
















 Lar
Lar
Modelos de 'raciocínio' da IA testados com as perguntas do quebra -cabeça de domingo da NPR
Todos os domingos, Will Shortz, da NPR, o gênio por trás dos quebra-cabeças de palavras cruzadas do The New York Times, envolve milhares de ouvintes com seu segmento, o Quebra-Cabeça de Domingo. Esses quebra-cabeças são projetados para serem resolvidos com conhecimento geral, mas representam um desafio significativo até mesmo para solucionadores de quebra-cabeças experientes.
Essa complexidade é o motivo pelo qual alguns especialistas acreditam que o Quebra-Cabeça de Domingo poderia servir como uma ferramenta valiosa para testar os limites das capacidades de resolução de problemas da IA.
Em um estudo recente, pesquisadores do Wellesley College, Oberlin College, Universidade do Texas em Austin, Northeastern University, Universidade Charles e a startup Cursor desenvolveram um benchmark de IA usando enigmas do Quebra-Cabeça de Domingo. Suas descobertas revelaram comportamentos intrigantes em modelos de raciocínio, incluindo o o1 da OpenAI, que ocasionalmente "desiste" e oferece respostas incorretas conscientemente.
Arjun Guha, professor de ciência da computação na Northeastern e coautor do estudo, explicou à TechCrunch que o objetivo era criar um benchmark que pudesse ser compreendido por qualquer pessoa com conhecimento geral. Ele observou, "Queríamos desenvolver um benchmark com problemas que humanos possam entender com apenas conhecimento geral."
A indústria de IA atualmente enfrenta um desafio com benchmarking, pois muitos testes focam em habilidades avançadas, como matemática e ciência de nível de doutorado, que não são relevantes para a maioria dos usuários. Além disso, até mesmo benchmarks lançados recentemente estão próximos da saturação.
O Quebra-Cabeça de Domingo oferece uma vantagem única porque não depende de conhecimento especializado, e seu formato impede que modelos de IA simplesmente regurgitem respostas memorizadas, segundo Guha. Ele elaborou, "Acho que o que torna esses problemas difíceis é que é realmente difícil fazer progresso significativo em um problema até resolvê-lo — é quando tudo se encaixa de uma vez. Isso requer uma combinação de insight e um processo de eliminação."
No entanto, o Quebra-Cabeça de Domingo não está isento de limitações. Ele é centrado na cultura dos EUA e usa apenas inglês, e há o risco de que modelos treinados nesses quebra-cabeças possam "trapacear" se já tiverem visto as perguntas antes. Guha tranquiliza, no entanto, que ainda não encontrou evidências disso. Ele acrescentou, "Novas perguntas são lançadas toda semana, e podemos esperar que as perguntas mais recentes sejam verdadeiramente inéditas. Pretendemos manter o benchmark atualizado e acompanhar como o desempenho do modelo muda ao longo do tempo."
O benchmark dos pesquisadores, com cerca de 600 enigmas do Quebra-Cabeça de Domingo, mostrou que modelos de raciocínio como o o1 e o R1 da DeepSeek superaram significativamente outros modelos. Esses modelos verificam os fatos meticulosamente, o que os ajuda a evitar armadilhas comuns. No entanto, essa minuciosidade significa que eles levam mais tempo para chegar a uma solução — geralmente de alguns segundos a minutos a mais.
Curiosamente, o R1 da DeepSeek às vezes admite a derrota, dizendo "Eu desisto", antes de oferecer uma resposta incorreta aleatória — uma reação com a qual muitos humanos podem se identificar. Outros comportamentos peculiares observados incluem modelos dando uma resposta errada, retratando-a, tentando outra suposição e falhando novamente. Alguns modelos ficam presos em loops intermináveis de "pensamento", fornecem explicações sem sentido ou respondem corretamente a uma pergunta apenas para depois explorar respostas alternativas desnecessariamente.
Guha comentou sobre o comportamento do R1, dizendo, "Em problemas difíceis, o R1 literalmente diz que está ficando 'frustrado'. Foi engraçado ver como um modelo emula o que um humano poderia dizer. Ainda resta ver como a 'frustração' no raciocínio pode afetar a qualidade dos resultados do modelo."

