




Le nouveau test AGI s'avère difficile, les souches majorité des modèles d'IA
La Fondation Arc Prize, co-fondée par le célèbre chercheur en IA François Chollet, a récemment dévoilé un nouveau benchmark appelé ARC-AGI-2 dans un article de blog. Ce test vise à repousser les limites de l'intelligence générale de l'IA, et jusqu'à présent, il s'avère être un défi de taille pour la plupart des modèles d'IA.
Selon le classement d'Arc Prize, même les modèles d'IA avancés en "raisonnement" comme o1-pro d'OpenAI et R1 de DeepSeek ne parviennent qu'à obtenir des scores entre 1 % et 1,3 %. Pendant ce temps, les modèles puissants non axés sur le raisonnement, tels que GPT-4.5, Claude 3.7 Sonnet et Gemini 2.0 Flash, se situent autour de la barre des 1 %.
Les tests ARC-AGI mettent les systèmes d'IA à l'épreuve avec des problèmes de type casse-tête, les obligeant à identifier des motifs visuels dans des grilles de carrés de différentes couleurs et à générer la grille "réponse" correcte. Ces problèmes sont conçus pour tester la capacité d'une IA à s'adapter à de nouveaux défis inédits.
Pour établir une référence humaine, la Fondation Arc Prize a fait passer le test ARC-AGI-2 à plus de 400 personnes. En moyenne, ces "panels" d'humains ont atteint un taux de réussite de 60 %, surpassant largement les modèles d'IA.
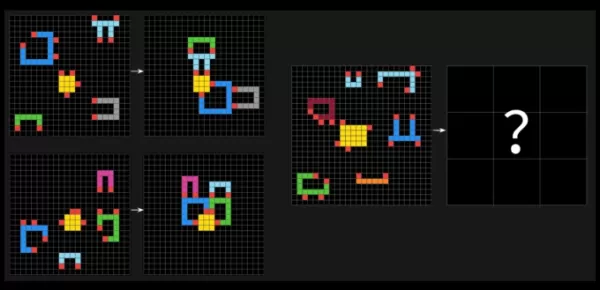
Un exemple de question d'ARC-AGI-2. Crédits image : Arc Prize François Chollet a déclaré sur X qu'ARC-AGI-2 est une mesure plus précise de l'intelligence réelle d'un modèle d'IA par rapport à son prédécesseur, ARC-AGI-1. Les tests de la Fondation Arc Prize sont conçus pour évaluer si une IA peut apprendre efficacement de nouvelles compétences au-delà de ses données d'entraînement.Chollet a souligné qu'ARC-AGI-2 empêche les modèles d'IA de s'appuyer sur une puissance de calcul "brute" pour résoudre les problèmes, un défaut qu'il a reconnu dans le premier test. Pour y remédier, ARC-AGI-2 introduit une métrique d'efficacité et exige que les modèles interprètent les motifs à la volée plutôt que de s'appuyer sur la mémorisation.
Dans un article de blog, le co-fondateur de la Fondation Arc Prize, Greg Kamradt, a insisté sur le fait que l'intelligence ne se limite pas à résoudre des problèmes ou à obtenir des scores élevés. "L'efficacité avec laquelle ces capacités sont acquises et déployées est un composant crucial et déterminant", a-t-il écrit. "La question centrale posée n'est pas seulement : 'L'IA peut-elle acquérir la compétence pour résoudre une tâche ?', mais aussi : 'À quelle efficacité ou à quel coût ?'"
ARC-AGI-1 est resté invaincu pendant environ cinq ans jusqu'en décembre 2024, lorsque le modèle de raisonnement avancé d'OpenAI, o3, a surpassé tous les autres modèles d'IA et égalé les performances humaines. Cependant, le succès d'o3 sur ARC-AGI-1 a eu un coût significatif. La version du modèle o3 d'OpenAI, o3 (low), qui a obtenu un impressionnant 75,7 % sur ARC-AGI-1, n'a atteint qu'un maigre 4 % sur ARC-AGI-2, en utilisant 200 $ de puissance de calcul par tâche.

