




Thử nghiệm AGI mới chứng minh đầy thách thức, phần lớn các mô hình AI
Quỹ Arc Prize, do nhà nghiên cứu AI nổi tiếng François Chollet đồng sáng lập, gần đây đã công bố một chuẩn mực mới có tên ARC-AGI-2 trong một bài đăng blog. Bài kiểm tra này nhằm đẩy xa giới hạn của trí thông minh tổng quát của AI, và cho đến nay, nó đang chứng tỏ là một thách thức khó khăn đối với hầu hết các mô hình AI.
Theo bảng xếp hạng Arc Prize, ngay cả các mô hình AI "suy luận" tiên tiến như o1-pro của OpenAI và R1 của DeepSeek chỉ đạt điểm số từ 1% đến 1.3%. Trong khi đó, các mô hình không suy luận mạnh mẽ như GPT-4.5, Claude 3.7 Sonnet và Gemini 2.0 Flash dao động quanh mức 1%.
Các bài kiểm tra ARC-AGI thách thức các hệ thống AI với những vấn đề giống như câu đố, yêu cầu chúng xác định các mẫu hình ảnh trong các lưới ô vuông có màu sắc khác nhau và tạo ra lưới "đáp án" chính xác. Những vấn đề này được thiết kế để kiểm tra khả năng thích nghi của AI với những thách thức mới, chưa từng thấy.
Để thiết lập một đường cơ sở cho con người, Quỹ Arc Prize đã yêu cầu hơn 400 người tham gia bài kiểm tra ARC-AGI-2. Trung bình, những "nhóm" người này đạt tỷ lệ thành công 60%, vượt trội đáng kể so với các mô hình AI.
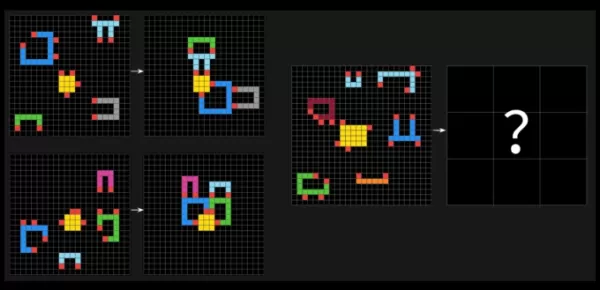
Một câu hỏi mẫu từ ARC-AGI-2. Tín dụng hình ảnh: Arc Prize François Chollet đã lên X để tuyên bố rằng ARC-AGI-2 là một thước đo chính xác hơn về trí thông minh thực sự của một mô hình AI so với phiên bản trước đó, ARC-AGI-1. Các bài kiểm tra của Quỹ Arc Prize được thiết kế để đánh giá liệu một AI có thể học các kỹ năng mới một cách hiệu quả ngoài dữ liệu huấn luyện của nó.Chollet nhấn mạnh rằng ARC-AGI-2 ngăn chặn các mô hình AI dựa vào sức mạnh tính toán "brute force" để giải quyết vấn đề, một lỗ hổng mà ông thừa nhận trong bài kiểm tra đầu tiên. Để khắc phục điều này, ARC-AGI-2 đưa ra một chỉ số hiệu quả và yêu cầu các mô hình phải diễn giải các mẫu ngay lập tức thay vì dựa vào việc ghi nhớ.
Trong một bài đăng blog, đồng sáng lập Quỹ Arc Prize Greg Kamradt nhấn mạnh rằng trí thông minh không chỉ là về việc giải quyết vấn đề hoặc đạt điểm cao. "Hiệu quả mà những khả năng đó được tiếp thu và triển khai là một thành phần quan trọng, định nghĩa," ông viết. "Câu hỏi cốt lõi không chỉ là, 'Liệu AI có thể tiếp thu kỹ năng để giải quyết một nhiệm vụ không?' mà còn là, 'Với hiệu quả hoặc chi phí bao nhiêu?'"
