




Microsoft-Studie zeigt die Grenzen von KI-Modellen beim Software-Debugging
KI-Modelle von OpenAI, Anthropic und anderen führenden KI-Laboren werden zunehmend für Programmieraufgaben eingesetzt. Google-CEO Sundar Pichai bemerkte im Oktober, dass KI 25 % des neuen Codes im Unternehmen generiert, während Meta-CEO Mark Zuckerberg plant, KI-Programmierwerkzeuge weitreichend im Social-Media-Riesen einzusetzen.
Allerdings haben selbst die leistungsstärksten Modelle Schwierigkeiten, Softwarefehler zu beheben, die erfahrene Entwickler mühelos meistern.
Eine kürzlich durchgeführte Studie von Microsoft Research, geleitet von Microsofts Forschungs- und Entwicklungsabteilung, zeigt, dass Modelle wie Anthropics Claude 3.7 Sonnet und OpenAIs o3-mini viele Probleme im SWE-bench Lite Softwareentwicklungs-Benchmark nicht lösen konnten. Die Ergebnisse verdeutlichen, dass KI trotz ambitionierter Behauptungen von Unternehmen wie OpenAI in Bereichen wie der Programmierung immer noch hinter menschlicher Expertise zurückbleibt.
Die Forscher der Studie testeten neun Modelle als Grundlage für einen „Single-Prompt-basierten Agenten“, der mit Debugging-Tools, einschließlich eines Python-Debuggers, ausgestattet war. Der Agent wurde beauftragt, 300 kuratierte Software-Debugging-Herausforderungen aus SWE-bench Lite zu bewältigen.
Die Ergebnisse zeigten, dass selbst mit fortschrittlichen Modellen der Agent selten mehr als die Hälfte der Aufgaben erfolgreich löste. Claude 3.7 Sonnet führte mit einer Erfolgsquote von 48,4 %, gefolgt von OpenAIs o1 mit 30,2 % und o3-mini mit 22,1 %.
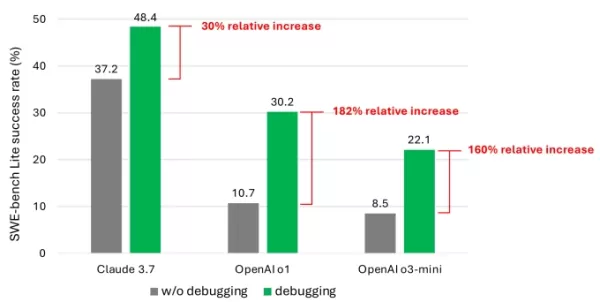
Ein Diagramm aus der Studie, das die Leistungssteigerung der Modelle durch Debugging-Tools zeigt. Bildnachweis: Microsoft Was erklärt die enttäuschenden Ergebnisse? Einige Modelle hatten Schwierigkeiten, verfügbare Debugging-Tools effektiv zu nutzen oder zu erkennen, welche Tools für spezifische Probleme geeignet waren. Das Hauptproblem war laut den Forschern ein Mangel an ausreichenden Trainingsdaten, insbesondere Daten, die „sequentielle Entscheidungsprozesse“ wie menschliche Debugging-Abläufe erfassen.
„Wir glauben, dass das Training oder die Feinabstimmung dieser Modelle ihre Debugging-Fähigkeiten verbessern kann“, schrieben die Forscher. „Dies erfordert jedoch spezialisierte Daten, wie Trajektoriendaten, die Agenten beim Interagieren mit einem Debugger erfassen, um Informationen zu sammeln, bevor sie Korrekturen vorschlagen.“
Nehmen Sie an TechCrunch Sessions teil: AI
Sichern Sie sich Ihren Platz bei unserer führenden Veranstaltung der KI-Branche mit Sprechern von OpenAI, Anthropic und Cohere. Für begrenzte Zeit kosten Tickets nur 292 $ für einen ganzen Tag mit Expertenvorträgen, Workshops und Networking-Möglichkeiten.
