




Der neue AGI -Test erweist sich als herausfordernd, die Mehrheit der KI -Modelle der Stümpfe
Die Arc Prize Foundation, mitbegründet von dem renommierten KI-Forscher François Chollet, hat kürzlich in einem Blogbeitrag einen neuen Benchmark namens ARC-AGI-2 vorgestellt. Dieser Test zielt darauf ab, die Grenzen der allgemeinen Intelligenz von KI zu erweitern, und bisher erweist er sich für die meisten KI-Modelle als schwer zu knacken.
Laut der Rangliste des Arc Prize erreichen selbst fortschrittliche „denkende“ KI-Modelle wie OpenAI's o1-pro und DeepSeek's R1 nur Werte zwischen 1 % und 1,3 %. Währenddessen liegen leistungsstarke nicht-denkende Modelle wie GPT-4.5, Claude 3.7 Sonnet und Gemini 2.0 Flash bei etwa 1 %.
ARC-AGI-Tests fordern KI-Systeme mit rätselartigen Problemen heraus, bei denen sie visuelle Muster in Gittern aus verschiedenfarbigen Quadraten erkennen und das richtige „Antwort“-Gitter erstellen müssen. Diese Probleme sind darauf ausgelegt, die Fähigkeit einer KI zu testen, sich an neue, unbekannte Herausforderungen anzupassen.
Um eine menschliche Basislinie zu etablieren, ließ die Arc Prize Foundation über 400 Personen den ARC-AGI-2-Test durchführen. Im Durchschnitt erzielten diese „Gremien“ von Menschen eine Erfolgsquote von 60 %, womit sie die KI-Modelle deutlich übertrafen.
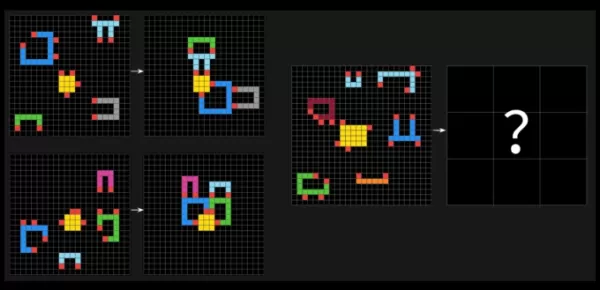
Eine Beispielaufgabe aus ARC-AGI-2. Bildnachweis: Arc Prize François Chollet erklärte auf X, dass ARC-AGI-2 im Vergleich zu seinem Vorgänger, ARC-AGI-1, ein genaueres Maß für die wahre Intelligenz eines KI-Modells ist. Die Tests der Arc Prize Foundation sind darauf ausgelegt, zu prüfen, ob eine KI effizient neue Fähigkeiten jenseits ihrer Trainingsdaten erlernen kann.Chollet betonte, dass ARC-AGI-2 verhindert, dass KI-Modelle Probleme durch „brute force“-Rechenleistung lösen, ein Mangel, den er beim ersten Test eingestand. Um dies zu beheben, führt ARC-AGI-2 eine Effizienzmetrik ein und verlangt, dass Modelle Muster spontan interpretieren, anstatt sich auf Auswendiglernen zu stützen.
In einem Blogbeitrag betonte Greg Kamradt, Mitbegründer der Arc Prize Foundation, dass Intelligenz nicht nur darin besteht, Probleme zu lösen oder hohe Punktzahlen zu erzielen. „Die Effizienz, mit der diese Fähigkeiten erworben und eingesetzt werden, ist eine entscheidende, definierende Komponente“, schrieb er. „Die zentrale Frage ist nicht nur: ‚Kann KI die Fähigkeit erwerben, eine Aufgabe zu lösen?‘, sondern auch: ‚Mit welcher Effizienz oder zu welchen Kosten?‘“
ARC-AGI-1 blieb etwa fünf Jahre lang ungeschlagen, bis im Dezember 2024 OpenAI's fortschrittliches Denkmodell o3 alle anderen KI-Modelle übertraf und die menschliche Leistung erreichte. Allerdings war der Erfolg von o3 bei ARC-AGI-1 mit erheblichen Kosten verbunden. Die Version von OpenAI's o3-Modell, o3 (low), die bei ARC-AGI-1 beeindruckende 75,7 % erzielte, erreichte bei ARC-AGI-2 nur magere 4 %, bei einem Einsatz von 200 US-Dollar Rechenleistung pro Aufgabe.

