
















 Дом
ДомМодели AI «Рассуждения», протестированные с помощью воскресной головоломки NPR.
Каждое воскресенье Уилл Шортц, создатель кроссвордов The New York Times, увлекает тысячи слушателей своим сегментом на NPR — Sunday Puzzle. Эти головоломки созданы так, чтобы их можно было решить с общими знаниями, но они представляют значительный вызов даже для опытных решателей.
Эта сложность заставляет некоторых экспертов считать Sunday Puzzle ценным инструментом для тестирования границ возможностей ИИ в решении задач.
В недавнем исследовании ученые из колледжей Уэллсли, Оберлин, Техасского университета в Остине, Северо-восточного университета, Карлова университета и стартапа Cursor разработали эталон ИИ, используя загадки из Sunday Puzzle. Их выводы выявили интересные особенности в моделях рассуждений, включая o1 от OpenAI, которые иногда «сдаются» и дают заведомо неверные ответы.
Арджун Гуха, профессор компьютерных наук Северо-восточного университета и соавтор исследования, объяснил TechCrunch, что целью было создание эталона, понятного любому с общими знаниями. Он отметил: «Мы хотели разработать эталон с задачами, которые люди могут понять, имея только общие знания».
Индустрия ИИ сталкивается с проблемой тестирования, поскольку многие тесты ориентированы на продвинутые навыки, такие как математика и наука уровня PhD, которые не актуальны для большинства пользователей. Кроме того, даже недавно выпущенные эталоны близки к насыщению.
Sunday Puzzle имеет уникальное преимущество, поскольку не требует специальных знаний, а его формат предотвращает простое воспроизведение ИИ заученных ответов, по словам Гуха. Он пояснил: «Я думаю, что сложность этих задач в том, что трудно добиться значительного прогресса, пока не решишь их — тогда всё сразу становится на свои места. Это требует сочетания интуиции и метода исключения».
Однако Sunday Puzzle не лишена ограничений. Она ориентирована на культуру США и использует только английский язык, и есть риск, что модели, обученные на этих головоломках, могут «обманывать», если ранее видели вопросы. Гуха успокаивает, что пока доказательств этого нет. Он добавил: «Новые вопросы выпускаются каждую неделю, и мы можем ожидать, что последние вопросы действительно неизвестны. Мы намерены поддерживать эталон актуальным и отслеживать, как производительность моделей меняется со временем».
Эталон исследователей, включающий около 600 загадок Sunday Puzzle, показал, что модели рассуждений, такие как o1 и R1 от DeepSeek, значительно превосходят другие модели. Эти модели тщательно проверяют себя, что помогает избегать распространенных ошибок. Однако такая тщательность означает, что им требуется больше времени на решение — обычно от нескольких секунд до минут.
Интересно, что R1 от DeepSeek иногда признаёт поражение, говоря «Я сдаюсь», прежде чем дать случайный неверный ответ — реакция, с которой многие люди могут себя ассоциировать. Среди других странных поведений замечено, что модели дают неверный ответ, отзывают его, пробуют другой и снова ошибаются. Некоторые модели застревают в бесконечных циклах «размышлений», дают бессмысленные объяснения или правильно отвечают на вопрос, но затем излишне исследуют альтернативные ответы.
Гуха прокомментировал поведение R1: «На сложных задачах R1 буквально говорит, что испытывает ‘раздражение’. Было забавно видеть, как модель имитирует то, что мог бы сказать человек. Еще предстоит выяснить, как ‘раздражение’ в рассуждениях влияет на качество результатов модели».

