
















 首页
首页新的AGI测试证明了具有挑战性,大多数AI模型
Arc奖基金会,由著名AI研究者弗朗索瓦·肖莱共同创立,最近在一篇博客文章中公布了一个名为ARC-AGI-2的新基准测试。该测试旨在推动AI通用智能的边界,到目前为止,对于大多数AI模型来说,这是一个难以破解的难题。
根据Arc奖排行榜,即使是像OpenAI的o1-pro和DeepSeek的R1这样的高级“推理”AI模型,也只能取得1%到1.3%的分数。同时,强大的非推理模型,如GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Flash,也仅在1%左右徘徊。
ARC-AGI测试通过类似拼图的问题挑战AI系统,要求它们识别不同颜色方块网格中的视觉模式,并生成正确的“答案”网格。这些问题旨在测试AI适应全新、未见过挑战的能力。
为了建立人类基准,Arc奖基金会有超过400人参加了ARC-AGI-2测试。平均而言,这些“测试小组”的人类取得了60%的成功率,显著优于AI模型。
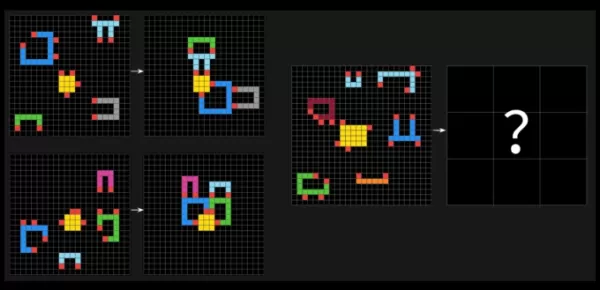
ARC-AGI-2的一个示例问题。图片来源:Arc奖 弗朗索瓦·肖莱在X上表示,与其前身ARC-AGI-1相比,ARC-AGI-2是衡量AI模型真实智能的更准确标准。Arc奖基金会的测试旨在评估AI是否能高效学习超出其训练数据的新技能。肖莱强调,ARC-AGI-2防止AI模型依赖“暴力计算”来解决问题,这是他承认的第一个测试中的缺陷。为此,ARC-AGI-2引入了效率指标,并要求模型即时解读模式,而不是依赖记忆。
在博客文章中,Arc奖基金会共同创始人格雷格·卡姆拉特强调,智能不仅仅是解决问题或取得高分。他写道:“这些能力被获取和部署的效率是一个关键的定义组成部分。核心问题不仅是‘AI能否获得解决任务的技能?’,还有‘以何种效率或成本?’”
ARC-AGI-1在大约五年内未被击败,直到2024年12月,OpenAI的高级推理模型o3超越了所有其他AI模型,并达到了人类表现水平。然而,o3在ARC-AGI-1上的成功付出了巨大成本。OpenAI的o3模型版本o3 (low)在ARC-AGI-1上取得了令人印象深刻的75.7%分数,但在ARC-AGI-2上仅取得4%的成绩,每项任务使用了价值200美元的计算能力。

前沿AI模型在ARC-AGI-1和ARC-AGI-2上的性能比较。图片来源:Arc奖 ARC-AGI-2的推出正值科技行业许多人呼吁新的、未饱和的基准来衡量AI进展之际。Hugging Face的共同创始人托马斯·沃尔夫最近对TechCrunch表示,AI行业缺乏足够的测试来衡量人工通用智能的关键特质,如创造力。除了新基准外,Arc奖基金会还宣布了2025年Arc奖竞赛,挑战开发者在ARC-AGI-2测试中实现85%的准确率,同时每项任务仅花费0.42美元。
相关文章
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
Databricks联合创始人获ACM奖后宣称通用人工智能即将到来
Databricks联合创始人兼首席技术官马泰·扎哈里亚(Matei Zaharia)差点就忽略了那封通知他荣获2026年ACM计算奖的邮件。“这确实是个惊喜,”他向TechCrunch透露道。2009年,扎哈里亚在加州大学伯克利分校攻读博士期间,在著名教授伊昂·斯托伊卡(Ion Stoica)的指导下开发的技术被整合到了Databricks中。扎哈里亚设计了一种方法,能显著加速处理那些缓慢且繁琐
OpenAI创始人山姆·阿尔特曼宣告超级智能时代来临
OpenAI首席执行官山姆·奥尔特曼宣布,人类已进入人工智能超级智能时代,且无法回头。"我们已越过不可逆转的临界点,上升阶段正式开启,"奥特曼表示,"人类正站在创造数字超级智能的边缘,而迄今为止,其发展态势竟比想象中更不令人感到陌生。"尽管缺乏明显迹象——街头尚未遍布机器人,疾病依然存在——但奥特曼所描述的深刻变革已悄然启动。在他这样的公司内部,正在研发能够超越人类通用智能的系统。"从重要意义上说
相关专题推荐
商业
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
Databricks联合创始人获ACM奖后宣称通用人工智能即将到来
Databricks联合创始人兼首席技术官马泰·扎哈里亚(Matei Zaharia)差点就忽略了那封通知他荣获2026年ACM计算奖的邮件。“这确实是个惊喜,”他向TechCrunch透露道。2009年,扎哈里亚在加州大学伯克利分校攻读博士期间,在著名教授伊昂·斯托伊卡(Ion Stoica)的指导下开发的技术被整合到了Databricks中。扎哈里亚设计了一种方法,能显著加速处理那些缓慢且繁琐
OpenAI创始人山姆·阿尔特曼宣告超级智能时代来临
OpenAI首席执行官山姆·奥尔特曼宣布,人类已进入人工智能超级智能时代,且无法回头。"我们已越过不可逆转的临界点,上升阶段正式开启,"奥特曼表示,"人类正站在创造数字超级智能的边缘,而迄今为止,其发展态势竟比想象中更不令人感到陌生。"尽管缺乏明显迹象——街头尚未遍布机器人,疾病依然存在——但奥特曼所描述的深刻变革已悄然启动。在他这样的公司内部,正在研发能够超越人类通用智能的系统。"从重要意义上说
相关专题推荐
商业
 最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
 10 个工具
10 个工具
 xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

