




새로운 AGI 테스트는 도전적인 것으로 판명되고 대다수의 AI 모델
Arc Prize 재단은 유명한 AI 연구자 프랑수아 숄레(François Chollet)가 공동 설립한 기관으로, 최근 블로그 포스트에서 ARC-AGI-2라는 새로운 벤치마크를 공개했습니다. 이 테스트는 AI의 일반 지능의 한계를 확장하는 것을 목표로 하며, 현재까지 대부분의 AI 모델들에게는 풀기 어려운 과제로 입증되고 있습니다.
Arc Prize 리더보드에 따르면, OpenAI의 o1-pro와 DeepSeek의 R1과 같은 고급 "추론" AI 모델들조차 1%에서 1.3% 사이의 점수만을 기록하고 있습니다. 한편, GPT-4.5, Claude 3.7 Sonnet, Gemini 2.0 Flash와 같은 강력한 비추론 모델들은 약 1% 정도의 점수를 유지하고 있습니다.
ARC-AGI 테스트는 AI 시스템이 다양한 색상의 사각형 격자에서 시각적 패턴을 식별하고 올바른 "답변" 격자를 생성하도록 요구하는 퍼즐과 같은 문제를 통해 도전합니다. 이러한 문제들은 AI가 새로운, 이전에 보지 못한 도전에 적응하는 능력을 테스트하도록 설계되었습니다.
인간의 기준선을 설정하기 위해 Arc Prize 재단은 400명 이상의 사람들에게 ARC-AGI-2 테스트를 치르게 했습니다. 평균적으로 이 "패널"들은 60%의 성공률을 달성하여 AI 모델들을 크게 앞질렀습니다.
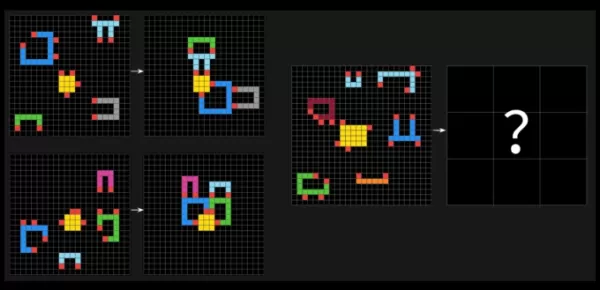
ARC-AGI-2의 샘플 질문. 이미지 출처: Arc Prize 프랑수아 숄레(François Chollet)는 X에서 ARC-AGI-2가 이전 버전인 ARC-AGI-1에 비해 AI 모델의 진정한 지능을 더 정확히 측정한다고 주장했습니다. Arc Prize 재단의 테스트는 AI가 훈련 데이터 너머의 새로운 기술을 효율적으로 학습할 수 있는지를 평가하도록 설계되었습니다.숄레는 ARC-AGI-2가 AI 모델이 "무차별 대입" 컴퓨팅 파워에 의존하여 문제를 해결하는 것을 방지한다고 강조했으며, 이는 첫 번째 테스트에서 인정한 결함이었습니다. 이를 해결하기 위해 ARC-AGI-2는 효율성 지표를 도입하고 모델이 기억에 의존하기보다는 즉석에서 패턴을 해석하도록 요구합니다.
블로그 포스트에서 Arc Prize 재단의 공동 설립자 그렉 캠라트(Greg Kamradt)는 지능이 단순히 문제를 해결하거나 높은 점수를 얻는 것만이 아니라고 강조했습니다. 그는 "그 능력이 획득되고 배포되는 효율성이 중요한 정의적 구성 요소"라고 썼습니다. "핵심 질문은 단순히 'AI가 작업을 해결하기 위한 기술을 획득할 수 있는가?'가 아니라, '어떤 효율성이나 비용으로?'입니다."
ARC-AGI-1은 약 5년 동안 무패로 남아 있었으나, 2024년 12월 OpenAI의 고급 추론 모델인 o3가 다른 모든 AI 모델을 능가하고 인간의 성능을 따라잡았습니다. 그러나 o3의 ARC-AGI-1에서의 성공은 상당한 비용을 초래했습니다. ARC-AGI-1에서 75.7%라는 인상적인 점수를 기록한 OpenAI의 o3 모델, o3 (low)는 ARC-AGI-2에서는 태스크당 200달러의 컴퓨팅 파워를 사용하며 겨우 4%를 기록했습니다.