Vergleich der Leistung von Frontier-KI-Modellen bei ARC-AGI-1 und ARC-AGI-2. Bildnachweis: Arc Prize Die Einführung von ARC-AGI-2 kommt zu einer Zeit, in der viele in der Technologiebranche nach neuen, ungesättigten Benchmarks verlangen, um den Fortschritt von KI zu messen. Thomas Wolf, Mitbegründer von Hugging Face, erklärte kürzlich gegenüber TechCrunch, dass der KI-Branche ausreichende Tests fehlen, um Schlüsselfähigkeiten der künstlichen allgemeinen Intelligenz, wie Kreativität, zu messen.Neben dem neuen Benchmark kündigte die Arc Prize Foundation den Arc Prize 2025-Wettbewerb an, der Entwickler herausfordert, eine Genauigkeit von 85 % beim ARC-AGI-2-Test zu erreichen, während sie nur 0,42 US-Dollar pro Aufgabe ausgeben.
Verwandter Artikel
 AGI wird das menschliche Denken mit einem Durchbruch bei der Universalsprache revolutionieren
Das Aufkommen der künstlichen allgemeinen Intelligenz birgt das Potenzial, die menschliche Kommunikation durch die Schaffung eines universellen Sprachrahmens neu zu gestalten. Im Gegensatz zu eng gefa
OpenAI bekräftigt gemeinnützige Wurzeln in großer Unternehmensumstrukturierung
OpenAI bleibt seiner gemeinnützigen Mission treu, während es eine bedeutende Unternehmensumstrukturierung durchläuft und Wachstum mit dem Engagement für ethische KI-Entwicklung in Einklang bringt.CEO
KI-Führer diskutieren AGI: Geerdet in der Realität
Bei einem kürzlichen Abendessen mit Geschäftsführern in San Francisco stellte ich eine Frage, die den Raum förmlich zum Erstarren brachte: Könnte die heutige KI jemals die Intellig
Kommentare (36)
0/200
AGI wird das menschliche Denken mit einem Durchbruch bei der Universalsprache revolutionieren
Das Aufkommen der künstlichen allgemeinen Intelligenz birgt das Potenzial, die menschliche Kommunikation durch die Schaffung eines universellen Sprachrahmens neu zu gestalten. Im Gegensatz zu eng gefa
OpenAI bekräftigt gemeinnützige Wurzeln in großer Unternehmensumstrukturierung
OpenAI bleibt seiner gemeinnützigen Mission treu, während es eine bedeutende Unternehmensumstrukturierung durchläuft und Wachstum mit dem Engagement für ethische KI-Entwicklung in Einklang bringt.CEO
KI-Führer diskutieren AGI: Geerdet in der Realität
Bei einem kürzlichen Abendessen mit Geschäftsführern in San Francisco stellte ich eine Frage, die den Raum förmlich zum Erstarren brachte: Könnte die heutige KI jemals die Intellig
Kommentare (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 29. Juli 2025 14:25:16 MESZ
29. Juli 2025 14:25:16 MESZ
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14. April 2025 10:35:00 MESZ
GeorgeMiller
14. April 2025 10:35:00 MESZ
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14. April 2025 03:46:37 MESZ
JonathanKing
14. April 2025 03:46:37 MESZ
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
13. April 2025 21:05:45 MESZ
DonaldGonzález
13. April 2025 21:05:45 MESZ
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13. April 2025 17:54:39 MESZ
HaroldMoore
13. April 2025 17:54:39 MESZ
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13. April 2025 17:36:48 MESZ
GregoryWilson
13. April 2025 17:36:48 MESZ
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
Die Arc Prize Foundation, mitbegründet von dem renommierten KI-Forscher François Chollet, hat kürzlich in einem Blogbeitrag einen neuen Benchmark namens ARC-AGI-2 vorgestellt. Dieser Test zielt darauf ab, die Grenzen der allgemeinen Intelligenz von KI zu erweitern, und bisher erweist er sich für die meisten KI-Modelle als schwer zu knacken.
Laut der Rangliste des Arc Prize erreichen selbst fortschrittliche „denkende“ KI-Modelle wie OpenAI's o1-pro und DeepSeek's R1 nur Werte zwischen 1 % und 1,3 %. Währenddessen liegen leistungsstarke nicht-denkende Modelle wie GPT-4.5, Claude 3.7 Sonnet und Gemini 2.0 Flash bei etwa 1 %.
ARC-AGI-Tests fordern KI-Systeme mit rätselartigen Problemen heraus, bei denen sie visuelle Muster in Gittern aus verschiedenfarbigen Quadraten erkennen und das richtige „Antwort“-Gitter erstellen müssen. Diese Probleme sind darauf ausgelegt, die Fähigkeit einer KI zu testen, sich an neue, unbekannte Herausforderungen anzupassen.
