




La nueva prueba AGI demuestra que los modelos de IA desafiantes y desafiantes
La Fundación Arc Prize, cofundada por el reconocido investigador de IA François Chollet, presentó recientemente un nuevo estándar llamado ARC-AGI-2 en una publicación de blog. Esta prueba busca ampliar los límites de la inteligencia general de la IA, y hasta ahora, está resultando ser un desafío difícil de superar para la mayoría de los modelos de IA.
Según la tabla de clasificación de Arc Prize, incluso los modelos avanzados de IA de "razonamiento" como o1-pro de OpenAI y R1 de DeepSeek solo logran puntajes entre el 1% y el 1.3%. Mientras tanto, modelos potentes sin razonamiento como GPT-4.5, Claude 3.7 Sonnet y Gemini 2.0 Flash están rondando la marca del 1%.
Las pruebas ARC-AGI desafían a los sistemas de IA con problemas similares a rompecabezas, requiriendo que identifiquen patrones visuales en cuadrículas de cuadrados de diferentes colores y generen la cuadrícula de "respuesta" correcta. Estos problemas están diseñados para evaluar la capacidad de una IA para adaptarse a nuevos desafíos no vistos.
Para establecer una línea base humana, la Fundación Arc Prize hizo que más de 400 personas realizaran la prueba ARC-AGI-2. En promedio, estos "paneles" de humanos lograron una tasa de éxito del 60%, superando significativamente a los modelos de IA.
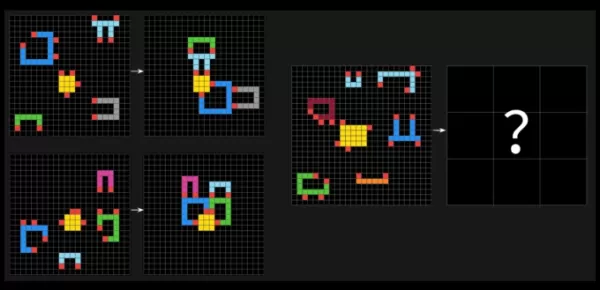
Una pregunta de muestra de ARC-AGI-2. Créditos de la imagen: Arc Prize François Chollet acudió a X para afirmar que ARC-AGI-2 es una medida más precisa de la verdadera inteligencia de un modelo de IA en comparación con su predecesor, ARC-AGI-1. Las pruebas de la Fundación Arc Prize están diseñadas para evaluar si una IA puede aprender eficientemente nuevas habilidades más allá de sus datos de entrenamiento.Chollet enfatizó que ARC-AGI-2 evita que los modelos de IA dependan de la potencia de cálculo de "fuerza bruta" para resolver problemas, un defecto que reconoció en la primera prueba. Para abordar esto, ARC-AGI-2 introduce una métrica de eficiencia y requiere que los modelos interpreten patrones sobre la marcha en lugar de depender de la memorización.
En una publicación de blog, el cofundador de la Fundación Arc Prize, Greg Kamradt, destacó que la inteligencia no se trata solo de resolver problemas o lograr puntajes altos. "La eficiencia con la que se adquieren y despliegan esas capacidades es un componente crucial y definitorio", escribió. "La pregunta central que se plantea no es solo, '¿Puede la IA adquirir la habilidad para resolver una tarea?', sino también, '¿Con qué eficiencia o costo?'"
ARC-AGI-1 permaneció imbatido durante aproximadamente cinco años hasta diciembre de 2024, cuando el modelo avanzado de razonamiento de OpenAI, o3, superó a todos los demás modelos de IA y igualó el rendimiento humano. Sin embargo, el éxito de o3 en ARC-AGI-1 tuvo un costo significativo. La versión del modelo o3 de OpenAI, o3 (bajo), que obtuvo un impresionante 75.7% en ARC-AGI-1, solo logró un escaso 4% en ARC-AGI-2, utilizando $200 de potencia de cálculo por tarea.

Comparación del rendimiento de modelos de IA de vanguardia en ARC-AGI-1 y ARC-AGI-2. Créditos de la imagen: Arc Prize La introducción de ARC-AGI-2 llega en un momento en que muchos en la industria tecnológica están pidiendo nuevos puntos de referencia no saturados para medir el progreso de la IA. Thomas Wolf, cofundador de Hugging Face, recientemente le dijo a TechCrunch que la industria de la IA carece de pruebas suficientes para medir rasgos clave de la inteligencia general artificial, como la creatividad.Junto con el nuevo estándar, la Fundación Arc Prize anunció el concurso Arc Prize 2025, desafiando a los desarrolladores a lograr una precisión del 85% en la prueba ARC-AGI-2 mientras gastan solo $0.42 por tarea.
