
















 首页
首页AI“推理”模型已通过NPR周日拼图问题测试
每周日,NPR的威尔·肖茨,《纽约时报》填字游戏的策划者,通过他的“周日谜题”节目吸引了数千名听众。这些谜题设计为仅需一般知识即可解答,但即便对经验丰富的解谜者也构成了重大挑战。
这种复杂性使得一些专家认为,周日谜题可以作为测试AI问题解决能力界限的宝贵工具。
在一项近期研究中,来自威尔斯利学院、奥伯林学院、德克萨斯大学奥斯汀分校、东北大学、查尔斯大学以及初创公司Cursor的研究人员,利用周日谜题中的谜语开发了一个AI基准测试。他们的发现揭示了推理模型的一些有趣行为,包括OpenAI的o1模型,它偶尔会“放弃”并故意给出错误答案。
东北大学的计算机科学教授、该研究的共同作者阿琼·古哈向TechCrunch解释,目标是创建一个任何具备一般知识的人都能理解的基准测试。他表示:“我们希望开发一个仅需一般知识就能理解问题的基准测试。”
AI行业目前在基准测试方面面临挑战,因为许多测试聚焦于博士级别的数学和科学等高级技能,这些对大多数用户并不相关。此外,即使是最近发布的基准测试也已接近饱和。
据古哈介绍,周日谜题的独特优势在于它不依赖专业知识,其格式能防止AI模型简单地复述记忆中的答案。他进一步解释:“我认为这些问题之所以难,是因为在解决之前很难取得实质性进展——只有当一切豁然开朗时,问题才会迎刃而解。这需要洞察力和排除法的结合。”
然而,周日谜题也有其局限性。它以美国文化为中心,仅使用英语,且存在模型可能因提前见过问题而“作弊”的风险。不过,古哈安慰道,他尚未发现这方面的证据。他补充说:“每周都会发布新问题,我们可以预期最新问题是真正未见过的。我们打算保持基准测试的新鲜度,并追踪模型性能随时间的变化。”
研究人员的基准测试包含约600个周日谜题的谜语,显示出像o1和DeepSeek的R1这样的推理模型明显优于其他模型。这些模型会仔细核查事实,帮助它们避免常见错误。然而,这种彻底性意味着它们需要更长时间得出答案——通常多几秒到几分钟。
有趣的是,DeepSeek的R1有时会承认失败,说“我放弃了”,然后给出一个随机的错误答案——这种反应让许多人感同身受。其他奇特行为包括模型给出一个错误答案后撤回,再次尝试猜测但仍失败。一些模型陷入无休止的“思考”循环,提供荒诞的解释,或在正确回答问题后仍不必要地探索其他答案。
古哈评论R1的行为时说:“在难题上,R1明确表示它感到‘沮丧’。看到模型模仿人类的说法很有趣。推理中的‘沮丧’如何影响模型结果的质量仍有待观察。”