R1 испытывает «раздражение» на вопросе из набора Sunday Puzzle. Источник изображения: Гуха и др. Текущий лидер эталона — o1 с результатом 59%, за ним следует недавно выпущенный o3-mini с высоким «усилием рассуждений» на уровне 47%. R1 набрала 35%. Исследователи планируют расширить тестирование на другие модели рассуждений, надеясь выявить области для улучшения.
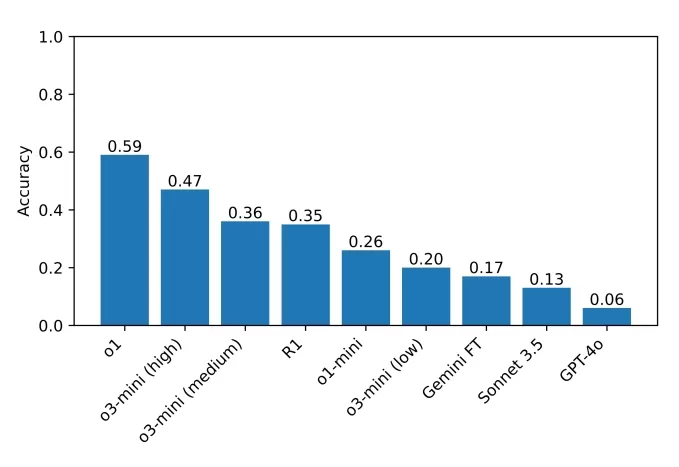
Результаты моделей, протестированных командой на их эталоне. Источник изображения: Гуха и др. Гуха подчеркнул важность доступных эталонов, заявив: «Для хорошего рассуждения не нужен PhD, поэтому должны быть возможны эталоны рассуждений, не требующие знаний уровня PhD. Эталон с более широким доступом позволяет большему числу исследователей понимать и анализировать результаты, что в будущем может привести к лучшим решениям. Кроме того, поскольку современные модели всё чаще применяются в ситуациях, затрагивающих всех, мы считаем, что каждый должен иметь возможность интуитивно понимать, на что эти модели способны — и на что нет».
Связанная статья
 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Барри Диллер: доверие к Сэму Альтману теряет значение по мере приближения эры общей искусственной интеллигенции
Миллиардер и медиа-магнат Барри Диллер не считает генерального директора OpenAI Сэма Альтмана недостойным доверия, несмотря на недавние сообщения, свидетельствующие об обратном. Выступая на этой недел
Рекомендации по связанным специальным темам
Создание анимации
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Барри Диллер: доверие к Сэму Альтману теряет значение по мере приближения эры общей искусственной интеллигенции
Миллиардер и медиа-магнат Барри Диллер не считает генерального директора OpenAI Сэма Альтмана недостойным доверия, несмотря на недавние сообщения, свидетельствующие об обратном. Выступая на этой недел
Рекомендации по связанным специальным темам
Создание анимации
 Генератор аниме на основе искусственного интеллекта для Donghua: Создание персонажей для веб-романов и аватаров для комиксов
Генератор аниме на основе искусственного интеллекта для Donghua: Создание персонажей для веб-романов и аватаров для комиксов
Откройте для себя лучшие генераторы аниме на основе искусственного интеллекта 2026 года для создания донхуа. Наш список, составленный специально для вас, включает мощные инструменты, позволяющие создавать потрясающих персонажей для веб-новелл и комиксов. Сравните бесплатные и платные варианты на основе реальных тестов. Найдите идеального помощника в творчестве и превратите свои истории в жизнь сегодня на сайте XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Создание комиксов
Лучшие инструменты для автоматической раскраски манги с помощью ИИ: нанесение плоских цветов без ошибок в цветовом решении
xix.ai
Создание комиксов
Лучшие инструменты для автоматической раскраски манги с помощью ИИ: нанесение плоских цветов без ошибок в цветовом решении
Откройте для себя лучшие инструменты для автоматической раскраски манги с помощью ИИ в 2026 году на сайте XIX.AI. В нашем тщательно составленном списке представлены самые популярные и революционные решения, которые наносят плоские цвета без единой ошибки в цветовом соответствии, что значительно повышает вашу продуктивность. Изучите сравнения бесплатных и платных версий, результаты реальных тестов и еженедельно обновляемые рейтинги, чтобы найти идеальный вариант для себя. Воспользуйтесь преимуществами ИИ уже сегодня.
10 инструментов
xix.ai
письмо
Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

