
















 Home
HomeAI 'Reasoning' Models Tested with NPR Sunday Puzzle Questions
Every Sunday, NPR's Will Shortz, the mastermind behind The New York Times' crossword puzzles, engages thousands of listeners with his segment, the Sunday Puzzle. These puzzles are crafted to be solvable with general knowledge, yet they pose a significant challenge even to seasoned puzzle solvers.
This complexity is why some experts believe the Sunday Puzzle could serve as a valuable tool for testing the boundaries of AI's problem-solving capabilities.
In a recent study, researchers from Wellesley College, Oberlin College, the University of Texas at Austin, Northeastern University, Charles University, and the startup Cursor developed an AI benchmark using riddles from the Sunday Puzzle. Their findings revealed intriguing behaviors in reasoning models, including OpenAI's o1, which occasionally "give up" and offer incorrect answers knowingly.
Arjun Guha, a computer science professor at Northeastern and a co-author of the study, explained to TechCrunch that the goal was to create a benchmark that could be understood by anyone with general knowledge. He noted, "We wanted to develop a benchmark with problems that humans can understand with only general knowledge."
The AI industry currently faces a challenge with benchmarking, as many tests focus on advanced skills like PhD-level math and science, which aren't relevant to most users. Moreover, even recently released benchmarks are nearing saturation.
The Sunday Puzzle offers a unique advantage because it doesn't rely on specialized knowledge, and its format prevents AI models from simply regurgitating memorized answers, according to Guha. He elaborated, "I think what makes these problems hard is that it's really difficult to make meaningful progress on a problem until you solve it — that's when everything clicks together all at once. That requires a combination of insight and a process of elimination."
However, the Sunday Puzzle isn't without its limitations. It's centered around U.S. culture and uses only English, and there's a risk that models trained on these puzzles could "cheat" if they've seen the questions before. Guha reassures, though, that he hasn't found evidence of this yet. He added, "New questions are released every week, and we can expect the latest questions to be truly unseen. We intend to keep the benchmark fresh and track how model performance changes over time."
The researchers' benchmark, featuring about 600 Sunday Puzzle riddles, showed that reasoning models like o1 and DeepSeek's R1 significantly outperformed other models. These models meticulously fact-check themselves, which helps them avoid common pitfalls. However, this thoroughness means they take longer to reach a solution — typically a few seconds to minutes more.
Interestingly, DeepSeek's R1 sometimes admits defeat, saying "I give up," before offering a random incorrect answer — a reaction many humans can empathize with. Other peculiar behaviors observed include models giving a wrong answer, retracting it, attempting another guess, and failing again. Some models get stuck in endless loops of "thinking," provide nonsensical explanations, or correctly answer a question only to then explore alternative answers unnecessarily.
Guha remarked on R1's behavior, saying, "On hard problems, R1 literally says that it's getting 'frustrated.' It was funny to see how a model emulates what a human might say. It remains to be seen how 'frustration' in reasoning can affect the quality of model results."

R1 getting “frustrated” on a question in the Sunday Puzzle challenge set.Image Credits:Guha et al.
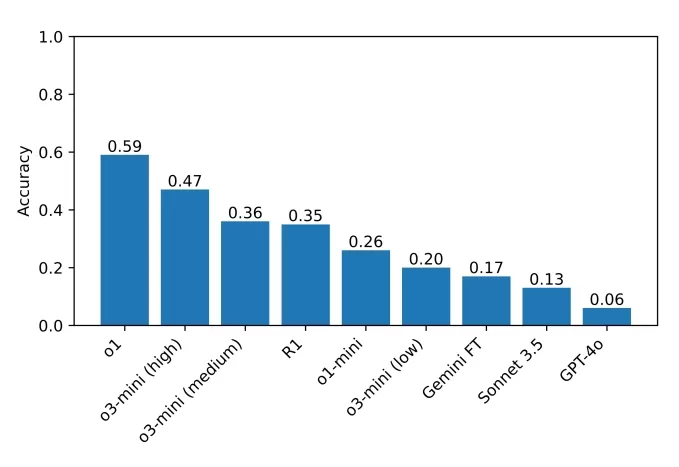
The current top performer on the benchmark is o1, achieving a 59% score, followed by the recently released o3-mini set to high "reasoning effort" at 47%. R1 scored 35%. The researchers plan to expand their testing to more reasoning models, hoping to pinpoint areas for improvement.
The scores of the models the team tested on their benchmark.Image Credits:Guha et al.
Guha emphasized the importance of accessible benchmarks, stating, "You don't need a PhD to be good at reasoning, so it should be possible to design reasoning benchmarks that don't require PhD-level knowledge. A benchmark with broader access allows a wider set of researchers to comprehend and analyze the results, which may in turn lead to better solutions in the future. Furthermore, as state-of-the-art models are increasingly deployed in settings that affect everyone, we believe everyone should be able to intuit what these models are — and aren't — capable of."
Related article
 WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Related Special Topic Recommendations
writing
WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Related Special Topic Recommendations
writing
 Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
 10 tools
10 tools
 xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai
code
Best AI Code Reviewers: Automate Clean Code Compliance & Refactor Legacy Repo Files
Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai
Text-to-speech
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