Präsentieren Sie sich bei TechCrunch Sessions: AI
Buchen Sie Ihren Platz bei TC Sessions: AI, um Ihre Arbeit über 1.200 Entscheidungsträgern zu präsentieren. Ausstellungsmöglichkeiten sind bis zum 9. Mai oder bis alle Tische ausgebucht sind verfügbar.
Die Ergebnisse sind nicht überraschend. Zahlreiche Studien haben gezeigt, dass KI-generierter Code oft Sicherheitslücken und Fehler aufweist, da Schwächen im Verständnis der Programmierlogik bestehen. Ein kürzlich durchgeführter Test von Devin, einem bekannten KI-Programmierwerkzeug, ergab, dass es nur drei von 20 Programmieraufgaben abschließen konnte.
Die Studie von Microsoft bietet eine der detailliertesten Untersuchungen dieser anhaltenden Herausforderung für KI-Modelle. Zwar wird sie das Interesse von Investoren an KI-gestützten Programmierwerkzeugen kaum bremsen, könnte aber Entwickler und ihre Führungskräfte dazu veranlassen, die starke Abhängigkeit von KI für Programmieraufgaben zu überdenken.
Bemerkenswert ist, dass mehrere Tech-Führer die Vorstellung zurückgewiesen haben, dass KI Programmierjobs eliminieren wird. Microsoft-Mitbegründer Bill Gates, Replit-CEO Amjad Masad, Okta-CEO Todd McKinnon und IBM-CEO Arvind Krishna haben alle ihr Vertrauen geäußert, dass das Programmieren als Beruf bestehen bleiben wird.
Verwandter Artikel
 Sicherheitslücke bei ChatGPT zum Diebstahl sensibler Google Mail-Daten ausgenutzt
Sicherheitswarnung: Forscher demonstrieren KI-gestützte DatenexfiltrationstechnikCybersecurity-Experten haben vor kurzem eine Sicherheitslücke entdeckt, durch die die Deep Research-Funktion von ChatGP
Anthropic räumt KI-Fehler in juristischem Dossier ein und bezeichnet ihn als "peinlich und unbeabsichtigt".
Anthropic hat sich zu den Vorwürfen bezüglich einer KI-generierten Quelle in seinem laufenden Rechtsstreit mit Musikverlagen geäußert und den Vorfall als einen "unbeabsichtigten Zitierfehler" seines C
Gmail führt automatische AI-gestützte E-Mail-Zusammenfassungen ein
Gemini-gestützte E-Mail-Zusammenfassungen für Workspace-NutzerGoogle Workspace-Abonnenten werden die erweiterte Rolle von Gemini bei der Verwaltung ihrer Posteingänge bemerken, da Google Mail nun au
Kommentare (6)
0/200
Sicherheitslücke bei ChatGPT zum Diebstahl sensibler Google Mail-Daten ausgenutzt
Sicherheitswarnung: Forscher demonstrieren KI-gestützte DatenexfiltrationstechnikCybersecurity-Experten haben vor kurzem eine Sicherheitslücke entdeckt, durch die die Deep Research-Funktion von ChatGP
Anthropic räumt KI-Fehler in juristischem Dossier ein und bezeichnet ihn als "peinlich und unbeabsichtigt".
