
















 Heim
HeimAI -Argumentationsmodelle mit NPR -Sonntagspuzzle -Fragen getestet
Jeden Sonntag begeistert Will Shortz, der Mastermind hinter den Kreuzworträtseln der New York Times, Tausende von Zuhörern mit seinem Segment, dem Sunday Puzzle, bei NPR. Diese Rätsel sind so gestaltet, dass sie mit Allgemeinwissen lösbar sind, stellen jedoch selbst für erfahrene Rätsellöser eine erhebliche Herausforderung dar.
Diese Komplexität ist der Grund, warum einige Experten glauben, dass der Sunday Puzzle als wertvolles Werkzeug dienen könnte, um die Grenzen der Problemlösungsfähigkeiten von KI zu testen.
In einer kürzlich durchgeführten Studie entwickelten Forscher vom Wellesley College, Oberlin College, der University of Texas at Austin, der Northeastern University, der Charles University und dem Startup Cursor einen KI-Benchmark unter Verwendung von Rätseln aus dem Sunday Puzzle. Ihre Ergebnisse zeigten faszinierende Verhaltensweisen bei Reasoning-Modellen, einschließlich OpenAI's o1, das gelegentlich „aufgibt“ und wissentlich falsche Antworten liefert.
Arjun Guha, ein Informatikprofessor an der Northeastern und Mitautor der Studie, erklärte gegenüber TechCrunch, dass das Ziel war, einen Benchmark zu erstellen, der für jeden mit Allgemeinwissen verständlich ist. Er bemerkte: „Wir wollten einen Benchmark mit Problemen entwickeln, die Menschen nur mit Allgemeinwissen verstehen können.“
Die KI-Branche steht derzeit vor einer Herausforderung beim Benchmarking, da viele Tests auf fortgeschrittene Fähigkeiten wie Mathematik und Naturwissenschaften auf PhD-Niveau fokussiert sind, die für die meisten Nutzer nicht relevant sind. Darüber hinaus sind selbst kürzlich veröffentlichte Benchmarks fast gesättigt.
Der Sunday Puzzle bietet einen einzigartigen Vorteil, da er nicht auf spezialisiertes Wissen angewiesen ist und sein Format verhindert, dass KI-Modelle einfach auswendig gelernte Antworten wiedergeben, so Guha. Er erläuterte: „Ich denke, was diese Probleme schwierig macht, ist, dass es wirklich schwer ist, bedeutende Fortschritte bei einem Problem zu machen, bis man es löst – das ist der Moment, in dem alles plötzlich zusammenpasst. Das erfordert eine Kombination aus Einsicht und einem Ausschlussverfahren.“
Allerdings hat der Sunday Puzzle auch seine Grenzen. Er ist stark auf die US-Kultur zentriert und verwendet ausschließlich Englisch, und es besteht das Risiko, dass Modelle, die auf diesen Rätseln trainiert wurden, „schummeln“ könnten, wenn sie die Fragen zuvor gesehen haben. Guha beruhigt jedoch, dass er dafür noch keine Beweise gefunden hat. Er fügte hinzu: „Neue Fragen werden jede Woche veröffentlicht, und wir können davon ausgehen, dass die neuesten Fragen wirklich ungesehen sind. Wir beabsichtigen, den Benchmark frisch zu halten und zu verfolgen, wie sich die Leistung der Modelle im Laufe der Zeit verändert.“
Der Benchmark der Forscher, der etwa 600 Rätsel aus dem Sunday Puzzle umfasst, zeigte, dass Reasoning-Modelle wie o1 und DeepSeek's R1 andere Modelle deutlich übertrafen. Diese Modelle überprüfen sich selbst akribisch, was ihnen hilft, häufige Fehler zu vermeiden. Diese Gründlichkeit bedeutet jedoch, dass sie länger brauchen, um eine Lösung zu finden – typischerweise einige Sekunden bis Minuten mehr.
Interessanterweise gibt DeepSeek's R1 manchmal auf und sagt „Ich gebe auf“, bevor es eine zufällige falsche Antwort liefert – eine Reaktion, mit der viele Menschen mitfühlen können. Andere merkwürdige Verhaltensweisen, die beobachtet wurden, umfassen Modelle, die eine falsche Antwort geben, diese zurückziehen, einen weiteren Versuch starten und erneut scheitern. Einige Modelle geraten in endlose Schleifen des „Nachdenkens“, liefern unsinnige Erklärungen oder beantworten eine Frage korrekt, um dann unnötigerweise alternative Antworten zu erkunden.
