




नया AGI परीक्षण चुनौतीपूर्ण साबित होता है, AI मॉडल के बहुमत स्टंप्स
आर्क पुरस्कार फाउंडेशन, जिसे प्रसिद्ध AI शोधकर्ता फ्राँस्वा शोले ने सह-स्थापित किया, ने हाल ही में एक ब्लॉग पोस्ट में ARC-AGI-2 नामक एक नया बेंचमार्क पेश किया। यह परीक्षण AI की सामान्य बुद्धिमत्ता की सीमाओं को आगे बढ़ाने का लक्ष्य रखता है, और अब तक, यह अधिकांश AI मॉडलों के लिए एक कठिन चुनौती साबित हो रहा है।
आर्क पुरस्कार लीडरबोर्ड के अनुसार, OpenAI के o1-pro और DeepSeek के R1 जैसे उन्नत "रीजनिंग" AI मॉडल भी केवल 1% से 1.3% के बीच स्कोर प्राप्त कर रहे हैं। इस बीच, GPT-4.5, Claude 3.7 Sonnet, और Gemini 2.0 Flash जैसे शक्तिशाली गैर-रीजनिंग मॉडल 1% के आसपास स्कोर कर रहे हैं।
ARC-AGI परीक्षण AI सिस्टम्स को पहेली जैसे समस्याओं के साथ चुनौती देते हैं, जिनमें उन्हें विभिन्न रंगों के वर्गों के ग्रिड में दृश्य पैटर्न की पहचान करनी होती है और सही "उत्तर" ग्रिड उत्पन्न करना होता है। ये समस्याएँ AI की नई, अनदेखी चुनौतियों के अनुकूल होने की क्षमता का परीक्षण करने के लिए डिज़ाइन की गई हैं।
मानव आधारभूत रेखा स्थापित करने के लिए, आर्क पुरस्कार फाउंडेशन ने 400 से अधिक लोगों से ARC-AGI-2 परीक्षण लिया। औसतन, इन "पैनलों" ने 60% की सफलता दर हासिल की, जो AI मॉडलों से काफी बेहतर प्रदर्शन है।
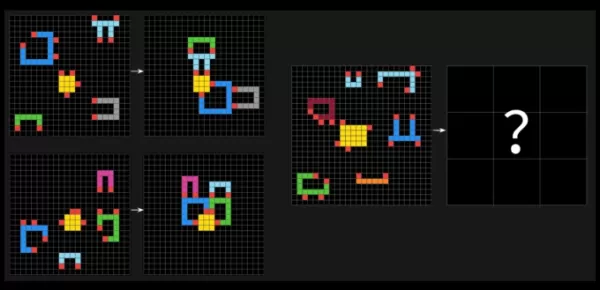
ARC-AGI-2 से एक नमूना प्रश्न। छवि सौजन्य: आर्क पुरस्कार फ्राँस्वा शोले ने X पर दावा किया कि ARC-AGI-2 अपने पूर्ववर्ती, ARC-AGI-1 की तुलना में AI मॉडल की वास्तविक बुद्धिमत्ता का अधिक सटीक माप है। आर्क पुरस्कार फाउंडेशन के परीक्षण यह आकलन करने के लिए डिज़ाइन किए गए हैं कि क्या AI अपने प्रशिक्षण डेटा से परे नई कौशल को कुशलतापूर्वक सीख सकता है।शोले ने जोर देकर कहा कि ARC-AGI-2 AI मॉडलों को समस्याओं को हल करने के लिए "ब्रूट फोर्स" कंप्यूटिंग शक्ति पर निर्भर करने से रोकता है, जो कि पहले परीक्षण में एक कमी थी। इसे संबोधित करने के लिए, ARC-AGI-2 एक दक्षता मीट्रिक पेश करता है और मॉडलों से पैटर्न को तुरंत व्याख्या करने की आवश्यकता होती है, न कि स्मृति पर निर्भर करने की।
एक ब्लॉग पोस्ट में, आर्क पुरस्कार फाउंडेशन के सह-संस्थापक ग्रेग कामराट ने जोर देकर कहा कि बुद्धिमत्ता केवल समस्याओं को हल करने या उच्च स्कोर प्राप्त करने के बारे में नहीं है। "उन क्षमताओं को प्राप्त करने और तैनात करने की दक्षता एक महत्वपूर्ण, परिभाषित घटक है," उन्होंने लिखा। "मूल प्रश्न यह नहीं है कि 'क्या AI किसी कार्य को हल करने का कौशल प्राप्त कर सकता है?' बल्कि यह भी है कि 'किस दक्षता या लागत पर?'"