Anthropic hat sich zu den Vorwürfen bezüglich einer KI-generierten Quelle in seinem laufenden Rechtsstreit mit Musikverlagen geäußert und den Vorfall als einen "unbeabsichtigten Zitierfehler" seines C
Gmail führt automatische AI-gestützte E-Mail-Zusammenfassungen ein
Gemini-gestützte E-Mail-Zusammenfassungen für Workspace-NutzerGoogle Workspace-Abonnenten werden die erweiterte Rolle von Gemini bei der Verwaltung ihrer Posteingänge bemerken, da Google Mail nun au
Kommentare (6)
0/200
![ThomasScott]() ThomasScott
ThomasScott
 7. September 2025 06:30:35 MESZ
7. September 2025 06:30:35 MESZ
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。


 0
0
![HenryWalker]() HenryWalker
17. August 2025 07:00:59 MESZ
HenryWalker
17. August 2025 07:00:59 MESZ
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
0
![BrianRoberts]() BrianRoberts
14. August 2025 09:00:59 MESZ
BrianRoberts
14. August 2025 09:00:59 MESZ
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
0
![KevinDavis]() KevinDavis
9. August 2025 23:00:59 MESZ
KevinDavis
9. August 2025 23:00:59 MESZ
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
0
![PeterThomas]() PeterThomas
1. August 2025 04:48:18 MESZ
PeterThomas
1. August 2025 04:48:18 MESZ
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
0
![JuanWhite]() JuanWhite
23. Juli 2025 06:59:29 MESZ
JuanWhite
23. Juli 2025 06:59:29 MESZ
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
0
KI-Modelle von OpenAI, Anthropic und anderen führenden KI-Laboren werden zunehmend für Programmieraufgaben eingesetzt. Google-CEO Sundar Pichai bemerkte im Oktober, dass KI 25 % des neuen Codes im Unternehmen generiert, während Meta-CEO Mark Zuckerberg plant, KI-Programmierwerkzeuge weitreichend im Social-Media-Riesen einzusetzen.
Allerdings haben selbst die leistungsstärksten Modelle Schwierigkeiten, Softwarefehler zu beheben, die erfahrene Entwickler mühelos meistern.
Eine kürzlich durchgeführte Studie von Microsoft Research, geleitet von Microsofts Forschungs- und Entwicklungsabteilung, zeigt, dass Modelle wie Anthropics Claude 3.7 Sonnet und OpenAIs o3-mini viele Probleme im SWE-bench Lite Softwareentwicklungs-Benchmark nicht lösen konnten. Die Ergebnisse verdeutlichen, dass KI trotz ambitionierter Behauptungen von Unternehmen wie OpenAI in Bereichen wie der Programmierung immer noch hinter menschlicher Expertise zurückbleibt.
Die Forscher der Studie testeten neun Modelle als Grundlage für einen „Single-Prompt-basierten Agenten“, der mit Debugging-Tools, einschließlich eines Python-Debuggers, ausgestattet war. Der Agent wurde beauftragt, 300 kuratierte Software-Debugging-Herausforderungen aus SWE-bench Lite zu bewältigen.
Die Ergebnisse zeigten, dass selbst mit fortschrittlichen Modellen der Agent selten mehr als die Hälfte der Aufgaben erfolgreich löste. Claude 3.7 Sonnet führte mit einer Erfolgsquote von 48,4 %, gefolgt von OpenAIs o1 mit 30,2 % und o3-mini mit 22,1 %.
Was erklärt die enttäuschenden Ergebnisse? Einige Modelle hatten Schwierigkeiten, verfügbare Debugging-Tools effektiv zu nutzen oder zu erkennen, welche Tools für spezifische Probleme geeignet waren. Das Hauptproblem war laut den Forschern ein Mangel an ausreichenden Trainingsdaten, insbesondere Daten, die „sequentielle Entscheidungsprozesse“ wie menschliche Debugging-Abläufe erfassen.
„Wir glauben, dass das Training oder die Feinabstimmung dieser Modelle ihre Debugging-Fähigkeiten verbessern kann“, schrieben die Forscher. „Dies erfordert jedoch spezialisierte Daten, wie Trajektoriendaten, die Agenten beim Interagieren mit einem Debugger erfassen, um Informationen zu sammeln, bevor sie Korrekturen vorschlagen.“
Nehmen Sie an TechCrunch Sessions teil: AI
Sichern Sie sich Ihren Platz bei unserer führenden Veranstaltung der KI-Branche mit Sprechern von OpenAI, Anthropic und Cohere. Für begrenzte Zeit kosten Tickets nur 292 $ für einen ganzen Tag mit Expertenvorträgen, Workshops und Networking-Möglichkeiten.