ARC-AGI-1과 ARC-AGI-2에서 프론티어 AI 모델 성능 비교. 이미지 출처: Arc Prize ARC-AGI-2의 도입은 기술 산업에서 많은 이들이 AI 발전을 측정하기 위해 새로운, 포화되지 않은 벤치마크를 요구하는 시점에 이루어졌습니다. Hugging Face의 공동 설립자 토마스 울프(Thomas Wolf)는 최근 TechCrunch에 AI 산업이 인공지능 일반의 핵심 특성, 예를 들어 창의성을 측정할 충분한 테스트가 부족하다고 말했습니다.새로운 벤치마크와 함께 Arc Prize 재단은 Arc Prize 2025 대회를 발표했으며, 개발자들에게 ARC-AGI-2 테스트에서 85% 정확도를 달성하면서 태스크당 0.42달러만을 사용하도록 도전했습니다.
관련 기사
 보편적 언어 혁신으로 인류의 사고에 혁신을 가져올 AGI
인공 일반 지능의 등장은 보편적인 언어 프레임워크를 만들어 인간의 커뮤니케이션을 재구성할 수 있는 혁신적인 잠재력을 제시합니다. 특수한 작업을 위해 설계된 협소한 AI 시스템과 달리, AGI는 여러 영역에 걸쳐 인간과 유사한 학습 능력을 갖추고 있어 언어 패턴, 문화적 맥락, 인지 과정을 분석할 수 있습니다. 이러한 독특한 조합은 인간의 인지 능력을 향상시
OpenAI 비영리 뿌리 재확인, 주요 기업 개편 속에서
OpenAI는 주요 기업 개편을 진행하면서도 비영리 사명에 확고히 전념하며, 성장과 윤리적 AI 개발에 대한 헌신을 균형 있게 유지하고 있습니다.CEO Sam Altman은 회사의 비전을 설명하며, 재무 전략이 진화하고 있지만 OpenAI의 인공지능 일반(AGI)을 전 세계적 이익을 위해 발전시키겠다는 헌신은 변함없다고 강조했습니다.공개 성명에서 Altma
AI 리더들이 AGI 논의: 현실에 근거하여
최근 샌프란시스코에서 열린 비즈니스 리더들과의 만찬에서 던진 질문 하나가 방 안을 얼어붙게 했습니다: 오늘날의 AI가 인간 수준의 지능이나 그 이상에 도달할 수 있을까요? 이 주제는 예상보다 더 많은 논쟁을 불러일으킵니다.2025년, 기술 CEO들은 ChatGPT와 Gemini 같은 대규모 언어 모델(LLM)에 대해 낙관
의견 (36)
0/200
보편적 언어 혁신으로 인류의 사고에 혁신을 가져올 AGI
인공 일반 지능의 등장은 보편적인 언어 프레임워크를 만들어 인간의 커뮤니케이션을 재구성할 수 있는 혁신적인 잠재력을 제시합니다. 특수한 작업을 위해 설계된 협소한 AI 시스템과 달리, AGI는 여러 영역에 걸쳐 인간과 유사한 학습 능력을 갖추고 있어 언어 패턴, 문화적 맥락, 인지 과정을 분석할 수 있습니다. 이러한 독특한 조합은 인간의 인지 능력을 향상시
OpenAI 비영리 뿌리 재확인, 주요 기업 개편 속에서
OpenAI는 주요 기업 개편을 진행하면서도 비영리 사명에 확고히 전념하며, 성장과 윤리적 AI 개발에 대한 헌신을 균형 있게 유지하고 있습니다.CEO Sam Altman은 회사의 비전을 설명하며, 재무 전략이 진화하고 있지만 OpenAI의 인공지능 일반(AGI)을 전 세계적 이익을 위해 발전시키겠다는 헌신은 변함없다고 강조했습니다.공개 성명에서 Altma
AI 리더들이 AGI 논의: 현실에 근거하여
최근 샌프란시스코에서 열린 비즈니스 리더들과의 만찬에서 던진 질문 하나가 방 안을 얼어붙게 했습니다: 오늘날의 AI가 인간 수준의 지능이나 그 이상에 도달할 수 있을까요? 이 주제는 예상보다 더 많은 논쟁을 불러일으킵니다.2025년, 기술 CEO들은 ChatGPT와 Gemini 같은 대규모 언어 모델(LLM)에 대해 낙관
의견 (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 2025년 7월 29일 오후 9시 25분 16초 GMT+09:00
2025년 7월 29일 오후 9시 25분 16초 GMT+09:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
2025년 4월 14일 오후 5시 35분 0초 GMT+09:00