ARC-AGI-1 लगभग पांच वर्षों तक अपराजित रहा, जब तक कि दिसंबर 2024 में OpenAI के उन्नत रीजनिंग मॉडल, o3, ने सभी अन्य AI मॉडलों को पीछे छोड़ दिया और मानव प्रदर्शन के बराबर पहुंच गया। हालांकि, ARC-AGI-1 पर o3 की सफलता एक महत्वपूर्ण लागत पर आई। OpenAI के o3 मॉडल का संस्करण, o3 (low), जिसने ARC-AGI-1 पर प्रभावशाली 75.7% स्कोर किया, ARC-AGI-2 पर केवल 4% स्कोर कर सका, प्रति कार्य $200 की कंप्यूटिंग शक्ति का उपयोग करते हुए।

ARC-AGI-1 और ARC-AGI-2 पर फ्रंटियर AI मॉडल प्रदर्शन की तुलना। छवि सौजन्य: आर्क पुरस्कार ARC-AGI-2 का परिचय ऐसे समय में हुआ है जब तकनीकी उद्योग में कई लोग AI प्रगति को मापने के लिए नए, असंतृप्त बेंचमार्क की मांग कर रहे हैं। Hugging Face के सह-संस्थापक थॉमस वोल्फ ने हाल ही में TechCrunch को बताया कि AI उद्योग में कृत्रिम सामान्य बुद्धिमत्ता के प्रमुख लक्षणों, जैसे रचनात्मकता, को मापने के लिए पर्याप्त परीक्षणों की कमी है।नए बेंचमार्क के साथ, आर्क पुरस्कार फाउंडेशन ने आर्क पुरस्कार 2025 प्रतियोगिता की घोषणा की, जिसमें डेवलपर्स को ARC-AGI-2 परीक्षण पर 85% सटीकता प्राप्त करने की चुनौती दी गई है, जबकि प्रति कार्य केवल $0.42 खर्च करना है।
संबंधित लेख
 OpenAI अपनी गैर-लाभकारी जड़ों की पुन: पुष्टि करता है प्रमुख कॉर्पोरेट पुनर्गठन में
OpenAI अपनी गैर-लाभकारी मिशन में दृढ़ रहता है क्योंकि यह एक महत्वपूर्ण कॉर्पोरेट पुनर्गठन से गुजर रहा है, विकास को नैतिक AI विकास के प्रति अपनी प्रतिबद्धता के साथ संतुलित करता है।सीईओ सैम ऑल्टमैन ने क
एआई नेता एजीआई पर चर्चा करते हैं: वास्तविकता में आधारित
सैन फ्रांसिस्को में बिज़नेस लीडर्स के साथ हाल ही में एक डिनर पर, मैंने एक सवाल उठाया जिससे कमरा जैसे ठंडा पड़ गया: क्या आज की AI कभी मानव जैसी बुद्धिमत्ता या उससे आगे पहुँच सकती है
Openai स्ट्राइक्स बैक: एआई प्रतियोगी को कम करने के लिए कथित प्रयासों के लिए एलोन मस्क ने कहा
Openai ने अपने सह-संस्थापक, एलोन मस्क और उनकी प्रतिस्पर्धी AI कंपनी, XAI के खिलाफ एक भयंकर कानूनी पलटवार लॉन्च किया है। अपने चल रहे झगड़े के एक नाटकीय वृद्धि में, ओपनई ने कस्तूरी पर आरोप लगाया कि वह उस कंपनी को कम करने में मदद करने के लिए एक "अथक" और "दुर्भावनापूर्ण" अभियान को छेड़ने का आरोप लगाता है। अदालत के अनुसार डी
सूचना (36)
0/200
OpenAI अपनी गैर-लाभकारी जड़ों की पुन: पुष्टि करता है प्रमुख कॉर्पोरेट पुनर्गठन में
OpenAI अपनी गैर-लाभकारी मिशन में दृढ़ रहता है क्योंकि यह एक महत्वपूर्ण कॉर्पोरेट पुनर्गठन से गुजर रहा है, विकास को नैतिक AI विकास के प्रति अपनी प्रतिबद्धता के साथ संतुलित करता है।सीईओ सैम ऑल्टमैन ने क
एआई नेता एजीआई पर चर्चा करते हैं: वास्तविकता में आधारित
सैन फ्रांसिस्को में बिज़नेस लीडर्स के साथ हाल ही में एक डिनर पर, मैंने एक सवाल उठाया जिससे कमरा जैसे ठंडा पड़ गया: क्या आज की AI कभी मानव जैसी बुद्धिमत्ता या उससे आगे पहुँच सकती है
Openai स्ट्राइक्स बैक: एआई प्रतियोगी को कम करने के लिए कथित प्रयासों के लिए एलोन मस्क ने कहा
Openai ने अपने सह-संस्थापक, एलोन मस्क और उनकी प्रतिस्पर्धी AI कंपनी, XAI के खिलाफ एक भयंकर कानूनी पलटवार लॉन्च किया है। अपने चल रहे झगड़े के एक नाटकीय वृद्धि में, ओपनई ने कस्तूरी पर आरोप लगाया कि वह उस कंपनी को कम करने में मदद करने के लिए एक "अथक" और "दुर्भावनापूर्ण" अभियान को छेड़ने का आरोप लगाता है। अदालत के अनुसार डी
