
















 家
家NPRサンデーパズルの質問でテストされたAI '推論モデル
毎週日曜日、NPRのウィル・ショーツ、ニューヨーク・タイムズのクロスワードパズルの仕掛け人が、彼のセグメント「サンデーパズル」で何千人ものリスナーを引きつけます。これらのパズルは一般知識で解けるように作られていますが、経験豊富なパズル愛好者にとってもかなりの挑戦となります。
この複雑さが、一部の専門家がサンデーパズルがAIの問題解決能力の限界をテストする貴重なツールになり得ると考える理由です。
最近の研究では、ウェルズリー大学、オバーリン大学、テキサス大学オースティン校、ノースイースタン大学、チャールズ大学、そしてスタートアップのCursorの研究者たちが、サンデーパズルのなぞなぞを使ったAIベンチマークを開発しました。彼らの発見は、OpenAIのo1を含む推論モデルが、時折「諦める」ことや、知っていて間違った答えを提供するなど、興味深い行動を示しました。
ノースイースタンのコンピュータサイエンス教授であり、研究の共著者であるアージュン・グハは、TechCrunchに対し、目標は一般知識を持つ人なら誰でも理解できるベンチマークを作ることだったと説明しました。彼は「私たちは、一般知識だけで人間が理解できる問題を使ったベンチマークを開発したかった」と述べました。
AI業界は現在、ベンチマークにおける課題に直面しています。多くのテストは、博士レベルの数学や科学など、ほとんどのユーザーに関係のない高度なスキルに焦点を当てています。さらに、最近リリースされたベンチマークでさえ、飽和状態に近づいています。
グハによると、サンデーパズルは専門知識に依存せず、その形式がAIモデルが単に記憶した答えを吐き出すことを防ぐため、独自の利点を提供します。彼は「これらの問題を難しくしているのは、問題を解くまで意味のある進展を遂げることが非常に難しい点です。すべてが一気に繋がるのはその瞬間です。それには洞察力と排除プロセスの組み合わせが必要です」と詳しく説明しました。
しかし、サンデーパズルには限界もあります。それは米国文化を中心に構成されており、英語のみを使用しています。また、モデルが以前に問題を見たことがある場合、「カンニング」するリスクがあります。グハはまだその証拠を見つけていないと安心させますが、「新しい問題は毎週リリースされ、最新の問題は本当に見たことがないものと期待できます。ベンチマークを新鮮に保ち、モデルのパフォーマンスが時間とともにどう変化するかを追跡するつもりです」と付け加えました。
研究者のベンチマークには、約600のサンデーパズルのなぞなぞが含まれており、o1やDeepSeekのR1のような推論モデルが他のモデルを大きく上回りました。これらのモデルは自身を綿密に事実確認し、よくある落とし穴を回避します。ただし、この徹底さは、解決に数秒から数分長くかかることを意味します。
興味深いことに、DeepSeekのR1は時折敗北を認め、「諦めます」と言ってランダムな間違った答えを提供します。これは多くの人間が共感できる反応です。観察された他の奇妙な行動には、モデルが間違った答えを出し、それを撤回し、別の推測を試みて再び失敗する、といったものがあります。一部のモデルは「思考」の無限ループに陥ったり、意味不明な説明を提供したり、正しい答えを出した後に不必要に他の答えを探ったりします。
グハはR1の行動について、「難しい問題では、R1が文字通り『苛立っている』と言います。モデルが人間が言うかもしれないことを模倣するのは面白かったです。推論における『苛立ち』がモデルの結果の質にどのように影響するかは、今後の課題です」とコメントしました。

