
















 首頁
首頁新的AGI測試證明了具有挑戰性,大多數AI模型
Arc獎金基金會,由知名AI研究員François Chollet共同創辦,最近在一篇博客文章中公布了一個名為ARC-AGI-2的新基準測試。此測試旨在推動AI通用智能的界限,迄今為止,對大多數AI模型來說,這是一個難以破解的挑戰。
根據Arc獎金排行榜,即使是像OpenAI的o1-pro和DeepSeek的R1這樣的高級「推理」AI模型,也僅能獲得1%至1.3%的分數。與此同時,強大的非推理模型,如GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Flash,也僅在1%左右徘徊。
ARC-AGI測試以類似謎題的問題挑戰AI系統,要求它們在不同顏色的方格網中識別視覺模式,並生成正確的「答案」網格。這些問題旨在測試AI適應全新、未見過的挑戰的能力。
為了建立人類基準,Arc獎金基金會讓超過400人參加了ARC-AGI-2測試。平均而言,這些「測試小組」的人類達到了60%的成功率,顯著超越了AI模型。
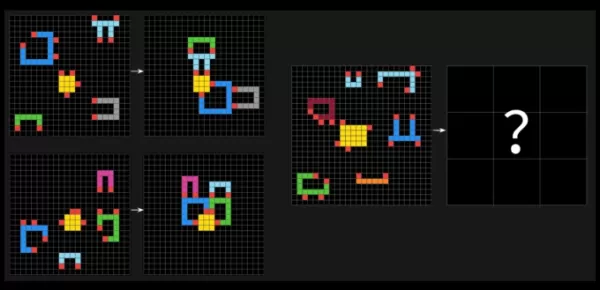
來自ARC-AGI-2的樣本問題。圖片來源:Arc Prize François Chollet在X上表示,與前一代ARC-AGI-1相比,ARC-AGI-2是衡量AI模型真實智能的更精確指標。Arc獎金基金會的測試旨在評估AI是否能高效學習超出其訓練數據的新技能。Chollet強調,ARC-AGI-2防止AI模型依賴「暴力計算」來解決問題,這是他承認的第一個測試中的缺陷。為了解決這一問題,ARC-AGI-2引入了效率指標,並要求模型即時解讀模式,而不是依賴記憶。
在博客文章中,Arc獎金基金會共同創辦人Greg Kamradt強調,智能不僅僅是解決問題或獲得高分。他寫道:「這些能力的獲取和部署效率是一個關鍵的定義性組成部分。」「核心問題不僅是『AI能否獲得解決任務的技能?』,還有『以何種效率或成本?』」
ARC-AGI-1在約五年內未被打破,直到2024年12月,OpenAI的高級推理模型o3超越了所有其他AI模型,並達到了人類的表現。然而,o3在ARC-AGI-1上的成功付出了顯著的代價。OpenAI的o3模型版本o3 (low),在ARC-AGI-1上獲得了令人印象深刻的75.7%分數,但在ARC-AGI-2上僅獲得4%,每項任務使用了價值200美元的計算能力。

