
















 首页
首页AI语音克隆:掌握语音转换的终极指南
在快速发展的世界人工智能中,人工智能语音克隆作为一项引人入胜且改变游戏规则的技术崭露头角。本指南将带你在人工智能语音克隆的复杂世界中展开旅程,探索如何使用人工智能克隆声音、创造创新的音频体验,并深入了解这项技术所带来的众多机会。从掌握基本工具和模型到遵循详细的说明,你将获得启动自己语音克隆项目所需的技能。沉浸在人工智能语音转换领域,开启音频制作的新前沿。
人工智能语音克隆的关键要点
- 了解人工智能语音克隆的基础知识
- 必要工具:人工智能模型、Google Collab 等
- 语音转换的分步指导
- 移除人声和分离伴奏的技巧
- 优化人工智能克隆的音频质量
- 探索道德考量和负责任的使用
- 解决语音克隆中的常见问题
- 人工智能语音克隆技术的未来趋势
人工智能语音克隆入门
什么是人工智能语音克隆?
本质上,人工智能语音克隆利用人工智能来模仿和重现一个人的声音。它不仅仅是基本的语音合成,而是捕捉声音的细微之处、语调变化和独特特质,使声音真正个性化。这一过程涉及在现有音频数据上训练人工智能模型,以识别特定声音的模式和特征。一旦训练完成,这些模型可以生成克隆声音的新语音,即使是原始说话者从未说过的短语。

人工智能语音克隆的应用范围广泛,涵盖娱乐、内容创作、辅助功能和个人助理。它为创建定制的有声书、个性化消息,甚至复活历史人物或已故亲人的声音(当然需考虑适当的道德和许可!)打开了大Astaltic的大门。然而,谨慎且负责任地处理这项技术至关重要,因为复制声音的能力带来了关于同意、真实性和潜在滥用的严肃问题。了解技术的功能和局限性是将其用于积极成果的第一步。让我们更深入地探索开始这段激动人心的旅程所需的工具。人工智能驱动的语音克隆已真正革新了当今的数字媒体和内容创作。
人工智能语音克隆所需的工具
开始你的AI语音克隆冒险需要一些关键工具和资源。以下是你需要的:
- 人工智能模型: 语音克隆的支柱,这些模型通常基于神经网络等深度学习架构,训练用于识别和复制语音模式。你可以在 Google AI 等平台或 GitHub 上的开源项目中找到流行的模型。确保下载你所选艺术家或演讲者的人工智能模型。

- 音频文件: 你需要高质量的音频文件,用于克隆的声音。音频数据质量越高,克隆效果越好。确保你有权将音频用于克隆目的。
- 音频编辑软件: 用于清理音频、移除背景噪音和分离人声轨道,这是必不可少的工具。Audacity(免费)或 Adobe Audition(付费)是首选。
- Google Collab: Google 提供的免费云端平台,可运行 Python 代码,包括人工智能语音克隆所需的复杂计算。它提供对强大 GPU 和 TPU 的访问,使过程更快更高效。你还将使用 Google Collab 上的 Easy GUI for RVC。
- Google Drive: 用于存储你的人工智能模型、音频文件和任何生成的内容。Google Drive 提供充足的存储空间,便于 Google Collab 访问。
有了这些工具,你就具备了创建逼真且引人入胜的人工智能语音克隆的条件。让我们继续设置这些工具。
高质量语音克隆的额外技巧
优化音频输入
输入音频的质量对克隆声音的质量影响巨大。在安静的环境中录音,尽量减少背景噪音。使用高质量麦克风捕捉声音的全部频谱。编辑音频以删除不必要的停顿或填充词。规范化音频水平也有助于确保一致的输出。通过关注这些细节,你将为人工智能模型提供最佳数据以进行处理。
道德考量和最佳实践
