학습률로 사용되었으며, 총 5,120GB의 VRAM을 사용했습니다(매니아 합성 커뮤니티에서는 RTX 3090의 24GB가 여전히 호화로운 표준으로 간주된다는 점을 고려하세요).
모델은 약 32,000단계 동안 훈련되었으며, 비디오당 최대 3개의 신원, 20개의 카메라 조건 프레임, 21개의 깊이 조건 프레임을 포함했으며, 둘 다 총 77개의 프레임에서 균일하게 샘플링되었습니다.
추론을 위해, 모델은 384×672 픽셀 해상도(초당 15프레임으로 약 5초)로 비디오를 생성했으며, 50개의 확산 추론 단계와 5의 분류기 없는 안내 스케일을 사용했습니다.
이전 방법
카메라-투-비디오 평가를 위해, 저자들은 FullDiT를 MotionCtrl, CameraCtrl, CamI2V와 비교했으며, 모든 모델은 일관성과 공정성을 보장하기 위해 RealEstate10k 데이터셋을 사용하여 훈련되었습니다.
신원 조건 생성에서는 비교 가능한 오픈소스 다중 신원 모델이 없었기 때문에, 동일한 훈련 데이터와 아키텍처를 사용하여 1B 매개변수 ConceptMaster 모델과 벤치마킹했습니다.
깊이-투-비디오 작업에서는 Ctrl-Adapter 및 ControlVideo와 비교했습니다.
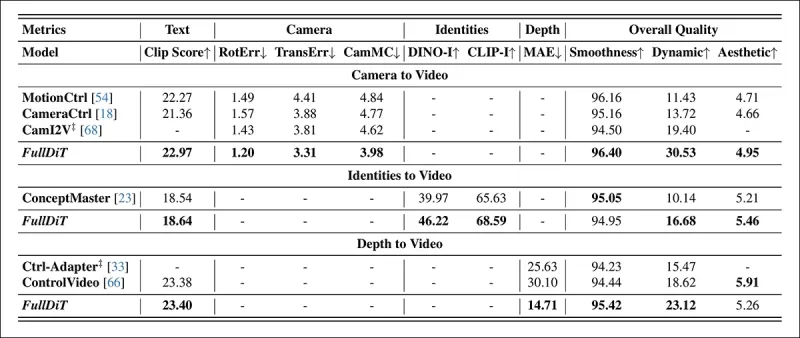 *단일 작업 비디오 생성에 대한 정량적 결과. FullDiT는 카메라-투-비디오 생성에서 MotionCtrl, CameraCtrl, CamI2V와 비교되었으며, 신원-투-비디오에서 ConceptMaster(1B 매개변수 버전), 깊이-투-비디오에서 Ctrl-Adapter 및 ControlVideo와 비교되었습니다. 모든 모델은 기본 설정을 사용하여 평가되었습니다. 일관성을 위해 각 방법에서 16개의 프레임이 균일하게 샘플링되어 이전 모델의 출력 길이와 일치했습니다.*
*단일 작업 비디오 생성에 대한 정량적 결과. FullDiT는 카메라-투-비디오 생성에서 MotionCtrl, CameraCtrl, CamI2V와 비교되었으며, 신원-투-비디오에서 ConceptMaster(1B 매개변수 버전), 깊이-투-비디오에서 Ctrl-Adapter 및 ControlVideo와 비교되었습니다. 모든 모델은 기본 설정을 사용하여 평가되었습니다. 일관성을 위해 각 방법에서 16개의 프레임이 균일하게 샘플링되어 이전 모델의 출력 길이와 일치했습니다.*
결과는 FullDiT가 다중 조건 신호를 동시에 처리함에도 불구하고 텍스트, 카메라 모션, 신원, 깊이 제어와 관련된 메트릭에서 최첨단 성능을 달성했음을 나타냅니다.