ARC-AGI-1 đã không bị đánh bại trong khoảng năm năm cho đến tháng 12 năm 2024, khi mô hình suy luận tiên tiến của OpenAI, o3, vượt qua tất cả các mô hình AI khác và đạt hiệu suất ngang bằng với con người. Tuy nhiên, thành công của o3 trên ARC-AGI-1 đi kèm với một chi phí đáng kể. Phiên bản mô hình o3 của OpenAI, o3 (thấp), đạt điểm ấn tượng 75.7% trên ARC-AGI-1, nhưng chỉ đạt 4% trên ARC-AGI-2, sử dụng 200 đô la sức mạnh tính toán cho mỗi nhiệm vụ.

So sánh hiệu suất của các mô hình AI Frontier trên ARC-AGI-1 và ARC-AGI-2. Tín dụng hình ảnh: Arc Prize Việc giới thiệu ARC-AGI-2 diễn ra vào thời điểm nhiều người trong ngành công nghệ đang kêu gọi các chuẩn mực mới, chưa bão hòa để đo lường tiến bộ của AI. Thomas Wolf, đồng sáng lập Hugging Face, gần đây đã nói với TechCrunch rằng ngành AI thiếu các bài kiểm tra đủ để đo lường các đặc điểm quan trọng của trí thông minh tổng quát nhân tạo, chẳng hạn như sự sáng tạo.Cùng với chuẩn mực mới, Quỹ Arc Prize đã công bố cuộc thi Arc Prize 2025, thách thức các nhà phát triển đạt độ chính xác 85% trên bài kiểm tra ARC-AGI-2 trong khi chỉ chi 0.42 đô la cho mỗi nhiệm vụ.
Bài viết liên quan
 OpenAI Tái Khẳng Định Gốc Rễ Phi Lợi Nhuận Trong Cuộc Đại Tu Doanh Nghiệp Lớn
OpenAI vẫn kiên định với sứ mệnh phi lợi nhuận khi trải qua một cuộc tái cơ cấu doanh nghiệp quan trọng, cân bằng giữa tăng trưởng và cam kết phát triển AI một cách có đạo đức.CEO Sam Altman đã phác t
Lãnh đạo AI Thảo luận về AGI: Dựa trên Thực tế
Trong một bữa tối gần đây với các nhà lãnh đạo doanh nghiệp tại San Francisco, tôi đã đặt ra một câu hỏi khiến cả phòng dường như đóng băng: liệu AI ngày nay có thể đạt đến trí tuệ
Openai Strikes Back: Sues Elon Musk vì những nỗ lực được cho là làm suy yếu đối thủ cạnh tranh AI
Openai đã đưa ra một cuộc phản công pháp lý khốc liệt chống lại người đồng sáng lập của mình, Elon Musk, và công ty AI cạnh tranh của ông, XAI. Trong một sự leo thang kịch tính của mối thù đang diễn ra của họ, Openai cáo buộc Musk đã tiến hành một chiến dịch "không ngừng" và "độc hại" để làm suy yếu công ty mà anh ta đã giúp bắt đầu. Theo Tòa án D
Nhận xét (36)
0/200
OpenAI Tái Khẳng Định Gốc Rễ Phi Lợi Nhuận Trong Cuộc Đại Tu Doanh Nghiệp Lớn
OpenAI vẫn kiên định với sứ mệnh phi lợi nhuận khi trải qua một cuộc tái cơ cấu doanh nghiệp quan trọng, cân bằng giữa tăng trưởng và cam kết phát triển AI một cách có đạo đức.CEO Sam Altman đã phác t
Lãnh đạo AI Thảo luận về AGI: Dựa trên Thực tế
Trong một bữa tối gần đây với các nhà lãnh đạo doanh nghiệp tại San Francisco, tôi đã đặt ra một câu hỏi khiến cả phòng dường như đóng băng: liệu AI ngày nay có thể đạt đến trí tuệ
Openai Strikes Back: Sues Elon Musk vì những nỗ lực được cho là làm suy yếu đối thủ cạnh tranh AI