前沿AI模型在ARC-AGI-1和ARC-AGI-2上的性能比較。圖片來源:Arc Prize ARC-AGI-2的推出正值科技行業許多人呼籲新的、未飽和的基準來衡量AI進展之際。Hugging Face的共同創辦人Thomas Wolf最近對TechCrunch表示,AI行業缺乏足夠的測試來衡量人工通用智能的關鍵特徵,如創造力。隨著新基準的推出,Arc獎金基金會宣布了2025年Arc獎金競賽,挑戰開發者在ARC-AGI-2測試中實現85%的準確率,同時每項任務僅花費0.42美元。
相關文章
 OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
Databricks 共同創辦人榮獲 ACM 獎項後,宣稱通用人工智慧即將問世
Databricks 共同創辦人暨技術長 Matei Zaharia 差點錯過那封通知他獲得 2026 年 ACM 計算獎的電子郵件。「這確實是個驚喜,」他向 TechCrunch 透露。2009年,扎哈里亞在加州大學柏克萊分校攻讀博士期間,在著名教授伊昂·斯托伊卡(Ion Stoica)的指導下所開發的技術,被整合進 Databricks。扎哈里亞設計了一種方法,能大幅加速處理那些緩慢且繁瑣的大
OpenAI執行長山姆·阿特曼宣告超級智能時代的來臨
OpenAI執行長山姆·奧特曼宣佈,人類已邁入人工超級智慧時代,且此進程不可逆轉。「我們已跨越無法回頭的臨界點,升華之路正式展開,」奧特曼表示:「人類正站在創造數位超級智能的門檻上,而迄今為止,這過程竟比想像中更為尋常。」儘管缺乏明顯跡象——街頭尚未遍布機器人,疾病仍未絕跡——但奧特曼所描述的深刻變革已悄然啟動。在諸如其公司等機構中,正研發出能超越人類通用智能的系統。「從重要層面而言,ChatGP
相關專題推薦
漫畫創作
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
Databricks 共同創辦人榮獲 ACM 獎項後,宣稱通用人工智慧即將問世
Databricks 共同創辦人暨技術長 Matei Zaharia 差點錯過那封通知他獲得 2026 年 ACM 計算獎的電子郵件。「這確實是個驚喜,」他向 TechCrunch 透露。2009年,扎哈里亞在加州大學柏克萊分校攻讀博士期間,在著名教授伊昂·斯托伊卡(Ion Stoica)的指導下所開發的技術,被整合進 Databricks。扎哈里亞設計了一種方法,能大幅加速處理那些緩慢且繁瑣的大
OpenAI執行長山姆·阿特曼宣告超級智能時代的來臨
OpenAI執行長山姆·奧特曼宣佈,人類已邁入人工超級智慧時代,且此進程不可逆轉。「我們已跨越無法回頭的臨界點,升華之路正式展開,」奧特曼表示:「人類正站在創造數位超級智能的門檻上,而迄今為止,這過程竟比想像中更為尋常。」儘管缺乏明顯跡象——街頭尚未遍布機器人,疾病仍未絕跡——但奧特曼所描述的深刻變革已悄然啟動。在諸如其公司等機構中,正研發出能超越人類通用智能的系統。「從重要層面而言,ChatGP
相關專題推薦
漫畫創作
 少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
 15 個工具
15 個工具
 xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

 評論 (39)
0/500
評論 (39)
0/500
![DonaldSanchez]()
이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
![MarkRoberts]()
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
![RonaldRoberts]()
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
![WillieRoberts]()
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
![GeorgeMiller]()
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
![JonathanKing]()
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
Arc獎金基金會,由知名AI研究員François Chollet共同創辦,最近在一篇博客文章中公布了一個名為ARC-AGI-2的新基準測試。此測試旨在推動AI通用智能的界限,迄今為止,對大多數AI模型來說,這是一個難以破解的挑戰。
根據Arc獎金排行榜,即使是像OpenAI的o1-pro和DeepSeek的R1這樣的高級「推理」AI模型,也僅能獲得1%至1.3%的分數。與此同時,強大的非推理模型,如GPT-4.5、Claude 3.7 Sonnet和Gemini 2.0 Flash,也僅在1%左右徘徊。
ARC-AGI測試以類似謎題的問題挑戰AI系統,要求它們在不同顏色的方格網中識別視覺模式,並生成正確的「答案」網格。這些問題旨在測試AI適應全新、未見過的挑戰的能力。
為了建立人類基準,Arc獎金基金會讓超過400人參加了ARC-AGI-2測試。平均而言,這些「測試小組」的人類達到了60%的成功率,顯著超越了AI模型。
Chollet強調,ARC-AGI-2防止AI模型依賴「暴力計算」來解決問題,這是他承認的第一個測試中的缺陷。為了解決這一問題,ARC-AGI-2引入了效率指標,並要求模型即時解讀模式,而不是依賴記憶。
在博客文章中,Arc獎金基金會共同創辦人Greg Kamradt強調,智能不僅僅是解決問題或獲得高分。他寫道:「這些能力的獲取和部署效率是一個關鍵的定義性組成部分。」「核心問題不僅是『AI能否獲得解決任務的技能?』,還有『以何種效率或成本?』」
ARC-AGI-1在約五年內未被打破,直到2024年12月,OpenAI的高級推理模型o3超越了所有其他AI模型,並達到了人類的表現。然而,o3在ARC-AGI-1上的成功付出了顯著的代價。OpenAI的o3模型版本o3 (low),在ARC-AGI-1上獲得了令人印象深刻的75.7%分數,但在ARC-AGI-2上僅獲得4%,每項任務使用了價值200美元的計算能力。
隨著新基準的推出,Arc獎金基金會宣布了2025年Arc獎金競賽,挑戰開發者在ARC-AGI-2測試中實現85%的準確率,同時每項任務僅花費0.42美元。










 OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
 Databricks 共同創辦人榮獲 ACM 獎項後,宣稱通用人工智慧即將問世
Databricks 共同創辦人暨技術長 Matei Zaharia 差點錯過那封通知他獲得 2026 年 ACM 計算獎的電子郵件。「這確實是個驚喜,」他向 TechCrunch 透露。2009年,扎哈里亞在加州大學柏克萊分校攻讀博士期間,在著名教授伊昂·斯托伊卡(Ion Stoica)的指導下所開發的技術,被整合進 Databricks。扎哈里亞設計了一種方法,能大幅加速處理那些緩慢且繁瑣的大
OpenAI執行長山姆·阿特曼宣告超級智能時代的來臨
OpenAI執行長山姆·奧特曼宣佈,人類已邁入人工超級智慧時代,且此進程不可逆轉。「我們已跨越無法回頭的臨界點,升華之路正式展開,」奧特曼表示:「人類正站在創造數位超級智能的門檻上,而迄今為止,這過程竟比想像中更為尋常。」儘管缺乏明顯跡象——街頭尚未遍布機器人,疾病仍未絕跡——但奧特曼所描述的深刻變革已悄然啟動。在諸如其公司等機構中,正研發出能超越人類通用智能的系統。「從重要層面而言,ChatGP
Databricks 共同創辦人榮獲 ACM 獎項後,宣稱通用人工智慧即將問世
Databricks 共同創辦人暨技術長 Matei Zaharia 差點錯過那封通知他獲得 2026 年 ACM 計算獎的電子郵件。「這確實是個驚喜,」他向 TechCrunch 透露。2009年,扎哈里亞在加州大學柏克萊分校攻讀博士期間,在著名教授伊昂·斯托伊卡(Ion Stoica)的指導下所開發的技術,被整合進 Databricks。扎哈里亞設計了一種方法,能大幅加速處理那些緩慢且繁瑣的大
OpenAI執行長山姆·阿特曼宣告超級智能時代的來臨
OpenAI執行長山姆·奧特曼宣佈,人類已邁入人工超級智慧時代,且此進程不可逆轉。「我們已跨越無法回頭的臨界點,升華之路正式展開,」奧特曼表示:「人類正站在創造數位超級智能的門檻上,而迄今為止,這過程竟比想像中更為尋常。」儘管缺乏明顯跡象——街頭尚未遍布機器人,疾病仍未絕跡——但奧特曼所描述的深刻變革已悄然啟動。在諸如其公司等機構中,正研發出能超越人類通用智能的系統。「從重要層面而言,ChatGP

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

이 새로운 벤치마크, 진짜 어렵네요. 🤯 요새 AI가 다들 잘하는 줄 알았는데 ARC-AGI-2에서 고전 중이라는 소식에 좀 놀랐어요. François Chollet가 만든거라니... 어쩌면 지능의 본질에 더 가까운 테스트일지도? 정말 일반 지능을 측정할 수 있을까 궁금해집니다. 논문 나오면 좀 더 알아봐야겠어요.
¿Un test que la mayoría de las IA no superan? Esto demuestra lo lejos que estamos de la AGI real. Me pregunto si estos benchmarks realmente miden la 'inteligencia' o solo la capacidad de resolver puzzles específicos. 🧩 Parece más un juego para investigadores que un avance práctico.
Новый тест ARC-AGI-2 выглядит как серьёзный вызов для ИИ! 😅 Интересно, насколько близко мы подошли к настоящему общему интеллекту, если даже продвинутые модели справляются с трудом. Может, ключ в комбинации логики и творческого подхода?
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?