전반적인 품질 메트릭에서 이 시스템은 일반적으로 다른 방법들을 능가했지만, 부드러움은 ConceptMaster보다 약간 낮았습니다. 이에 대해 저자들은 다음과 같이 언급합니다:
**‘FullDiT의 부드러움은 인접 프레임 간 CLIP 유사성을 기반으로 계산되기 때문에 ConceptMaster보다 약간 낮습니다. FullDiT는 ConceptMaster에 비해 훨씬 더 큰 역학을 보여주므로, 인접 프레임 간의 큰 변동으로 인해 부드러움 메트릭이 영향을 받습니다.’**
**‘미적 점수에서는 평가 모델이 회화 스타일의 이미지를 선호하며, ControlVideo는 일반적으로 이 스타일의 비디오를 생성하므로 미적 점수에서 높은 점수를 얻습니다.’**
정성적 비교와 관련하여, PDF 예제는 필연적으로 정적이며(여기에서 전체를 재현하기에는 너무 큼) FullDiT 프로젝트 사이트의 샘플 비디오를 참조하는 것이 바람직할 수 있습니다.
 *PDF에서 재현된 정성적 결과의 첫 번째 섹션. 추가 예제는 여기에서 재현하기에는 너무 광범위하므로 소스 논문을 참조하세요.*
*PDF에서 재현된 정성적 결과의 첫 번째 섹션. 추가 예제는 여기에서 재현하기에는 너무 광범위하므로 소스 논문을 참조하세요.*
저자들은 다음과 같이 언급합니다:
**‘FullDiT는 [ConceptMaster]에 비해 우수한 신원 보존을 보여주며, 더 나은 역학과 시각적 품질의 비디오를 생성합니다. ConceptMaster와 FullDiT는 동일한 백본에서 훈련되었기 때문에, 이는 완전 주의를 통한 조건 주입의 효과를 강조합니다.’**
**‘…[다른] 결과는 기존 깊이-투-비디오 및 카메라-투-비디오 방법에 비해 FullDiT의 우수한 제어 가능성과 생성 품질을 보여줍니다.’**
 *PDF의 FullDiT의 다중 신호 출력 예제 섹션. 추가 예제는 소스 논문과 프로젝트 사이트를 참조하세요.*
*PDF의 FullDiT의 다중 신호 출력 예제 섹션. 추가 예제는 소스 논문과 프로젝트 사이트를 참조하세요.*
결론
FullDiT는 더 포괄적인 비디오 기반 모델로 나아가는 흥미로운 단계를 나타냅니다. 그러나 컨트롤넷 스타일 기능에 대한 수요가 특히 오픈소스 프로젝트에서 대규모 구현을 정당화하는지는 여전히 의문입니다. 이러한 프로젝트는 상업적 지원 없이 필요한 방대한 GPU 처리 능력을 확보하는 데 어려움을 겪을 것입니다.
주요 과제는 깊이 및 포즈와 같은 시스템을 사용하려면 ComfyUI와 같은 복잡한 사용자 인터페이스에 대한 비사소한 익숙함이 필요하다는 점입니다. 따라서 이러한 종류의 기능적 오픈소스 모델은 자원을 확보하거나 독점적으로 모델을 선별하고 훈련할 동기가 부족한 소규모 VFX 회사에서 개발될 가능성이 높습니다.
반면, API 기반 ‘AI 렌탈’ 시스템은 직접 훈련된 보조 제어 시스템을 가진 모델에 대해 더 간단하고 사용자 친화적인 해석 방법을 개발할 강한 동기를 가질 수 있습니다.
**재생하려면 클릭하세요. FullDiT를 사용한 비디오 생성에 깊이+텍스트 제어를 부과한 예제.**
*저자들은 알려진 기본 모델(예: SDXL 등)을 지정하지 않았습니다.*
**최초 게시일: 2025년 3월 27일 목요일**
관련 기사
 유튜브, 안내형 답변이 포함된 AI 기반 검색 기능 테스트 중
많은 사용자가 요리법이나 여행 계획을 검색할 때 유튜브를 찾아 관련 동영상을 찾곤 합니다. 이제 유튜브는 텍스트와 동영상 콘텐츠를 결합해 단계별 결과를 제공하는 AI 기반 대화형 검색 도구를 선보입니다.새로운 'Ask YouTube' 기능을 통해 사용자는 "샌프란시스코에서 산타바바라까지 3일간의 로드트립을 계획해 주세요"와 같은 질문을 할 수 있으며, 단순
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
관련 특별 주제 추천
사업
유튜브, 안내형 답변이 포함된 AI 기반 검색 기능 테스트 중
많은 사용자가 요리법이나 여행 계획을 검색할 때 유튜브를 찾아 관련 동영상을 찾곤 합니다. 이제 유튜브는 텍스트와 동영상 콘텐츠를 결합해 단계별 결과를 제공하는 AI 기반 대화형 검색 도구를 선보입니다.새로운 'Ask YouTube' 기능을 통해 사용자는 "샌프란시스코에서 산타바바라까지 3일간의 로드트립을 계획해 주세요"와 같은 질문을 할 수 있으며, 단순
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
관련 특별 주제 추천
사업
 최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
 10 도구
10 도구
 xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai
암호
자동화된 단위 테스트를 위한 최고의 AI 도구들: 한 번의 클릭으로 Jest, PyTest, JUnit 테스트 케이스를 생성하세요.