 Comments (12)
0/500
Comments (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
Every Sunday, NPR's Will Shortz, the mastermind behind The New York Times' crossword puzzles, engages thousands of listeners with his segment, the Sunday Puzzle. These puzzles are crafted to be solvable with general knowledge, yet they pose a significant challenge even to seasoned puzzle solvers.
This complexity is why some experts believe the Sunday Puzzle could serve as a valuable tool for testing the boundaries of AI's problem-solving capabilities.
In a recent study, researchers from Wellesley College, Oberlin College, the University of Texas at Austin, Northeastern University, Charles University, and the startup Cursor developed an AI benchmark using riddles from the Sunday Puzzle. Their findings revealed intriguing behaviors in reasoning models, including OpenAI's o1, which occasionally "give up" and offer incorrect answers knowingly.
Arjun Guha, a computer science professor at Northeastern and a co-author of the study, explained to TechCrunch that the goal was to create a benchmark that could be understood by anyone with general knowledge. He noted, "We wanted to develop a benchmark with problems that humans can understand with only general knowledge."
The AI industry currently faces a challenge with benchmarking, as many tests focus on advanced skills like PhD-level math and science, which aren't relevant to most users. Moreover, even recently released benchmarks are nearing saturation.
The Sunday Puzzle offers a unique advantage because it doesn't rely on specialized knowledge, and its format prevents AI models from simply regurgitating memorized answers, according to Guha. He elaborated, "I think what makes these problems hard is that it's really difficult to make meaningful progress on a problem until you solve it — that's when everything clicks together all at once. That requires a combination of insight and a process of elimination."
However, the Sunday Puzzle isn't without its limitations. It's centered around U.S. culture and uses only English, and there's a risk that models trained on these puzzles could "cheat" if they've seen the questions before. Guha reassures, though, that he hasn't found evidence of this yet. He added, "New questions are released every week, and we can expect the latest questions to be truly unseen. We intend to keep the benchmark fresh and track how model performance changes over time."
The researchers' benchmark, featuring about 600 Sunday Puzzle riddles, showed that reasoning models like o1 and DeepSeek's R1 significantly outperformed other models. These models meticulously fact-check themselves, which helps them avoid common pitfalls. However, this thoroughness means they take longer to reach a solution — typically a few seconds to minutes more.
Interestingly, DeepSeek's R1 sometimes admits defeat, saying "I give up," before offering a random incorrect answer — a reaction many humans can empathize with. Other peculiar behaviors observed include models giving a wrong answer, retracting it, attempting another guess, and failing again. Some models get stuck in endless loops of "thinking," provide nonsensical explanations, or correctly answer a question only to then explore alternative answers unnecessarily.
Guha remarked on R1's behavior, saying, "On hard problems, R1 literally says that it's getting 'frustrated.' It was funny to see how a model emulates what a human might say. It remains to be seen how 'frustration' in reasoning can affect the quality of model results."
The current top performer on the benchmark is o1, achieving a 59% score, followed by the recently released o3-mini set to high "reasoning effort" at 47%. R1 scored 35%. The researchers plan to expand their testing to more reasoning models, hoping to pinpoint areas for improvement.
Guha emphasized the importance of accessible benchmarks, stating, "You don't need a PhD to be good at reasoning, so it should be possible to design reasoning benchmarks that don't require PhD-level knowledge. A benchmark with broader access allows a wider set of researchers to comprehend and analyze the results, which may in turn lead to better solutions in the future. Furthermore, as state-of-the-art models are increasingly deployed in settings that affect everyone, we believe everyone should be able to intuit what these models are — and aren't — capable of."










 WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
 Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman

Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai

Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai

Discover the 2026 best AI code reviewers on XIX.AI. Our curated list features top-rated, game-changing tools for automating clean code compliance and refactoring legacy repo files. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