R1在周日谜题挑战集的一个问题上感到“沮丧”。图片来源:古哈等人 当前基准测试的最高得分者是o1,得分为59%,其次是最近发布的o3-mini在高“推理努力”设置下得分47%。R1得分为35%。研究人员计划扩展测试到更多推理模型,希望找出改进的领域。
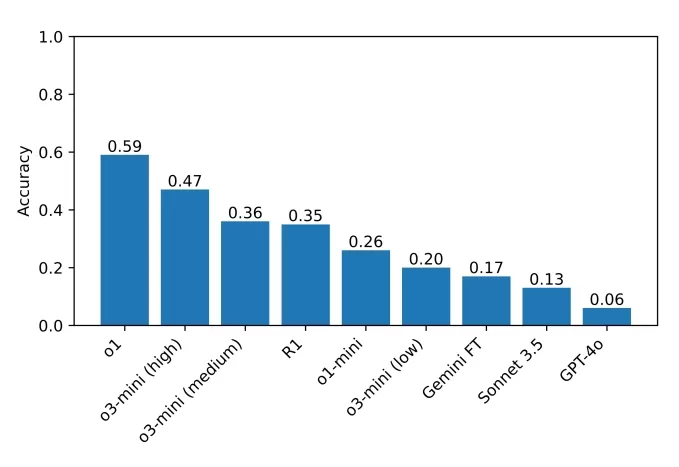
团队测试的模型在基准测试中的得分。图片来源:古哈等人 古哈强调了可访问基准测试的重要性,他说:“你不需要博士学位就能擅长推理,因此应该可以设计出不要求博士级知识的推理基准测试。具有更广泛访问性的基准测试能让更多研究人员理解和分析结果,这可能会在未来带来更好的解决方案。此外,随着最先进的模型越来越多地部署在影响每个人的场景中,我们认为每个人都应该能够直观了解这些模型的能力和局限性。”
相关文章
 Notion 将其工作区转变为人工智能代理的枢纽
生产力软件公司 Notion 正迈入智能代理时代。在周三的一场直播产品发布会上,以协作式笔记应用而闻名的 Notion 推出了一款全新的开发者平台。该平台不仅扩展了其定制 AI 代理的功能,还能与外部代理连接,并允许团队构建能够从任何数据库提取数据的自动化多步骤工作流。通过构建一个编排层——即一个能在多个工具和数据源之间协调AI工作的系统——Notion将自身定位为不仅仅是一款具备AI功能的笔记应
ElevenLabs宣布黑石集团、杰米·福克斯和伊娃·朗格利亚成为新投资者
语音人工智能公司ElevenLabs披露了其5亿美元D轮融资的更多投资者名单,该轮融资最初于2月宣布。 其中包括贝莱德(BlackRock)、威灵顿(Wellington)、D.E. Shaw和施罗德(Schroders)等机构投资者;英伟达(NVIDIA)、Salesforce、桑坦德银行(Santander)、KPN和德国电信(Deutsche Telekom)等企业;以及杰米·福克斯(Jam
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
相关专题推荐
写作
Notion 将其工作区转变为人工智能代理的枢纽
生产力软件公司 Notion 正迈入智能代理时代。在周三的一场直播产品发布会上,以协作式笔记应用而闻名的 Notion 推出了一款全新的开发者平台。该平台不仅扩展了其定制 AI 代理的功能,还能与外部代理连接,并允许团队构建能够从任何数据库提取数据的自动化多步骤工作流。通过构建一个编排层——即一个能在多个工具和数据源之间协调AI工作的系统——Notion将自身定位为不仅仅是一款具备AI功能的笔记应
ElevenLabs宣布黑石集团、杰米·福克斯和伊娃·朗格利亚成为新投资者
语音人工智能公司ElevenLabs披露了其5亿美元D轮融资的更多投资者名单,该轮融资最初于2月宣布。 其中包括贝莱德(BlackRock)、威灵顿(Wellington)、D.E. Shaw和施罗德(Schroders)等机构投资者;英伟达(NVIDIA)、Salesforce、桑坦德银行(Santander)、KPN和德国电信(Deutsche Telekom)等企业;以及杰米·福克斯(Jam
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
相关专题推荐
写作
 最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
最适合广播和播客使用的AI脚本编写工具:帮助您创作引人入胜的音频广告
在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
 10 个工具
10 个工具
 xix.ai
商业
最佳 AI 合同审查软件:即时发现法律漏洞与合规风险
xix.ai
商业
最佳 AI 合同审查软件:即时发现法律漏洞与合规风险
在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai
动画创作
专为东华设计的AI动漫生成器:可用于创建网络小说角色及漫画头像
探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai
漫画创作
漫画领域顶尖的AI自动上色工具:零一致性错误地应用平涂色彩
立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai
写作
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

 评论 (12)
0/500
评论 (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
每周日,NPR的威尔·肖茨,《纽约时报》填字游戏的策划者,通过他的“周日谜题”节目吸引了数千名听众。这些谜题设计为仅需一般知识即可解答,但即便对经验丰富的解谜者也构成了重大挑战。
这种复杂性使得一些专家认为,周日谜题可以作为测试AI问题解决能力界限的宝贵工具。
在一项近期研究中,来自威尔斯利学院、奥伯林学院、德克萨斯大学奥斯汀分校、东北大学、查尔斯大学以及初创公司Cursor的研究人员,利用周日谜题中的谜语开发了一个AI基准测试。他们的发现揭示了推理模型的一些有趣行为,包括OpenAI的o1模型,它偶尔会“放弃”并故意给出错误答案。
东北大学的计算机科学教授、该研究的共同作者阿琼·古哈向TechCrunch解释,目标是创建一个任何具备一般知识的人都能理解的基准测试。他表示:“我们希望开发一个仅需一般知识就能理解问题的基准测试。”
AI行业目前在基准测试方面面临挑战,因为许多测试聚焦于博士级别的数学和科学等高级技能,这些对大多数用户并不相关。此外,即使是最近发布的基准测试也已接近饱和。
据古哈介绍,周日谜题的独特优势在于它不依赖专业知识,其格式能防止AI模型简单地复述记忆中的答案。他进一步解释:“我认为这些问题之所以难,是因为在解决之前很难取得实质性进展——只有当一切豁然开朗时,问题才会迎刃而解。这需要洞察力和排除法的结合。”
然而,周日谜题也有其局限性。它以美国文化为中心,仅使用英语,且存在模型可能因提前见过问题而“作弊”的风险。不过,古哈安慰道,他尚未发现这方面的证据。他补充说:“每周都会发布新问题,我们可以预期最新问题是真正未见过的。我们打算保持基准测试的新鲜度,并追踪模型性能随时间的变化。”
研究人员的基准测试包含约600个周日谜题的谜语,显示出像o1和DeepSeek的R1这样的推理模型明显优于其他模型。这些模型会仔细核查事实,帮助它们避免常见错误。然而,这种彻底性意味着它们需要更长时间得出答案——通常多几秒到几分钟。
有趣的是,DeepSeek的R1有时会承认失败,说“我放弃了”,然后给出一个随机的错误答案——这种反应让许多人感同身受。其他奇特行为包括模型给出一个错误答案后撤回,再次尝试猜测但仍失败。一些模型陷入无休止的“思考”循环,提供荒诞的解释,或在正确回答问题后仍不必要地探索其他答案。
古哈评论R1的行为时说:“在难题上,R1明确表示它感到‘沮丧’。看到模型模仿人类的说法很有趣。推理中的‘沮丧’如何影响模型结果的质量仍有待观察。”
当前基准测试的最高得分者是o1,得分为59%,其次是最近发布的o3-mini在高“推理努力”设置下得分47%。R1得分为35%。研究人员计划扩展测试到更多推理模型,希望找出改进的领域。
古哈强调了可访问基准测试的重要性,他说:“你不需要博士学位就能擅长推理,因此应该可以设计出不要求博士级知识的推理基准测试。具有更广泛访问性的基准测试能让更多研究人员理解和分析结果,这可能会在未来带来更好的解决方案。此外,随着最先进的模型越来越多地部署在影响每个人的场景中,我们认为每个人都应该能够直观了解这些模型的能力和局限性。”










