




新しいAGIテストは挑戦的であり、AIモデルの大部分を切り株します
アーク賞財団は、著名なAI研究者フランソワ・ショレが共同設立者として参加し、最近のブログ投稿でARC-AGI-2という新たなベンチマークを発表しました。このテストはAIの一般知能の限界を押し広げることを目指しており、これまでのところ、ほとんどのAIモデルにとって難題であることが証明されています。
アーク賞のリーダーボードによると、OpenAIのo1-proやDeepSeekのR1のような高度な「推論」AIモデルでさえ、スコアは1%から1.3%の間に留まっています。一方、GPT-4.5、Claude 3.7 Sonnet、Gemini 2.0 Flashといった強力な非推論モデルは、1%前後のスコアにとどまっています。
ARC-AGIテストは、AIシステムに対して異なる色の四角形のグリッドで視覚的パターンを識別し、正しい「答え」のグリッドを生成することを求めるパズルのような問題で挑戦します。これらの問題は、AIが新しい、未見の課題に適応する能力をテストするために設計されています。
人間の基準を確立するため、アーク賞財団は400人以上にARC-AGI-2テストを受けさせました。平均して、これらの「パネル」の人間は60%の成功率を達成し、AIモデルを大きく上回りました。
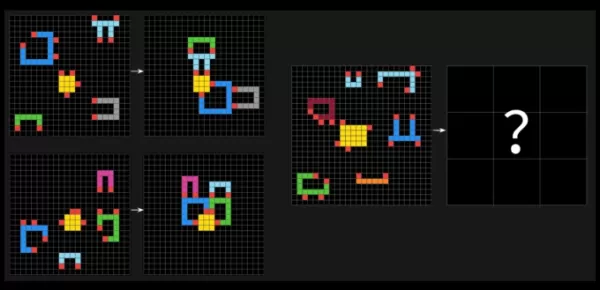
ARC-AGI-2からのサンプル問題。画像提供:Arc Prize フランソワ・ショレはXで、ARC-AGI-2は前身のARC-AGI-1と比較して、AIモデルの真の知能をより正確に測定すると主張しました。アーク賞財団のテストは、AIがトレーニングデータ以外の新しいスキルを効率的に学習できるかどうかを評価するために設計されています。ショレは、ARC-AGI-2がAIモデルが「力ずく」の計算能力に頼って問題を解決することを防ぐと強調し、最初のテストで認められた欠点を修正しました。これに対処するため、ARC-AGI-2は効率メトリックを導入し、モデルが記憶に頼るのではなく、その場でパターンを解釈することを要求します。
ブログ投稿で、アーク賞財団の共同設立者グレッグ・カムラットは、知能は単に問題を解決したり高スコアを達成することだけではないと強調しました。「それらの能力が取得され、展開される効率は、決定的な重要な要素です」と彼は書いています。「問われている核心的な質問は、『AIがタスクを解決するスキルを獲得できるか?』だけでなく、『どの程度の効率またはコストで?』でもあります」
ARC-AGI-1は約5年間無敗でしたが、2024年12月にOpenAIの高度な推論モデルo3が他のすべてのAIモデルを上回り、人間のパフォーマンスに匹敵しました。しかし、ARC-AGI-1でのo3の成功は大きなコストを伴いました。ARC-AGI-1で75.7%の印象的なスコアを達成したOpenAIのo3モデル(o3 (low))は、ARC-AGI-2ではタスクごとに200ドルの計算能力を使用して、わずか4%しか達成できませんでした。

ARC-AGI-1およびARC-AGI-2でのフロンティアAIモデルのパフォーマンス比較。画像提供:Arc Prize ARC-AGI-2の導入は、技術業界の多くの人々がAIの進歩を測定するための新しい、未飽和のベンチマークを求めている時期に起こりました。Hugging Faceの共同設立者トーマス・ウルフは最近、TechCrunchに対し、AI業界には人工知能の重要な特性、例えば創造性を測定する十分なテストが不足していると語りました。新しいベンチマークとともに、アーク賞財団はArc Prize 2025コンテストを発表し、開発者に対してARC-AGI-2テストで85%の精度を達成しながら、タスクごとに0.42ドルしか使わないよう挑戦しました。
関連記事
 AGIは世界共通語のブレークスルーで人類の思考に革命をもたらす
人工知能(Artificial General Intelligence)の出現は、普遍的な言語フレームワークの構築を通じて、人間のコミュニケーションを再構築する変革的な可能性を提示している。特殊なタスクのために設計された狭いAIシステムとは異なり、AGIは複数の領域にわたる人間のような学習能力を持ち、言語パターン、文化的文脈、認知プロセスの分析を可能にする。このユニークな組み合わせは、人間の認知
OpenAIが非営利のルーツを再確認、主要な企業再編の中で
OpenAIは、倫理的なAI開発へのコミットメントと成長のバランスを取りながら、大きな企業再編を進め、非営利のミッションに揺るぎなく取り組んでいます。CEOのサム・アルトマンは、会社のビジョンを概説し、財務戦略が進化している一方で、人工汎用知能(AGI)をグローバルな利益のために進めるOpenAIの献身は変わらないと強調しました。公開声明で、アルトマンは次のように述べました:「OpenAIは従来の
AIリーダーがAGIを議論:現実に基づく
サンフランシスコのビジネスリーダーとの最近の夕食会で、私は一つの質問を投げかけました。それは、現在のAIが人間のような知能、またはそれ以上に達することができるかというもので、場が凍りついたようでした。これは思いのほか多くの議論を呼び起こすトピックです。2025年、テックCEOたちはChatGPTやGeminiの背後にあるような大規模言語モデル(LLM)につい