2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

 의견 (3)
0/500
의견 (3)
0/500
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
비디오 기반 모델인 훈위안(Hunyuan)과 완 2.1(Wan 2.1)은 상당한 발전을 이루었지만, 영화 및 TV 제작에서 요구되는 세밀한 제어, 특히 시각 효과(VFX) 분야에서는 종종 부족함을 드러냅니다. 전문 VFX 스튜디오에서는 이러한 모델과 함께 스테이블 디퓨전(Stable Diffusion), 칸딘스키(Kandinsky), 플럭스(Flux)와 같은 초기 이미지 기반 모델을 사용하여 특정 창의적 요구를 충족하도록 출력을 정제하는 도구 세트를 활용합니다. 감독이 “멋지게 보이는데, 조금 더 [n]하게 만들어 줄 수 있나요?”라고 요청할 때, 모델이 그러한 조정을 위한 정밀도를 부족하다고 단순히 말하는 것만으로는 충분하지 않습니다.
대신, AI VFX 팀은 전통적인 CGI와 구성 기술을 조합하고, 맞춤 개발된 워크플로우를 사용하여 비디오 합성의 경계를 더욱 확장합니다. 이 접근 방식은 크롬(Chrome)과 같은 기본 웹 브라우저를 사용하는 것과 유사합니다. 기본적으로 기능적이지만, 진정으로 필요에 맞게 조정하려면 몇 가지 플러그인을 설치해야 합니다.
컨트롤 프릭스
확산 기반 이미지 합성 분야에서 가장 중요한 제3자 시스템 중 하나는 컨트롤넷(ControlNet)입니다. 이 기술은 생성 모델에 구조적 제어를 도입하여 사용자가 엣지 맵, 깊이 맵, 또는 포즈 정보와 같은 추가 입력을 사용하여 이미지나 비디오 생성을 안내할 수 있게 합니다.
*컨트롤넷의 다양한 방법은 깊이>이미지(상단 행), 의미적 분할>이미지(하단 좌측), 그리고 인간과 동물의 포즈 기반 이미지 생성(하단 좌측)을 가능하게 합니다.*
컨트롤넷은 텍스트 프롬프트에만 의존하지 않습니다. 별도의 신경망 브랜치 또는 어댑터를 사용하여 이러한 조건 신호를 처리하면서 기본 모델의 생성 능력을 유지합니다. 이를 통해 사용자의 사양에 밀접하게 맞춘 고도로 맞춤화된 출력을 가능하게 하며, 구성, 구조, 또는 모션에 대한 정밀한 제어가 필요한 응용 분야에서 매우 유용합니다.
*안내 포즈를 사용하면 컨트롤넷을 통해 다양한 정확한 출력 유형을 얻을 수 있습니다.* Source: https://arxiv.org/pdf/2302.05543
그러나 내부에 초점을 맞춘 신경망 프로세스 집합에서 외부적으로 작동하는 이러한 어댑터 기반 시스템에는 몇 가지 단점이 있습니다. 어댑터는 독립적으로 훈련되므로 여러 어댑터를 결합할 때 브랜치 충돌이 발생하여 생성 품질이 저하될 수 있습니다. 또한 각 어댑터마다 추가적인 계산 자원과 메모리가 필요하여 매개변수 중복을 초래하고, 확장이 비효율적입니다. 더욱이, 유연성에도 불구하고 어댑터는 다중 조건 생성을 위해 완전히 미세 조정된 모델에 비해 종종 최적이 아닌 결과를 산출합니다. 이러한 문제로 인해 다중 제어 신호의 원활한 통합이 필요한 작업에서 어댑터 기반 방법은 덜 효과적일 수 있습니다.
