
















 Hogar
HogarEstudio de Microsoft Revela Limitaciones de Modelos de IA en Depuración de Software
Modelos de IA de OpenAI, Anthropic y otros laboratorios líderes de IA se utilizan cada vez más para tareas de codificación. El CEO de Google, Sundar Pichai, señaló en octubre que la IA genera el 25% del nuevo código en la empresa, mientras que el CEO de Meta, Mark Zuckerberg, busca implementar ampliamente herramientas de codificación de IA en el gigante de las redes sociales.
Sin embargo, incluso los modelos de mejor rendimiento tienen dificultades para corregir errores de software que los desarrolladores experimentados manejan con facilidad.
Un reciente estudio de Microsoft Research, realizado por la división de I+D de Microsoft, muestra que modelos como Claude 3.7 Sonnet de Anthropic y o3-mini de OpenAI tienen dificultades para resolver muchos problemas en el punto de referencia de desarrollo de software SWE-bench Lite. Los hallazgos destacan que, a pesar de las ambiciosas afirmaciones de empresas como OpenAI, la IA aún está lejos de la experiencia humana en áreas como la codificación.
Los investigadores del estudio probaron nueve modelos como base para un “agente basado en un solo prompt” equipado con herramientas de depuración, incluido un depurador de Python. El agente tuvo la tarea de abordar 300 desafíos de depuración de software seleccionados de SWE-bench Lite.
Los resultados mostraron que incluso con modelos avanzados, el agente rara vez resolvió más de la mitad de las tareas con éxito. Claude 3.7 Sonnet lideró con una tasa de éxito del 48.4%, seguido por o1 de OpenAI con un 30.2% y o3-mini con un 22.1%.
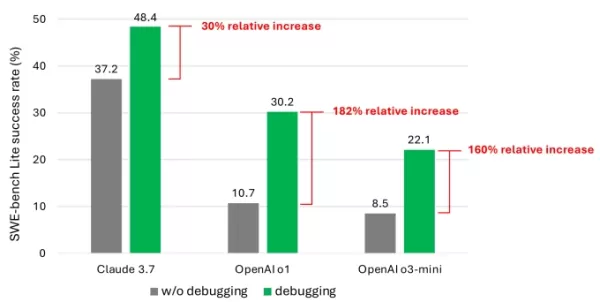
Un gráfico del estudio que muestra el aumento de rendimiento que los modelos obtuvieron con herramientas de depuración. Créditos de la imagen: Microsoft ¿Qué explica los resultados mediocres? Algunos modelos tuvieron dificultades para usar efectivamente las herramientas de depuración disponibles o identificar qué herramientas eran adecuadas para problemas específicos. El problema principal, según los investigadores, fue la falta de datos de entrenamiento suficientes, particularmente datos que capturen “procesos de toma de decisiones secuenciales” como los rastros de depuración humana.
“Creemos que entrenar o ajustar estos modelos puede mejorar sus capacidades de depuración,” escribieron los investigadores. “Sin embargo, esto requiere datos especializados, como datos de trayectoria que capturen a los agentes interactuando con un depurador para recopilar información antes de proponer soluciones.”
Asiste a TechCrunch Sessions: AI
Reserva tu lugar en nuestro evento principal de la industria de IA, con oradores de OpenAI, Anthropic y Cohere. Por tiempo limitado, las entradas cuestan solo $292 para un día completo de charlas de expertos, talleres y oportunidades de networking.
Exhibe en TechCrunch Sessions: AI
Reserva tu espacio en TC Sessions: AI para presentar tu trabajo a más de 1,200 tomadores de decisiones. Las oportunidades de exhibición están disponibles hasta el 9 de mayo o hasta que las mesas estén completamente reservadas.
Los hallazgos no son sorprendentes. Numerosos estudios han demostrado que el código generado por IA a menudo introduce fallos de seguridad y errores debido a debilidades en la comprensión de la lógica de programación. Una prueba reciente de Devin, una conocida herramienta de codificación de IA, reveló que solo pudo completar tres de 20 tareas de programación.
El estudio de Microsoft ofrece uno de los exámenes más profundos de este desafío continuo para los modelos de IA. Aunque es poco probable que frene el interés de los inversores en herramientas de codificación impulsadas por IA, puede llevar a los desarrolladores y sus líderes a reconsiderar depender en gran medida de la IA para tareas de codificación.
Notablemente, varios líderes tecnológicos han rechazado la idea de que la IA eliminará los empleos de codificación. El cofundador de Microsoft, Bill Gates, el CEO de Replit, Amjad Masad, el CEO de Okta, Todd McKinnon, y el CEO de IBM, Arvind Krishna, han expresado confianza en que la programación como profesión perdurará.
Artículo relacionado
 Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
Recomendaciones de temas especiales relacionados
Educación y aprendizaje
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
Recomendaciones de temas especiales relacionados
Educación y aprendizaje
 Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
 10 herramientas
10 herramientas
 xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai
Análisis de datos
Las mejores herramientas de visualización de datos con IA: genera automáticamente paneles de BI interactivos a partir de archivos sin procesar
Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai
Redes Sociales
Kits de imagen de marca basados en IA para redes sociales: mantén una imagen de marca coherente en todos los canales
Descubre los mejores kits de branding con IA para redes sociales de 2026. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias para mantener una imagen de marca perfectamente coherente en todos los canales. Compara las opciones gratuitas con las de pago mediante pruebas reales. Potencia hoy mismo la identidad visual de tu marca.
10 herramientas
xix.ai
chatbot
Las mejores aplicaciones de novias virtuales con IA y herramientas de compañía con IA para juegos de rol (Guía 2026)
Descubre las mejores herramientas de IA de 2026 para disfrutar de una experiencia de rol inmersiva y establecer conexiones. La guía seleccionada por XIX.AI incluye potentes aplicaciones revolucionarias con clasificaciones actualizadas semanalmente, comparativas entre opciones gratuitas y de pago, y pruebas en condiciones reales. Encuentra tu pareja ideal y disfruta hoy mismo de una compañía digital significativa.
10 herramientas
xix.ai