Artículo relacionado
 La inteligencia artificial revolucionará el pensamiento humano con un avance en el lenguaje universal
La aparición de la Inteligencia Artificial General presenta un potencial transformador para remodelar la comunicación humana mediante la creación de un marco lingüístico universal. A diferencia de los
OpenAI Reafirma sus Raíces Sin Fines de Lucro en una Gran Reestructuración Corporativa
OpenAI permanece firme en su misión sin fines de lucro mientras atraviesa una reestructuración corporativa significativa, equilibrando el crecimiento con su compromiso con el desarrollo ético de la IA
Líderes de IA Discuten AGI: Fundamentado en la Realidad
En una reciente cena con líderes empresariales en San Francisco, lancé una pregunta que pareció congelar la sala: ¿podría la IA actual alcanzar alguna vez una inteligencia similar
comentario (36)
0/200
La inteligencia artificial revolucionará el pensamiento humano con un avance en el lenguaje universal
La aparición de la Inteligencia Artificial General presenta un potencial transformador para remodelar la comunicación humana mediante la creación de un marco lingüístico universal. A diferencia de los
OpenAI Reafirma sus Raíces Sin Fines de Lucro en una Gran Reestructuración Corporativa
OpenAI permanece firme en su misión sin fines de lucro mientras atraviesa una reestructuración corporativa significativa, equilibrando el crecimiento con su compromiso con el desarrollo ético de la IA
Líderes de IA Discuten AGI: Fundamentado en la Realidad
En una reciente cena con líderes empresariales en San Francisco, lancé una pregunta que pareció congelar la sala: ¿podría la IA actual alcanzar alguna vez una inteligencia similar
comentario (36)
0/200
![WillieRoberts]() WillieRoberts
WillieRoberts
 29 de julio de 2025 14:25:16 GMT+02:00
29 de julio de 2025 14:25:16 GMT+02:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!


 0
0
![GeorgeMiller]() GeorgeMiller
14 de abril de 2025 10:35:00 GMT+02:00
GeorgeMiller
14 de abril de 2025 10:35:00 GMT+02:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
![JonathanKing]() JonathanKing
14 de abril de 2025 03:46:37 GMT+02:00
JonathanKing
14 de abril de 2025 03:46:37 GMT+02:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
![DonaldGonzález]() DonaldGonzález
13 de abril de 2025 21:05:45 GMT+02:00
DonaldGonzález
13 de abril de 2025 21:05:45 GMT+02:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
![HaroldMoore]() HaroldMoore
13 de abril de 2025 17:54:39 GMT+02:00
HaroldMoore
13 de abril de 2025 17:54:39 GMT+02:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
![GregoryWilson]() GregoryWilson
13 de abril de 2025 17:36:48 GMT+02:00
GregoryWilson
13 de abril de 2025 17:36:48 GMT+02:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0
La Fundación Arc Prize, cofundada por el reconocido investigador de IA François Chollet, presentó recientemente un nuevo estándar llamado ARC-AGI-2 en una publicación de blog. Esta prueba busca ampliar los límites de la inteligencia general de la IA, y hasta ahora, está resultando ser un desafío difícil de superar para la mayoría de los modelos de IA.
Según la tabla de clasificación de Arc Prize, incluso los modelos avanzados de IA de "razonamiento" como o1-pro de OpenAI y R1 de DeepSeek solo logran puntajes entre el 1% y el 1.3%. Mientras tanto, modelos potentes sin razonamiento como GPT-4.5, Claude 3.7 Sonnet y Gemini 2.0 Flash están rondando la marca del 1%.
Las pruebas ARC-AGI desafían a los sistemas de IA con problemas similares a rompecabezas, requiriendo que identifiquen patrones visuales en cuadrículas de cuadrados de diferentes colores y generen la cuadrícula de "respuesta" correcta. Estos problemas están diseñados para evaluar la capacidad de una IA para adaptarse a nuevos desafíos no vistos.
Para establecer una línea base humana, la Fundación Arc Prize hizo que más de 400 personas realizaran la prueba ARC-AGI-2. En promedio, estos "paneles" de humanos lograron una tasa de éxito del 60%, superando significativamente a los modelos de IA.
Chollet enfatizó que ARC-AGI-2 evita que los modelos de IA dependan de la potencia de cálculo de "fuerza bruta" para resolver problemas, un defecto que reconoció en la primera prueba. Para abordar esto, ARC-AGI-2 introduce una métrica de eficiencia y requiere que los modelos interpreten patrones sobre la marcha en lugar de depender de la memorización.
En una publicación de blog, el cofundador de la Fundación Arc Prize, Greg Kamradt, destacó que la inteligencia no se trata solo de resolver problemas o lograr puntajes altos. "La eficiencia con la que se adquieren y despliegan esas capacidades es un componente crucial y definitorio", escribió. "La pregunta central que se plantea no es solo, '¿Puede la IA adquirir la habilidad para resolver una tarea?', sino también, '¿Con qué eficiencia o costo?'"
