
















 Maison
MaisonModèles de «raisonnement» AI testés avec les questions de puzzle du dimanche NPR
Tous les dimanches, Will Shortz de NPR, le cerveau derrière les mots croisés du New York Times, captive des milliers d'auditeurs avec son segment, le Puzzle du Dimanche. Ces puzzles sont conçus pour être résolus avec des connaissances générales, mais ils représentent un défi significatif même pour les solveurs de puzzles chevronnés.
Cette complexité explique pourquoi certains experts estiment que le Puzzle du Dimanche pourrait servir d'outil précieux pour tester les limites des capacités de résolution de problèmes de l'IA.
Dans une étude récente, des chercheurs du Wellesley College, de l'Oberlin College, de l'Université du Texas à Austin, de l'Université Northeastern, de l'Université Charles et de la startup Cursor ont développé un benchmark d'IA en utilisant des énigmes du Puzzle du Dimanche. Leurs résultats ont révélé des comportements intrigants dans les modèles de raisonnement, y compris o1 d'OpenAI, qui parfois "abandonne" et propose des réponses incorrectes en connaissance de cause.
Arjun Guha, professeur d'informatique à Northeastern et co-auteur de l'étude, a expliqué à TechCrunch que l'objectif était de créer un benchmark compréhensible par quiconque possède des connaissances générales. Il a noté, "Nous voulions développer un benchmark avec des problèmes que les humains peuvent comprendre avec seulement des connaissances générales."
L'industrie de l'IA fait actuellement face à un défi avec les benchmarks, car de nombreux tests se concentrent sur des compétences avancées comme les mathématiques et les sciences de niveau doctorat, qui ne sont pas pertinentes pour la plupart des utilisateurs. De plus, même les benchmarks récemment publiés approchent de la saturation.
Le Puzzle du Dimanche offre un avantage unique car il ne repose pas sur des connaissances spécialisées, et son format empêche les modèles d'IA de simplement régurgiter des réponses mémorisées, selon Guha. Il a expliqué, "Je pense que ce qui rend ces problèmes difficiles, c'est qu'il est vraiment compliqué de faire des progrès significatifs sur un problème jusqu'à ce qu'on le résolve — c'est là que tout s'assemble d'un coup. Cela nécessite une combinaison d'intuition et d'un processus d'élimination."
Cependant, le Puzzle du Dimanche n'est pas sans limites. Il est centré sur la culture américaine et utilise uniquement l'anglais, et il existe un risque que les modèles entraînés sur ces puzzles puissent "tricher" s'ils ont déjà vu les questions. Guha rassure toutefois qu'il n'a pas encore trouvé de preuves de cela. Il a ajouté, "De nouvelles questions sont publiées chaque semaine, et nous pouvons nous attendre à ce que les dernières questions soient véritablement inédites. Nous avons l'intention de garder le benchmark à jour et de suivre l'évolution des performances des modèles au fil du temps."
Le benchmark des chercheurs, comprenant environ 600 énigmes du Puzzle du Dimanche, a montré que des modèles de raisonnement comme o1 et R1 de DeepSeek surpassaient significativement les autres modèles. Ces modèles vérifient méticuleusement leurs propres faits, ce qui les aide à éviter les pièges courants. Cependant, cette minutie signifie qu'ils prennent plus de temps pour arriver à une solution — généralement de quelques secondes à quelques minutes de plus.
Chose intéressante, R1 de DeepSeek admet parfois sa défaite, disant "J'abandonne", avant de proposer une réponse incorrecte au hasard — une réaction à laquelle beaucoup d'humains peuvent s'identifier. D'autres comportements étranges observés incluent des modèles donnant une mauvaise réponse, la rétractant, tentant une autre supposition, et échouant à nouveau. Certains modèles se retrouvent coincés dans des boucles infinies de "réflexion", fournissent des explications absurdes, ou répondent correctement à une question pour ensuite explorer inutilement des réponses alternatives.
Guha a commenté le comportement de R1, disant, "Sur des problèmes difficiles, R1 dit littéralement qu'il devient 'frustré'. C'était amusant de voir comment un modèle imite ce qu'un humain pourrait dire. Il reste à voir comment la 'frustration' dans le raisonnement peut affecter la qualité des résultats des modèles."