Guha kommentierte das Verhalten von R1 und sagte: „Bei schwierigen Problemen sagt R1 buchstäblich, dass es ‚frustriert‘ ist. Es war amüsant zu sehen, wie ein Modell nachahmt, was ein Mensch sagen könnte. Es bleibt abzuwarten, wie ‚Frustration‘ beim Reasoning die Qualität der Modellergebnisse beeinflussen kann.“

R1 wird bei einer Frage im Sunday Puzzle-Herausforderungsset „frustriert“.Bildnachweis:Guha et al. Der derzeitige Spitzenreiter im Benchmark ist o1 mit einem Ergebnis von 59 %, gefolgt von dem kürzlich veröffentlichten o3-mini, das auf hohe „Reasoning-Anstrengung“ eingestellt ist, mit 47 %. R1 erzielte 35 %. Die Forscher planen, ihre Tests auf weitere Reasoning-Modelle auszuweiten, in der Hoffnung, Verbesserungsbereiche zu identifizieren.
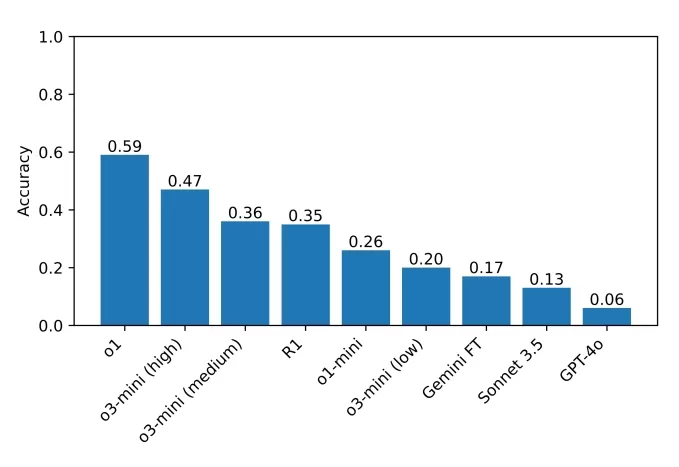
Die Punktzahlen der Modelle, die das Team in ihrem Benchmark getestet hat.Bildnachweis:Guha et al. Guha betonte die Bedeutung zugänglicher Benchmarks und erklärte: „Man braucht keinen PhD, um gut im Reasoning zu sein, daher sollte es möglich sein, Reasoning-Benchmarks zu entwerfen, die kein Wissen auf PhD-Niveau erfordern. Ein Benchmark mit breiterem Zugang ermöglicht es einer größeren Gruppe von Forschern, die Ergebnisse zu verstehen und zu analysieren, was wiederum in Zukunft zu besseren Lösungen führen kann. Darüber hinaus glauben wir, dass jeder in der Lage sein sollte, intuitiv zu erfassen, was diese Modelle können – und was nicht –, da modernste Modelle zunehmend in Bereichen eingesetzt werden, die jeden betreffen.“
Verwandter Artikel
 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
 10 Tools
10 Tools
 xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai
Code
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

 Kommentare (12)
Kommentare (12)
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Jeden Sonntag begeistert Will Shortz, der Mastermind hinter den Kreuzworträtseln der New York Times, Tausende von Zuhörern mit seinem Segment, dem Sunday Puzzle, bei NPR. Diese Rätsel sind so gestaltet, dass sie mit Allgemeinwissen lösbar sind, stellen jedoch selbst für erfahrene Rätsellöser eine erhebliche Herausforderung dar.
Diese Komplexität ist der Grund, warum einige Experten glauben, dass der Sunday Puzzle als wertvolles Werkzeug dienen könnte, um die Grenzen der Problemlösungsfähigkeiten von KI zu testen.
In einer kürzlich durchgeführten Studie entwickelten Forscher vom Wellesley College, Oberlin College, der University of Texas at Austin, der Northeastern University, der Charles University und dem Startup Cursor einen KI-Benchmark unter Verwendung von Rätseln aus dem Sunday Puzzle. Ihre Ergebnisse zeigten faszinierende Verhaltensweisen bei Reasoning-Modellen, einschließlich OpenAI's o1, das gelegentlich „aufgibt“ und wissentlich falsche Antworten liefert.