ARC-AGI-1 permaneció imbatido durante aproximadamente cinco años hasta diciembre de 2024, cuando el modelo avanzado de razonamiento de OpenAI, o3, superó a todos los demás modelos de IA y igualó el rendimiento humano. Sin embargo, el éxito de o3 en ARC-AGI-1 tuvo un costo significativo. La versión del modelo o3 de OpenAI, o3 (bajo), que obtuvo un impresionante 75.7% en ARC-AGI-1, solo logró un escaso 4% en ARC-AGI-2, utilizando $200 de potencia de cálculo por tarea.
Junto con el nuevo estándar, la Fundación Arc Prize anunció el concurso Arc Prize 2025, desafiando a los desarrolladores a lograr una precisión del 85% en la prueba ARC-AGI-2 mientras gastan solo $0.42 por tarea.









 La inteligencia artificial revolucionará el pensamiento humano con un avance en el lenguaje universal
La aparición de la Inteligencia Artificial General presenta un potencial transformador para remodelar la comunicación humana mediante la creación de un marco lingüístico universal. A diferencia de los
OpenAI Reafirma sus Raíces Sin Fines de Lucro en una Gran Reestructuración Corporativa
OpenAI permanece firme en su misión sin fines de lucro mientras atraviesa una reestructuración corporativa significativa, equilibrando el crecimiento con su compromiso con el desarrollo ético de la IA
La inteligencia artificial revolucionará el pensamiento humano con un avance en el lenguaje universal
La aparición de la Inteligencia Artificial General presenta un potencial transformador para remodelar la comunicación humana mediante la creación de un marco lingüístico universal. A diferencia de los
OpenAI Reafirma sus Raíces Sin Fines de Lucro en una Gran Reestructuración Corporativa
OpenAI permanece firme en su misión sin fines de lucro mientras atraviesa una reestructuración corporativa significativa, equilibrando el crecimiento con su compromiso con el desarrollo ético de la IA
 Líderes de IA Discuten AGI: Fundamentado en la Realidad
En una reciente cena con líderes empresariales en San Francisco, lancé una pregunta que pareció congelar la sala: ¿podría la IA actual alcanzar alguna vez una inteligencia similar
29 de julio de 2025 14:25:16 GMT+02:00
Líderes de IA Discuten AGI: Fundamentado en la Realidad
En una reciente cena con líderes empresariales en San Francisco, lancé una pregunta que pareció congelar la sala: ¿podría la IA actual alcanzar alguna vez una inteligencia similar
29 de julio de 2025 14:25:16 GMT+02:00
This ARC-AGI-2 test sounds brutal! Most AI models are getting crushed, which makes me wonder if we’re hyping AI too much. 🤔 Cool to see Chollet shaking things up though!
0
14 de abril de 2025 10:35:00 GMT+02:00
Este test ARC-AGI-2 es realmente difícil. Lo probé con varios modelos de IA y todos se quedaron atascados. Es genial ver cómo desafía los límites, pero es frustrante cuando ni siquiera los modelos top pueden resolverlo. Quizás sea hora de un nuevo enfoque en el desarrollo de IA. ¡Sigan empujando los límites, pero no olviden celebrar las pequeñas victorias también!
0
14 de abril de 2025 03:46:37 GMT+02:00
¡Este nuevo test de AGI es realmente difícil! Lo intenté y ni siquiera los modelos de IA más inteligentes que conozco pudieron resolverlo. Es como un rompecabezas que te mantiene despierto toda la noche. Felicitaciones a François Chollet por desafiar los límites, pero es frustrante cuando hasta los mejores fallan. Tal vez la próxima vez, ¿verdad?
0
13 de abril de 2025 21:05:45 GMT+02:00
ARC-AGI-2のテストは本当に難しいですね!いくつかのAIモデルで試してみましたが、どれも解けませんでした。限界を押し広げるのは素晴らしいですが、トップモデルが解けないとちょっとイライラします。AI開発に新しいアプローチが必要かもしれませんね。小さな勝利も祝いましょう!
0
13 de abril de 2025 17:54:39 GMT+02:00
この新しいAGIテスト、めっちゃ難しいです!試してみたけど、知っている中で一番賢いAIモデルでも解けませんでした。夜更かししてしまうパズルのようです。フランソワ・ショレに敬意を表しますが、最高のAIが失敗するのはもどかしいですね。次こそは、ね?
0
13 de abril de 2025 17:36:48 GMT+02:00
新しいAGIテストが難しいんだって?ほとんどのAIモデルが苦戦してるらしいね。それはすごいけど、ちょっと怖いよね。本当のAIまでどれだけ遠いのか気になるな。とにかく、限界を押し広げてほしいな。誰かが解くまでどれくらいかかるか見てみよう!
0