人工智能语音克隆伴随着一些你必须注意的道德考量。始终获得被克隆者的同意。保持使用人工智能生成声音的透明度,避免任何欺骗行为。负责任地使用技术,避免创建可能有害或误导的内容。尊重版权和知识产权。通过遵循这些道德准则,你可以帮助确保人工智能语音克隆用于积极目的,其潜力不会因滥用而被削弱。你还可以从 Discord 下载任何艺术家模型。
人工智能语音克隆分步指南
步骤 1:下载人工智能模型
首先下载你需要的人工智能模型。许多当前 RVC 模型仅使用以 RVC 结尾的语音模型,因此确保你选择的艺术家或演讲者有该文件可用。

你可以在专注于人工智能语音克隆的 Discord 服务器上或通过其他爱好者共享的链接找到这些模型。确保模型与你打算使用的语音克隆软件兼容。
步骤 2:准备音频数据
清理并准备你想要克隆的声音的音频数据。移除背景噪音,分离人声轨道,确保音频质量高。音频编辑软件可以帮助完成这一过程。高质量的音频数据对于人工智能模型有效学习和复制声音至关重要。
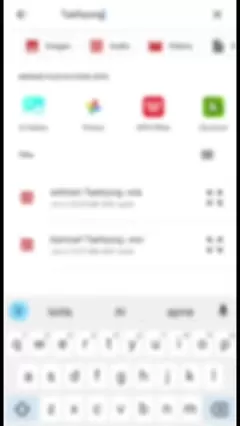
像 x-minus.pro 这样的网站可以帮助你从音频中移除人声和伴奏。
步骤 3:设置 Google Collab
- 访问 Google Collab: 在你的网络浏览器中打开 Google Collab。

- 上传必需文件: 将你的人工智能模型和音频文件上传到你的 Google Drive。
- 连接到运行时环境: 将 Google Collab 连接到运行时环境(GPU 或 TPU)以加速处理。这将使 Google Collab 能够访问 Python 3 Google Compute Engine 后端以获得更快的速度。
步骤 4:运行语音克隆过程
- 安装必要库: 在 Google Collab 中执行代码单元以安装语音克隆所需的库和依赖项。
- 加载人工智能模型: 将你的人工智能模型加载到 Google Collab 中。
- 输入音频: 提供你想要转换的音频。这可以是你自己的录音或其他音频文件。
- 转换声音: 运行语音转换过程。人工智能模型将把输入音频转换为克隆的声音。
步骤 5:优化和下载
- 聆听输出: 检查转换后的音频是否存在任何瑕疵或不一致。
- 调整参数: 在 Google Collab 中优化参数以改进语音克隆过程。
- 下载转换后的音频: 一旦满意,下载转换后的音频文件。选择合适的格式(例如 WAV 或 MP3)。
工具的定价和可用性
Google Collab
Google Collab 是一项免费服务,提供对包括 GPU 和 TPU 在内的云端计算资源的访问。这使其成为运行人工智能模型的可访问选项。然而,存在使用限制,你可能需要升级到付费计划(Collab Pro 或 Collab Pro+)以获得更多资源和更长的运行时间。
音频编辑软件
Audacity 是一款免费且开源的音频编辑器,提供广泛的清理和编辑音频功能。Adobe Audition 等付费选项提供更高级的工具,但需支付月度或年度订阅费用。最佳选择取决于你的预算和项目的复杂性。
人工智能语音克隆的优点和缺点
优点
- 能够精确复制特定声音
- 增强的内容创作能力
- 为语言障碍者提供辅助解决方案的潜力
- 创建以已故艺术家克隆声音为特色的虚拟音乐会
- 提供语音银行服务以保留个人声音
- 可用于虚拟助手或个性化语音消息
缺点
- 关于同意和真实性的道德问题
- 可能被滥用于有害或误导性内容
- 存在版权和知识产权侵权的风险
- 需要大量高质量音频数据进行训练
- 克隆声音可能听起来不自然或机械
- 计算密集,需要强大的硬件或云端计算资源
人工智能语音克隆技术的关键功能
语音复制