이상적으로, 컨트롤넷의 기능은 모듈 방식으로 모델에 기본적으로 통합되어 동시 비디오/오디오 생성이나 기본 립싱크 기능과 같은 미래 혁신을 가능하게 해야 합니다. 현재는 각 추가 기능이 후반 작업이 되거나, 기본 모델의 민감한 가중치를 조정해야 하는 비기본 절차가 됩니다.
FullDiT
중국에서 개발된 새로운 접근 방식인 FullDiT는 컨트롤넷 스타일의 기능을 사후 처리로 취급하지 않고 훈련 중에 생성 비디오 모델에 직접 통합합니다.
*새 논문에 따르면, FullDiT 접근 방식은 신원 부여, 깊이, 카메라 움직임을 기본 생성에 통합할 수 있으며, 이들을 동시에 조합하여 호출할 수 있습니다.* Source: https://arxiv.org/pdf/2503.19907
**FullDiT: 다중 작업 비디오 생성 기반 모델과 완전 주의**라는 제목의 논문에 설명된 FullDiT는 신원 전송, 깊이 매핑, 카메라 움직임과 같은 다중 작업 조건을 훈련된 생성 비디오 모델의 핵심에 통합합니다. 저자들은 프로토타입 모델과 프로젝트 사이트에서 제공되는 동반 비디오 클립을 개발했습니다.
**재생하려면 클릭하세요. 기본 훈련된 기반 모델만으로 컨트롤넷 스타일의 사용자 부여 사례.** Source: https://fulldit.github.io/
저자들은 FullDiT를 이미지 또는 텍스트 프롬프트 이상의 제어를 제공하는 텍스트-투-비디오(T2V) 및 이미지-투-비디오(I2V) 모델의 개념 증명으로 제시합니다. 유사한 모델이 존재하지 않으므로 연구자들은 다중 작업 비디오 평가를 위한 새로운 벤치마크인 **FullBench**를 만들었으며, 그들이 고안한 테스트에서 최첨단 성능을 달성했다고 주장합니다. 그러나 저자들이 설계한 FullBench의 객관성은 아직 검증되지 않았으며, 1,400개의 사례로 구성된 데이터셋은 더 광범위한 결론을 내리기에는 너무 제한적일 수 있습니다.
FullDiT 아키텍처의 가장 흥미로운 측면은 새로운 제어 유형을 통합할 가능성입니다. 저자들은 다음과 같이 언급합니다:
**‘이 연구에서는 카메라, 신원, 깊이 정보만을 제어 조건으로 탐구했습니다. 오디오, 음성, 포인트 클라우드, 객체 경계 상자, 광학 흐름 등 다른 조건과 모달리티는 추가로 조사하지 않았습니다. FullDiT의 설계는 최소한의 아키텍처 수정으로 다른 모달리티를 원활히 통합할 수 있지만, 기존 모델을 새로운 조건과 모달리티에 빠르고 비용 효율적으로 적응시키는 방법은 여전히 중요한 질문으로, 추가 탐구가 필요합니다.’**
FullDiT는 다중 작업 비디오 생성에서 한 걸음 나아간 발전을 나타내지만, 기존 아키텍처를 기반으로 하여 새로운 패러다임을 도입하지는 않습니다. 그럼에도 불구하고, 컨트롤넷 스타일 기능을 기본적으로 통합한 유일한 비디오 기반 모델로 돋보이며, 그 아키텍처는 미래 혁신을 수용하도록 설계되었습니다.
**재생하려면 클릭하세요. 프로젝트 사이트에서 제공하는 사용자 제어 카메라 움직임 사례.**
이 논문은 Kuaishou Technology와 홍콩중문대학의 9명의 연구자가 작성했으며, 제목은 **FullDiT: 다중 작업 비디오 생성 기반 모델과 완전 주의**입니다. 프로젝트 페이지와 새로운 벤치마크 데이터는 Hugging Face에서 확인할 수 있습니다.