R1 devenant “frustré” sur une question du défi du Puzzle du Dimanche. Crédits image : Guha et al. L'actuel meilleur performeur sur le benchmark est o1, avec un score de 59 %, suivi par l'o3-mini récemment publié, réglé sur un haut "effort de raisonnement" à 47 %. R1 a obtenu 35 %. Les chercheurs prévoient d'élargir leurs tests à davantage de modèles de raisonnement, espérant identifier des domaines à améliorer.
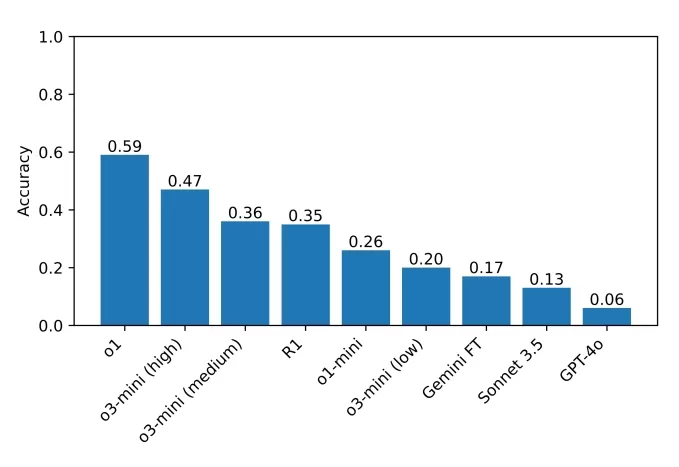
Les scores des modèles testés par l'équipe sur leur benchmark. Crédits image : Guha et al. Guha a souligné l'importance des benchmarks accessibles, déclarant, "Vous n'avez pas besoin d'un doctorat pour être bon en raisonnement, donc il devrait être possible de concevoir des benchmarks de raisonnement qui ne nécessitent pas de connaissances de niveau doctorat. Un benchmark avec un accès plus large permet à un ensemble plus vaste de chercheurs de comprendre et d'analyser les résultats, ce qui peut à son tour conduire à de meilleures solutions à l'avenir. De plus, à mesure que les modèles de pointe sont de plus en plus déployés dans des contextes qui affectent tout le monde, nous pensons que tout le monde devrait pouvoir intuitivement comprendre ce que ces modèles sont — et ne sont pas — capables de faire."
Article connexe
 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
Recommandations de sujets spéciaux liés
Création d'animations
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
Recommandations de sujets spéciaux liés
Création d'animations
 Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Generateur d'animation AI pour Donghua : Créer des personnages de romans web et des avatars de bandes dessinées
Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
 10 outils
10 outils
 xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
xix.ai
Création de bande dessinée
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