人工智能语音克隆的核心功能是能够以惊人的准确性复制特定声音。人工智能模型分析音频数据以学习声音的独特特征,包括音调、音高、节奏和语调。一旦训练完成,模型可以生成克隆声音的新语音,即使是原始说话者从未实际说过的内容。这项功能使创建定制的有声书、个性化消息和听起来像特定人物的虚拟助手成为可能。
语音转换
语音转换是将一个人的声音转换为另一个人的声音的过程。这项技术允许你获取现有的音频录音并将说话者的声音更改为克隆的声音。语音转换可用于为视频创建配音、为电影配音以及生成不同语言的语音。该过程涉及分析源声音,然后应用目标声音的特征,创造出无缝且自然的声音转换。
人工智能语音克隆的用例
内容创作
人工智能语音克隆为内容创作开辟了新的可能性,允许你创建独特的音频体验。你可以克隆自己的声音以创建个性化消息、虚拟助手和教育内容。这项技术还允许为视频、有声书和播客生成配音。内容创作者可以利用人工智能语音克隆尝试不同的声音,创建脱颖而出的内容。
辅助功能
人工智能语音克隆为语言障碍者提供解决方案。通过克隆一个人的声音,可以创建辅助技术,使他们能够更有效地沟通。克隆技术还可用于提供语音银行服务,让人们在因医疗原因失去声音之前保留自己的声音。这项技术可以提高有沟通障碍个体的可访问性和包容性。
娱乐
人工智能语音克隆可用于创建新的娱乐形式。人工智能生成的声音可用于为电影配音、创建动画角色以及制作沉浸式游戏体验。这项技术还使创建以已故艺术家克隆声音为特色的虚拟音乐会成为可能。克隆技术为互动式故事讲述和个性化娱乐体验开辟了可能性,以满足个人偏好。
关于人工智能语音克隆的常见问题
人工智能语音克隆是否道德?
人工智能语音克隆的道德考量复杂,取决于技术的使用方式。获得被克隆者的同意至关重要。关于使用人工智能生成声音的透明度对于避免欺骗也至关重要。负责任地使用这项技术涉及尊重版权、知识产权,并避免创建有害或误导性内容。遵循这些道德准则将有助于确保人工智能语音克隆用于有益目的。
人工智能语音克隆的局限性是什么?
人工智能语音克隆并非没有局限性。克隆声音的质量取决于训练数据的数量和质量。模型可能难以复制具有复杂语音模式或口音的声音。如果没有适当优化,人工智能生成的声音可能听起来不自然或机械。此外,人工智能语音克隆可能需要强大的硬件或云端计算资源。随着技术的进步,许多这些局限性将得到解决。
我可以使用人工智能语音克隆进行商业项目吗?
你可以使用人工智能语音克隆进行商业项目。使用人工智能语音克隆进行商业项目的可行性和合法性取决于几个因素。确保你有权将音频数据用于克隆目的。遵守所有相关的版权和知识产权法律。对你的观众保持使用人工智能生成声音的透明度。通过解决这些问题,你可以在避免法律和道德陷阱的同时使用人工智能语音克隆进行商业项目。考虑购买和/或使用高级订阅以获得最佳商业应用。
与语音克隆相关的问题
什么是 Google Collab 以及它如何工作?
Google Collab 是 Google 提供的云端平台,允许你在协作环境中运行 Python 代码。它提供对包括 GPU 和 TPU 在内的强大计算资源的访问,使其成为机器学习项目的理想选择。Google Collab 通过提供 Jupyter 笔记本界面工作,你可以在其中编写和执行代码。你可以将文件上传到 Google Drive 并直接从 Collab 笔记本访问它们。此外,Google Collab 与其他 Google 服务集成,便于分享你的工作并与他人协作。Google Collab 免费使用,但存在使用限制。你可能需要升级到付费计划以获得更多资源和更长的运行时间。
在哪里可以找到用于克隆过程的人工智能语音模型?