コメント (36)
0/200
AGIは世界共通語のブレークスルーで人類の思考に革命をもたらす
人工知能(Artificial General Intelligence)の出現は、普遍的な言語フレームワークの構築を通じて、人間のコミュニケーションを再構築する変革的な可能性を提示している。特殊なタスクのために設計された狭いAIシステムとは異なり、AGIは複数の領域にわたる人間のような学習能力を持ち、言語パターン、文化的文脈、認知プロセスの分析を可能にする。このユニークな組み合わせは、人間の認知
OpenAIが非営利のルーツを再確認、主要な企業再編の中で
OpenAIは、倫理的なAI開発へのコミットメントと成長のバランスを取りながら、大きな企業再編を進め、非営利のミッションに揺るぎなく取り組んでいます。CEOのサム・アルトマンは、会社のビジョンを概説し、財務戦略が進化している一方で、人工汎用知能(AGI)をグローバルな利益のために進めるOpenAIの献身は変わらないと強調しました。公開声明で、アルトマンは次のように述べました:「OpenAIは従来の
AIリーダーがAGIを議論:現実に基づく
サンフランシスコのビジネスリーダーとの最近の夕食会で、私は一つの質問を投げかけました。それは、現在のAIが人間のような知能、またはそれ以上に達することができるかというもので、場が凍りついたようでした。これは思いのほか多くの議論を呼び起こすトピックです。2025年、テックCEOたちはChatGPTやGeminiの背後にあるような大規模言語モデル(LLM)につい
コメント (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 2025年7月29日 21:25:16 JST
2025年7月29日 21:25:16 JST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
2025年4月14日 17:35:00 JST
GeorgeMiller
2025年4月14日 17:35:00 JST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
2025年4月14日 10:46:37 JST
JonathanKing
2025年4月14日 10:46:37 JST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
2025年4月14日 4:05:45 JST
DonaldGonzález
2025年4月14日 4:05:45 JST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
2025年4月14日 0:54:39 JST
HaroldMoore
2025年4月14日 0:54:39 JST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
2025年4月14日 0:36:48 JST
GregoryWilson
2025年4月14日 0:36:48 JST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
アーク賞財団は、著名なAI研究者フランソワ・ショレが共同設立者として参加し、最近のブログ投稿でARC-AGI-2という新たなベンチマークを発表しました。このテストはAIの一般知能の限界を押し広げることを目指しており、これまでのところ、ほとんどのAIモデルにとって難題であることが証明されています。
アーク賞のリーダーボードによると、OpenAIのo1-proやDeepSeekのR1のような高度な「推論」AIモデルでさえ、スコアは1%から1.3%の間に留まっています。一方、GPT-4.5、Claude 3.7 Sonnet、Gemini 2.0 Flashといった強力な非推論モデルは、1%前後のスコアにとどまっています。
ARC-AGIテストは、AIシステムに対して異なる色の四角形のグリッドで視覚的パターンを識別し、正しい「答え」のグリッドを生成することを求めるパズルのような問題で挑戦します。これらの問題は、AIが新しい、未見の課題に適応する能力をテストするために設計されています。
人間の基準を確立するため、アーク賞財団は400人以上にARC-AGI-2テストを受けさせました。平均して、これらの「パネル」の人間は60%の成功率を達成し、AIモデルを大きく上回りました。
ショレは、ARC-AGI-2がAIモデルが「力ずく」の計算能力に頼って問題を解決することを防ぐと強調し、最初のテストで認められた欠点を修正しました。これに対処するため、ARC-AGI-2は効率メトリックを導入し、モデルが記憶に頼るのではなく、その場でパターンを解釈することを要求します。