방법
FullDiT의 통합 주의 메커니즘은 조건 간의 공간적 및 시간적 관계를 포착하여 교차 모달 표현 학습을 향상시키도록 설계되었습니다.
*새 논문에 따르면, FullDiT는 완전 자가 주의를 통해 다중 입력 조건을 통합하여 단일 시퀀스로 변환합니다. 반면, 어댑터 기반 모델(가장 왼쪽 위)은 각 입력에 대해 별도의 모듈을 사용하여 중복, 충돌, 그리고 더 약한 성능을 초래합니다.*
각 입력 스트림을 별도로 처리하는 어댑터 기반 설정과 달리, FullDiT의 공유 주의 구조는 브랜치 충돌을 피하고 매개변수 오버헤드를 줄입니다. 저자들은 이 아키텍처가 주요 재설계 없이 새로운 입력 유형으로 확장 가능하며, 모델 스키마가 훈련 중에 보지 못한 조건 조합(예: 카메라 모션과 캐릭터 신원 연결)에 일반화할 수 있는 조짐을 보인다고 주장합니다.
**재생하려면 클릭하세요. 프로젝트 사이트에서 제공하는 신원 생성 사례.**
FullDiT의 아키텍처에서는 텍스트, 카메라 모션, 신원, 깊이와 같은 모든 조건 입력이 먼저 통합 토큰 형식으로 변환됩니다. 이러한 토큰은 단일 긴 시퀀스로 연결되어 완전 자가 주의를 사용하는 트랜스포머 레이어 스택을 통해 처리됩니다. 이 접근 방식은 Open-Sora Plan 및 Movie Gen과 같은 선행 작업을 따릅니다.
이 설계는 모델이 모든 조건에 걸쳐 시간적 및 공간적 관계를 공동으로 학습할 수 있게 합니다. 각 트랜스포머 블록은 전체 시퀀스에 대해 작동하여, 각 입력에 대해 별도의 모듈에 의존하지 않고 모달리티 간의 동적 상호작용을 가능하게 합니다. 이 아키텍처는 확장 가능하도록 설계되어, 주요 구조적 변경 없이 향후 추가 제어 신호를 통합하기가 더 쉬워집니다.
세 가지의 힘
FullDiT는 각 제어 신호를 표준화된 토큰 형식으로 변환하여 모든 조건이 통합 주의 프레임워크에서 함께 처리될 수 있도록 합니다. 카메라 모션의 경우, 모델은 각 프레임에 대해 위치 및 방향과 같은 외부 매개변수 시퀀스를 인코딩합니다. 이러한 매개변수는 타임스탬프가 지정되고 신호의 시간적 특성을 반영하는 임베딩 벡터로 투영됩니다.
신원 정보는 본질적으로 시간적이지 않고 공간적이기 때문에 다르게 처리됩니다. 모델은 각 프레임의 어떤 부분에 어떤 캐릭터가 존재하는지를 나타내는 신원 맵을 사용합니다. 이러한 맵은 패치로 나뉘며, 각 패치는 공간적 신원 단서를 포착하는 임베딩으로 투영되어 모델이 프레임의 특정 영역을 특정 엔티티와 연관시킬 수 있게 합니다.
깊이는 시공간적 신호로, 모델은 깊이 비디오를 공간과 시간을 아우르는 3D 패치로 나누어 처리합니다. 이러한 패치는 프레임 간 구조를 보존하는 방식으로 임베딩됩니다.
임베딩된 후, 카메라, 신원, 깊이와 같은 모든 조건 토큰은 단일 긴 시퀀스로 연결되어 FullDiT가 완전 자가 주의를 사용하여 함께 처리할 수 있도록 합니다. 이 공유 표현은 모델이 독립된 처리 스트림에 의존하지 않고 모달리티 간 및 시간에 걸친 상호작용을 학습할 수 있게 합니다.
데이터 및 테스트
FullDiT의 훈련 접근 방식은 모든 조건이 동시에 존재해야 하는 대신 각 조건 유형에 맞춘 선택적으로 주석이 달린 데이터셋에 의존했습니다.
텍스트 조건의 경우, MiraData 프로젝트에서 설명된 구조적 캡션 접근 방식을 따릅니다.
