
















 Home
HomeNew AGI Test Proves Challenging, Stumps Majority of AI Models
The Arc Prize Foundation, co-founded by renowned AI researcher François Chollet, recently unveiled a new benchmark called ARC-AGI-2 in a blog post. This test aims to push the boundaries of AI's general intelligence, and so far, it's proving to be a tough nut to crack for most AI models.
According to the Arc Prize leaderboard, even advanced "reasoning" AI models like OpenAI's o1-pro and DeepSeek's R1 are only managing scores between 1% and 1.3%. Meanwhile, powerful non-reasoning models such as GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Flash are hovering around the 1% mark.
ARC-AGI tests challenge AI systems with puzzle-like problems, requiring them to identify visual patterns in grids of different-colored squares and generate the correct "answer" grid. These problems are designed to test an AI's ability to adapt to new, unseen challenges.
To establish a human baseline, the Arc Prize Foundation had over 400 people take the ARC-AGI-2 test. On average, these "panels" of humans achieved a 60% success rate, significantly outperforming the AI models.
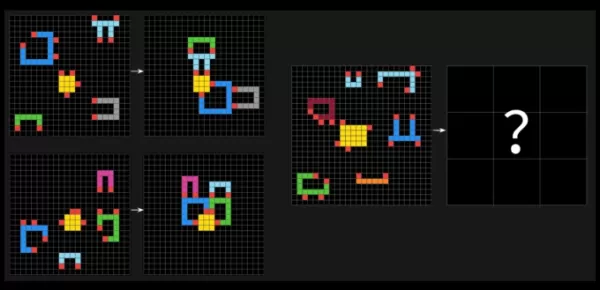
a sample question from Arc-AGI-2.Image Credits:Arc Prize François Chollet took to X to claim that ARC-AGI-2 is a more accurate measure of an AI model's true intelligence compared to its predecessor, ARC-AGI-1. The Arc Prize Foundation's tests are designed to assess whether an AI can efficiently learn new skills beyond its training data.
Chollet emphasized that ARC-AGI-2 prevents AI models from relying on "brute force" computing power to solve problems, a flaw he acknowledged in the first test. To address this, ARC-AGI-2 introduces an efficiency metric and requires models to interpret patterns on the fly rather than relying on memorization.
In a blog post, Arc Prize Foundation co-founder Greg Kamradt stressed that intelligence isn't just about solving problems or achieving high scores. "The efficiency with which those capabilities are acquired and deployed is a crucial, defining component," he wrote. "The core question being asked is not just, 'Can AI acquire [the] skill to solve a task?' but also, 'At what efficiency or cost?'"
ARC-AGI-1 remained unbeaten for about five years until December 2024, when OpenAI's advanced reasoning model, o3, surpassed all other AI models and matched human performance. However, o3's success on ARC-AGI-1 came at a significant cost. The version of OpenAI's o3 model, o3 (low), which scored an impressive 75.7% on ARC-AGI-1, only managed a paltry 4% on ARC-AGI-2, using $200 worth of computing power per task.