Openai đã đưa ra một cuộc phản công pháp lý khốc liệt chống lại người đồng sáng lập của mình, Elon Musk, và công ty AI cạnh tranh của ông, XAI. Trong một sự leo thang kịch tính của mối thù đang diễn ra của họ, Openai cáo buộc Musk đã tiến hành một chiến dịch "không ngừng" và "độc hại" để làm suy yếu công ty mà anh ta đã giúp bắt đầu. Theo Tòa án D
Nhận xét (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
15:35:00 GMT+07:00 Ngày 14 tháng 4 năm 2025
GeorgeMiller
15:35:00 GMT+07:00 Ngày 14 tháng 4 năm 2025
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
08:46:37 GMT+07:00 Ngày 14 tháng 4 năm 2025
JonathanKing
08:46:37 GMT+07:00 Ngày 14 tháng 4 năm 2025
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
02:05:45 GMT+07:00 Ngày 14 tháng 4 năm 2025
DonaldGonzález
02:05:45 GMT+07:00 Ngày 14 tháng 4 năm 2025
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
22:54:39 GMT+07:00 Ngày 13 tháng 4 năm 2025
HaroldMoore
22:54:39 GMT+07:00 Ngày 13 tháng 4 năm 2025
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
22:36:48 GMT+07:00 Ngày 13 tháng 4 năm 2025
GregoryWilson
22:36:48 GMT+07:00 Ngày 13 tháng 4 năm 2025
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
Quỹ Arc Prize, do nhà nghiên cứu AI nổi tiếng François Chollet đồng sáng lập, gần đây đã công bố một chuẩn mực mới có tên ARC-AGI-2 trong một bài đăng blog. Bài kiểm tra này nhằm đẩy xa giới hạn của trí thông minh tổng quát của AI, và cho đến nay, nó đang chứng tỏ là một thách thức khó khăn đối với hầu hết các mô hình AI.
Theo bảng xếp hạng Arc Prize, ngay cả các mô hình AI "suy luận" tiên tiến như o1-pro của OpenAI và R1 của DeepSeek chỉ đạt điểm số từ 1% đến 1.3%. Trong khi đó, các mô hình không suy luận mạnh mẽ như GPT-4.5, Claude 3.7 Sonnet và Gemini 2.0 Flash dao động quanh mức 1%.
Các bài kiểm tra ARC-AGI thách thức các hệ thống AI với những vấn đề giống như câu đố, yêu cầu chúng xác định các mẫu hình ảnh trong các lưới ô vuông có màu sắc khác nhau và tạo ra lưới "đáp án" chính xác. Những vấn đề này được thiết kế để kiểm tra khả năng thích nghi của AI với những thách thức mới, chưa từng thấy.
Để thiết lập một đường cơ sở cho con người, Quỹ Arc Prize đã yêu cầu hơn 400 người tham gia bài kiểm tra ARC-AGI-2. Trung bình, những "nhóm" người này đạt tỷ lệ thành công 60%, vượt trội đáng kể so với các mô hình AI.
Chollet nhấn mạnh rằng ARC-AGI-2 ngăn chặn các mô hình AI dựa vào sức mạnh tính toán "brute force" để giải quyết vấn đề, một lỗ hổng mà ông thừa nhận trong bài kiểm tra đầu tiên. Để khắc phục điều này, ARC-AGI-2 đưa ra một chỉ số hiệu quả và yêu cầu các mô hình phải diễn giải các mẫu ngay lập tức thay vì dựa vào việc ghi nhớ.
Trong một bài đăng blog, đồng sáng lập Quỹ Arc Prize Greg Kamradt nhấn mạnh rằng trí thông minh không chỉ là về việc giải quyết vấn đề hoặc đạt điểm cao. "Hiệu quả mà những khả năng đó được tiếp thu và triển khai là một thành phần quan trọng, định nghĩa," ông viết. "Câu hỏi cốt lõi không chỉ là, 'Liệu AI có thể tiếp thu kỹ năng để giải quyết một nhiệm vụ không?' mà còn là, 'Với hiệu quả hoặc chi phí bao nhiêu?'"