Um eine menschliche Basislinie zu etablieren, ließ die Arc Prize Foundation über 400 Personen den ARC-AGI-2-Test durchführen. Im Durchschnitt erzielten diese „Gremien“ von Menschen eine Erfolgsquote von 60 %, womit sie die KI-Modelle deutlich übertrafen.
Chollet betonte, dass ARC-AGI-2 verhindert, dass KI-Modelle Probleme durch „brute force“-Rechenleistung lösen, ein Mangel, den er beim ersten Test eingestand. Um dies zu beheben, führt ARC-AGI-2 eine Effizienzmetrik ein und verlangt, dass Modelle Muster spontan interpretieren, anstatt sich auf Auswendiglernen zu stützen.
In einem Blogbeitrag betonte Greg Kamradt, Mitbegründer der Arc Prize Foundation, dass Intelligenz nicht nur darin besteht, Probleme zu lösen oder hohe Punktzahlen zu erzielen. „Die Effizienz, mit der diese Fähigkeiten erworben und eingesetzt werden, ist eine entscheidende, definierende Komponente“, schrieb er. „Die zentrale Frage ist nicht nur: ‚Kann KI die Fähigkeit erwerben, eine Aufgabe zu lösen?‘, sondern auch: ‚Mit welcher Effizienz oder zu welchen Kosten?‘“
ARC-AGI-1 blieb etwa fünf Jahre lang ungeschlagen, bis im Dezember 2024 OpenAI's fortschrittliches Denkmodell o3 alle anderen KI-Modelle übertraf und die menschliche Leistung erreichte. Allerdings war der Erfolg von o3 bei ARC-AGI-1 mit erheblichen Kosten verbunden. Die Version von OpenAI's o3-Modell, o3 (low), die bei ARC-AGI-1 beeindruckende 75,7 % erzielte, erreichte bei ARC-AGI-2 nur magere 4 %, bei einem Einsatz von 200 US-Dollar Rechenleistung pro Aufgabe.
Neben dem neuen Benchmark kündigte die Arc Prize Foundation den Arc Prize 2025-Wettbewerb an, der Entwickler herausfordert, eine Genauigkeit von 85 % beim ARC-AGI-2-Test zu erreichen, während sie nur 0,42 US-Dollar pro Aufgabe ausgeben.









 AGI wird das menschliche Denken mit einem Durchbruch bei der Universalsprache revolutionieren
Das Aufkommen der künstlichen allgemeinen Intelligenz birgt das Potenzial, die menschliche Kommunikation durch die Schaffung eines universellen Sprachrahmens neu zu gestalten. Im Gegensatz zu eng gefa
OpenAI bekräftigt gemeinnützige Wurzeln in großer Unternehmensumstrukturierung
OpenAI bleibt seiner gemeinnützigen Mission treu, während es eine bedeutende Unternehmensumstrukturierung durchläuft und Wachstum mit dem Engagement für ethische KI-Entwicklung in Einklang bringt.CEO
AGI wird das menschliche Denken mit einem Durchbruch bei der Universalsprache revolutionieren
Das Aufkommen der künstlichen allgemeinen Intelligenz birgt das Potenzial, die menschliche Kommunikation durch die Schaffung eines universellen Sprachrahmens neu zu gestalten. Im Gegensatz zu eng gefa
OpenAI bekräftigt gemeinnützige Wurzeln in großer Unternehmensumstrukturierung
OpenAI bleibt seiner gemeinnützigen Mission treu, während es eine bedeutende Unternehmensumstrukturierung durchläuft und Wachstum mit dem Engagement für ethische KI-Entwicklung in Einklang bringt.CEO
 KI-Führer diskutieren AGI: Geerdet in der Realität
Bei einem kürzlichen Abendessen mit Geschäftsführern in San Francisco stellte ich eine Frage, die den Raum förmlich zum Erstarren brachte: Könnte die heutige KI jemals die Intellig
29. Juli 2025 14:25:16 MESZ
KI-Führer diskutieren AGI: Geerdet in der Realität
Bei einem kürzlichen Abendessen mit Geschäftsführern in San Francisco stellte ich eine Frage, die den Raum förmlich zum Erstarren brachte: Könnte die heutige KI jemals die Intellig
29. Juli 2025 14:25:16 MESZ
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14. April 2025 10:35:00 MESZ
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14. April 2025 03:46:37 MESZ
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
13. April 2025 21:05:45 MESZ
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13. April 2025 17:54:39 MESZ
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13. April 2025 17:36:48 MESZ
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













