




Novos testes da AGI prova desafiadores, toca a maioria dos modelos de IA
A Fundação Arc Prize, co-fundada pelo renomado pesquisador de IA François Chollet, revelou recentemente um novo benchmark chamado ARC-AGI-2 em um post de blog. Este teste visa expandir os limites da inteligência geral de IA, e até agora, está se mostrando um desafio difícil para a maioria dos modelos de IA.
De acordo com o ranking da Arc Prize, até mesmo modelos avançados de IA de "raciocínio" como o o1-pro da OpenAI e o R1 da DeepSeek estão obtendo pontuações entre 1% e 1,3%. Enquanto isso, modelos poderosos sem raciocínio, como GPT-4.5, Claude 3.7 Sonnet e Gemini 2.0 Flash, estão na faixa de 1%.
Os testes ARC-AGI desafiam sistemas de IA com problemas semelhantes a quebra-cabeças, exigindo que identifiquem padrões visuais em grades de quadrados coloridos e gerem a grade "resposta" correta. Esses problemas são projetados para testar a capacidade de uma IA de se adaptar a novos desafios nunca vistos.
Para estabelecer uma linha de base humana, a Fundação Arc Prize fez com que mais de 400 pessoas realizassem o teste ARC-AGI-2. Em média, esses "painéis" de humanos alcançaram uma taxa de sucesso de 60%, superando significativamente os modelos de IA.
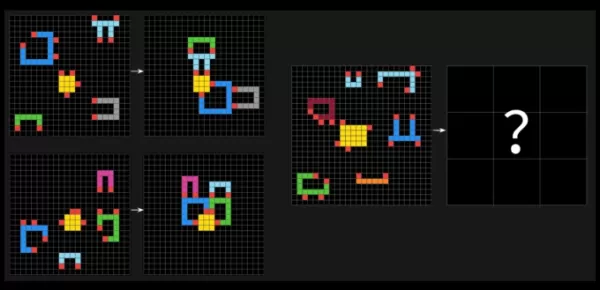
Uma questão de exemplo do ARC-AGI-2. Créditos da imagem: Arc Prize François Chollet foi ao X afirmar que o ARC-AGI-2 é uma medida mais precisa da verdadeira inteligência de um modelo de IA em comparação com seu antecessor, ARC-AGI-1. Os testes da Fundação Arc Prize são projetados para avaliar se uma IA pode aprender novas habilidades de forma eficiente além de seus dados de treinamento.Chollet enfatizou que o ARC-AGI-2 impede que os modelos de IA dependam de poder computacional de "força bruta" para resolver problemas, uma falha que ele reconheceu no primeiro teste. Para abordar isso, o ARC-AGI-2 introduz uma métrica de eficiência e exige que os modelos interpretem padrões no momento, em vez de dependerem de memorização.
Em um post de blog, o co-fundador da Fundação Arc Prize, Greg Kamradt, destacou que a inteligência não se trata apenas de resolver problemas ou alcançar altas pontuações. "A eficiência com que essas capacidades são adquiridas e implementadas é um componente crucial e definidor", ele escreveu. "A questão central não é apenas, 'A IA pode adquirir a habilidade para resolver uma tarefa?', mas também, 'Com que eficiência ou custo?'"
O ARC-AGI-1 permaneceu imbatível por cerca de cinco anos até dezembro de 2024, quando o modelo avançado de raciocínio da OpenAI, o3, superou todos os outros modelos de IA e igualou o desempenho humano. No entanto, o sucesso do o3 no ARC-AGI-1 teve um custo significativo. A versão do modelo o3 da OpenAI, o3 (low), que obteve impressionantes 75,7% no ARC-AGI-1, conseguiu apenas 4% no ARC-AGI-2, usando $200 de poder computacional por tarefa.

