
















 首頁
首頁AI“推理”模型已通過NPR週日拼圖問題測試
每週日,NPR的Will Shortz,這位《紐約時報》填字遊戲的策劃者,透過他的「週日謎題」節目吸引了數千名聽眾。這些謎題設計上只需一般知識即可解答,但即使對資深的謎題愛好者來說,也具有相當的挑戰性。
這種複雜性使得一些專家認為,週日謎題可用於測試AI問題解決能力的極限,成為一個有價值的工具。
在一項近期研究中,來自Wellesley College、Oberlin College、德克薩斯大學奧斯汀分校、東北大學、查爾斯大學以及新創公司Cursor的研究人員,利用週日謎題中的謎語開發了一個AI基準。他們的發現揭示了推理模型的一些有趣行為,包括OpenAI的o1模型,有時會「放棄」並故意給出錯誤答案。
東北大學計算機科學教授、該研究的共同作者Arjun Guha向TechCrunch解釋,目標是創建一個任何具備一般知識的人都能理解的基準。他表示:「我們希望開發一個只需一般知識就能理解問題的基準。」
當前AI行業在基準測試方面面臨挑戰,因為許多測試聚焦於博士級別的數學和科學等高級技能,這些對大多數用戶來說並不相關。此外,即使是最近發布的基準也已接近飽和。
根據Guha的說法,週日謎題的獨特優勢在於它不依賴專業知識,且其格式能防止AI模型僅僅重複記憶的答案。他進一步說明:「我認為這些問題的難度在於,在解決問題之前很難取得實質進展——一旦解決,一切就會瞬間豁然開朗。這需要洞察力和排除法的結合。」
然而,週日謎題也有其局限性。它以美國文化為中心,且僅使用英語,且存在模型若事先見過這些問題可能「作弊」的風險。Guha安慰說,他尚未發現這方面的證據。他補充道:「每週都會發布新問題,我們可以期待最新的問題是真正未被見過的。我們打算保持基準的新鮮度,並追蹤模型性能隨時間的變化。」
研究人員的基準包含大約600個週日謎題的謎語,顯示像o1和DeepSeek的R1這樣的推理模型顯著優於其他模型。這些模型會仔細檢查自己的事實,這有助於它們避免常見錯誤。然而,這種徹底性意味著它們需要更長時間才能得出解決方案——通常多花幾秒到幾分鐘。
有趣的是,DeepSeek的R1有時會承認失敗,說「我放棄了」,然後給出一個隨機的錯誤答案——這是許多人類都能感同身受的反應。其他觀察到的奇特行為包括模型給出錯誤答案後撤回,嘗試另一個猜測後再次失敗。一些模型陷入無休止的「思考」循環,提供荒誕的解釋,或在正確回答問題後仍不必要地探索其他答案。
Guha評論R1的行為時說:「在困難問題上,R1甚至會說它感到『沮喪』。看到模型模仿人類可能說的話真是有趣。推理中的『沮喪』如何影響模型結果的質量仍有待觀察。」