सूचना (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 29 जुलाई 2025 5:55:16 अपराह्न IST
29 जुलाई 2025 5:55:16 अपराह्न IST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14 अप्रैल 2025 2:05:00 अपराह्न IST
GeorgeMiller
14 अप्रैल 2025 2:05:00 अपराह्न IST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14 अप्रैल 2025 7:16:37 पूर्वाह्न IST
JonathanKing
14 अप्रैल 2025 7:16:37 पूर्वाह्न IST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
14 अप्रैल 2025 12:35:45 पूर्वाह्न IST
DonaldGonzález
14 अप्रैल 2025 12:35:45 पूर्वाह्न IST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13 अप्रैल 2025 9:24:39 अपराह्न IST
HaroldMoore
13 अप्रैल 2025 9:24:39 अपराह्न IST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13 अप्रैल 2025 9:06:48 अपराह्न IST
GregoryWilson
13 अप्रैल 2025 9:06:48 अपराह्न IST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
आर्क पुरस्कार फाउंडेशन, जिसे प्रसिद्ध AI शोधकर्ता फ्राँस्वा शोले ने सह-स्थापित किया, ने हाल ही में एक ब्लॉग पोस्ट में ARC-AGI-2 नामक एक नया बेंचमार्क पेश किया। यह परीक्षण AI की सामान्य बुद्धिमत्ता की सीमाओं को आगे बढ़ाने का लक्ष्य रखता है, और अब तक, यह अधिकांश AI मॉडलों के लिए एक कठिन चुनौती साबित हो रहा है।
आर्क पुरस्कार लीडरबोर्ड के अनुसार, OpenAI के o1-pro और DeepSeek के R1 जैसे उन्नत "रीजनिंग" AI मॉडल भी केवल 1% से 1.3% के बीच स्कोर प्राप्त कर रहे हैं। इस बीच, GPT-4.5, Claude 3.7 Sonnet, और Gemini 2.0 Flash जैसे शक्तिशाली गैर-रीजनिंग मॉडल 1% के आसपास स्कोर कर रहे हैं।
ARC-AGI परीक्षण AI सिस्टम्स को पहेली जैसे समस्याओं के साथ चुनौती देते हैं, जिनमें उन्हें विभिन्न रंगों के वर्गों के ग्रिड में दृश्य पैटर्न की पहचान करनी होती है और सही "उत्तर" ग्रिड उत्पन्न करना होता है। ये समस्याएँ AI की नई, अनदेखी चुनौतियों के अनुकूल होने की क्षमता का परीक्षण करने के लिए डिज़ाइन की गई हैं।
मानव आधारभूत रेखा स्थापित करने के लिए, आर्क पुरस्कार फाउंडेशन ने 400 से अधिक लोगों से ARC-AGI-2 परीक्षण लिया। औसतन, इन "पैनलों" ने 60% की सफलता दर हासिल की, जो AI मॉडलों से काफी बेहतर प्रदर्शन है।
शोले ने जोर देकर कहा कि ARC-AGI-2 AI मॉडलों को समस्याओं को हल करने के लिए "ब्रूट फोर्स" कंप्यूटिंग शक्ति पर निर्भर करने से रोकता है, जो कि पहले परीक्षण में एक कमी थी। इसे संबोधित करने के लिए, ARC-AGI-2 एक दक्षता मीट्रिक पेश करता है और मॉडलों से पैटर्न को तुरंत व्याख्या करने की आवश्यकता होती है, न कि स्मृति पर निर्भर करने की।
एक ब्लॉग पोस्ट में, आर्क पुरस्कार फाउंडेशन के सह-संस्थापक ग्रेग कामराट ने जोर देकर कहा कि बुद्धिमत्ता केवल समस्याओं को हल करने या उच्च स्कोर प्राप्त करने के बारे में नहीं है। "उन क्षमताओं को प्राप्त करने और तैनात करने की दक्षता एक महत्वपूर्ण, परिभाषित घटक है," उन्होंने लिखा। "मूल प्रश्न यह नहीं है कि 'क्या AI किसी कार्य को हल करने का कौशल प्राप्त कर सकता है?' बल्कि यह भी है कि 'किस दक्षता या लागत पर?'"