 Комментарии (12)
Комментарии (12)
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Каждое воскресенье Уилл Шортц, создатель кроссвордов The New York Times, увлекает тысячи слушателей своим сегментом на NPR — Sunday Puzzle. Эти головоломки созданы так, чтобы их можно было решить с общими знаниями, но они представляют значительный вызов даже для опытных решателей.
Эта сложность заставляет некоторых экспертов считать Sunday Puzzle ценным инструментом для тестирования границ возможностей ИИ в решении задач.
В недавнем исследовании ученые из колледжей Уэллсли, Оберлин, Техасского университета в Остине, Северо-восточного университета, Карлова университета и стартапа Cursor разработали эталон ИИ, используя загадки из Sunday Puzzle. Их выводы выявили интересные особенности в моделях рассуждений, включая o1 от OpenAI, которые иногда «сдаются» и дают заведомо неверные ответы.
Арджун Гуха, профессор компьютерных наук Северо-восточного университета и соавтор исследования, объяснил TechCrunch, что целью было создание эталона, понятного любому с общими знаниями. Он отметил: «Мы хотели разработать эталон с задачами, которые люди могут понять, имея только общие знания».
Индустрия ИИ сталкивается с проблемой тестирования, поскольку многие тесты ориентированы на продвинутые навыки, такие как математика и наука уровня PhD, которые не актуальны для большинства пользователей. Кроме того, даже недавно выпущенные эталоны близки к насыщению.
Sunday Puzzle имеет уникальное преимущество, поскольку не требует специальных знаний, а его формат предотвращает простое воспроизведение ИИ заученных ответов, по словам Гуха. Он пояснил: «Я думаю, что сложность этих задач в том, что трудно добиться значительного прогресса, пока не решишь их — тогда всё сразу становится на свои места. Это требует сочетания интуиции и метода исключения».
Однако Sunday Puzzle не лишена ограничений. Она ориентирована на культуру США и использует только английский язык, и есть риск, что модели, обученные на этих головоломках, могут «обманывать», если ранее видели вопросы. Гуха успокаивает, что пока доказательств этого нет. Он добавил: «Новые вопросы выпускаются каждую неделю, и мы можем ожидать, что последние вопросы действительно неизвестны. Мы намерены поддерживать эталон актуальным и отслеживать, как производительность моделей меняется со временем».
Эталон исследователей, включающий около 600 загадок Sunday Puzzle, показал, что модели рассуждений, такие как o1 и R1 от DeepSeek, значительно превосходят другие модели. Эти модели тщательно проверяют себя, что помогает избегать распространенных ошибок. Однако такая тщательность означает, что им требуется больше времени на решение — обычно от нескольких секунд до минут.
Интересно, что R1 от DeepSeek иногда признаёт поражение, говоря «Я сдаюсь», прежде чем дать случайный неверный ответ — реакция, с которой многие люди могут себя ассоциировать. Среди других странных поведений замечено, что модели дают неверный ответ, отзывают его, пробуют другой и снова ошибаются. Некоторые модели застревают в бесконечных циклах «размышлений», дают бессмысленные объяснения или правильно отвечают на вопрос, но затем излишне исследуют альтернативные ответы.
Гуха прокомментировал поведение R1: «На сложных задачах R1 буквально говорит, что испытывает ‘раздражение’. Было забавно видеть, как модель имитирует то, что мог бы сказать человек. Еще предстоит выяснить, как ‘раздражение’ в рассуждениях влияет на качество результатов модели».
Текущий лидер эталона — o1 с результатом 59%, за ним следует недавно выпущенный o3-mini с высоким «усилием рассуждений» на уровне 47%. R1 набрала 35%. Исследователи планируют расширить тестирование на другие модели рассуждений, надеясь выявить области для улучшения.
Гуха подчеркнул важность доступных эталонов, заявив: «Для хорошего рассуждения не нужен PhD, поэтому должны быть возможны эталоны рассуждений, не требующие знаний уровня PhD. Эталон с более широким доступом позволяет большему числу исследователей понимать и анализировать результаты, что в будущем может привести к лучшим решениям. Кроме того, поскольку современные модели всё чаще применяются в ситуациях, затрагивающих всех, мы считаем, что каждый должен иметь возможность интуитивно понимать, на что эти модели способны — и на что нет».










 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
 Барри Диллер: доверие к Сэму Альтману теряет значение по мере приближения эры общей искусственной интеллигенции
Миллиардер и медиа-магнат Барри Диллер не считает генерального директора OpenAI Сэма Альтмана недостойным доверия, несмотря на недавние сообщения, свидетельствующие об обратном. Выступая на этой недел
Барри Диллер: доверие к Сэму Альтману теряет значение по мере приближения эры общей искусственной интеллигенции
Миллиардер и медиа-магнат Барри Диллер не считает генерального директора OpenAI Сэма Альтмана недостойным доверия, несмотря на недавние сообщения, свидетельствующие об обратном. Выступая на этой недел

Откройте для себя лучшие генераторы аниме на основе искусственного интеллекта 2026 года для создания донхуа. Наш список, составленный специально для вас, включает мощные инструменты, позволяющие создавать потрясающих персонажей для веб-новелл и комиксов. Сравните бесплатные и платные варианты на основе реальных тестов. Найдите идеального помощника в творчестве и превратите свои истории в жизнь сегодня на сайте XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие инструменты для автоматической раскраски манги с помощью ИИ в 2026 году на сайте XIX.AI. В нашем тщательно составленном списке представлены самые популярные и революционные решения, которые наносят плоские цвета без единой ошибки в цветовом соответствии, что значительно повышает вашу продуктивность. Изучите сравнения бесплатных и платных версий, результаты реальных тестов и еженедельно обновляемые рейтинги, чтобы найти идеальный вариант для себя. Воспользуйтесь преимуществами ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai

Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