 comentario (6)
0/500
comentario (6)
0/500
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
Modelos de IA de OpenAI, Anthropic y otros laboratorios líderes de IA se utilizan cada vez más para tareas de codificación. El CEO de Google, Sundar Pichai, señaló en octubre que la IA genera el 25% del nuevo código en la empresa, mientras que el CEO de Meta, Mark Zuckerberg, busca implementar ampliamente herramientas de codificación de IA en el gigante de las redes sociales.
Sin embargo, incluso los modelos de mejor rendimiento tienen dificultades para corregir errores de software que los desarrolladores experimentados manejan con facilidad.
Un reciente estudio de Microsoft Research, realizado por la división de I+D de Microsoft, muestra que modelos como Claude 3.7 Sonnet de Anthropic y o3-mini de OpenAI tienen dificultades para resolver muchos problemas en el punto de referencia de desarrollo de software SWE-bench Lite. Los hallazgos destacan que, a pesar de las ambiciosas afirmaciones de empresas como OpenAI, la IA aún está lejos de la experiencia humana en áreas como la codificación.
Los investigadores del estudio probaron nueve modelos como base para un “agente basado en un solo prompt” equipado con herramientas de depuración, incluido un depurador de Python. El agente tuvo la tarea de abordar 300 desafíos de depuración de software seleccionados de SWE-bench Lite.
Los resultados mostraron que incluso con modelos avanzados, el agente rara vez resolvió más de la mitad de las tareas con éxito. Claude 3.7 Sonnet lideró con una tasa de éxito del 48.4%, seguido por o1 de OpenAI con un 30.2% y o3-mini con un 22.1%.
¿Qué explica los resultados mediocres? Algunos modelos tuvieron dificultades para usar efectivamente las herramientas de depuración disponibles o identificar qué herramientas eran adecuadas para problemas específicos. El problema principal, según los investigadores, fue la falta de datos de entrenamiento suficientes, particularmente datos que capturen “procesos de toma de decisiones secuenciales” como los rastros de depuración humana.
“Creemos que entrenar o ajustar estos modelos puede mejorar sus capacidades de depuración,” escribieron los investigadores. “Sin embargo, esto requiere datos especializados, como datos de trayectoria que capturen a los agentes interactuando con un depurador para recopilar información antes de proponer soluciones.”
Asiste a TechCrunch Sessions: AI
Reserva tu lugar en nuestro evento principal de la industria de IA, con oradores de OpenAI, Anthropic y Cohere. Por tiempo limitado, las entradas cuestan solo $292 para un día completo de charlas de expertos, talleres y oportunidades de networking.
Exhibe en TechCrunch Sessions: AI
Reserva tu espacio en TC Sessions: AI para presentar tu trabajo a más de 1,200 tomadores de decisiones. Las oportunidades de exhibición están disponibles hasta el 9 de mayo o hasta que las mesas estén completamente reservadas.
Los hallazgos no son sorprendentes. Numerosos estudios han demostrado que el código generado por IA a menudo introduce fallos de seguridad y errores debido a debilidades en la comprensión de la lógica de programación. Una prueba reciente de Devin, una conocida herramienta de codificación de IA, reveló que solo pudo completar tres de 20 tareas de programación.
El estudio de Microsoft ofrece uno de los exámenes más profundos de este desafío continuo para los modelos de IA. Aunque es poco probable que frene el interés de los inversores en herramientas de codificación impulsadas por IA, puede llevar a los desarrolladores y sus líderes a reconsiderar depender en gran medida de la IA para tareas de codificación.
Notablemente, varios líderes tecnológicos han rechazado la idea de que la IA eliminará los empleos de codificación. El cofundador de Microsoft, Bill Gates, el CEO de Replit, Amjad Masad, el CEO de Okta, Todd McKinnon, y el CEO de IBM, Arvind Krishna, han expresado confianza en que la programación como profesión perdurará.









 Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
 Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
 YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai

Descubre los mejores kits de branding con IA para redes sociales de 2026. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias para mantener una imagen de marca perfectamente coherente en todos los canales. Compara las opciones gratuitas con las de pago mediante pruebas reales. Potencia hoy mismo la identidad visual de tu marca.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para disfrutar de una experiencia de rol inmersiva y establecer conexiones. La guía seleccionada por XIX.AI incluye potentes aplicaciones revolucionarias con clasificaciones actualizadas semanalmente, comparativas entre opciones gratuitas y de pago, y pruebas en condiciones reales. Encuentra tu pareja ideal y disfruta hoy mismo de una compañía digital significativa.
10 herramientas
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