R1在週日謎題挑戰集中的一個問題上感到「沮喪」。圖片來源:Guha等人 當前基準的頂尖表現者是o1,得分59%,其次是最近發布的o3-mini在高「推理努力」設置下得47%。R1得分35%。研究人員計劃擴展對更多推理模型的測試,希望找出改進的領域。
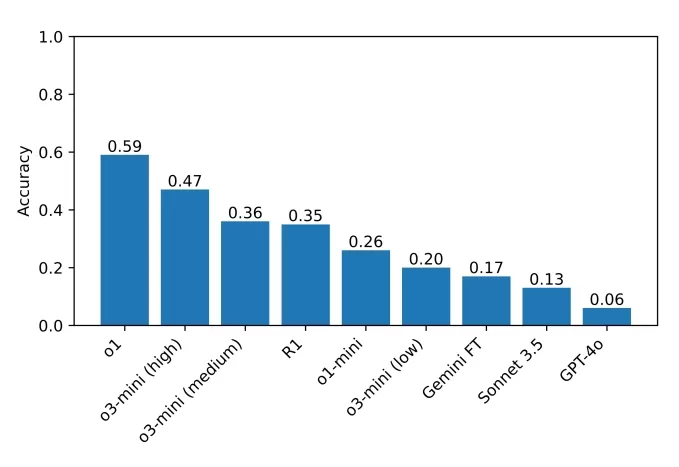
團隊在基準測試中測試的模型得分。圖片來源:Guha等人 Guha強調了可訪問基準的重要性,說道:「你不需要博士學位就能擅長推理,因此應該可以設計出不需要博士級知識的推理基準。更廣泛的基準讓更多研究人員能夠理解和分析結果,這可能會在未來帶來更好的解決方案。此外,隨著最先進的模型越來越多地應用於影響每個人的場景,我們相信每個人都應該能夠直觀理解這些模型的能力與局限。」
相關文章
 Notion 將其工作區轉變為人工智慧代理的樞紐
生產力軟體公司 Notion 正邁入「代理時代」。在週三的直播產品發布會上,以協作式筆記應用程式聞名的 Notion 揭曉了一套全新的開發者平台,該平台不僅擴展了其自訂 AI 代理程式的能力,還能與外部代理程式串接,並讓團隊建立自動化多步驟工作流程,從任何資料庫中擷取資料。透過建立一個「協調層」——一個能在多個工具和資料來源之間協調 AI 工作的系統——Notion 將自身定位為不僅僅是一款具備
ElevenLabs 宣布 BlackRock、傑米·福克斯與伊娃·朗格莉亞成為新投資人
語音人工智慧公司 ElevenLabs 已公布其 5 億美元 D 輪融資的更多投資者名單,該輪融資最初於二月宣布。 投資者陣容包括黑石集團(BlackRock)、威靈頓管理(Wellington)、D.E. Shaw及施羅德(Schroders)等機構投資者;NVIDIA、Salesforce、桑坦德銀行(Santander)、KPN及德國電信(Deutsche Telekom)等企業;以及傑米·
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
相關專題推薦
健康與養生
Notion 將其工作區轉變為人工智慧代理的樞紐
生產力軟體公司 Notion 正邁入「代理時代」。在週三的直播產品發布會上,以協作式筆記應用程式聞名的 Notion 揭曉了一套全新的開發者平台,該平台不僅擴展了其自訂 AI 代理程式的能力,還能與外部代理程式串接,並讓團隊建立自動化多步驟工作流程,從任何資料庫中擷取資料。透過建立一個「協調層」——一個能在多個工具和資料來源之間協調 AI 工作的系統——Notion 將自身定位為不僅僅是一款具備
ElevenLabs 宣布 BlackRock、傑米·福克斯與伊娃·朗格莉亞成為新投資人
語音人工智慧公司 ElevenLabs 已公布其 5 億美元 D 輪融資的更多投資者名單,該輪融資最初於二月宣布。 投資者陣容包括黑石集團(BlackRock)、威靈頓管理(Wellington)、D.E. Shaw及施羅德(Schroders)等機構投資者;NVIDIA、Salesforce、桑坦德銀行(Santander)、KPN及德國電信(Deutsche Telekom)等企業;以及傑米·
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
相關專題推薦
健康與養生
 AI 孕期輔助系統:生成安全且按孕期分階段的運動與營養計畫
AI 孕期輔助系統:生成安全且按孕期分階段的運動與營養計畫
探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
 10 個工具
10 個工具
 xix.ai
寫作
最佳免費且無法被偵測的 AI 寫手:將機械化的草稿轉化為自然、類人化的散文
xix.ai
寫作
最佳免費且無法被偵測的 AI 寫手:將機械化的草稿轉化為自然、類人化的散文
立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai
圖像編輯
用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

