




Новый тест AGI оказывается сложным, пензирует большинство моделей искусственного интеллекта
Фонд Arc Prize, соучредителем которого является известный исследователь ИИ Франсуа Шолле, недавно представил новый тест под названием ARC-AGI-2 в публикации в блоге. Этот тест направлен на расширение границ общего интеллекта ИИ, и пока он оказывается сложной задачей для большинства моделей ИИ.
Согласно таблице лидеров Arc Prize, даже продвинутые модели ИИ с функцией "рассуждения", такие как o1-pro от OpenAI и R1 от DeepSeek, достигают результатов лишь в диапазоне от 1% до 1.3%. В то же время мощные модели без функции рассуждений, такие как GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, показывают результаты около 1%.
Тесты ARC-AGI бросают вызов системам ИИ с задачами-головоломками, требующими определения визуальных узоров в сетках из разноцветных квадратов и создания правильной "ответной" сетки. Эти задачи разработаны для проверки способности ИИ адаптироваться к новым, ранее не виданным вызовам.
Для установления человеческого базового уровня Фонд Arc Prize привлек более 400 человек к прохождению теста ARC-AGI-2. В среднем эти "панели" людей достигли 60% успеха, значительно опережая модели ИИ.
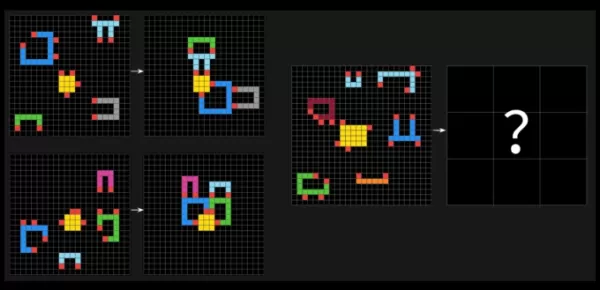
Пример вопроса из ARC-AGI-2. Источник изображения: Arc Prize Франсуа Шолле заявил на X, что ARC-AGI-2 является более точной мерой истинного интеллекта модели ИИ по сравнению с его предшественником, ARC-AGI-1. Тесты Фонда Arc Prize разработаны для оценки способности ИИ эффективно обучаться новым навыкам за пределами обучающих данных.Шолле подчеркнул, что ARC-AGI-2 предотвращает использование моделями ИИ "грубой силы" вычислительной мощности для решения задач, что было недостатком первого теста. Для этого ARC-AGI-2 вводит метрику эффективности и требует от моделей интерпретации узоров на лету, а не полагаться на запоминание.
В публикации в блоге соучредитель Фонда Arc Prize Грег Камрадт подчеркнул, что интеллект — это не только решение задач или достижение высоких результатов. "Эффективность, с которой эти способности приобретаются и применяются, является решающим, определяющим компонентом," — написал он. "Основной вопрос заключается не только в том, 'Может ли ИИ приобрести навык для решения задачи?', но и 'С какой эффективностью или стоимостью?'"
ARC-AGI-1 оставался непревзойденным около пяти лет до декабря 2024 года, когда продвинутая модель рассуждений OpenAI, o3, превзошла все другие модели ИИ и сравнялась с человеческими результатами. Однако успех o3 на ARC-AGI-1 обошелся дорого. Версия модели OpenAI o3 (low), которая набрала впечатляющие 75.7% на ARC-AGI-1, показала лишь 4% на ARC-AGI-2, используя вычислительную мощность стоимостью 200 долларов на задачу.

Сравнение производительности передовых моделей ИИ на ARC-AGI-1 и ARC-AGI-2. Источник изображения: Arc Prize Введение ARC-AGI-2 происходит в момент, когда многие в технологической индустрии призывают к новым, ненасыщенным тестам для измерения прогресса ИИ. Томас Вольф, соучредитель Hugging Face, недавно сообщил TechCrunch, что индустрии ИИ не хватает достаточных тестов для измерения ключевых черт искусственного общего интеллекта, таких как креативность.Наряду с новым тестом Фонд Arc Prize объявил о конкурсе Arc Prize 2025, побуждая разработчиков достичь 85% точности на тесте ARC-AGI-2, тратя при этом всего 0.42 доллара на задачу.