人工智能语音模型可以从各种来源获得。一个选择是像 GitHub 这样的开源平台,开发者在其中分享他们的训练模型。另一个选择是通过专注于人工智能语音克隆的 Discord 服务器。请注意列为 SVC 模型的模型,因为那是与 RVC 完全不同的另一个过程。
相关文章
 Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
相关专题推荐
漫画创作
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
相关专题推荐
漫画创作
 少年漫画顶级AI生成器:打造高能动作场面与特效
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
 15 个工具
15 个工具
 xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

 评论 (5)
0/500
评论 (5)
0/500
![WilliamYoung]()
Die Stimmenklon-Technologie ist faszinierend, aber auch ein bisschen gruselig. Wer garantiert, dass meine Stimme nicht missbraucht wird? Trotzdem, die Anwendungen für Hörbücher oder persönliche Assistenten sind wirklich verlockend. 🎙️
![GeorgeMartinez]()
声を複製できるって、正直ちょっと怖いですよね…プライバシーや悪用が心配です。でも、音楽やゲームのボイスキャラクターには役立ちそう!使い方次第な技術ですね😅
![JackPerez]()
This guide on AI voice cloning is mind-blowing! 😮 The idea of creating realistic voices for audio projects feels like sci-fi magic. Can’t wait to try it out for my podcast!
![WilliamAllen]()
This AI voice cloning guide is mind-blowing! 😮 The tech sounds like magic, but I wonder how it’ll impact voice actors’ jobs.
![DavidGreen]()
This AI voice cloning guide is mind-blowing! It’s wild to think we can recreate voices so realistically. I’m curious how this tech might change podcasting or even trick scammers. 😎 Anyone else worried about deepfake voices getting too good?
在快速发展的世界人工智能中,人工智能语音克隆作为一项引人入胜且改变游戏规则的技术崭露头角。本指南将带你在人工智能语音克隆的复杂世界中展开旅程,探索如何使用人工智能克隆声音、创造创新的音频体验,并深入了解这项技术所带来的众多机会。从掌握基本工具和模型到遵循详细的说明,你将获得启动自己语音克隆项目所需的技能。沉浸在人工智能语音转换领域,开启音频制作的新前沿。
人工智能语音克隆的关键要点
- 了解人工智能语音克隆的基础知识
- 必要工具:人工智能模型、Google Collab 等
- 语音转换的分步指导
- 移除人声和分离伴奏的技巧
- 优化人工智能克隆的音频质量
- 探索道德考量和负责任的使用
- 解决语音克隆中的常见问题
- 人工智能语音克隆技术的未来趋势
人工智能语音克隆入门
什么是人工智能语音克隆?