*MiraData 프로젝트의 비디오 수집 및 주석 파이프라인.* Source: https://arxiv.org/pdf/2407.06358
카메라 모션의 경우, 고품질의 카메라 매개변수 주석이 포함된 RealEstate10K 데이터셋이 주요 데이터 소스였습니다. 그러나 저자들은 RealEstate10K와 같은 정적 장면 카메라 데이터셋만으로 훈련하면 생성된 비디오에서 동적 객체 및 인간 움직임이 감소하는 경향이 있음을 관찰했습니다. 이를 해결하기 위해 더 동적인 카메라 모션을 포함한 내부 데이터셋을 사용하여 추가 미세 조정을 수행했습니다.
신원 주석은 ConceptMaster 프로젝트를 위해 개발된 파이프라인을 사용하여 생성되었으며, 이는 세밀한 신원 정보를 효율적으로 필터링하고 추출할 수 있게 했습니다.
*ConceptMaster 프레임워크는 맞춤형 비디오에서 신원 분리 문제를 해결하면서 개념 충실도를 보존하도록 설계되었습니다.* Source: https://arxiv.org/pdf/2501.04698
깊이 주석은 Panda-70M 데이터셋에서 Depth Anything을 사용하여 얻었습니다.
데이터 순서화를 통한 최적화
저자들은 또한 점진적 훈련 일정을 구현하여 더 도전적인 조건을 훈련 초기에 도입함으로써 모델이 더 단순한 작업이 추가되기 전에 견고한 표현을 습득하도록 했습니다. 훈련 순서는 텍스트에서 카메라 조건, 신원, 그리고 마지막으로 깊이로 진행되었으며, 쉬운 작업은 일반적으로 나중에 더 적은 사례로 도입되었습니다.
저자들은 이러한 작업 순서화의 가치를 다음과 같이 강조합니다:
**‘사전 훈련 단계에서, 더 도전적인 작업은 더 긴 훈련 시간을 요구하며 학습 과정 초기에 도입되어야 한다는 점을 확인했습니다. 이러한 도전적인 작업은 출력 비디오와 크게 다른 복잡한 데이터 분포를 포함하며, 모델이 이를 정확히 포착하고 표현할 수 있는 충분한 용량을 필요로 합니다.’**
**‘반대로, 쉬운 작업을 너무 일찍 도입하면 모델이 즉각적인 최적화 피드백을 제공하는 쉬운 작업을 먼저 학습하는 데 우선순위를 두게 되어 더 도전적인 작업의 수렴을 방해할 수 있습니다.’**
*연구자들이 채택한 데이터 훈련 순서를 보여주는 그림으로, 빨간색은 더 많은 데이터 양을 나타냅니다.*
초기 사전 훈련 후, 최종 미세 조정 단계에서 시각적 품질과 모션 역학을 개선했습니다. 이후 훈련은 표준 확산 프레임워크를 따랐습니다: 비디오 잠재 변수에 노이즈를 추가하고, 모델이 임베딩된 조건 토큰을 안내로 사용하여 이를 예측하고 제거하도록 학습했습니다.
FullDiT를 효과적으로 평가하고 기존 방법과 공정한 비교를 제공하기 위해, 저자들은 적절한 다른 벤치마크가 없는 상황에서 1,400개의 고유한 테스트 사례로 구성된 선별된 벤치마크 스위트인 **FullBench**를 도입했습니다.
*새로운 FullBench 벤치마크를 위한 데이터 탐색기 인스턴스.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
각 데이터 포인트는 카메라 모션, 신원, 깊이를 포함한 다양한 조건 신호에 대한 참값 주석을 제공했습니다.
메트릭
저자들은 텍스트 정렬, 카메라 제어, 신원 유사성, 깊이 정확도, 일반 비디오 품질의 다섯 가지 주요 성능 측면을 다루는 10개의 메트릭을 사용하여 FullDiT를 평가했습니다.
텍스트 정렬은 CLIP 유사성을 사용하여 측정되었으며, 카메라 제어는 CameraCtrl 프로젝트의 CamI2V 접근 방식을 따라 회전 오류(RotErr), 변환 오류(TransErr), 카메라 모션 일관성(CamMC)을 통해 평가되었습니다.