Arjun Guha, ein Informatikprofessor an der Northeastern und Mitautor der Studie, erklärte gegenüber TechCrunch, dass das Ziel war, einen Benchmark zu erstellen, der für jeden mit Allgemeinwissen verständlich ist. Er bemerkte: „Wir wollten einen Benchmark mit Problemen entwickeln, die Menschen nur mit Allgemeinwissen verstehen können.“
Die KI-Branche steht derzeit vor einer Herausforderung beim Benchmarking, da viele Tests auf fortgeschrittene Fähigkeiten wie Mathematik und Naturwissenschaften auf PhD-Niveau fokussiert sind, die für die meisten Nutzer nicht relevant sind. Darüber hinaus sind selbst kürzlich veröffentlichte Benchmarks fast gesättigt.
Der Sunday Puzzle bietet einen einzigartigen Vorteil, da er nicht auf spezialisiertes Wissen angewiesen ist und sein Format verhindert, dass KI-Modelle einfach auswendig gelernte Antworten wiedergeben, so Guha. Er erläuterte: „Ich denke, was diese Probleme schwierig macht, ist, dass es wirklich schwer ist, bedeutende Fortschritte bei einem Problem zu machen, bis man es löst – das ist der Moment, in dem alles plötzlich zusammenpasst. Das erfordert eine Kombination aus Einsicht und einem Ausschlussverfahren.“
Allerdings hat der Sunday Puzzle auch seine Grenzen. Er ist stark auf die US-Kultur zentriert und verwendet ausschließlich Englisch, und es besteht das Risiko, dass Modelle, die auf diesen Rätseln trainiert wurden, „schummeln“ könnten, wenn sie die Fragen zuvor gesehen haben. Guha beruhigt jedoch, dass er dafür noch keine Beweise gefunden hat. Er fügte hinzu: „Neue Fragen werden jede Woche veröffentlicht, und wir können davon ausgehen, dass die neuesten Fragen wirklich ungesehen sind. Wir beabsichtigen, den Benchmark frisch zu halten und zu verfolgen, wie sich die Leistung der Modelle im Laufe der Zeit verändert.“
Der Benchmark der Forscher, der etwa 600 Rätsel aus dem Sunday Puzzle umfasst, zeigte, dass Reasoning-Modelle wie o1 und DeepSeek's R1 andere Modelle deutlich übertrafen. Diese Modelle überprüfen sich selbst akribisch, was ihnen hilft, häufige Fehler zu vermeiden. Diese Gründlichkeit bedeutet jedoch, dass sie länger brauchen, um eine Lösung zu finden – typischerweise einige Sekunden bis Minuten mehr.
Interessanterweise gibt DeepSeek's R1 manchmal auf und sagt „Ich gebe auf“, bevor es eine zufällige falsche Antwort liefert – eine Reaktion, mit der viele Menschen mitfühlen können. Andere merkwürdige Verhaltensweisen, die beobachtet wurden, umfassen Modelle, die eine falsche Antwort geben, diese zurückziehen, einen weiteren Versuch starten und erneut scheitern. Einige Modelle geraten in endlose Schleifen des „Nachdenkens“, liefern unsinnige Erklärungen oder beantworten eine Frage korrekt, um dann unnötigerweise alternative Antworten zu erkunden.
Guha kommentierte das Verhalten von R1 und sagte: „Bei schwierigen Problemen sagt R1 buchstäblich, dass es ‚frustriert‘ ist. Es war amüsant zu sehen, wie ein Modell nachahmt, was ein Mensch sagen könnte. Es bleibt abzuwarten, wie ‚Frustration‘ beim Reasoning die Qualität der Modellergebnisse beeinflussen kann.“
Der derzeitige Spitzenreiter im Benchmark ist o1 mit einem Ergebnis von 59 %, gefolgt von dem kürzlich veröffentlichten o3-mini, das auf hohe „Reasoning-Anstrengung“ eingestellt ist, mit 47 %. R1 erzielte 35 %. Die Forscher planen, ihre Tests auf weitere Reasoning-Modelle auszuweiten, in der Hoffnung, Verbesserungsbereiche zu identifizieren.
Guha betonte die Bedeutung zugänglicher Benchmarks und erklärte: „Man braucht keinen PhD, um gut im Reasoning zu sein, daher sollte es möglich sein, Reasoning-Benchmarks zu entwerfen, die kein Wissen auf PhD-Niveau erfordern. Ein Benchmark mit breiterem Zugang ermöglicht es einer größeren Gruppe von Forschern, die Ergebnisse zu verstehen und zu analysieren, was wiederum in Zukunft zu besseren Lösungen führen kann. Darüber hinaus glauben wir, dass jeder in der Lage sein sollte, intuitiv zu erfassen, was diese Modelle können – und was nicht –, da modernste Modelle zunehmend in Bereichen eingesetzt werden, die jeden betreffen.“










 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
 Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