R1 ficando “frustrado” em uma pergunta do conjunto de desafios do Quebra-Cabeça de Domingo. Créditos da imagem: Guha et al. O atual líder no benchmark é o o1, alcançando uma pontuação de 59%, seguido pelo recém-lançado o3-mini configurado para alto "esforço de raciocínio" com 47%. O R1 obteve 35%. Os pesquisadores planejam expandir seus testes para mais modelos de raciocínio, esperando identificar áreas para melhoria.
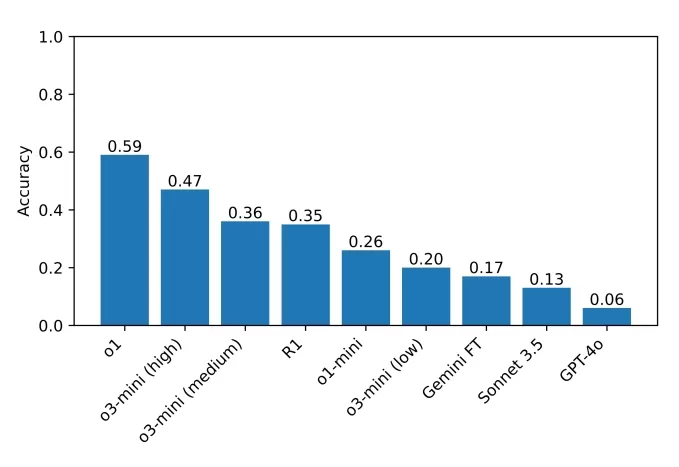
As pontuações dos modelos testados pela equipe em seu benchmark. Créditos da imagem: Guha et al. Guha enfatizou a importância de benchmarks acessíveis, afirmando, "Você não precisa de um doutorado para ser bom em raciocínio, então deve ser possível projetar benchmarks de raciocínio que não exijam conhecimento de nível de doutorado. Um benchmark com acesso mais amplo permite que um conjunto mais amplo de pesquisadores compreenda e analise os resultados, o que pode, por sua vez, levar a melhores soluções no futuro. Além disso, à medida que modelos de ponta são cada vez mais implementados em ambientes que afetam a todos, acreditamos que todos deveriam ser capazes de intuir o que esses modelos são — e não são — capazes de fazer."
Artigo relacionado
 O WordPress.com agora permite que agentes de IA escrevam e publiquem posts, entre outras coisas
O WordPress.com, a popular plataforma de hospedagem e publicação na web, está agora adotando agentes de IA — uma iniciativa que pode transformar a aparência e a experiência da web. A empresa anunciou
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
Recomendações de tópicos especiais relacionados
Criação de Animação
O WordPress.com agora permite que agentes de IA escrevam e publiquem posts, entre outras coisas
O WordPress.com, a popular plataforma de hospedagem e publicação na web, está agora adotando agentes de IA — uma iniciativa que pode transformar a aparência e a experiência da web. A empresa anunciou
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
Recomendações de tópicos especiais relacionados
Criação de Animação
 Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Criação de quadrinhos
As melhores ferramentas de colorização automática com IA para mangás: aplique cores planas sem erros de consistência
xix.ai
Criação de quadrinhos
As melhores ferramentas de colorização automática com IA para mangás: aplique cores planas sem erros de consistência
Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai
escrita
Os melhores criadores de perfis de ficção com IA: gerar motivações consistentes para personagens e falhas fatais
Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai
Negócios
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