ブログ投稿で、アーク賞財団の共同設立者グレッグ・カムラットは、知能は単に問題を解決したり高スコアを達成することだけではないと強調しました。「それらの能力が取得され、展開される効率は、決定的な重要な要素です」と彼は書いています。「問われている核心的な質問は、『AIがタスクを解決するスキルを獲得できるか?』だけでなく、『どの程度の効率またはコストで?』でもあります」
ARC-AGI-1は約5年間無敗でしたが、2024年12月にOpenAIの高度な推論モデルo3が他のすべてのAIモデルを上回り、人間のパフォーマンスに匹敵しました。しかし、ARC-AGI-1でのo3の成功は大きなコストを伴いました。ARC-AGI-1で75.7%の印象的なスコアを達成したOpenAIのo3モデル(o3 (low))は、ARC-AGI-2ではタスクごとに200ドルの計算能力を使用して、わずか4%しか達成できませんでした。
新しいベンチマークとともに、アーク賞財団はArc Prize 2025コンテストを発表し、開発者に対してARC-AGI-2テストで85%の精度を達成しながら、タスクごとに0.42ドルしか使わないよう挑戦しました。









 AGIは世界共通語のブレークスルーで人類の思考に革命をもたらす
人工知能(Artificial General Intelligence)の出現は、普遍的な言語フレームワークの構築を通じて、人間のコミュニケーションを再構築する変革的な可能性を提示している。特殊なタスクのために設計された狭いAIシステムとは異なり、AGIは複数の領域にわたる人間のような学習能力を持ち、言語パターン、文化的文脈、認知プロセスの分析を可能にする。このユニークな組み合わせは、人間の認知
OpenAIが非営利のルーツを再確認、主要な企業再編の中で
OpenAIは、倫理的なAI開発へのコミットメントと成長のバランスを取りながら、大きな企業再編を進め、非営利のミッションに揺るぎなく取り組んでいます。CEOのサム・アルトマンは、会社のビジョンを概説し、財務戦略が進化している一方で、人工汎用知能(AGI)をグローバルな利益のために進めるOpenAIの献身は変わらないと強調しました。公開声明で、アルトマンは次のように述べました:「OpenAIは従来の
AGIは世界共通語のブレークスルーで人類の思考に革命をもたらす
人工知能(Artificial General Intelligence)の出現は、普遍的な言語フレームワークの構築を通じて、人間のコミュニケーションを再構築する変革的な可能性を提示している。特殊なタスクのために設計された狭いAIシステムとは異なり、AGIは複数の領域にわたる人間のような学習能力を持ち、言語パターン、文化的文脈、認知プロセスの分析を可能にする。このユニークな組み合わせは、人間の認知
OpenAIが非営利のルーツを再確認、主要な企業再編の中で
OpenAIは、倫理的なAI開発へのコミットメントと成長のバランスを取りながら、大きな企業再編を進め、非営利のミッションに揺るぎなく取り組んでいます。CEOのサム・アルトマンは、会社のビジョンを概説し、財務戦略が進化している一方で、人工汎用知能(AGI)をグローバルな利益のために進めるOpenAIの献身は変わらないと強調しました。公開声明で、アルトマンは次のように述べました:「OpenAIは従来の
 AIリーダーがAGIを議論:現実に基づく
サンフランシスコのビジネスリーダーとの最近の夕食会で、私は一つの質問を投げかけました。それは、現在のAIが人間のような知能、またはそれ以上に達することができるかというもので、場が凍りついたようでした。これは思いのほか多くの議論を呼び起こすトピックです。2025年、テックCEOたちはChatGPTやGeminiの背後にあるような大規模言語モデル(LLM)につい
2025年7月29日 21:25:16 JST
AIリーダーがAGIを議論:現実に基づく
サンフランシスコのビジネスリーダーとの最近の夕食会で、私は一つの質問を投げかけました。それは、現在のAIが人間のような知能、またはそれ以上に達することができるかというもので、場が凍りついたようでした。これは思いのほか多くの議論を呼び起こすトピックです。2025年、テックCEOたちはChatGPTやGeminiの背後にあるような大規模言語モデル(LLM)につい
2025年7月29日 21:25:16 JST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
2025年4月14日 17:35:00 JST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
2025年4月14日 10:46:37 JST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
2025年4月14日 4:05:45 JST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
2025年4月14日 0:54:39 JST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
2025年4月14日 0:36:48 JST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