Comparaison des performances des modèles d'IA de pointe sur ARC-AGI-1 et ARC-AGI-2. Crédits image : Arc Prize L'introduction d'ARC-AGI-2 intervient à un moment où de nombreux acteurs de l'industrie technologique réclament de nouveaux benchmarks non saturés pour mesurer les progrès de l'IA. Thomas Wolf, co-fondateur de Hugging Face, a récemment déclaré à TechCrunch que l'industrie de l'IA manque de tests suffisants pour mesurer des traits clés de l'intelligence générale artificielle, tels que la créativité.Parallèlement au nouveau benchmark, la Fondation Arc Prize a annoncé le concours Arc Prize 2025, défiant les développeurs d'atteindre une précision de 85 % sur le test ARC-AGI-2 tout en dépensant seulement 0,42 $ par tâche.
Article connexe
 L'AGI s'apprête à révolutionner la pensée humaine grâce à une avancée dans le domaine du langage universel
L'émergence de l'intelligence artificielle générale présente un potentiel de transformation pour remodeler la communication humaine par la création d'un cadre linguistique universel. Contrairement aux
OpenAI Réaffirme ses Racines Non Lucratives dans une Refonte Majeure de l'Entreprise
OpenAI reste ferme dans sa mission non lucrative alors qu'elle entreprend une restructuration d'entreprise significative, équilibrant la croissance avec son engagement envers un développement éthique
Les leaders de l'IA discutent de l'AGI : Ancrés dans la réalité
Lors d'un dîner récent avec des chefs d'entreprise à San Francisco, j'ai posé une question qui a semblé geler l'atmosphère : l'IA d'aujourd'hui pourrait-elle atteindre ou dépasser
commentaires (36)
0/200
L'AGI s'apprête à révolutionner la pensée humaine grâce à une avancée dans le domaine du langage universel
L'émergence de l'intelligence artificielle générale présente un potentiel de transformation pour remodeler la communication humaine par la création d'un cadre linguistique universel. Contrairement aux
OpenAI Réaffirme ses Racines Non Lucratives dans une Refonte Majeure de l'Entreprise
OpenAI reste ferme dans sa mission non lucrative alors qu'elle entreprend une restructuration d'entreprise significative, équilibrant la croissance avec son engagement envers un développement éthique
Les leaders de l'IA discutent de l'AGI : Ancrés dans la réalité
Lors d'un dîner récent avec des chefs d'entreprise à San Francisco, j'ai posé une question qui a semblé geler l'atmosphère : l'IA d'aujourd'hui pourrait-elle atteindre ou dépasser
commentaires (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 29 juillet 2025 14:25:16 UTC+02:00
29 juillet 2025 14:25:16 UTC+02:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14 avril 2025 10:35:00 UTC+02:00
GeorgeMiller
14 avril 2025 10:35:00 UTC+02:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14 avril 2025 03:46:37 UTC+02:00
JonathanKing
14 avril 2025 03:46:37 UTC+02:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
13 avril 2025 21:05:45 UTC+02:00
DonaldGonzález
13 avril 2025 21:05:45 UTC+02:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13 avril 2025 17:54:39 UTC+02:00
HaroldMoore
13 avril 2025 17:54:39 UTC+02:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13 avril 2025 17:36:48 UTC+02:00
GregoryWilson
13 avril 2025 17:36:48 UTC+02:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
La Fondation Arc Prize, co-fondée par le célèbre chercheur en IA François Chollet, a récemment dévoilé un nouveau benchmark appelé ARC-AGI-2 dans un article de blog. Ce test vise à repousser les limites de l'intelligence générale de l'IA, et jusqu'à présent, il s'avère être un défi de taille pour la plupart des modèles d'IA.
Selon le classement d'Arc Prize, même les modèles d'IA avancés en "raisonnement" comme o1-pro d'OpenAI et R1 de DeepSeek ne parviennent qu'à obtenir des scores entre 1 % et 1,3 %. Pendant ce temps, les modèles puissants non axés sur le raisonnement, tels que GPT-4.5, Claude 3.7 Sonnet et Gemini 2.0 Flash, se situent autour de la barre des 1 %.
Les tests ARC-AGI mettent les systèmes d'IA à l'épreuve avec des problèmes de type casse-tête, les obligeant à identifier des motifs visuels dans des grilles de carrés de différentes couleurs et à générer la grille "réponse" correcte. Ces problèmes sont conçus pour tester la capacité d'une IA à s'adapter à de nouveaux défis inédits.