GeorgeMiller
2025년 4월 14일 오후 5시 35분 0초 GMT+09:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
2025년 4월 14일 오전 10시 46분 37초 GMT+09:00
JonathanKing
2025년 4월 14일 오전 10시 46분 37초 GMT+09:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
2025년 4월 14일 오전 4시 5분 45초 GMT+09:00
DonaldGonzález
2025년 4월 14일 오전 4시 5분 45초 GMT+09:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
2025년 4월 14일 오전 12시 54분 39초 GMT+09:00
HaroldMoore
2025년 4월 14일 오전 12시 54분 39초 GMT+09:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
2025년 4월 14일 오전 12시 36분 48초 GMT+09:00
GregoryWilson
2025년 4월 14일 오전 12시 36분 48초 GMT+09:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
Arc Prize 재단은 유명한 AI 연구자 프랑수아 숄레(François Chollet)가 공동 설립한 기관으로, 최근 블로그 포스트에서 ARC-AGI-2라는 새로운 벤치마크를 공개했습니다. 이 테스트는 AI의 일반 지능의 한계를 확장하는 것을 목표로 하며, 현재까지 대부분의 AI 모델들에게는 풀기 어려운 과제로 입증되고 있습니다.
Arc Prize 리더보드에 따르면, OpenAI의 o1-pro와 DeepSeek의 R1과 같은 고급 "추론" AI 모델들조차 1%에서 1.3% 사이의 점수만을 기록하고 있습니다. 한편, GPT-4.5, Claude 3.7 Sonnet, Gemini 2.0 Flash와 같은 강력한 비추론 모델들은 약 1% 정도의 점수를 유지하고 있습니다.
ARC-AGI 테스트는 AI 시스템이 다양한 색상의 사각형 격자에서 시각적 패턴을 식별하고 올바른 "답변" 격자를 생성하도록 요구하는 퍼즐과 같은 문제를 통해 도전합니다. 이러한 문제들은 AI가 새로운, 이전에 보지 못한 도전에 적응하는 능력을 테스트하도록 설계되었습니다.
인간의 기준선을 설정하기 위해 Arc Prize 재단은 400명 이상의 사람들에게 ARC-AGI-2 테스트를 치르게 했습니다. 평균적으로 이 "패널"들은 60%의 성공률을 달성하여 AI 모델들을 크게 앞질렀습니다.
숄레는 ARC-AGI-2가 AI 모델이 "무차별 대입" 컴퓨팅 파워에 의존하여 문제를 해결하는 것을 방지한다고 강조했으며, 이는 첫 번째 테스트에서 인정한 결함이었습니다. 이를 해결하기 위해 ARC-AGI-2는 효율성 지표를 도입하고 모델이 기억에 의존하기보다는 즉석에서 패턴을 해석하도록 요구합니다.
블로그 포스트에서 Arc Prize 재단의 공동 설립자 그렉 캠라트(Greg Kamradt)는 지능이 단순히 문제를 해결하거나 높은 점수를 얻는 것만이 아니라고 강조했습니다. 그는 "그 능력이 획득되고 배포되는 효율성이 중요한 정의적 구성 요소"라고 썼습니다. "핵심 질문은 단순히 'AI가 작업을 해결하기 위한 기술을 획득할 수 있는가?'가 아니라, '어떤 효율성이나 비용으로?'입니다."
ARC-AGI-1은 약 5년 동안 무패로 남아 있었으나, 2024년 12월 OpenAI의 고급 추론 모델인 o3가 다른 모든 AI 모델을 능가하고 인간의 성능을 따라잡았습니다. 그러나 o3의 ARC-AGI-1에서의 성공은 상당한 비용을 초래했습니다. ARC-AGI-1에서 75.7%라는 인상적인 점수를 기록한 OpenAI의 o3 모델, o3 (low)는 ARC-AGI-2에서는 태스크당 200달러의 컴퓨팅 파워를 사용하며 겨우 4%를 기록했습니다.