 commentaires (12)
commentaires (12)
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Tous les dimanches, Will Shortz de NPR, le cerveau derrière les mots croisés du New York Times, captive des milliers d'auditeurs avec son segment, le Puzzle du Dimanche. Ces puzzles sont conçus pour être résolus avec des connaissances générales, mais ils représentent un défi significatif même pour les solveurs de puzzles chevronnés.
Cette complexité explique pourquoi certains experts estiment que le Puzzle du Dimanche pourrait servir d'outil précieux pour tester les limites des capacités de résolution de problèmes de l'IA.
Dans une étude récente, des chercheurs du Wellesley College, de l'Oberlin College, de l'Université du Texas à Austin, de l'Université Northeastern, de l'Université Charles et de la startup Cursor ont développé un benchmark d'IA en utilisant des énigmes du Puzzle du Dimanche. Leurs résultats ont révélé des comportements intrigants dans les modèles de raisonnement, y compris o1 d'OpenAI, qui parfois "abandonne" et propose des réponses incorrectes en connaissance de cause.
Arjun Guha, professeur d'informatique à Northeastern et co-auteur de l'étude, a expliqué à TechCrunch que l'objectif était de créer un benchmark compréhensible par quiconque possède des connaissances générales. Il a noté, "Nous voulions développer un benchmark avec des problèmes que les humains peuvent comprendre avec seulement des connaissances générales."
L'industrie de l'IA fait actuellement face à un défi avec les benchmarks, car de nombreux tests se concentrent sur des compétences avancées comme les mathématiques et les sciences de niveau doctorat, qui ne sont pas pertinentes pour la plupart des utilisateurs. De plus, même les benchmarks récemment publiés approchent de la saturation.
Le Puzzle du Dimanche offre un avantage unique car il ne repose pas sur des connaissances spécialisées, et son format empêche les modèles d'IA de simplement régurgiter des réponses mémorisées, selon Guha. Il a expliqué, "Je pense que ce qui rend ces problèmes difficiles, c'est qu'il est vraiment compliqué de faire des progrès significatifs sur un problème jusqu'à ce qu'on le résolve — c'est là que tout s'assemble d'un coup. Cela nécessite une combinaison d'intuition et d'un processus d'élimination."
Cependant, le Puzzle du Dimanche n'est pas sans limites. Il est centré sur la culture américaine et utilise uniquement l'anglais, et il existe un risque que les modèles entraînés sur ces puzzles puissent "tricher" s'ils ont déjà vu les questions. Guha rassure toutefois qu'il n'a pas encore trouvé de preuves de cela. Il a ajouté, "De nouvelles questions sont publiées chaque semaine, et nous pouvons nous attendre à ce que les dernières questions soient véritablement inédites. Nous avons l'intention de garder le benchmark à jour et de suivre l'évolution des performances des modèles au fil du temps."
Le benchmark des chercheurs, comprenant environ 600 énigmes du Puzzle du Dimanche, a montré que des modèles de raisonnement comme o1 et R1 de DeepSeek surpassaient significativement les autres modèles. Ces modèles vérifient méticuleusement leurs propres faits, ce qui les aide à éviter les pièges courants. Cependant, cette minutie signifie qu'ils prennent plus de temps pour arriver à une solution — généralement de quelques secondes à quelques minutes de plus.
Chose intéressante, R1 de DeepSeek admet parfois sa défaite, disant "J'abandonne", avant de proposer une réponse incorrecte au hasard — une réaction à laquelle beaucoup d'humains peuvent s'identifier. D'autres comportements étranges observés incluent des modèles donnant une mauvaise réponse, la rétractant, tentant une autre supposition, et échouant à nouveau. Certains modèles se retrouvent coincés dans des boucles infinies de "réflexion", fournissent des explications absurdes, ou répondent correctement à une question pour ensuite explorer inutilement des réponses alternatives.
Guha a commenté le comportement de R1, disant, "Sur des problèmes difficiles, R1 dit littéralement qu'il devient 'frustré'. C'était amusant de voir comment un modèle imite ce qu'un humain pourrait dire. Il reste à voir comment la 'frustration' dans le raisonnement peut affecter la qualité des résultats des modèles."
L'actuel meilleur performeur sur le benchmark est o1, avec un score de 59 %, suivi par l'o3-mini récemment publié, réglé sur un haut "effort de raisonnement" à 47 %. R1 a obtenu 35 %. Les chercheurs prévoient d'élargir leurs tests à davantage de modèles de raisonnement, espérant identifier des domaines à améliorer.
Guha a souligné l'importance des benchmarks accessibles, déclarant, "Vous n'avez pas besoin d'un doctorat pour être bon en raisonnement, donc il devrait être possible de concevoir des benchmarks de raisonnement qui ne nécessitent pas de connaissances de niveau doctorat. Un benchmark avec un accès plus large permet à un ensemble plus vaste de chercheurs de comprendre et d'analyser les résultats, ce qui peut à son tour conduire à de meilleures solutions à l'avenir. De plus, à mesure que les modèles de pointe sont de plus en plus déployés dans des contextes qui affectent tout le monde, nous pensons que tout le monde devrait pouvoir intuitivement comprendre ce que ces modèles sont — et ne sont pas — capables de faire."










 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
 Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se

Découvrez les meilleurs générateurs d’animés AI de 2026 pour la création de doublages en chinois. Notre liste, sélectionnée avec soin, propose des outils puissants pour créer des personnages incroyables pour des romans web et des avatars de comics. Comparez les options gratuites et payantes grâce à des tests réels. Trouvez le partenaire créatif idéal et donnez vie à vos histoires dès aujourd’hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