Präsentieren Sie sich bei TechCrunch Sessions: AI
Buchen Sie Ihren Platz bei TC Sessions: AI, um Ihre Arbeit über 1.200 Entscheidungsträgern zu präsentieren. Ausstellungsmöglichkeiten sind bis zum 9. Mai oder bis alle Tische ausgebucht sind verfügbar.
Die Ergebnisse sind nicht überraschend. Zahlreiche Studien haben gezeigt, dass KI-generierter Code oft Sicherheitslücken und Fehler aufweist, da Schwächen im Verständnis der Programmierlogik bestehen. Ein kürzlich durchgeführter Test von Devin, einem bekannten KI-Programmierwerkzeug, ergab, dass es nur drei von 20 Programmieraufgaben abschließen konnte.
Die Studie von Microsoft bietet eine der detailliertesten Untersuchungen dieser anhaltenden Herausforderung für KI-Modelle. Zwar wird sie das Interesse von Investoren an KI-gestützten Programmierwerkzeugen kaum bremsen, könnte aber Entwickler und ihre Führungskräfte dazu veranlassen, die starke Abhängigkeit von KI für Programmieraufgaben zu überdenken.
Bemerkenswert ist, dass mehrere Tech-Führer die Vorstellung zurückgewiesen haben, dass KI Programmierjobs eliminieren wird. Microsoft-Mitbegründer Bill Gates, Replit-CEO Amjad Masad, Okta-CEO Todd McKinnon und IBM-CEO Arvind Krishna haben alle ihr Vertrauen geäußert, dass das Programmieren als Beruf bestehen bleiben wird.










 Sicherheitslücke bei ChatGPT zum Diebstahl sensibler Google Mail-Daten ausgenutzt
Sicherheitswarnung: Forscher demonstrieren KI-gestützte DatenexfiltrationstechnikCybersecurity-Experten haben vor kurzem eine Sicherheitslücke entdeckt, durch die die Deep Research-Funktion von ChatGP
Sicherheitslücke bei ChatGPT zum Diebstahl sensibler Google Mail-Daten ausgenutzt
Sicherheitswarnung: Forscher demonstrieren KI-gestützte DatenexfiltrationstechnikCybersecurity-Experten haben vor kurzem eine Sicherheitslücke entdeckt, durch die die Deep Research-Funktion von ChatGP
 Anthropic räumt KI-Fehler in juristischem Dossier ein und bezeichnet ihn als "peinlich und unbeabsichtigt".
Anthropic hat sich zu den Vorwürfen bezüglich einer KI-generierten Quelle in seinem laufenden Rechtsstreit mit Musikverlagen geäußert und den Vorfall als einen "unbeabsichtigten Zitierfehler" seines C
Anthropic räumt KI-Fehler in juristischem Dossier ein und bezeichnet ihn als "peinlich und unbeabsichtigt".
Anthropic hat sich zu den Vorwürfen bezüglich einer KI-generierten Quelle in seinem laufenden Rechtsstreit mit Musikverlagen geäußert und den Vorfall als einen "unbeabsichtigten Zitierfehler" seines C
 Gmail führt automatische AI-gestützte E-Mail-Zusammenfassungen ein
Gemini-gestützte E-Mail-Zusammenfassungen für Workspace-NutzerGoogle Workspace-Abonnenten werden die erweiterte Rolle von Gemini bei der Verwaltung ihrer Posteingänge bemerken, da Google Mail nun au
7. September 2025 06:30:35 MESZ
Gmail führt automatische AI-gestützte E-Mail-Zusammenfassungen ein
Gemini-gestützte E-Mail-Zusammenfassungen für Workspace-NutzerGoogle Workspace-Abonnenten werden die erweiterte Rolle von Gemini bei der Verwaltung ihrer Posteingänge bemerken, da Google Mail nun au
7. September 2025 06:30:35 MESZ
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
0
17. August 2025 07:00:59 MESZ
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
0
14. August 2025 09:00:59 MESZ
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
0
9. August 2025 23:00:59 MESZ
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
0
1. August 2025 04:48:18 MESZ
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
0
23. Juli 2025 06:59:29 MESZ
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
0













