
















 Hogar
HogarModelos de 'razonamiento' de ai probados con preguntas de rompecabezas de NPR Sunday
Cada domingo, Will Shortz de NPR, la mente maestra detrás de los crucigramas del New York Times, cautiva a miles de oyentes con su segmento, el Sunday Puzzle. Estos acertijos están diseñados para ser resueltos con conocimientos generales, pero representan un desafío significativo incluso para los solucionadores de acertijos experimentados.
Esta complejidad es la razón por la que algunos expertos creen que el Sunday Puzzle podría servir como una herramienta valiosa para probar los límites de las capacidades de resolución de problemas de la IA.
En un estudio reciente, investigadores de Wellesley College, Oberlin College, la Universidad de Texas en Austin, Northeastern University, la Universidad Charles y la startup Cursor desarrollaron un punto de referencia de IA utilizando acertijos del Sunday Puzzle. Sus hallazgos revelaron comportamientos intrigantes en modelos de razonamiento, incluido el o1 de OpenAI, que en ocasiones "se rinde" y ofrece respuestas incorrectas a sabiendas.
Arjun Guha, profesor de ciencias de la computación en Northeastern y coautor del estudio, explicó a TechCrunch que el objetivo era crear un punto de referencia que cualquier persona con conocimientos generales pudiera entender. Señaló, "Queríamos desarrollar un punto de referencia con problemas que los humanos puedan entender con solo conocimientos generales."
La industria de la IA enfrenta actualmente un desafío con los puntos de referencia, ya que muchas pruebas se centran en habilidades avanzadas como matemáticas y ciencias a nivel de doctorado, que no son relevantes para la mayoría de los usuarios. Además, incluso los puntos de referencia recientemente lanzados están acercándose a la saturación.
El Sunday Puzzle ofrece una ventaja única porque no depende de conocimientos especializados, y su formato evita que los modelos de IA simplemente regurgiten respuestas memorizadas, según Guha. Él explicó, "Creo que lo que hace que estos problemas sean difíciles es que es realmente complicado avanzar significativamente en un problema hasta que lo resuelves — es cuando todo encaja de repente. Eso requiere una combinación de perspicacia y un proceso de eliminación."
Sin embargo, el Sunday Puzzle no está exento de limitaciones. Está centrado en la cultura estadounidense y usa solo inglés, y existe el riesgo de que los modelos entrenados con estos acertijos puedan "hacer trampa" si han visto las preguntas antes. Guha asegura, sin embargo, que aún no ha encontrado evidencia de esto. Añadió, "Se lanzan nuevas preguntas cada semana, y podemos esperar que las últimas preguntas sean realmente nuevas. Pretendemos mantener el punto de referencia actualizado y seguir cómo cambia el rendimiento de los modelos con el tiempo."
El punto de referencia de los investigadores, que incluye alrededor de 600 acertijos del Sunday Puzzle, mostró que los modelos de razonamiento como o1 y R1 de DeepSeek superaron significativamente a otros modelos. Estos modelos verifican meticulosamente sus propios datos, lo que les ayuda a evitar errores comunes. Sin embargo, esta minuciosidad significa que tardan más en llegar a una solución — típicamente de unos segundos a minutos más.
Curiosamente, R1 de DeepSeek a veces admite la derrota, diciendo "me rindo", antes de ofrecer una respuesta incorrecta al azar — una reacción con la que muchos humanos pueden empatizar. Otros comportamientos peculiares observados incluyen modelos que dan una respuesta equivocada, la retractan, intentan otra suposición y fallan nuevamente. Algunos modelos se quedan atrapados en bucles interminables de "pensamiento", proporcionan explicaciones sin sentido o responden correctamente a una pregunta solo para luego explorar respuestas alternativas innecesariamente.
Guha comentó sobre el comportamiento de R1, diciendo, "En problemas difíciles, R1 literalmente dice que está 'frustrado'. Fue divertido ver cómo un modelo emula lo que un humano podría decir. Queda por ver cómo la 'frustración' en el razonamiento puede afectar la calidad de los resultados del modelo."