Связанная статья
 AGI совершит революцию в человеческом мышлении благодаря прорыву в области универсального языка
Появление искусственного интеллекта общего назначения несет в себе трансформационный потенциал для изменения человеческой коммуникации путем создания универсальной языковой базы. В отличие от узкоспец
OpenAI подтверждает свои некоммерческие корни в ходе масштабной корпоративной реструктуризации
OpenAI остается верной своей некоммерческой миссии, проходя через значительную корпоративную реструктуризацию, балансируя между ростом и приверженностью этичному развитию ИИ.Генеральный директор Сэм А
Лидеры ИИ основывают дискуссию об AGI на реальности
На недавнем ужине с бизнес-лидерами в Сан-Франциско я задал вопрос, который, казалось, заставил всех замолчать: сможет ли сегодняшний ИИ когда-нибудь достичь уровня человеческого и
Комментарии (36)
AGI совершит революцию в человеческом мышлении благодаря прорыву в области универсального языка
Появление искусственного интеллекта общего назначения несет в себе трансформационный потенциал для изменения человеческой коммуникации путем создания универсальной языковой базы. В отличие от узкоспец
OpenAI подтверждает свои некоммерческие корни в ходе масштабной корпоративной реструктуризации
OpenAI остается верной своей некоммерческой миссии, проходя через значительную корпоративную реструктуризацию, балансируя между ростом и приверженностью этичному развитию ИИ.Генеральный директор Сэм А
Лидеры ИИ основывают дискуссию об AGI на реальности
На недавнем ужине с бизнес-лидерами в Сан-Франциско я задал вопрос, который, казалось, заставил всех замолчать: сможет ли сегодняшний ИИ когда-нибудь достичь уровня человеческого и
Комментарии (36)
![WillieRoberts]() WillieRoberts
WillieRoberts
 29 июля 2025 г., 15:25:16 GMT+03:00
29 июля 2025 г., 15:25:16 GMT+03:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14 апреля 2025 г., 11:35:00 GMT+03:00
GeorgeMiller
14 апреля 2025 г., 11:35:00 GMT+03:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14 апреля 2025 г., 4:46:37 GMT+03:00
JonathanKing
14 апреля 2025 г., 4:46:37 GMT+03:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
13 апреля 2025 г., 22:05:45 GMT+03:00
DonaldGonzález
13 апреля 2025 г., 22:05:45 GMT+03:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13 апреля 2025 г., 18:54:39 GMT+03:00
HaroldMoore
13 апреля 2025 г., 18:54:39 GMT+03:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13 апреля 2025 г., 18:36:48 GMT+03:00
GregoryWilson
13 апреля 2025 г., 18:36:48 GMT+03:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
Фонд Arc Prize, соучредителем которого является известный исследователь ИИ Франсуа Шолле, недавно представил новый тест под названием ARC-AGI-2 в публикации в блоге. Этот тест направлен на расширение границ общего интеллекта ИИ, и пока он оказывается сложной задачей для большинства моделей ИИ.
Согласно таблице лидеров Arc Prize, даже продвинутые модели ИИ с функцией "рассуждения", такие как o1-pro от OpenAI и R1 от DeepSeek, достигают результатов лишь в диапазоне от 1% до 1.3%. В то же время мощные модели без функции рассуждений, такие как GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, показывают результаты около 1%.
Тесты ARC-AGI бросают вызов системам ИИ с задачами-головоломками, требующими определения визуальных узоров в сетках из разноцветных квадратов и создания правильной "ответной" сетки. Эти задачи разработаны для проверки способности ИИ адаптироваться к новым, ранее не виданным вызовам.