本质上,人工智能语音克隆利用人工智能来模仿和重现一个人的声音。它不仅仅是基本的语音合成,而是捕捉声音的细微之处、语调变化和独特特质,使声音真正个性化。这一过程涉及在现有音频数据上训练人工智能模型,以识别特定声音的模式和特征。一旦训练完成,这些模型可以生成克隆声音的新语音,即使是原始说话者从未说过的短语。
人工智能语音克隆的应用范围广泛,涵盖娱乐、内容创作、辅助功能和个人助理。它为创建定制的有声书、个性化消息,甚至复活历史人物或已故亲人的声音(当然需考虑适当的道德和许可!)打开了大Astaltic的大门。然而,谨慎且负责任地处理这项技术至关重要,因为复制声音的能力带来了关于同意、真实性和潜在滥用的严肃问题。了解技术的功能和局限性是将其用于积极成果的第一步。让我们更深入地探索开始这段激动人心的旅程所需的工具。人工智能驱动的语音克隆已真正革新了当今的数字媒体和内容创作。
人工智能语音克隆所需的工具
开始你的AI语音克隆冒险需要一些关键工具和资源。以下是你需要的:
- 人工智能模型: 语音克隆的支柱,这些模型通常基于神经网络等深度学习架构,训练用于识别和复制语音模式。你可以在 Google AI 等平台或 GitHub 上的开源项目中找到流行的模型。确保下载你所选艺术家或演讲者的人工智能模型。
- 音频文件: 你需要高质量的音频文件,用于克隆的声音。音频数据质量越高,克隆效果越好。确保你有权将音频用于克隆目的。
- 音频编辑软件: 用于清理音频、移除背景噪音和分离人声轨道,这是必不可少的工具。Audacity(免费)或 Adobe Audition(付费)是首选。
- Google Collab: Google 提供的免费云端平台,可运行 Python 代码,包括人工智能语音克隆所需的复杂计算。它提供对强大 GPU 和 TPU 的访问,使过程更快更高效。你还将使用 Google Collab 上的 Easy GUI for RVC。
- Google Drive: 用于存储你的人工智能模型、音频文件和任何生成的内容。Google Drive 提供充足的存储空间,便于 Google Collab 访问。
有了这些工具,你就具备了创建逼真且引人入胜的人工智能语音克隆的条件。让我们继续设置这些工具。
高质量语音克隆的额外技巧
优化音频输入
输入音频的质量对克隆声音的质量影响巨大。在安静的环境中录音,尽量减少背景噪音。使用高质量麦克风捕捉声音的全部频谱。编辑音频以删除不必要的停顿或填充词。规范化音频水平也有助于确保一致的输出。通过关注这些细节,你将为人工智能模型提供最佳数据以进行处理。
道德考量和最佳实践
人工智能语音克隆伴随着一些你必须注意的道德考量。始终获得被克隆者的同意。保持使用人工智能生成声音的透明度,避免任何欺骗行为。负责任地使用技术,避免创建可能有害或误导的内容。尊重版权和知识产权。通过遵循这些道德准则,你可以帮助确保人工智能语音克隆用于积极目的,其潜力不会因滥用而被削弱。你还可以从 Discord 下载任何艺术家模型。
人工智能语音克隆分步指南
步骤 1:下载人工智能模型
首先下载你需要的人工智能模型。许多当前 RVC 模型仅使用以 RVC 结尾的语音模型,因此确保你选择的艺术家或演讲者有该文件可用。
你可以在专注于人工智能语音克隆的 Discord 服务器上或通过其他爱好者共享的链接找到这些模型。确保模型与你打算使用的语音克隆软件兼容。
步骤 2:准备音频数据
清理并准备你想要克隆的声音的音频数据。移除背景噪音,分离人声轨道,确保音频质量高。音频编辑软件可以帮助完成这一过程。高质量的音频数据对于人工智能模型有效学习和复制声音至关重要。
像 x-minus.pro 这样的网站可以帮助你从音频中移除人声和伴奏。
步骤 3:设置 Google Collab
- 访问 Google Collab: 在你的网络浏览器中打开 Google Collab。
- 上传必需文件: 将你的人工智能模型和音频文件上传到你的 Google Drive。
- 连接到运行时环境: 将 Google Collab 连接到运行时环境(GPU 或 TPU)以加速处理。这将使 Google Collab 能够访问 Python 3 Google Compute Engine 后端以获得更快的速度。
步骤 4:运行语音克隆过程
- 安装必要库: 在 Google Collab 中执行代码单元以安装语音克隆所需的库和依赖项。