R1 se "frustra" con una pregunta en el conjunto de desafíos del Sunday Puzzle. Créditos de la imagen: Guha et al. El mejor desempeño actual en el punto de referencia es o1, con un puntaje del 59%, seguido por el recientemente lanzado o3-mini configurado en un alto "esfuerzo de razonamiento" con un 47%. R1 obtuvo un 35%. Los investigadores planean expandir sus pruebas a más modelos de razonamiento, esperando identificar áreas para mejorar.
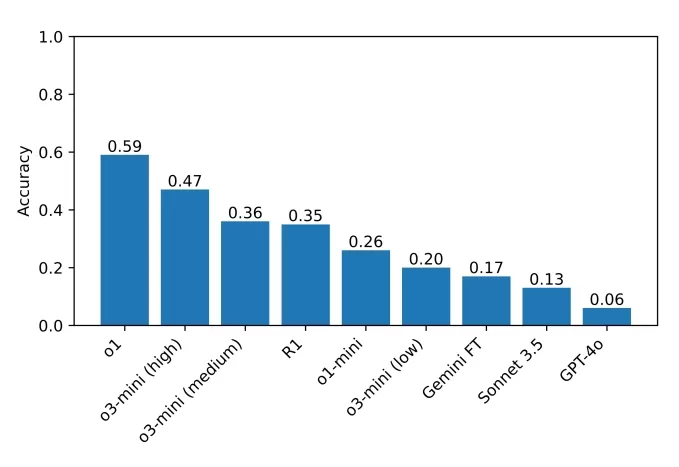
Las puntuaciones de los modelos que el equipo probó en su punto de referencia. Créditos de la imagen: Guha et al. Guha enfatizó la importancia de los puntos de referencia accesibles, declarando, "No necesitas un doctorado para ser bueno en razonamiento, por lo que debería ser posible diseñar puntos de referencia de razonamiento que no requieran conocimientos a nivel de doctorado. Un punto de referencia con un acceso más amplio permite que un conjunto más amplio de investigadores comprenda y analice los resultados, lo que puede llevar a mejores soluciones en el futuro. Además, a medida que los modelos de última generación se implementan cada vez más en entornos que afectan a todos, creemos que todos deberían poder intuir qué son —y qué no son— capaces de hacer estos modelos."
Artículo relacionado
 WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
Recomendaciones de temas especiales relacionados
Creación de animación
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
Recomendaciones de temas especiales relacionados
Creación de animación
 Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Creación de cómics
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
xix.ai
Creación de cómics
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