サンデーパズルチャレンジセットの質問で「苛立つ」R1。画像クレジット:グハら。 現在のベンチマークのトップパフォーマーはo1で、59%のスコアを達成し、次いで最近リリースされた「高推論努力」に設定されたo3-miniが47%、R1は35%でした。研究者たちは、さらに多くの推論モデルをテストに含め、改善の余地を特定することを計画しています。
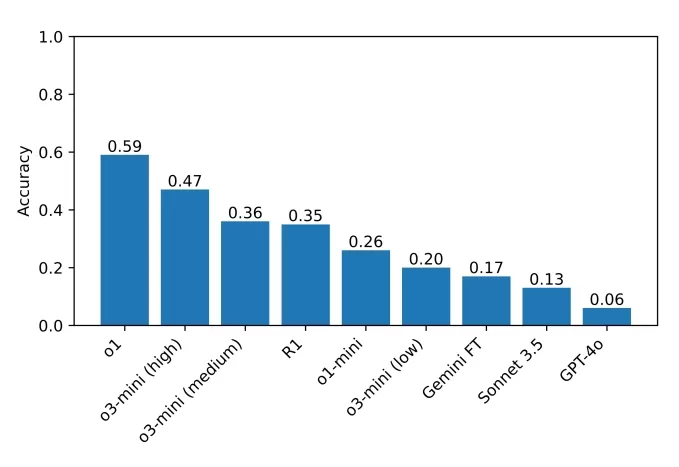
チームがベンチマークでテストしたモデルのスコア。画像クレジット:グハら。 グハはアクセス可能なベンチマークの重要性を強調し、「推論に優れているのに博士号は必要ありません。したがって、博士レベルの知識を必要としない推論ベンチマークを設計できるはずです。より幅広いアクセスが可能なベンチマークは、より多くの研究者が結果を理解し分析することを可能にし、将来的により良い解決策につながる可能性があります。さらに、最先端のモデルがすべての人に影響を与える場面でますます展開される中、誰もがこれらのモデルが何ができ、何ができないかを直感的に理解できるべきだと考えています」と述べました。
関連記事
 WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
関連特集おすすめ
アニメーション制作
WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
関連特集おすすめ
アニメーション制作
 東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
 10 ツール
10 ツール
 xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
xix.ai
漫画制作
漫画向けトップAI自動着色ツール:色むらのないフラットカラーを適用
XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
書き込み
AI小説プロファイル作成のトップクリエイター:一貫性のあるキャラクターの動機と致命的な欠点を生成する
深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai
仕事
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