 評論 (12)
0/500
評論 (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
每週日,NPR的Will Shortz,這位《紐約時報》填字遊戲的策劃者,透過他的「週日謎題」節目吸引了數千名聽眾。這些謎題設計上只需一般知識即可解答,但即使對資深的謎題愛好者來說,也具有相當的挑戰性。
這種複雜性使得一些專家認為,週日謎題可用於測試AI問題解決能力的極限,成為一個有價值的工具。
在一項近期研究中,來自Wellesley College、Oberlin College、德克薩斯大學奧斯汀分校、東北大學、查爾斯大學以及新創公司Cursor的研究人員,利用週日謎題中的謎語開發了一個AI基準。他們的發現揭示了推理模型的一些有趣行為,包括OpenAI的o1模型,有時會「放棄」並故意給出錯誤答案。
東北大學計算機科學教授、該研究的共同作者Arjun Guha向TechCrunch解釋,目標是創建一個任何具備一般知識的人都能理解的基準。他表示:「我們希望開發一個只需一般知識就能理解問題的基準。」
當前AI行業在基準測試方面面臨挑戰,因為許多測試聚焦於博士級別的數學和科學等高級技能,這些對大多數用戶來說並不相關。此外,即使是最近發布的基準也已接近飽和。
根據Guha的說法,週日謎題的獨特優勢在於它不依賴專業知識,且其格式能防止AI模型僅僅重複記憶的答案。他進一步說明:「我認為這些問題的難度在於,在解決問題之前很難取得實質進展——一旦解決,一切就會瞬間豁然開朗。這需要洞察力和排除法的結合。」
然而,週日謎題也有其局限性。它以美國文化為中心,且僅使用英語,且存在模型若事先見過這些問題可能「作弊」的風險。Guha安慰說,他尚未發現這方面的證據。他補充道:「每週都會發布新問題,我們可以期待最新的問題是真正未被見過的。我們打算保持基準的新鮮度,並追蹤模型性能隨時間的變化。」
研究人員的基準包含大約600個週日謎題的謎語,顯示像o1和DeepSeek的R1這樣的推理模型顯著優於其他模型。這些模型會仔細檢查自己的事實,這有助於它們避免常見錯誤。然而,這種徹底性意味著它們需要更長時間才能得出解決方案——通常多花幾秒到幾分鐘。
有趣的是,DeepSeek的R1有時會承認失敗,說「我放棄了」,然後給出一個隨機的錯誤答案——這是許多人類都能感同身受的反應。其他觀察到的奇特行為包括模型給出錯誤答案後撤回,嘗試另一個猜測後再次失敗。一些模型陷入無休止的「思考」循環,提供荒誕的解釋,或在正確回答問題後仍不必要地探索其他答案。
Guha評論R1的行為時說:「在困難問題上,R1甚至會說它感到『沮喪』。看到模型模仿人類可能說的話真是有趣。推理中的『沮喪』如何影響模型結果的質量仍有待觀察。」
當前基準的頂尖表現者是o1,得分59%,其次是最近發布的o3-mini在高「推理努力」設置下得47%。R1得分35%。研究人員計劃擴展對更多推理模型的測試,希望找出改進的領域。
Guha強調了可訪問基準的重要性,說道:「你不需要博士學位就能擅長推理,因此應該可以設計出不需要博士級知識的推理基準。更廣泛的基準讓更多研究人員能夠理解和分析結果,這可能會在未來帶來更好的解決方案。此外,隨著最先進的模型越來越多地應用於影響每個人的場景,我們相信每個人都應該能夠直觀理解這些模型的能力與局限。」










 Notion 將其工作區轉變為人工智慧代理的樞紐
生產力軟體公司 Notion 正邁入「代理時代」。在週三的直播產品發布會上,以協作式筆記應用程式聞名的 Notion 揭曉了一套全新的開發者平台,該平台不僅擴展了其自訂 AI 代理程式的能力,還能與外部代理程式串接,並讓團隊建立自動化多步驟工作流程,從任何資料庫中擷取資料。透過建立一個「協調層」——一個能在多個工具和資料來源之間協調 AI 工作的系統——Notion 將自身定位為不僅僅是一款具備
Notion 將其工作區轉變為人工智慧代理的樞紐
生產力軟體公司 Notion 正邁入「代理時代」。在週三的直播產品發布會上,以協作式筆記應用程式聞名的 Notion 揭曉了一套全新的開發者平台,該平台不僅擴展了其自訂 AI 代理程式的能力,還能與外部代理程式串接,並讓團隊建立自動化多步驟工作流程,從任何資料庫中擷取資料。透過建立一個「協調層」——一個能在多個工具和資料來源之間協調 AI 工作的系統——Notion 將自身定位為不僅僅是一款具備
 ElevenLabs 宣布 BlackRock、傑米·福克斯與伊娃·朗格莉亞成為新投資人
語音人工智慧公司 ElevenLabs 已公布其 5 億美元 D 輪融資的更多投資者名單,該輪融資最初於二月宣布。 投資者陣容包括黑石集團(BlackRock)、威靈頓管理(Wellington)、D.E. Shaw及施羅德(Schroders)等機構投資者;NVIDIA、Salesforce、桑坦德銀行(Santander)、KPN及德國電信(Deutsche Telekom)等企業;以及傑米·
ElevenLabs 宣布 BlackRock、傑米·福克斯與伊娃·朗格莉亞成為新投資人
語音人工智慧公司 ElevenLabs 已公布其 5 億美元 D 輪融資的更多投資者名單,該輪融資最初於二月宣布。 投資者陣容包括黑石集團(BlackRock)、威靈頓管理(Wellington)、D.E. Shaw及施羅德(Schroders)等機構投資者;NVIDIA、Salesforce、桑坦德銀行(Santander)、KPN及德國電信(Deutsche Telekom)等企業;以及傑米·
 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理

探索 2026 年最佳 AI 孕期輔助工具,為您量身打造安全且針對各孕期的運動與營養計畫。獲取精選的高評分推薦,包含免費與付費方案的比較,以及實用經驗分享。透過 XIX.AI 的專家指南,開啟您最健康的孕期旅程。立即探索。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最頂尖的免費且難以被察覺的 AI 寫手。我們精心篩選的頂級清單,能協助您將生硬的草稿轉化為自然流暢、宛如人類撰寫的文字。透過實際測試與每週更新的排行榜,比較免費與付費選項的優劣。立即解鎖您的 AI 寫作優勢。
10 個工具
xix.ai

2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