새로운 벤치마크와 함께 Arc Prize 재단은 Arc Prize 2025 대회를 발표했으며, 개발자들에게 ARC-AGI-2 테스트에서 85% 정확도를 달성하면서 태스크당 0.42달러만을 사용하도록 도전했습니다.









 보편적 언어 혁신으로 인류의 사고에 혁신을 가져올 AGI
인공 일반 지능의 등장은 보편적인 언어 프레임워크를 만들어 인간의 커뮤니케이션을 재구성할 수 있는 혁신적인 잠재력을 제시합니다. 특수한 작업을 위해 설계된 협소한 AI 시스템과 달리, AGI는 여러 영역에 걸쳐 인간과 유사한 학습 능력을 갖추고 있어 언어 패턴, 문화적 맥락, 인지 과정을 분석할 수 있습니다. 이러한 독특한 조합은 인간의 인지 능력을 향상시
OpenAI 비영리 뿌리 재확인, 주요 기업 개편 속에서
OpenAI는 주요 기업 개편을 진행하면서도 비영리 사명에 확고히 전념하며, 성장과 윤리적 AI 개발에 대한 헌신을 균형 있게 유지하고 있습니다.CEO Sam Altman은 회사의 비전을 설명하며, 재무 전략이 진화하고 있지만 OpenAI의 인공지능 일반(AGI)을 전 세계적 이익을 위해 발전시키겠다는 헌신은 변함없다고 강조했습니다.공개 성명에서 Altma
보편적 언어 혁신으로 인류의 사고에 혁신을 가져올 AGI
인공 일반 지능의 등장은 보편적인 언어 프레임워크를 만들어 인간의 커뮤니케이션을 재구성할 수 있는 혁신적인 잠재력을 제시합니다. 특수한 작업을 위해 설계된 협소한 AI 시스템과 달리, AGI는 여러 영역에 걸쳐 인간과 유사한 학습 능력을 갖추고 있어 언어 패턴, 문화적 맥락, 인지 과정을 분석할 수 있습니다. 이러한 독특한 조합은 인간의 인지 능력을 향상시
OpenAI 비영리 뿌리 재확인, 주요 기업 개편 속에서
OpenAI는 주요 기업 개편을 진행하면서도 비영리 사명에 확고히 전념하며, 성장과 윤리적 AI 개발에 대한 헌신을 균형 있게 유지하고 있습니다.CEO Sam Altman은 회사의 비전을 설명하며, 재무 전략이 진화하고 있지만 OpenAI의 인공지능 일반(AGI)을 전 세계적 이익을 위해 발전시키겠다는 헌신은 변함없다고 강조했습니다.공개 성명에서 Altma
 AI 리더들이 AGI 논의: 현실에 근거하여
최근 샌프란시스코에서 열린 비즈니스 리더들과의 만찬에서 던진 질문 하나가 방 안을 얼어붙게 했습니다: 오늘날의 AI가 인간 수준의 지능이나 그 이상에 도달할 수 있을까요? 이 주제는 예상보다 더 많은 논쟁을 불러일으킵니다.2025년, 기술 CEO들은 ChatGPT와 Gemini 같은 대규모 언어 모델(LLM)에 대해 낙관
2025년 7월 29일 오후 9시 25분 16초 GMT+09:00
AI 리더들이 AGI 논의: 현실에 근거하여
최근 샌프란시스코에서 열린 비즈니스 리더들과의 만찬에서 던진 질문 하나가 방 안을 얼어붙게 했습니다: 오늘날의 AI가 인간 수준의 지능이나 그 이상에 도달할 수 있을까요? 이 주제는 예상보다 더 많은 논쟁을 불러일으킵니다.2025년, 기술 CEO들은 ChatGPT와 Gemini 같은 대규모 언어 모델(LLM)에 대해 낙관
2025년 7월 29일 오후 9시 25분 16초 GMT+09:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
2025년 4월 14일 오후 5시 35분 0초 GMT+09:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
2025년 4월 14일 오전 10시 46분 37초 GMT+09:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
2025년 4월 14일 오전 4시 5분 45초 GMT+09:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
2025년 4월 14일 오전 12시 54분 39초 GMT+09:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
2025년 4월 14일 오전 12시 36분 48초 GMT+09:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