Pour établir une référence humaine, la Fondation Arc Prize a fait passer le test ARC-AGI-2 à plus de 400 personnes. En moyenne, ces "panels" d'humains ont atteint un taux de réussite de 60 %, surpassant largement les modèles d'IA.
Chollet a souligné qu'ARC-AGI-2 empêche les modèles d'IA de s'appuyer sur une puissance de calcul "brute" pour résoudre les problèmes, un défaut qu'il a reconnu dans le premier test. Pour y remédier, ARC-AGI-2 introduit une métrique d'efficacité et exige que les modèles interprètent les motifs à la volée plutôt que de s'appuyer sur la mémorisation.
Dans un article de blog, le co-fondateur de la Fondation Arc Prize, Greg Kamradt, a insisté sur le fait que l'intelligence ne se limite pas à résoudre des problèmes ou à obtenir des scores élevés. "L'efficacité avec laquelle ces capacités sont acquises et déployées est un composant crucial et déterminant", a-t-il écrit. "La question centrale posée n'est pas seulement : 'L'IA peut-elle acquérir la compétence pour résoudre une tâche ?', mais aussi : 'À quelle efficacité ou à quel coût ?'"
ARC-AGI-1 est resté invaincu pendant environ cinq ans jusqu'en décembre 2024, lorsque le modèle de raisonnement avancé d'OpenAI, o3, a surpassé tous les autres modèles d'IA et égalé les performances humaines. Cependant, le succès d'o3 sur ARC-AGI-1 a eu un coût significatif. La version du modèle o3 d'OpenAI, o3 (low), qui a obtenu un impressionnant 75,7 % sur ARC-AGI-1, n'a atteint qu'un maigre 4 % sur ARC-AGI-2, en utilisant 200 $ de puissance de calcul par tâche.
Parallèlement au nouveau benchmark, la Fondation Arc Prize a annoncé le concours Arc Prize 2025, défiant les développeurs d'atteindre une précision de 85 % sur le test ARC-AGI-2 tout en dépensant seulement 0,42 $ par tâche.









 L'AGI s'apprête à révolutionner la pensée humaine grâce à une avancée dans le domaine du langage universel
L'émergence de l'intelligence artificielle générale présente un potentiel de transformation pour remodeler la communication humaine par la création d'un cadre linguistique universel. Contrairement aux
OpenAI Réaffirme ses Racines Non Lucratives dans une Refonte Majeure de l'Entreprise
OpenAI reste ferme dans sa mission non lucrative alors qu'elle entreprend une restructuration d'entreprise significative, équilibrant la croissance avec son engagement envers un développement éthique
L'AGI s'apprête à révolutionner la pensée humaine grâce à une avancée dans le domaine du langage universel
L'émergence de l'intelligence artificielle générale présente un potentiel de transformation pour remodeler la communication humaine par la création d'un cadre linguistique universel. Contrairement aux
OpenAI Réaffirme ses Racines Non Lucratives dans une Refonte Majeure de l'Entreprise
OpenAI reste ferme dans sa mission non lucrative alors qu'elle entreprend une restructuration d'entreprise significative, équilibrant la croissance avec son engagement envers un développement éthique
 Les leaders de l'IA discutent de l'AGI : Ancrés dans la réalité
Lors d'un dîner récent avec des chefs d'entreprise à San Francisco, j'ai posé une question qui a semblé geler l'atmosphère : l'IA d'aujourd'hui pourrait-elle atteindre ou dépasser
29 juillet 2025 14:25:16 UTC+02:00
Les leaders de l'IA discutent de l'AGI : Ancrés dans la réalité
Lors d'un dîner récent avec des chefs d'entreprise à San Francisco, j'ai posé une question qui a semblé geler l'atmosphère : l'IA d'aujourd'hui pourrait-elle atteindre ou dépasser
29 juillet 2025 14:25:16 UTC+02:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14 avril 2025 10:35:00 UTC+02:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14 avril 2025 03:46:37 UTC+02:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
13 avril 2025 21:05:45 UTC+02:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13 avril 2025 17:54:39 UTC+02:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13 avril 2025 17:36:48 UTC+02:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