Comparação do desempenho de modelos de IA de ponta no ARC-AGI-1 e ARC-AGI-2. Créditos da imagem: Arc Prize A introdução do ARC-AGI-2 ocorre em um momento em que muitos na indústria de tecnologia estão pedindo novos benchmarks não saturados para medir o progresso da IA. Thomas Wolf, co-fundador da Hugging Face, disse recentemente à TechCrunch que a indústria de IA carece de testes suficientes para medir características-chave da inteligência geral artificial, como a criatividade.Junto com o novo benchmark, a Fundação Arc Prize anunciou o concurso Arc Prize 2025, desafiando desenvolvedores a alcançar 85% de precisão no teste ARC-AGI-2 gastando apenas $0,42 por tarefa.
Artigo relacionado
 A AGI está pronta para revolucionar o pensamento humano com um avanço na linguagem universal
O surgimento da Inteligência Artificial Geral apresenta um potencial transformador para remodelar a comunicação humana por meio da criação de uma estrutura de linguagem universal. Diferentemente dos s
OpenAI Reafirma Raízes Sem Fins Lucrativos em Grande Reestruturação Corporativa
OpenAI permanece firme em sua missão sem fins lucrativos enquanto passa por uma reestruturação corporativa significativa, equilibrando crescimento com seu compromisso com o desenvolvimento ético de IA
Líderes de IA Discutem AGI: Baseados na Realidade
Durante um recente jantar com líderes empresariais em San Francisco, lancei uma pergunta que pareceu congelar o ambiente: será que a IA de hoje poderia alcançar ou até superar a in
Comentários (36)
0/200
A AGI está pronta para revolucionar o pensamento humano com um avanço na linguagem universal
O surgimento da Inteligência Artificial Geral apresenta um potencial transformador para remodelar a comunicação humana por meio da criação de uma estrutura de linguagem universal. Diferentemente dos s
OpenAI Reafirma Raízes Sem Fins Lucrativos em Grande Reestruturação Corporativa
OpenAI permanece firme em sua missão sem fins lucrativos enquanto passa por uma reestruturação corporativa significativa, equilibrando crescimento com seu compromisso com o desenvolvimento ético de IA
Líderes de IA Discutem AGI: Baseados na Realidade
Durante um recente jantar com líderes empresariais em San Francisco, lancei uma pergunta que pareceu congelar o ambiente: será que a IA de hoje poderia alcançar ou até superar a in
Comentários (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 29 de Julho de 2025 à16 13:25:16 WEST
29 de Julho de 2025 à16 13:25:16 WEST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14 de Abril de 2025 à0 09:35:00 WEST
GeorgeMiller
14 de Abril de 2025 à0 09:35:00 WEST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14 de Abril de 2025 à37 02:46:37 WEST
JonathanKing
14 de Abril de 2025 à37 02:46:37 WEST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
13 de Abril de 2025 à45 20:05:45 WEST
DonaldGonzález
13 de Abril de 2025 à45 20:05:45 WEST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13 de Abril de 2025 à39 16:54:39 WEST
HaroldMoore
13 de Abril de 2025 à39 16:54:39 WEST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13 de Abril de 2025 à48 16:36:48 WEST
GregoryWilson
13 de Abril de 2025 à48 16:36:48 WEST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
A Fundação Arc Prize, co-fundada pelo renomado pesquisador de IA François Chollet, revelou recentemente um novo benchmark chamado ARC-AGI-2 em um post de blog. Este teste visa expandir os limites da inteligência geral de IA, e até agora, está se mostrando um desafio difícil para a maioria dos modelos de IA.
De acordo com o ranking da Arc Prize, até mesmo modelos avançados de IA de "raciocínio" como o o1-pro da OpenAI e o R1 da DeepSeek estão obtendo pontuações entre 1% e 1,3%. Enquanto isso, modelos poderosos sem raciocínio, como GPT-4.5, Claude 3.7 Sonnet e Gemini 2.0 Flash, estão na faixa de 1%.
Os testes ARC-AGI desafiam sistemas de IA com problemas semelhantes a quebra-cabeças, exigindo que identifiquem padrões visuais em grades de quadrados coloridos e gerem a grade "resposta" correta. Esses problemas são projetados para testar a capacidade de uma IA de se adaptar a novos desafios nunca vistos.