 comentario (12)
0/500
comentario (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Cada domingo, Will Shortz de NPR, la mente maestra detrás de los crucigramas del New York Times, cautiva a miles de oyentes con su segmento, el Sunday Puzzle. Estos acertijos están diseñados para ser resueltos con conocimientos generales, pero representan un desafío significativo incluso para los solucionadores de acertijos experimentados.
Esta complejidad es la razón por la que algunos expertos creen que el Sunday Puzzle podría servir como una herramienta valiosa para probar los límites de las capacidades de resolución de problemas de la IA.
En un estudio reciente, investigadores de Wellesley College, Oberlin College, la Universidad de Texas en Austin, Northeastern University, la Universidad Charles y la startup Cursor desarrollaron un punto de referencia de IA utilizando acertijos del Sunday Puzzle. Sus hallazgos revelaron comportamientos intrigantes en modelos de razonamiento, incluido el o1 de OpenAI, que en ocasiones "se rinde" y ofrece respuestas incorrectas a sabiendas.
Arjun Guha, profesor de ciencias de la computación en Northeastern y coautor del estudio, explicó a TechCrunch que el objetivo era crear un punto de referencia que cualquier persona con conocimientos generales pudiera entender. Señaló, "Queríamos desarrollar un punto de referencia con problemas que los humanos puedan entender con solo conocimientos generales."
La industria de la IA enfrenta actualmente un desafío con los puntos de referencia, ya que muchas pruebas se centran en habilidades avanzadas como matemáticas y ciencias a nivel de doctorado, que no son relevantes para la mayoría de los usuarios. Además, incluso los puntos de referencia recientemente lanzados están acercándose a la saturación.
El Sunday Puzzle ofrece una ventaja única porque no depende de conocimientos especializados, y su formato evita que los modelos de IA simplemente regurgiten respuestas memorizadas, según Guha. Él explicó, "Creo que lo que hace que estos problemas sean difíciles es que es realmente complicado avanzar significativamente en un problema hasta que lo resuelves — es cuando todo encaja de repente. Eso requiere una combinación de perspicacia y un proceso de eliminación."
Sin embargo, el Sunday Puzzle no está exento de limitaciones. Está centrado en la cultura estadounidense y usa solo inglés, y existe el riesgo de que los modelos entrenados con estos acertijos puedan "hacer trampa" si han visto las preguntas antes. Guha asegura, sin embargo, que aún no ha encontrado evidencia de esto. Añadió, "Se lanzan nuevas preguntas cada semana, y podemos esperar que las últimas preguntas sean realmente nuevas. Pretendemos mantener el punto de referencia actualizado y seguir cómo cambia el rendimiento de los modelos con el tiempo."
El punto de referencia de los investigadores, que incluye alrededor de 600 acertijos del Sunday Puzzle, mostró que los modelos de razonamiento como o1 y R1 de DeepSeek superaron significativamente a otros modelos. Estos modelos verifican meticulosamente sus propios datos, lo que les ayuda a evitar errores comunes. Sin embargo, esta minuciosidad significa que tardan más en llegar a una solución — típicamente de unos segundos a minutos más.
Curiosamente, R1 de DeepSeek a veces admite la derrota, diciendo "me rindo", antes de ofrecer una respuesta incorrecta al azar — una reacción con la que muchos humanos pueden empatizar. Otros comportamientos peculiares observados incluyen modelos que dan una respuesta equivocada, la retractan, intentan otra suposición y fallan nuevamente. Algunos modelos se quedan atrapados en bucles interminables de "pensamiento", proporcionan explicaciones sin sentido o responden correctamente a una pregunta solo para luego explorar respuestas alternativas innecesariamente.
Guha comentó sobre el comportamiento de R1, diciendo, "En problemas difíciles, R1 literalmente dice que está 'frustrado'. Fue divertido ver cómo un modelo emula lo que un humano podría decir. Queda por ver cómo la 'frustración' en el razonamiento puede afectar la calidad de los resultados del modelo."
El mejor desempeño actual en el punto de referencia es o1, con un puntaje del 59%, seguido por el recientemente lanzado o3-mini configurado en un alto "esfuerzo de razonamiento" con un 47%. R1 obtuvo un 35%. Los investigadores planean expandir sus pruebas a más modelos de razonamiento, esperando identificar áreas para mejorar.
Guha enfatizó la importancia de los puntos de referencia accesibles, declarando, "No necesitas un doctorado para ser bueno en razonamiento, por lo que debería ser posible diseñar puntos de referencia de razonamiento que no requieran conocimientos a nivel de doctorado. Un punto de referencia con un acceso más amplio permite que un conjunto más amplio de investigadores comprenda y analice los resultados, lo que puede llevar a mejores soluciones en el futuro. Además, a medida que los modelos de última generación se implementan cada vez más en entornos que afectan a todos, creemos que todos deberían poder intuir qué son —y qué no son— capaces de hacer estos modelos."










 WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
WordPress.com ya permite que los agentes de IA redacten y publiquen entradas, entre otras cosas
WordPress.com, la popular plataforma de alojamiento web y publicación, está incorporando ahora agentes de IA, una iniciativa que podría transformar el aspecto y la experiencia de la web. La empresa an
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
 Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere

Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













