
















 집
집AI '추론'모델은 NPR 일요일 퍼즐 질문으로 테스트되었습니다
매주 일요일, NPR의 윌 쇼츠(Will Shortz), 뉴욕 타임스의 크로스워드 퍼즐의 주역은, 수천 명의 청취자들과 함께 일요 퍼즐 세그먼트를 진행합니다. 이 퍼즐들은 일반 지식으로 풀 수 있도록 설계되었지만, 숙련된 퍼즐 해결자들에게도 상당한 도전을 제공합니다.
이 복잡성 때문에 일부 전문가들은 일요 퍼즐이 AI의 문제 해결 능력의 한계를 테스트하는 데 유용한 도구가 될 수 있다고 믿습니다.
최근 연구에서 웰즐리 대학, 오벌린 대학, 텍사스 오스틴 대학, 노스이스턴 대학, 찰스 대학, 그리고 스타트업 커서(Cursor)의 연구원들은 일요 퍼즐의 수수께끼를 사용해 AI 벤치마크를 개발했습니다. 그들의 발견은 OpenAI의 o1을 포함한 추론 모델들이 때때로 "포기"하고 의도적으로 잘못된 답을 제공하는 흥미로운 행동을 보여주었습니다.
노스이스턴의 컴퓨터 과학 교수이자 연구의 공동 저자인 아르준 구하(Arjun Guha)는 테크크런치(TechCrunch)에 목표가 일반 지식만으로 이해할 수 있는 벤치마크를 만드는 것이라고 설명했습니다. 그는 "우리는 일반 지식만으로 사람들이 이해할 수 있는 문제를 가진 벤치마크를 개발하고 싶었다"고 말했습니다.
현재 AI 산업은 벤치마킹에 어려움을 겪고 있으며, 많은 테스트가 박사 수준의 수학 및 과학과 같은 고급 기술에 초점을 맞추고 있어 대부분의 사용자와 관련이 없습니다. 게다가 최근 발표된 벤치마크조차도 포화 상태에 가까워지고 있습니다.
구하에 따르면, 일요 퍼즐은 전문 지식에 의존하지 않고, 그 형식이 AI 모델이 단순히 기억된 답을 되풀이하는 것을 방지하기 때문에 독특한 이점을 제공합니다. 그는 "이 문제들이 어려운 이유는 문제를 해결할 때까지 의미 있는 진전을 이루기가 정말 어렵기 때문입니다. 모든 것이 한 번에 딱 맞아떨어집니다. 이는 통찰력과 제거 과정의 조합을 요구합니다"라고 설명했습니다.
그러나 일요 퍼즐에는 한계가 있습니다. 미국 문화를 중심으로 하며 영어만 사용하고, 모델이 이미 질문을 본 경우 "속임수"를 쓸 위험이 있습니다. 구하는 아직 이런 증거를 찾지 못했다고 안심시켰습니다. 그는 "매주 새로운 질문이 공개되며, 최신 질문은 정말로 보지 못한 질문일 것으로 기대할 수 있습니다. 우리는 벤치마크를 신선하게 유지하고 모델 성능이 시간에 따라 어떻게 변하는지 추적할 계획입니다"라고 덧붙였습니다.
약 600개의 일요 퍼즐 수수께끼를 포함한 연구자들의 벤치마크는 o1과 DeepSeek의 R1과 같은 추론 모델이 다른 모델들을 크게 앞섰음을 보여주었습니다. 이 모델들은 스스로를 꼼꼼히 사실 확인하여 흔한 함정을 피합니다. 그러나 이 철저함은 솔루션에 도달하는 데 더 많은 시간이 걸립니다 — 보통 몇 초에서 몇 분 더 걸립니다.
흥미롭게도, DeepSeek의 R1은 때때로 "포기합니다"라고 말하며 무작위로 잘못된 답을 제공합니다 — 많은 사람들이 공감할 수 있는 반응입니다. 관찰된 다른 특이한 행동으로는 모델이 잘못된 답을 제시한 후 철회하고, 다른 추측을 시도했다가 다시 실패하는 경우가 있습니다. 일부 모델은 "생각"의 끝없는 루프에 갇히거나, 터무니없는 설명을 제공하거나, 정답을 맞춘 후에도 불필요하게 다른 답을 탐색합니다.
구하는 R1의 행동에 대해 언급하며, "어려운 문제에서 R1은 문자 그대로 '좌절하고 있다'고 말합니다. 모델이 인간이 말할 법한 것을 모방하는 모습이 재미있었습니다. 추론에서 '좌절'이 모델 결과의 품질에 어떤 영향을 미칠지는 아직 지켜봐야 합니다"라고 말했습니다.