 Comentários (12)
Comentários (12)
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Todos os domingos, Will Shortz, da NPR, o gênio por trás dos quebra-cabeças de palavras cruzadas do The New York Times, envolve milhares de ouvintes com seu segmento, o Quebra-Cabeça de Domingo. Esses quebra-cabeças são projetados para serem resolvidos com conhecimento geral, mas representam um desafio significativo até mesmo para solucionadores de quebra-cabeças experientes.
Essa complexidade é o motivo pelo qual alguns especialistas acreditam que o Quebra-Cabeça de Domingo poderia servir como uma ferramenta valiosa para testar os limites das capacidades de resolução de problemas da IA.
Em um estudo recente, pesquisadores do Wellesley College, Oberlin College, Universidade do Texas em Austin, Northeastern University, Universidade Charles e a startup Cursor desenvolveram um benchmark de IA usando enigmas do Quebra-Cabeça de Domingo. Suas descobertas revelaram comportamentos intrigantes em modelos de raciocínio, incluindo o o1 da OpenAI, que ocasionalmente "desiste" e oferece respostas incorretas conscientemente.
Arjun Guha, professor de ciência da computação na Northeastern e coautor do estudo, explicou à TechCrunch que o objetivo era criar um benchmark que pudesse ser compreendido por qualquer pessoa com conhecimento geral. Ele observou, "Queríamos desenvolver um benchmark com problemas que humanos possam entender com apenas conhecimento geral."
A indústria de IA atualmente enfrenta um desafio com benchmarking, pois muitos testes focam em habilidades avançadas, como matemática e ciência de nível de doutorado, que não são relevantes para a maioria dos usuários. Além disso, até mesmo benchmarks lançados recentemente estão próximos da saturação.
O Quebra-Cabeça de Domingo oferece uma vantagem única porque não depende de conhecimento especializado, e seu formato impede que modelos de IA simplesmente regurgitem respostas memorizadas, segundo Guha. Ele elaborou, "Acho que o que torna esses problemas difíceis é que é realmente difícil fazer progresso significativo em um problema até resolvê-lo — é quando tudo se encaixa de uma vez. Isso requer uma combinação de insight e um processo de eliminação."
No entanto, o Quebra-Cabeça de Domingo não está isento de limitações. Ele é centrado na cultura dos EUA e usa apenas inglês, e há o risco de que modelos treinados nesses quebra-cabeças possam "trapacear" se já tiverem visto as perguntas antes. Guha tranquiliza, no entanto, que ainda não encontrou evidências disso. Ele acrescentou, "Novas perguntas são lançadas toda semana, e podemos esperar que as perguntas mais recentes sejam verdadeiramente inéditas. Pretendemos manter o benchmark atualizado e acompanhar como o desempenho do modelo muda ao longo do tempo."
O benchmark dos pesquisadores, com cerca de 600 enigmas do Quebra-Cabeça de Domingo, mostrou que modelos de raciocínio como o o1 e o R1 da DeepSeek superaram significativamente outros modelos. Esses modelos verificam os fatos meticulosamente, o que os ajuda a evitar armadilhas comuns. No entanto, essa minuciosidade significa que eles levam mais tempo para chegar a uma solução — geralmente de alguns segundos a minutos a mais.
Curiosamente, o R1 da DeepSeek às vezes admite a derrota, dizendo "Eu desisto", antes de oferecer uma resposta incorreta aleatória — uma reação com a qual muitos humanos podem se identificar. Outros comportamentos peculiares observados incluem modelos dando uma resposta errada, retratando-a, tentando outra suposição e falhando novamente. Alguns modelos ficam presos em loops intermináveis de "pensamento", fornecem explicações sem sentido ou respondem corretamente a uma pergunta apenas para depois explorar respostas alternativas desnecessariamente.
Guha comentou sobre o comportamento do R1, dizendo, "Em problemas difíceis, o R1 literalmente diz que está ficando 'frustrado'. Foi engraçado ver como um modelo emula o que um humano poderia dizer. Ainda resta ver como a 'frustração' no raciocínio pode afetar a qualidade dos resultados do modelo."
O atual líder no benchmark é o o1, alcançando uma pontuação de 59%, seguido pelo recém-lançado o3-mini configurado para alto "esforço de raciocínio" com 47%. O R1 obteve 35%. Os pesquisadores planejam expandir seus testes para mais modelos de raciocínio, esperando identificar áreas para melhoria.
Guha enfatizou a importância de benchmarks acessíveis, afirmando, "Você não precisa de um doutorado para ser bom em raciocínio, então deve ser possível projetar benchmarks de raciocínio que não exijam conhecimento de nível de doutorado. Um benchmark com acesso mais amplo permite que um conjunto mais amplo de pesquisadores compreenda e analise os resultados, o que pode, por sua vez, levar a melhores soluções no futuro. Além disso, à medida que modelos de ponta são cada vez mais implementados em ambientes que afetam a todos, acreditamos que todos deveriam ser capazes de intuir o que esses modelos são — e não são — capazes de fazer."










 O WordPress.com agora permite que agentes de IA escrevam e publiquem posts, entre outras coisas
O WordPress.com, a popular plataforma de hospedagem e publicação na web, está agora adotando agentes de IA — uma iniciativa que pode transformar a aparência e a experiência da web. A empresa anunciou
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
O WordPress.com agora permite que agentes de IA escrevam e publiquem posts, entre outras coisas
O WordPress.com, a popular plataforma de hospedagem e publicação na web, está agora adotando agentes de IA — uma iniciativa que pode transformar a aparência e a experiência da web. A empresa anunciou
A Kakao Mobility apresenta o plano de ação para a direção autônoma de nível 4 com IA física
A Kakao Mobility planeja desenvolver tecnologias de direção autônoma de nível 4 internamente, como parte de sua estratégia de IA física.Na conferência World IT Show 2026, realizada no COEX, em Seul,
 Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future

Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de colorização automática por IA para mangás de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções de ponta e revolucionárias que aplicam cores planas sem nenhum erro de consistência, aumentando sua produtividade. Explore comparações entre versões gratuitas e pagas, testes práticos e rankings atualizados semanalmente para encontrar a opção ideal para você. Aproveite hoje mesmo as vantagens da IA.
10 ferramentas
xix.ai

Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