Para estabelecer uma linha de base humana, a Fundação Arc Prize fez com que mais de 400 pessoas realizassem o teste ARC-AGI-2. Em média, esses "painéis" de humanos alcançaram uma taxa de sucesso de 60%, superando significativamente os modelos de IA.
Chollet enfatizou que o ARC-AGI-2 impede que os modelos de IA dependam de poder computacional de "força bruta" para resolver problemas, uma falha que ele reconheceu no primeiro teste. Para abordar isso, o ARC-AGI-2 introduz uma métrica de eficiência e exige que os modelos interpretem padrões no momento, em vez de dependerem de memorização.
Em um post de blog, o co-fundador da Fundação Arc Prize, Greg Kamradt, destacou que a inteligência não se trata apenas de resolver problemas ou alcançar altas pontuações. "A eficiência com que essas capacidades são adquiridas e implementadas é um componente crucial e definidor", ele escreveu. "A questão central não é apenas, 'A IA pode adquirir a habilidade para resolver uma tarefa?', mas também, 'Com que eficiência ou custo?'"
O ARC-AGI-1 permaneceu imbatível por cerca de cinco anos até dezembro de 2024, quando o modelo avançado de raciocínio da OpenAI, o3, superou todos os outros modelos de IA e igualou o desempenho humano. No entanto, o sucesso do o3 no ARC-AGI-1 teve um custo significativo. A versão do modelo o3 da OpenAI, o3 (low), que obteve impressionantes 75,7% no ARC-AGI-1, conseguiu apenas 4% no ARC-AGI-2, usando $200 de poder computacional por tarefa.
Junto com o novo benchmark, a Fundação Arc Prize anunciou o concurso Arc Prize 2025, desafiando desenvolvedores a alcançar 85% de precisão no teste ARC-AGI-2 gastando apenas $0,42 por tarefa.









 A AGI está pronta para revolucionar o pensamento humano com um avanço na linguagem universal
O surgimento da Inteligência Artificial Geral apresenta um potencial transformador para remodelar a comunicação humana por meio da criação de uma estrutura de linguagem universal. Diferentemente dos s
OpenAI Reafirma Raízes Sem Fins Lucrativos em Grande Reestruturação Corporativa
OpenAI permanece firme em sua missão sem fins lucrativos enquanto passa por uma reestruturação corporativa significativa, equilibrando crescimento com seu compromisso com o desenvolvimento ético de IA
A AGI está pronta para revolucionar o pensamento humano com um avanço na linguagem universal
O surgimento da Inteligência Artificial Geral apresenta um potencial transformador para remodelar a comunicação humana por meio da criação de uma estrutura de linguagem universal. Diferentemente dos s
OpenAI Reafirma Raízes Sem Fins Lucrativos em Grande Reestruturação Corporativa
OpenAI permanece firme em sua missão sem fins lucrativos enquanto passa por uma reestruturação corporativa significativa, equilibrando crescimento com seu compromisso com o desenvolvimento ético de IA
 Líderes de IA Discutem AGI: Baseados na Realidade
Durante um recente jantar com líderes empresariais em San Francisco, lancei uma pergunta que pareceu congelar o ambiente: será que a IA de hoje poderia alcançar ou até superar a in
29 de Julho de 2025 à16 13:25:16 WEST
Líderes de IA Discutem AGI: Baseados na Realidade
Durante um recente jantar com líderes empresariais em San Francisco, lancei uma pergunta que pareceu congelar o ambiente: será que a IA de hoje poderia alcançar ou até superar a in
29 de Julho de 2025 à16 13:25:16 WEST
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14 de Abril de 2025 à0 09:35:00 WEST
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14 de Abril de 2025 à37 02:46:37 WEST
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
13 de Abril de 2025 à45 20:05:45 WEST
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13 de Abril de 2025 à39 16:54:39 WEST
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13 de Abril de 2025 à48 16:36:48 WEST
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