 评论 (39)
0/500
评论 (39)
0/500
![DonaldSanchez]()
이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
![MarkRoberts]()
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
![RonaldRoberts]()
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
![WillieRoberts]()
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
![GeorgeMiller]()
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
![JonathanKing]()
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
Arc奖基金会,由著名AI研究者弗朗索瓦·肖莱共同创立,最近在一篇博客文章中公布了一个名为ARC-AGI-2的新基准测试。该测试旨在推动AI通用智能的边界,到目前为止,对于大多数AI模型来说,这是一个难以破解的难题。
根据Arc奖排行榜,即使是像OpenAI的o1-pro和DeepSeek的R1这样的高级“推理”AI模型,也只能取得1%到1.3%的分数。同时,强大的非推理模型,如GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Flash,也仅在1%左右徘徊。
ARC-AGI测试通过类似拼图的问题挑战AI系统,要求它们识别不同颜色方块网格中的视觉模式,并生成正确的“答案”网格。这些问题旨在测试AI适应全新、未见过挑战的能力。
为了建立人类基准,Arc奖基金会有超过400人参加了ARC-AGI-2测试。平均而言,这些“测试小组”的人类取得了60%的成功率,显著优于AI模型。
肖莱强调,ARC-AGI-2防止AI模型依赖“暴力计算”来解决问题,这是他承认的第一个测试中的缺陷。为此,ARC-AGI-2引入了效率指标,并要求模型即时解读模式,而不是依赖记忆。
在博客文章中,Arc奖基金会共同创始人格雷格·卡姆拉特强调,智能不仅仅是解决问题或取得高分。他写道:“这些能力被获取和部署的效率是一个关键的定义组成部分。核心问题不仅是‘AI能否获得解决任务的技能?’,还有‘以何种效率或成本?’”
ARC-AGI-1在大约五年内未被击败,直到2024年12月,OpenAI的高级推理模型o3超越了所有其他AI模型,并达到了人类表现水平。然而,o3在ARC-AGI-1上的成功付出了巨大成本。OpenAI的o3模型版本o3 (low)在ARC-AGI-1上取得了令人印象深刻的75.7%分数,但在ARC-AGI-2上仅取得4%的成绩,每项任务使用了价值200美元的计算能力。
除了新基准外,Arc奖基金会还宣布了2025年Arc奖竞赛,挑战开发者在ARC-AGI-2测试中实现85%的准确率,同时每项任务仅花费0.42美元。










 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
 Databricks联合创始人获ACM奖后宣称通用人工智能即将到来
Databricks联合创始人兼首席技术官马泰·扎哈里亚(Matei Zaharia)差点就忽略了那封通知他荣获2026年ACM计算奖的邮件。“这确实是个惊喜,”他向TechCrunch透露道。2009年,扎哈里亚在加州大学伯克利分校攻读博士期间,在著名教授伊昂·斯托伊卡(Ion Stoica)的指导下开发的技术被整合到了Databricks中。扎哈里亚设计了一种方法,能显著加速处理那些缓慢且繁琐
OpenAI创始人山姆·阿尔特曼宣告超级智能时代来临
OpenAI首席执行官山姆·奥尔特曼宣布,人类已进入人工智能超级智能时代,且无法回头。"我们已越过不可逆转的临界点,上升阶段正式开启,"奥特曼表示,"人类正站在创造数字超级智能的边缘,而迄今为止,其发展态势竟比想象中更不令人感到陌生。"尽管缺乏明显迹象——街头尚未遍布机器人,疾病依然存在——但奥特曼所描述的深刻变革已悄然启动。在他这样的公司内部,正在研发能够超越人类通用智能的系统。"从重要意义上说
Databricks联合创始人获ACM奖后宣称通用人工智能即将到来
Databricks联合创始人兼首席技术官马泰·扎哈里亚(Matei Zaharia)差点就忽略了那封通知他荣获2026年ACM计算奖的邮件。“这确实是个惊喜,”他向TechCrunch透露道。2009年,扎哈里亚在加州大学伯克利分校攻读博士期间,在著名教授伊昂·斯托伊卡(Ion Stoica)的指导下开发的技术被整合到了Databricks中。扎哈里亚设计了一种方法,能显著加速处理那些缓慢且繁琐
OpenAI创始人山姆·阿尔特曼宣告超级智能时代来临
OpenAI首席执行官山姆·奥尔特曼宣布,人类已进入人工智能超级智能时代,且无法回头。"我们已越过不可逆转的临界点,上升阶段正式开启,"奥特曼表示,"人类正站在创造数字超级智能的边缘,而迄今为止,其发展态势竟比想象中更不令人感到陌生。"尽管缺乏明显迹象——街头尚未遍布机器人,疾病依然存在——但奥特曼所描述的深刻变革已悄然启动。在他这样的公司内部,正在研发能够超越人类通用智能的系统。"从重要意义上说

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?