일요 퍼즐 챌린지 세트에서 질문에 “좌절”하는 R1.이미지 출처:구하 외. 현재 벤치마크에서 최고 성과를 낸 모델은 o1으로 59% 점수를 기록했으며, 최근 출시된 o3-mini는 높은 "추론 노력" 설정에서 47%를 기록했습니다. R1은 35%를 기록했습니다. 연구원들은 더 많은 추론 모델로 테스트를 확장하여 개선 영역을 정확히 파악할 계획입니다.
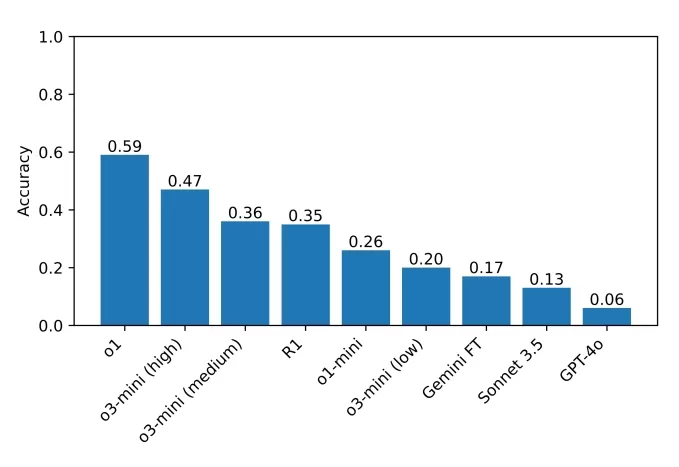
팀이 벤치마크에서 테스트한 모델들의 점수.이미지 출처:구하 외. 구하는 접근 가능한 벤치마크의 중요성을 강조하며, "추론에 능숙하기 위해 박사 학위가 필요하지 않으므로, 박사 수준의 지식을 요구하지 않는 추론 벤치마크를 설계할 수 있어야 합니다. 더 많은 연구자들이 결과를 이해하고 분석할 수 있는 벤치마크는 미래에 더 나은 솔루션으로 이어질 수 있습니다. 또한, 최첨단 모델이 점점 더 모두에게 영향을 미치는 환경에 배포됨에 따라, 모두가 이 모델들이 무엇을 할 수 있고, 할 수 없는지를 직관적으로 이해할 수 있어야 한다고 믿습니다"라고 말했습니다.
관련 기사
 WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
관련 특별 주제 추천
만화 창작
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
관련 특별 주제 추천
만화 창작
 만화용 최고의 AI 자동 채색 도구: 일관성 오류 없이 플랫 컬러 적용하기
만화용 최고의 AI 자동 채색 도구: 일관성 오류 없이 플랫 컬러 적용하기
XIX.AI에서 2026년 최고의 만화 AI 자동 채색 도구를 만나보세요. 저희가 엄선한 이 목록에는 일관성 오류 없이 평면 색상을 적용하여 생산성을 높여주는, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인하여 여러분에게 딱 맞는 도구를 찾아보세요. 지금 바로 AI의 힘을 경험해 보세요.
 10 도구
10 도구
 xix.ai
글쓰기
최고의 AI 소설 캐릭터 생성기: 일관된 캐릭터 동기와 치명적인 결점 생성
xix.ai
글쓰기
최고의 AI 소설 캐릭터 생성기: 일관된 캐릭터 동기와 치명적인 결점 생성
깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
10 도구
xix.ai
사업
최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai
암호
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