신원 유사성은 DINO-I와 CLIP-I를 사용하여 평가되었으며, 깊이 제어 정확도는 평균 절대 오차(MAE)를 사용하여 정량화되었습니다.
비디오 품질은 MiraData의 세 가지 메트릭으로 판단되었습니다: 부드러움을 위한 프레임 수준 CLIP 유사성; 역학을 위한 광학 흐름 기반 모션 거리; 시각적 매력을 위한 LAION-Aesthetic 점수.
훈련
저자들은 약 10억 개의 매개변수를 포함하는 내부(공개되지 않은) 텍스트-투-비디오 확산 모델을 사용하여 FullDiT를 훈련했습니다. 이전 방법과의 비교에서 공정성을 유지하고 재현 가능성을 보장하기 위해 의도적으로 적당한 매개변수 크기를 선택했습니다.
훈련 비디오의 길이와 해상도가 다양했기 때문에, 저자들은 각 배치를 공통 해상도로 크기를 조정하고 패딩하여 표준화했으며, 시퀀스당 77개의 프레임을 샘플링하고 주의 및 손실 마스크를 적용하여 훈련 효과를 최적화했습니다.
Adam 옵티마이저는 64개의 NVIDIA H800 GPU 클러스터에서 1×10−5의 학습률로 사용되었으며, 총 5,120GB의 VRAM을 사용했습니다(매니아 합성 커뮤니티에서는 RTX 3090의 24GB가 여전히 호화로운 표준으로 간주된다는 점을 고려하세요).
모델은 약 32,000단계 동안 훈련되었으며, 비디오당 최대 3개의 신원, 20개의 카메라 조건 프레임, 21개의 깊이 조건 프레임을 포함했으며, 둘 다 총 77개의 프레임에서 균일하게 샘플링되었습니다.
추론을 위해, 모델은 384×672 픽셀 해상도(초당 15프레임으로 약 5초)로 비디오를 생성했으며, 50개의 확산 추론 단계와 5의 분류기 없는 안내 스케일을 사용했습니다.
이전 방법
카메라-투-비디오 평가를 위해, 저자들은 FullDiT를 MotionCtrl, CameraCtrl, CamI2V와 비교했으며, 모든 모델은 일관성과 공정성을 보장하기 위해 RealEstate10k 데이터셋을 사용하여 훈련되었습니다.
신원 조건 생성에서는 비교 가능한 오픈소스 다중 신원 모델이 없었기 때문에, 동일한 훈련 데이터와 아키텍처를 사용하여 1B 매개변수 ConceptMaster 모델과 벤치마킹했습니다.
깊이-투-비디오 작업에서는 Ctrl-Adapter 및 ControlVideo와 비교했습니다.
*단일 작업 비디오 생성에 대한 정량적 결과. FullDiT는 카메라-투-비디오 생성에서 MotionCtrl, CameraCtrl, CamI2V와 비교되었으며, 신원-투-비디오에서 ConceptMaster(1B 매개변수 버전), 깊이-투-비디오에서 Ctrl-Adapter 및 ControlVideo와 비교되었습니다. 모든 모델은 기본 설정을 사용하여 평가되었습니다. 일관성을 위해 각 방법에서 16개의 프레임이 균일하게 샘플링되어 이전 모델의 출력 길이와 일치했습니다.*
결과는 FullDiT가 다중 조건 신호를 동시에 처리함에도 불구하고 텍스트, 카메라 모션, 신원, 깊이 제어와 관련된 메트릭에서 최첨단 성능을 달성했음을 나타냅니다.
전반적인 품질 메트릭에서 이 시스템은 일반적으로 다른 방법들을 능가했지만, 부드러움은 ConceptMaster보다 약간 낮았습니다. 이에 대해 저자들은 다음과 같이 언급합니다:
**‘FullDiT의 부드러움은 인접 프레임 간 CLIP 유사성을 기반으로 계산되기 때문에 ConceptMaster보다 약간 낮습니다. FullDiT는 ConceptMaster에 비해 훨씬 더 큰 역학을 보여주므로, 인접 프레임 간의 큰 변동으로 인해 부드러움 메트릭이 영향을 받습니다.’**
**‘미적 점수에서는 평가 모델이 회화 스타일의 이미지를 선호하며, ControlVideo는 일반적으로 이 스타일의 비디오를 생성하므로 미적 점수에서 높은 점수를 얻습니다.’**
정성적 비교와 관련하여, PDF 예제는 필연적으로 정적이며(여기에서 전체를 재현하기에는 너무 큼) FullDiT 프로젝트 사이트의 샘플 비디오를 참조하는 것이 바람직할 수 있습니다.