- 加载人工智能模型: 将你的人工智能模型加载到 Google Collab 中。
- 输入音频: 提供你想要转换的音频。这可以是你自己的录音或其他音频文件。
- 转换声音: 运行语音转换过程。人工智能模型将把输入音频转换为克隆的声音。
步骤 5:优化和下载
- 聆听输出: 检查转换后的音频是否存在任何瑕疵或不一致。
- 调整参数: 在 Google Collab 中优化参数以改进语音克隆过程。
- 下载转换后的音频: 一旦满意,下载转换后的音频文件。选择合适的格式(例如 WAV 或 MP3)。
工具的定价和可用性
Google Collab
Google Collab 是一项免费服务,提供对包括 GPU 和 TPU 在内的云端计算资源的访问。这使其成为运行人工智能模型的可访问选项。然而,存在使用限制,你可能需要升级到付费计划(Collab Pro 或 Collab Pro+)以获得更多资源和更长的运行时间。
音频编辑软件
Audacity 是一款免费且开源的音频编辑器,提供广泛的清理和编辑音频功能。Adobe Audition 等付费选项提供更高级的工具,但需支付月度或年度订阅费用。最佳选择取决于你的预算和项目的复杂性。
人工智能语音克隆的优点和缺点
优点
- 能够精确复制特定声音
- 增强的内容创作能力
- 为语言障碍者提供辅助解决方案的潜力
- 创建以已故艺术家克隆声音为特色的虚拟音乐会
- 提供语音银行服务以保留个人声音
- 可用于虚拟助手或个性化语音消息
缺点
- 关于同意和真实性的道德问题
- 可能被滥用于有害或误导性内容
- 存在版权和知识产权侵权的风险
- 需要大量高质量音频数据进行训练
- 克隆声音可能听起来不自然或机械
- 计算密集,需要强大的硬件或云端计算资源
人工智能语音克隆技术的关键功能
语音复制
人工智能语音克隆的核心功能是能够以惊人的准确性复制特定声音。人工智能模型分析音频数据以学习声音的独特特征,包括音调、音高、节奏和语调。一旦训练完成,模型可以生成克隆声音的新语音,即使是原始说话者从未实际说过的内容。这项功能使创建定制的有声书、个性化消息和听起来像特定人物的虚拟助手成为可能。
语音转换
语音转换是将一个人的声音转换为另一个人的声音的过程。这项技术允许你获取现有的音频录音并将说话者的声音更改为克隆的声音。语音转换可用于为视频创建配音、为电影配音以及生成不同语言的语音。该过程涉及分析源声音,然后应用目标声音的特征,创造出无缝且自然的声音转换。
人工智能语音克隆的用例
内容创作
人工智能语音克隆为内容创作开辟了新的可能性,允许你创建独特的音频体验。你可以克隆自己的声音以创建个性化消息、虚拟助手和教育内容。这项技术还允许为视频、有声书和播客生成配音。内容创作者可以利用人工智能语音克隆尝试不同的声音,创建脱颖而出的内容。
辅助功能
人工智能语音克隆为语言障碍者提供解决方案。通过克隆一个人的声音,可以创建辅助技术,使他们能够更有效地沟通。克隆技术还可用于提供语音银行服务,让人们在因医疗原因失去声音之前保留自己的声音。这项技术可以提高有沟通障碍个体的可访问性和包容性。
娱乐
人工智能语音克隆可用于创建新的娱乐形式。人工智能生成的声音可用于为电影配音、创建动画角色以及制作沉浸式游戏体验。这项技术还使创建以已故艺术家克隆声音为特色的虚拟音乐会成为可能。克隆技术为互动式故事讲述和个性化娱乐体验开辟了可能性,以满足个人偏好。
关于人工智能语音克隆的常见问题
人工智能语音克隆是否道德?
人工智能语音克隆的道德考量复杂,取决于技术的使用方式。获得被克隆者的同意至关重要。关于使用人工智能生成声音的透明度对于避免欺骗也至关重要。负责任地使用这项技术涉及尊重版权、知识产权,并避免创建有害或误导性内容。遵循这些道德准则将有助于确保人工智能语音克隆用于有益目的。
人工智能语音克隆的局限性是什么?
人工智能语音克隆并非没有局限性。克隆声音的质量取决于训练数据的数量和质量。模型可能难以复制具有复杂语音模式或口音的声音。如果没有适当优化,人工智能生成的声音可能听起来不自然或机械。此外,人工智能语音克隆可能需要强大的硬件或云端计算资源。随着技术的进步,许多这些局限性将得到解决。
我可以使用人工智能语音克隆进行商业项目吗?