 コメント (12)
0/500
コメント (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
毎週日曜日、NPRのウィル・ショーツ、ニューヨーク・タイムズのクロスワードパズルの仕掛け人が、彼のセグメント「サンデーパズル」で何千人ものリスナーを引きつけます。これらのパズルは一般知識で解けるように作られていますが、経験豊富なパズル愛好者にとってもかなりの挑戦となります。
この複雑さが、一部の専門家がサンデーパズルがAIの問題解決能力の限界をテストする貴重なツールになり得ると考える理由です。
最近の研究では、ウェルズリー大学、オバーリン大学、テキサス大学オースティン校、ノースイースタン大学、チャールズ大学、そしてスタートアップのCursorの研究者たちが、サンデーパズルのなぞなぞを使ったAIベンチマークを開発しました。彼らの発見は、OpenAIのo1を含む推論モデルが、時折「諦める」ことや、知っていて間違った答えを提供するなど、興味深い行動を示しました。
ノースイースタンのコンピュータサイエンス教授であり、研究の共著者であるアージュン・グハは、TechCrunchに対し、目標は一般知識を持つ人なら誰でも理解できるベンチマークを作ることだったと説明しました。彼は「私たちは、一般知識だけで人間が理解できる問題を使ったベンチマークを開発したかった」と述べました。
AI業界は現在、ベンチマークにおける課題に直面しています。多くのテストは、博士レベルの数学や科学など、ほとんどのユーザーに関係のない高度なスキルに焦点を当てています。さらに、最近リリースされたベンチマークでさえ、飽和状態に近づいています。
グハによると、サンデーパズルは専門知識に依存せず、その形式がAIモデルが単に記憶した答えを吐き出すことを防ぐため、独自の利点を提供します。彼は「これらの問題を難しくしているのは、問題を解くまで意味のある進展を遂げることが非常に難しい点です。すべてが一気に繋がるのはその瞬間です。それには洞察力と排除プロセスの組み合わせが必要です」と詳しく説明しました。
しかし、サンデーパズルには限界もあります。それは米国文化を中心に構成されており、英語のみを使用しています。また、モデルが以前に問題を見たことがある場合、「カンニング」するリスクがあります。グハはまだその証拠を見つけていないと安心させますが、「新しい問題は毎週リリースされ、最新の問題は本当に見たことがないものと期待できます。ベンチマークを新鮮に保ち、モデルのパフォーマンスが時間とともにどう変化するかを追跡するつもりです」と付け加えました。
研究者のベンチマークには、約600のサンデーパズルのなぞなぞが含まれており、o1やDeepSeekのR1のような推論モデルが他のモデルを大きく上回りました。これらのモデルは自身を綿密に事実確認し、よくある落とし穴を回避します。ただし、この徹底さは、解決に数秒から数分長くかかることを意味します。
興味深いことに、DeepSeekのR1は時折敗北を認め、「諦めます」と言ってランダムな間違った答えを提供します。これは多くの人間が共感できる反応です。観察された他の奇妙な行動には、モデルが間違った答えを出し、それを撤回し、別の推測を試みて再び失敗する、といったものがあります。一部のモデルは「思考」の無限ループに陥ったり、意味不明な説明を提供したり、正しい答えを出した後に不必要に他の答えを探ったりします。
グハはR1の行動について、「難しい問題では、R1が文字通り『苛立っている』と言います。モデルが人間が言うかもしれないことを模倣するのは面白かったです。推論における『苛立ち』がモデルの結果の質にどのように影響するかは、今後の課題です」とコメントしました。
現在のベンチマークのトップパフォーマーはo1で、59%のスコアを達成し、次いで最近リリースされた「高推論努力」に設定されたo3-miniが47%、R1は35%でした。研究者たちは、さらに多くの推論モデルをテストに含め、改善の余地を特定することを計画しています。
グハはアクセス可能なベンチマークの重要性を強調し、「推論に優れているのに博士号は必要ありません。したがって、博士レベルの知識を必要としない推論ベンチマークを設計できるはずです。より幅広いアクセスが可能なベンチマークは、より多くの研究者が結果を理解し分析することを可能にし、将来的により良い解決策につながる可能性があります。さらに、最先端のモデルがすべての人に影響を与える場面でますます展開される中、誰もがこれらのモデルが何ができ、何ができないかを直感的に理解できるべきだと考えています」と述べました。










 WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
WordPress.comでは、AIエージェントによる投稿の作成や公開が可能になりました。その他にもさまざまな機能が追加されています。
人気のウェブホスティング・パブリッシングプラットフォームであるWordPress.comが、AIエージェントの導入に乗り出した。この動きは、ウェブのあり方を一変させる可能性がある。同社は金曜日、AIエージェントが顧客のウェブサイト上でコンテンツの下書き作成、編集、公開を行うほか、コメントの管理、メタデータの更新・修正、タグやカテゴリを用いたコンテンツの整理も可能になると発表した。これらすべての操作
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
 バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

XIX.AIで、2026年版のおすすめマンガ用AI自動着色ツールをご覧ください。厳選されたリストには、一貫性の誤差ゼロでフラットカラーを適用し、生産性を飛躍的に向上させる、高評価の画期的なソリューションが揃っています。無料版と有料版の比較、実地テスト、毎週更新されるランキングを参考に、あなたにぴったりのツールを見つけてください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

深みのあるキャラクターを創り出す、2026年最高のAIフィクションプロファイル作成ツールを発見しましょう。XIX.AIが厳選したこのリストには、一貫した動機や致命的な欠点を生成する、高評価で業界を変革するツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐストーリーテリングの可能性を解き放ちましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