Comparison of Frontier AI model performance on ARC-AGI-1 and ARC-AGI-2.Image Credits:Arc Prize The introduction of ARC-AGI-2 comes at a time when many in the tech industry are calling for new, unsaturated benchmarks to measure AI progress. Thomas Wolf, co-founder of Hugging Face, recently told TechCrunch that the AI industry lacks sufficient tests to measure key traits of artificial general intelligence, such as creativity.
Alongside the new benchmark, the Arc Prize Foundation announced the Arc Prize 2025 contest, challenging developers to achieve 85% accuracy on the ARC-AGI-2 test while spending only $0.42 per task.
Related article
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Databricks Co-Founder Claims AGI Arrival After Winning ACM Award
Databricks co-founder and CTO Matei Zaharia nearly overlooked the email informing him he had been awarded the 2026 ACM Prize in Computing. "It was certainly a surprise," he shared with TechCrunch.In 2009, the technology Zaharia developed during his P
OpenAI's Sam Altman Declares Dawn of the Superintelligence Era
OpenAI CEO Sam Altman has announced that humanity has entered the age of artificial superintelligence, and there is no going back."We have passed the point of no return; the ascent has begun," Altman says. "We are on the brink of creating digital sup
Related Special Topic Recommendations
Business
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Databricks Co-Founder Claims AGI Arrival After Winning ACM Award
Databricks co-founder and CTO Matei Zaharia nearly overlooked the email informing him he had been awarded the 2026 ACM Prize in Computing. "It was certainly a surprise," he shared with TechCrunch.In 2009, the technology Zaharia developed during his P
OpenAI's Sam Altman Declares Dawn of the Superintelligence Era
OpenAI CEO Sam Altman has announced that humanity has entered the age of artificial superintelligence, and there is no going back."We have passed the point of no return; the ascent has begun," Altman says. "We are on the brink of creating digital sup
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (39)
0/500
Comments (39)
0/500
![DonaldSanchez]()
이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
![MarkRoberts]()
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
![RonaldRoberts]()
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
![WillieRoberts]()
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
![GeorgeMiller]()
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
![JonathanKing]()
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
The Arc Prize Foundation, co-founded by renowned AI researcher François Chollet, recently unveiled a new benchmark called ARC-AGI-2 in a blog post. This test aims to push the boundaries of AI's general intelligence, and so far, it's proving to be a tough nut to crack for most AI models.
According to the Arc Prize leaderboard, even advanced "reasoning" AI models like OpenAI's o1-pro and DeepSeek's R1 are only managing scores between 1% and 1.3%. Meanwhile, powerful non-reasoning models such as GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Flash are hovering around the 1% mark.
ARC-AGI tests challenge AI systems with puzzle-like problems, requiring them to identify visual patterns in grids of different-colored squares and generate the correct "answer" grid. These problems are designed to test an AI's ability to adapt to new, unseen challenges.
To establish a human baseline, the Arc Prize Foundation had over 400 people take the ARC-AGI-2 test. On average, these "panels" of humans achieved a 60% success rate, significantly outperforming the AI models.
Chollet emphasized that ARC-AGI-2 prevents AI models from relying on "brute force" computing power to solve problems, a flaw he acknowledged in the first test. To address this, ARC-AGI-2 introduces an efficiency metric and requires models to interpret patterns on the fly rather than relying on memorization.
In a blog post, Arc Prize Foundation co-founder Greg Kamradt stressed that intelligence isn't just about solving problems or achieving high scores. "The efficiency with which those capabilities are acquired and deployed is a crucial, defining component," he wrote. "The core question being asked is not just, 'Can AI acquire [the] skill to solve a task?' but also, 'At what efficiency or cost?'"
ARC-AGI-1 remained unbeaten for about five years until December 2024, when OpenAI's advanced reasoning model, o3, surpassed all other AI models and matched human performance. However, o3's success on ARC-AGI-1 came at a significant cost. The version of OpenAI's o3 model, o3 (low), which scored an impressive 75.7% on ARC-AGI-1, only managed a paltry 4% on ARC-AGI-2, using $200 worth of computing power per task.
Alongside the new benchmark, the Arc Prize Foundation announced the Arc Prize 2025 contest, challenging developers to achieve 85% accuracy on the ARC-AGI-2 test while spending only $0.42 per task.










 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
 Databricks Co-Founder Claims AGI Arrival After Winning ACM Award
Databricks co-founder and CTO Matei Zaharia nearly overlooked the email informing him he had been awarded the 2026 ACM Prize in Computing. "It was certainly a surprise," he shared with TechCrunch.In 2009, the technology Zaharia developed during his P
OpenAI's Sam Altman Declares Dawn of the Superintelligence Era
OpenAI CEO Sam Altman has announced that humanity has entered the age of artificial superintelligence, and there is no going back."We have passed the point of no return; the ascent has begun," Altman says. "We are on the brink of creating digital sup
Databricks Co-Founder Claims AGI Arrival After Winning ACM Award
Databricks co-founder and CTO Matei Zaharia nearly overlooked the email informing him he had been awarded the 2026 ACM Prize in Computing. "It was certainly a surprise," he shared with TechCrunch.In 2009, the technology Zaharia developed during his P
OpenAI's Sam Altman Declares Dawn of the Superintelligence Era
OpenAI CEO Sam Altman has announced that humanity has entered the age of artificial superintelligence, and there is no going back."We have passed the point of no return; the ascent has begun," Altman says. "We are on the brink of creating digital sup

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?