你可以使用人工智能语音克隆进行商业项目。使用人工智能语音克隆进行商业项目的可行性和合法性取决于几个因素。确保你有权将音频数据用于克隆目的。遵守所有相关的版权和知识产权法律。对你的观众保持使用人工智能生成声音的透明度。通过解决这些问题,你可以在避免法律和道德陷阱的同时使用人工智能语音克隆进行商业项目。考虑购买和/或使用高级订阅以获得最佳商业应用。
与语音克隆相关的问题
什么是 Google Collab 以及它如何工作?
Google Collab 是 Google 提供的云端平台,允许你在协作环境中运行 Python 代码。它提供对包括 GPU 和 TPU 在内的强大计算资源的访问,使其成为机器学习项目的理想选择。Google Collab 通过提供 Jupyter 笔记本界面工作,你可以在其中编写和执行代码。你可以将文件上传到 Google Drive 并直接从 Collab 笔记本访问它们。此外,Google Collab 与其他 Google 服务集成,便于分享你的工作并与他人协作。Google Collab 免费使用,但存在使用限制。你可能需要升级到付费计划以获得更多资源和更长的运行时间。
在哪里可以找到用于克隆过程的人工智能语音模型?
人工智能语音模型可以从各种来源获得。一个选择是像 GitHub 这样的开源平台,开发者在其中分享他们的训练模型。另一个选择是通过专注于人工智能语音克隆的 Discord 服务器。请注意列为 SVC 模型的模型,因为那是与 RVC 完全不同的另一个过程。










 Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
 Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
Claude Opus 4.7 正式发布,将可靠性置于智能之上
Anthropic 今年保持着激进的开发节奏,几乎每隔一天就会推出新功能。备受期待的 Claude Opus 4.7 刚刚正式发布,有趣的是,Anthropic 在公告中直言不讳地表示:“这并非我们最强大的模型。” 传闻中更强大的 Claude Mythos Preview 仍处于待命状态。尽管如此,Opus 4.7 依然引发了广泛关注,因为它致力于解决“更可靠”而非“更智能”的问题。基准测试结果
 海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,
海尔推出全球最轻的人工智能运动外骨骼机器人,重量仅为1.75公斤
海尔集团推出了全球最轻的运动型人工智能外骨骼机器人——海尔外骨骼机器人W3。此次发布创下了行业轻量化新纪录,标志着在轻量化设计和智能人体运动增强领域取得了重大突破。高端材料成就超轻量化设计W3采用创新的一体化制造工艺,融合全碳纤维与钛合金。这种航空级材料组合将总重量控制在仅1.75公斤,实现了轻量化与高强度的完美平衡,展现出极致的机械性能。为提升舒适度,该机器人融入了非牛顿流体材料,触感柔软亲肤,

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

Die Stimmenklon-Technologie ist faszinierend, aber auch ein bisschen gruselig. Wer garantiert, dass meine Stimme nicht missbraucht wird? Trotzdem, die Anwendungen für Hörbücher oder persönliche Assistenten sind wirklich verlockend. 🎙️
声を複製できるって、正直ちょっと怖いですよね…プライバシーや悪用が心配です。でも、音楽やゲームのボイスキャラクターには役立ちそう!使い方次第な技術ですね😅
This guide on AI voice cloning is mind-blowing! 😮 The idea of creating realistic voices for audio projects feels like sci-fi magic. Can’t wait to try it out for my podcast!
This AI voice cloning guide is mind-blowing! 😮 The tech sounds like magic, but I wonder how it’ll impact voice actors’ jobs.
This AI voice cloning guide is mind-blowing! It’s wild to think we can recreate voices so realistically. I’m curious how this tech might change podcasting or even trick scammers. 😎 Anyone else worried about deepfake voices getting too good?