 의견 (12)
0/500
의견 (12)
0/500
![RaymondBaker]()
Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
![StephenRamirez]()
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
![PaulTaylor]()
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
![StephenScott]()
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
![CharlesThomas]()
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
![JackMartin]()
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓
매주 일요일, NPR의 윌 쇼츠(Will Shortz), 뉴욕 타임스의 크로스워드 퍼즐의 주역은, 수천 명의 청취자들과 함께 일요 퍼즐 세그먼트를 진행합니다. 이 퍼즐들은 일반 지식으로 풀 수 있도록 설계되었지만, 숙련된 퍼즐 해결자들에게도 상당한 도전을 제공합니다.
이 복잡성 때문에 일부 전문가들은 일요 퍼즐이 AI의 문제 해결 능력의 한계를 테스트하는 데 유용한 도구가 될 수 있다고 믿습니다.
최근 연구에서 웰즐리 대학, 오벌린 대학, 텍사스 오스틴 대학, 노스이스턴 대학, 찰스 대학, 그리고 스타트업 커서(Cursor)의 연구원들은 일요 퍼즐의 수수께끼를 사용해 AI 벤치마크를 개발했습니다. 그들의 발견은 OpenAI의 o1을 포함한 추론 모델들이 때때로 "포기"하고 의도적으로 잘못된 답을 제공하는 흥미로운 행동을 보여주었습니다.
노스이스턴의 컴퓨터 과학 교수이자 연구의 공동 저자인 아르준 구하(Arjun Guha)는 테크크런치(TechCrunch)에 목표가 일반 지식만으로 이해할 수 있는 벤치마크를 만드는 것이라고 설명했습니다. 그는 "우리는 일반 지식만으로 사람들이 이해할 수 있는 문제를 가진 벤치마크를 개발하고 싶었다"고 말했습니다.
현재 AI 산업은 벤치마킹에 어려움을 겪고 있으며, 많은 테스트가 박사 수준의 수학 및 과학과 같은 고급 기술에 초점을 맞추고 있어 대부분의 사용자와 관련이 없습니다. 게다가 최근 발표된 벤치마크조차도 포화 상태에 가까워지고 있습니다.
구하에 따르면, 일요 퍼즐은 전문 지식에 의존하지 않고, 그 형식이 AI 모델이 단순히 기억된 답을 되풀이하는 것을 방지하기 때문에 독특한 이점을 제공합니다. 그는 "이 문제들이 어려운 이유는 문제를 해결할 때까지 의미 있는 진전을 이루기가 정말 어렵기 때문입니다. 모든 것이 한 번에 딱 맞아떨어집니다. 이는 통찰력과 제거 과정의 조합을 요구합니다"라고 설명했습니다.
그러나 일요 퍼즐에는 한계가 있습니다. 미국 문화를 중심으로 하며 영어만 사용하고, 모델이 이미 질문을 본 경우 "속임수"를 쓸 위험이 있습니다. 구하는 아직 이런 증거를 찾지 못했다고 안심시켰습니다. 그는 "매주 새로운 질문이 공개되며, 최신 질문은 정말로 보지 못한 질문일 것으로 기대할 수 있습니다. 우리는 벤치마크를 신선하게 유지하고 모델 성능이 시간에 따라 어떻게 변하는지 추적할 계획입니다"라고 덧붙였습니다.
약 600개의 일요 퍼즐 수수께끼를 포함한 연구자들의 벤치마크는 o1과 DeepSeek의 R1과 같은 추론 모델이 다른 모델들을 크게 앞섰음을 보여주었습니다. 이 모델들은 스스로를 꼼꼼히 사실 확인하여 흔한 함정을 피합니다. 그러나 이 철저함은 솔루션에 도달하는 데 더 많은 시간이 걸립니다 — 보통 몇 초에서 몇 분 더 걸립니다.
흥미롭게도, DeepSeek의 R1은 때때로 "포기합니다"라고 말하며 무작위로 잘못된 답을 제공합니다 — 많은 사람들이 공감할 수 있는 반응입니다. 관찰된 다른 특이한 행동으로는 모델이 잘못된 답을 제시한 후 철회하고, 다른 추측을 시도했다가 다시 실패하는 경우가 있습니다. 일부 모델은 "생각"의 끝없는 루프에 갇히거나, 터무니없는 설명을 제공하거나, 정답을 맞춘 후에도 불필요하게 다른 답을 탐색합니다.
구하는 R1의 행동에 대해 언급하며, "어려운 문제에서 R1은 문자 그대로 '좌절하고 있다'고 말합니다. 모델이 인간이 말할 법한 것을 모방하는 모습이 재미있었습니다. 추론에서 '좌절'이 모델 결과의 품질에 어떤 영향을 미칠지는 아직 지켜봐야 합니다"라고 말했습니다.
현재 벤치마크에서 최고 성과를 낸 모델은 o1으로 59% 점수를 기록했으며, 최근 출시된 o3-mini는 높은 "추론 노력" 설정에서 47%를 기록했습니다. R1은 35%를 기록했습니다. 연구원들은 더 많은 추론 모델로 테스트를 확장하여 개선 영역을 정확히 파악할 계획입니다.
구하는 접근 가능한 벤치마크의 중요성을 강조하며, "추론에 능숙하기 위해 박사 학위가 필요하지 않으므로, 박사 수준의 지식을 요구하지 않는 추론 벤치마크를 설계할 수 있어야 합니다. 더 많은 연구자들이 결과를 이해하고 분석할 수 있는 벤치마크는 미래에 더 나은 솔루션으로 이어질 수 있습니다. 또한, 최첨단 모델이 점점 더 모두에게 영향을 미치는 환경에 배포됨에 따라, 모두가 이 모델들이 무엇을 할 수 있고, 할 수 없는지를 직관적으로 이해할 수 있어야 한다고 믿습니다"라고 말했습니다.










 WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
 배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비

XIX.AI에서 2026년 최고의 만화 AI 자동 채색 도구를 만나보세요. 저희가 엄선한 이 목록에는 일관성 오류 없이 평면 색상을 적용하여 생산성을 높여주는, 최고 평점을 받은 혁신적인 솔루션들이 포함되어 있습니다. 무료 버전과 유료 버전의 비교 분석, 실제 테스트 결과, 매주 업데이트되는 순위 정보를 확인하여 여러분에게 딱 맞는 도구를 찾아보세요. 지금 바로 AI의 힘을 경험해 보세요.
10 도구
xix.ai

깊이 있는 캐릭터를 창조할 수 있는 2026년 최고의 AI 소설 프로필 생성 도구를 만나보세요. XIX.AI가 엄선한 이 목록에는 일관된 동기와 치명적인 결점을 생성해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 여러분의 스토리텔링 잠재력을 발휘해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

Die Vorstellung, dass KI solche Puzzles löst, ist faszinierend. Aber wie weit kann diese 'Argumentationsfähigkeit' wirklich gehen? Ich frage mich, ob das mehr ist als nur komplexe Mustererkennung. Die ethischen Implikationen, wenn diese Systeme 'echtes' Denken simulieren könnten, sind beängstigend. 🤔
NPR's Sunday Puzzle with AI? Sounds like a brain teaser showdown! I wonder if these models can outsmart Will Shortz’s tricky wordplay. 🤔
¡Esta herramienta de IA que resuelve los rompecabezas de los domingos de NPR es genial! Es como tener un amigo listo que ama los rompecabezas tanto como yo. A veces se equivoca, pero ¿quién no? ¡Sigue así, IA! 😄
This AI tool tackling NPR's Sunday Puzzles is super cool! It's like having a brainy friend who loves puzzles as much as I do. Sometimes it gets the answers wrong, but hey, who doesn't? Keep up the good work, AI! 🤓
NPRのサンデーパズルに挑戦するこのAIツール、めっちゃ面白い!パズル好きの友達がいるみたいで嬉しい。たまに答えを間違えるけど、誰でもそうなるよね。頑張ってね、AI!😊
NPRのサンデーパズルをAIで解くのは驚きです!これらのトリッキーな質問をモデルがどれだけうまく処理するかを見るのはクールです。時々間違えることもありますが、それでも印象的です。アルゴリズムを調整し続けてくださいね!🤓