*PDF에서 재현된 정성적 결과의 첫 번째 섹션. 추가 예제는 여기에서 재현하기에는 너무 광범위하므로 소스 논문을 참조하세요.*
저자들은 다음과 같이 언급합니다:
**‘FullDiT는 [ConceptMaster]에 비해 우수한 신원 보존을 보여주며, 더 나은 역학과 시각적 품질의 비디오를 생성합니다. ConceptMaster와 FullDiT는 동일한 백본에서 훈련되었기 때문에, 이는 완전 주의를 통한 조건 주입의 효과를 강조합니다.’**
**‘…[다른] 결과는 기존 깊이-투-비디오 및 카메라-투-비디오 방법에 비해 FullDiT의 우수한 제어 가능성과 생성 품질을 보여줍니다.’**
*PDF의 FullDiT의 다중 신호 출력 예제 섹션. 추가 예제는 소스 논문과 프로젝트 사이트를 참조하세요.*
결론
FullDiT는 더 포괄적인 비디오 기반 모델로 나아가는 흥미로운 단계를 나타냅니다. 그러나 컨트롤넷 스타일 기능에 대한 수요가 특히 오픈소스 프로젝트에서 대규모 구현을 정당화하는지는 여전히 의문입니다. 이러한 프로젝트는 상업적 지원 없이 필요한 방대한 GPU 처리 능력을 확보하는 데 어려움을 겪을 것입니다.
주요 과제는 깊이 및 포즈와 같은 시스템을 사용하려면 ComfyUI와 같은 복잡한 사용자 인터페이스에 대한 비사소한 익숙함이 필요하다는 점입니다. 따라서 이러한 종류의 기능적 오픈소스 모델은 자원을 확보하거나 독점적으로 모델을 선별하고 훈련할 동기가 부족한 소규모 VFX 회사에서 개발될 가능성이 높습니다.
반면, API 기반 ‘AI 렌탈’ 시스템은 직접 훈련된 보조 제어 시스템을 가진 모델에 대해 더 간단하고 사용자 친화적인 해석 방법을 개발할 강한 동기를 가질 수 있습니다.
**재생하려면 클릭하세요. FullDiT를 사용한 비디오 생성에 깊이+텍스트 제어를 부과한 예제.**
*저자들은 알려진 기본 모델(예: SDXL 등)을 지정하지 않았습니다.*
**최초 게시일: 2025년 3월 27일 목요일**










 유튜브, 안내형 답변이 포함된 AI 기반 검색 기능 테스트 중
많은 사용자가 요리법이나 여행 계획을 검색할 때 유튜브를 찾아 관련 동영상을 찾곤 합니다. 이제 유튜브는 텍스트와 동영상 콘텐츠를 결합해 단계별 결과를 제공하는 AI 기반 대화형 검색 도구를 선보입니다.새로운 'Ask YouTube' 기능을 통해 사용자는 "샌프란시스코에서 산타바바라까지 3일간의 로드트립을 계획해 주세요"와 같은 질문을 할 수 있으며, 단순
유튜브, 안내형 답변이 포함된 AI 기반 검색 기능 테스트 중
많은 사용자가 요리법이나 여행 계획을 검색할 때 유튜브를 찾아 관련 동영상을 찾곤 합니다. 이제 유튜브는 텍스트와 동영상 콘텐츠를 결합해 단계별 결과를 제공하는 AI 기반 대화형 검색 도구를 선보입니다.새로운 'Ask YouTube' 기능을 통해 사용자는 "샌프란시스코에서 산타바바라까지 3일간의 로드트립을 계획해 주세요"와 같은 질문을 할 수 있으며, 단순
 독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
 반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