Для установления человеческого базового уровня Фонд Arc Prize привлек более 400 человек к прохождению теста ARC-AGI-2. В среднем эти "панели" людей достигли 60% успеха, значительно опережая модели ИИ.
Шолле подчеркнул, что ARC-AGI-2 предотвращает использование моделями ИИ "грубой силы" вычислительной мощности для решения задач, что было недостатком первого теста. Для этого ARC-AGI-2 вводит метрику эффективности и требует от моделей интерпретации узоров на лету, а не полагаться на запоминание.
В публикации в блоге соучредитель Фонда Arc Prize Грег Камрадт подчеркнул, что интеллект — это не только решение задач или достижение высоких результатов. "Эффективность, с которой эти способности приобретаются и применяются, является решающим, определяющим компонентом," — написал он. "Основной вопрос заключается не только в том, 'Может ли ИИ приобрести навык для решения задачи?', но и 'С какой эффективностью или стоимостью?'"
ARC-AGI-1 оставался непревзойденным около пяти лет до декабря 2024 года, когда продвинутая модель рассуждений OpenAI, o3, превзошла все другие модели ИИ и сравнялась с человеческими результатами. Однако успех o3 на ARC-AGI-1 обошелся дорого. Версия модели OpenAI o3 (low), которая набрала впечатляющие 75.7% на ARC-AGI-1, показала лишь 4% на ARC-AGI-2, используя вычислительную мощность стоимостью 200 долларов на задачу.
Наряду с новым тестом Фонд Arc Prize объявил о конкурсе Arc Prize 2025, побуждая разработчиков достичь 85% точности на тесте ARC-AGI-2, тратя при этом всего 0.42 доллара на задачу.









 AGI совершит революцию в человеческом мышлении благодаря прорыву в области универсального языка
Появление искусственного интеллекта общего назначения несет в себе трансформационный потенциал для изменения человеческой коммуникации путем создания универсальной языковой базы. В отличие от узкоспец
OpenAI подтверждает свои некоммерческие корни в ходе масштабной корпоративной реструктуризации
OpenAI остается верной своей некоммерческой миссии, проходя через значительную корпоративную реструктуризацию, балансируя между ростом и приверженностью этичному развитию ИИ.Генеральный директор Сэм А
AGI совершит революцию в человеческом мышлении благодаря прорыву в области универсального языка
Появление искусственного интеллекта общего назначения несет в себе трансформационный потенциал для изменения человеческой коммуникации путем создания универсальной языковой базы. В отличие от узкоспец
OpenAI подтверждает свои некоммерческие корни в ходе масштабной корпоративной реструктуризации
OpenAI остается верной своей некоммерческой миссии, проходя через значительную корпоративную реструктуризацию, балансируя между ростом и приверженностью этичному развитию ИИ.Генеральный директор Сэм А
 Лидеры ИИ основывают дискуссию об AGI на реальности
На недавнем ужине с бизнес-лидерами в Сан-Франциско я задал вопрос, который, казалось, заставил всех замолчать: сможет ли сегодняшний ИИ когда-нибудь достичь уровня человеческого и
29 июля 2025 г., 15:25:16 GMT+03:00
Лидеры ИИ основывают дискуссию об AGI на реальности
На недавнем ужине с бизнес-лидерами в Сан-Франциско я задал вопрос, который, казалось, заставил всех замолчать: сможет ли сегодняшний ИИ когда-нибудь достичь уровня человеческого и
29 июля 2025 г., 15:25:16 GMT+03:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14 апреля 2025 г., 11:35:00 GMT+03:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14 апреля 2025 г., 4:46:37 GMT+03:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
13 апреля 2025 г., 22:05:45 GMT+03:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13 апреля 2025 г., 18:54:39 GMT+03:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13 апреля 2025 г., 18:36:48 GMT+03:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