ARC-AGI-1 đã không bị đánh bại trong khoảng năm năm cho đến tháng 12 năm 2024, khi mô hình suy luận tiên tiến của OpenAI, o3, vượt qua tất cả các mô hình AI khác và đạt hiệu suất ngang bằng với con người. Tuy nhiên, thành công của o3 trên ARC-AGI-1 đi kèm với một chi phí đáng kể. Phiên bản mô hình o3 của OpenAI, o3 (thấp), đạt điểm ấn tượng 75.7% trên ARC-AGI-1, nhưng chỉ đạt 4% trên ARC-AGI-2, sử dụng 200 đô la sức mạnh tính toán cho mỗi nhiệm vụ.
Cùng với chuẩn mực mới, Quỹ Arc Prize đã công bố cuộc thi Arc Prize 2025, thách thức các nhà phát triển đạt độ chính xác 85% trên bài kiểm tra ARC-AGI-2 trong khi chỉ chi 0.42 đô la cho mỗi nhiệm vụ.









 OpenAI Tái Khẳng Định Gốc Rễ Phi Lợi Nhuận Trong Cuộc Đại Tu Doanh Nghiệp Lớn
OpenAI vẫn kiên định với sứ mệnh phi lợi nhuận khi trải qua một cuộc tái cơ cấu doanh nghiệp quan trọng, cân bằng giữa tăng trưởng và cam kết phát triển AI một cách có đạo đức.CEO Sam Altman đã phác t
OpenAI Tái Khẳng Định Gốc Rễ Phi Lợi Nhuận Trong Cuộc Đại Tu Doanh Nghiệp Lớn
OpenAI vẫn kiên định với sứ mệnh phi lợi nhuận khi trải qua một cuộc tái cơ cấu doanh nghiệp quan trọng, cân bằng giữa tăng trưởng và cam kết phát triển AI một cách có đạo đức.CEO Sam Altman đã phác t
 Lãnh đạo AI Thảo luận về AGI: Dựa trên Thực tế
Trong một bữa tối gần đây với các nhà lãnh đạo doanh nghiệp tại San Francisco, tôi đã đặt ra một câu hỏi khiến cả phòng dường như đóng băng: liệu AI ngày nay có thể đạt đến trí tuệ
Openai Strikes Back: Sues Elon Musk vì những nỗ lực được cho là làm suy yếu đối thủ cạnh tranh AI
Openai đã đưa ra một cuộc phản công pháp lý khốc liệt chống lại người đồng sáng lập của mình, Elon Musk, và công ty AI cạnh tranh của ông, XAI. Trong một sự leo thang kịch tính của mối thù đang diễn ra của họ, Openai cáo buộc Musk đã tiến hành một chiến dịch "không ngừng" và "độc hại" để làm suy yếu công ty mà anh ta đã giúp bắt đầu. Theo Tòa án D
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
Lãnh đạo AI Thảo luận về AGI: Dựa trên Thực tế
Trong một bữa tối gần đây với các nhà lãnh đạo doanh nghiệp tại San Francisco, tôi đã đặt ra một câu hỏi khiến cả phòng dường như đóng băng: liệu AI ngày nay có thể đạt đến trí tuệ
Openai Strikes Back: Sues Elon Musk vì những nỗ lực được cho là làm suy yếu đối thủ cạnh tranh AI
Openai đã đưa ra một cuộc phản công pháp lý khốc liệt chống lại người đồng sáng lập của mình, Elon Musk, và công ty AI cạnh tranh của ông, XAI. Trong một sự leo thang kịch tính của mối thù đang diễn ra của họ, Openai cáo buộc Musk đã tiến hành một chiến dịch "không ngừng" và "độc hại" để làm suy yếu công ty mà anh ta đã giúp bắt đầu. Theo Tòa án D
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
15:35:00 GMT+07:00 Ngày 14 tháng 4 năm 2025
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
08:46:37 GMT+07:00 Ngày 14 tháng 4 năm 2025
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
02:05:45 GMT+07:00 Ngày 14 tháng 4 năm 2025
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
22:54:39 GMT+07:00 Ngày 13 tháng 4 năm 2025
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
22:36:48 GMT+07:00 Ngày 13 tháng 4 năm 2025
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