 Notion 将其工作区转变为人工智能代理的枢纽
生产力软件公司 Notion 正迈入智能代理时代。在周三的一场直播产品发布会上,以协作式笔记应用而闻名的 Notion 推出了一款全新的开发者平台。该平台不仅扩展了其定制 AI 代理的功能,还能与外部代理连接,并允许团队构建能够从任何数据库提取数据的自动化多步骤工作流。通过构建一个编排层——即一个能在多个工具和数据源之间协调AI工作的系统——Notion将自身定位为不仅仅是一款具备AI功能的笔记应
Notion 将其工作区转变为人工智能代理的枢纽
生产力软件公司 Notion 正迈入智能代理时代。在周三的一场直播产品发布会上,以协作式笔记应用而闻名的 Notion 推出了一款全新的开发者平台。该平台不仅扩展了其定制 AI 代理的功能,还能与外部代理连接,并允许团队构建能够从任何数据库提取数据的自动化多步骤工作流。通过构建一个编排层——即一个能在多个工具和数据源之间协调AI工作的系统——Notion将自身定位为不仅仅是一款具备AI功能的笔记应
 ElevenLabs宣布黑石集团、杰米·福克斯和伊娃·朗格利亚成为新投资者
语音人工智能公司ElevenLabs披露了其5亿美元D轮融资的更多投资者名单,该轮融资最初于2月宣布。 其中包括贝莱德(BlackRock)、威灵顿(Wellington)、D.E. Shaw和施罗德(Schroders)等机构投资者;英伟达(NVIDIA)、Salesforce、桑坦德银行(Santander)、KPN和德国电信(Deutsche Telekom)等企业;以及杰米·福克斯(Jam
ElevenLabs宣布黑石集团、杰米·福克斯和伊娃·朗格利亚成为新投资者
语音人工智能公司ElevenLabs披露了其5亿美元D轮融资的更多投资者名单,该轮融资最初于2月宣布。 其中包括贝莱德(BlackRock)、威灵顿(Wellington)、D.E. Shaw和施罗德(Schroders)等机构投资者;英伟达(NVIDIA)、Salesforce、桑坦德银行(Santander)、KPN和德国电信(Deutsche Telekom)等企业;以及杰米·福克斯(Jam
 WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运
WordPress.com 现已支持 AI 助手撰写和发布文章,还有更多功能
广受欢迎的网站托管和发布平台 WordPress.com 现已开始引入人工智能助手——这一举措或将重塑网络的呈现方式。该公司于周五宣布,将允许人工智能助手在用户网站上起草、编辑和发布内容,同时还能管理评论、更新和修正元数据,并通过标签和分类对内容进行整理。所有这些操作均通过一个界面进行控制,网站所有者只需使用自然语言命令说明其需求即可。凭借这些新功能,网站几乎可以完全由人工指导的AI代理来创建和运

在XIX.AI上,发现2026年最适合用于广播和播客制作的AI脚本工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您快速制作出引人入胜的音频广告。通过实际测试和每周更新的排名,您可以了解免费选项与付费选项之间的差异。今天就释放您的创造力吧!
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 合同审查软件。我们精心筛选的顶级榜单汇集了功能强大的工具,能够即时发现法律漏洞和合规风险。通过实际测试和每周更新的排名,对比免费与付费选项。找到能彻底改变游戏规则的解决方案,实现安全、高效的合同分析。立即探索这本权威指南。
10 个工具
xix.ai

探索2026年最适合制作中文动画的人工智能工具。我们精心挑选的顶级列表中包含了各种强大的工具,能够帮助你创建出令人惊叹的网络小说角色和漫画头像。通过实际测试来对比免费选项和付费选项,找到最适合你的创作工具,今天就在XIX.AI上将你的故事变为现实吧。
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