ARC-AGI-1 लगभग पांच वर्षों तक अपराजित रहा, जब तक कि दिसंबर 2024 में OpenAI के उन्नत रीजनिंग मॉडल, o3, ने सभी अन्य AI मॉडलों को पीछे छोड़ दिया और मानव प्रदर्शन के बराबर पहुंच गया। हालांकि, ARC-AGI-1 पर o3 की सफलता एक महत्वपूर्ण लागत पर आई। OpenAI के o3 मॉडल का संस्करण, o3 (low), जिसने ARC-AGI-1 पर प्रभावशाली 75.7% स्कोर किया, ARC-AGI-2 पर केवल 4% स्कोर कर सका, प्रति कार्य $200 की कंप्यूटिंग शक्ति का उपयोग करते हुए।
नए बेंचमार्क के साथ, आर्क पुरस्कार फाउंडेशन ने आर्क पुरस्कार 2025 प्रतियोगिता की घोषणा की, जिसमें डेवलपर्स को ARC-AGI-2 परीक्षण पर 85% सटीकता प्राप्त करने की चुनौती दी गई है, जबकि प्रति कार्य केवल $0.42 खर्च करना है।









 OpenAI अपनी गैर-लाभकारी जड़ों की पुन: पुष्टि करता है प्रमुख कॉर्पोरेट पुनर्गठन में
OpenAI अपनी गैर-लाभकारी मिशन में दृढ़ रहता है क्योंकि यह एक महत्वपूर्ण कॉर्पोरेट पुनर्गठन से गुजर रहा है, विकास को नैतिक AI विकास के प्रति अपनी प्रतिबद्धता के साथ संतुलित करता है।सीईओ सैम ऑल्टमैन ने क
OpenAI अपनी गैर-लाभकारी जड़ों की पुन: पुष्टि करता है प्रमुख कॉर्पोरेट पुनर्गठन में
OpenAI अपनी गैर-लाभकारी मिशन में दृढ़ रहता है क्योंकि यह एक महत्वपूर्ण कॉर्पोरेट पुनर्गठन से गुजर रहा है, विकास को नैतिक AI विकास के प्रति अपनी प्रतिबद्धता के साथ संतुलित करता है।सीईओ सैम ऑल्टमैन ने क
 एआई नेता एजीआई पर चर्चा करते हैं: वास्तविकता में आधारित
सैन फ्रांसिस्को में बिज़नेस लीडर्स के साथ हाल ही में एक डिनर पर, मैंने एक सवाल उठाया जिससे कमरा जैसे ठंडा पड़ गया: क्या आज की AI कभी मानव जैसी बुद्धिमत्ता या उससे आगे पहुँच सकती है
Openai स्ट्राइक्स बैक: एआई प्रतियोगी को कम करने के लिए कथित प्रयासों के लिए एलोन मस्क ने कहा
Openai ने अपने सह-संस्थापक, एलोन मस्क और उनकी प्रतिस्पर्धी AI कंपनी, XAI के खिलाफ एक भयंकर कानूनी पलटवार लॉन्च किया है। अपने चल रहे झगड़े के एक नाटकीय वृद्धि में, ओपनई ने कस्तूरी पर आरोप लगाया कि वह उस कंपनी को कम करने में मदद करने के लिए एक "अथक" और "दुर्भावनापूर्ण" अभियान को छेड़ने का आरोप लगाता है। अदालत के अनुसार डी
29 जुलाई 2025 5:55:16 अपराह्न IST
एआई नेता एजीआई पर चर्चा करते हैं: वास्तविकता में आधारित
सैन फ्रांसिस्को में बिज़नेस लीडर्स के साथ हाल ही में एक डिनर पर, मैंने एक सवाल उठाया जिससे कमरा जैसे ठंडा पड़ गया: क्या आज की AI कभी मानव जैसी बुद्धिमत्ता या उससे आगे पहुँच सकती है
Openai स्ट्राइक्स बैक: एआई प्रतियोगी को कम करने के लिए कथित प्रयासों के लिए एलोन मस्क ने कहा
Openai ने अपने सह-संस्थापक, एलोन मस्क और उनकी प्रतिस्पर्धी AI कंपनी, XAI के खिलाफ एक भयंकर कानूनी पलटवार लॉन्च किया है। अपने चल रहे झगड़े के एक नाटकीय वृद्धि में, ओपनई ने कस्तूरी पर आरोप लगाया कि वह उस कंपनी को कम करने में मदद करने के लिए एक "अथक" और "दुर्भावनापूर्ण" अभियान को छेड़ने का आरोप लगाता है। अदालत के अनुसार डी
29 जुलाई 2025 5:55:16 अपराह्न IST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14 अप्रैल 2025 2:05:00 अपराह्न IST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14 अप्रैल 2025 7:16:37 पूर्वाह्न IST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
14 अप्रैल 2025 12:35:45 पूर्वाह्न IST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13 अप्रैल 2025 9:24:39 अपराह्न IST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13 अप्रैल 2025 9:06:48 अपराह्न IST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













