




Gaia giới thiệu điểm chuẩn mới để tìm kiếm trí thông minh thực sự ngoài ARC-AGI
Trí thông minh ở khắp mọi nơi, nhưng việc đánh giá chính xác nó có cảm giác như đang cố gắng bắt một đám mây bằng bàn tay trần của bạn. Chúng tôi sử dụng các bài kiểm tra và điểm chuẩn, như các kỳ thi tuyển sinh đại học, để có được một ý tưởng sơ bộ. Mỗi năm, sinh viên nhồi nhét cho các bài kiểm tra này, đôi khi thậm chí đạt 100%hoàn hảo. Nhưng điểm số hoàn hảo đó có nghĩa là tất cả họ đều sở hữu cùng một mức độ thông minh hay họ đã đạt đến đỉnh điểm của tiềm năng tinh thần? Tất nhiên là không. Những điểm chuẩn này chỉ là ước tính sơ bộ, không phải là các chỉ số chính xác về khả năng thực sự của ai đó.
Trong thế giới của AI thế hệ, các điểm chuẩn như MMLU (hiểu ngôn ngữ đa nhiệm lớn) là cách đánh giá các mô hình thông qua các câu hỏi trắc nghiệm trên các lĩnh vực học thuật khác nhau. Mặc dù chúng cho phép so sánh dễ dàng, nhưng chúng không thực sự nắm bắt được toàn bộ các khả năng thông minh.
Lấy Claude 3.5 Sonnet và GPT-4.5 chẳng hạn. Họ có thể đạt điểm tương tự trên MMLU, cho thấy họ ngang hàng. Nhưng bất cứ ai thực sự đã sử dụng những mô hình này đều biết hiệu suất trong thế giới thực của họ đều có thể khá khác nhau.
Điều đó có nghĩa là gì khi đo 'trí thông minh' trong AI?
Với sự ra mắt gần đây của chuẩn mực ARC-AGI, được thiết kế để kiểm tra các mô hình về lý luận chung và giải quyết vấn đề sáng tạo, đã có một làn sóng thảo luận mới về ý nghĩa của việc đo lường "trí thông minh" trong AI. Không phải ai cũng có cơ hội đi sâu vào ARC-AGI, nhưng ngành công nghiệp đang xôn xao về điều này và các phương pháp mới để thử nghiệm. Mỗi điểm chuẩn đều có vị trí của nó, và ARC-AGI là một bước đi đúng hướng.
Một sự phát triển thú vị khác là 'Bài kiểm tra cuối cùng của loài người', một điểm chuẩn toàn diện với 3.000 câu hỏi được đánh giá ngang hàng, nhiều bước kéo dài các ngành khác nhau. Đó là một nỗ lực đầy tham vọng để đẩy các hệ thống AI sang lý luận cấp chuyên gia. Kết quả ban đầu cho thấy sự tiến bộ nhanh chóng, với Openai được báo cáo đạt điểm 26,6% chỉ một tháng sau khi phát hành. Nhưng giống như các điểm chuẩn khác, nó tập trung chủ yếu vào kiến thức và lý luận trong chân không, chứ không phải vào các kỹ năng sử dụng công cụ thực tế, rất quan trọng đối với các ứng dụng AI trong thế giới thực.
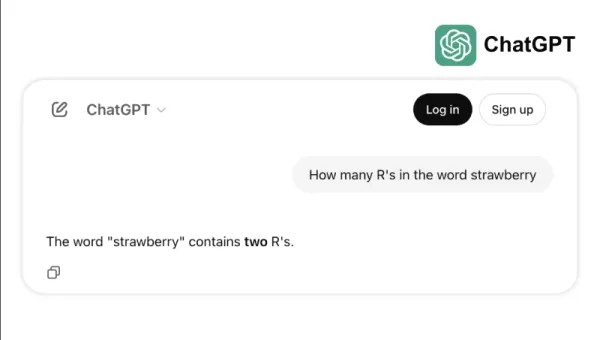
Lấy ví dụ, làm thế nào một số mô hình hàng đầu đấu tranh với các nhiệm vụ đơn giản như đếm "R" S trong "Dâu" hoặc so sánh 3,8 với 3.1111. Những lỗi này, ngay cả trẻ em hoặc máy tính cơ bản cũng có thể tránh được, làm nổi bật khoảng cách giữa thành công điểm chuẩn và độ tin cậy trong thế giới thực. Đó là một lời nhắc nhở rằng trí thông minh không chỉ là về các bài kiểm tra acing; Đó là về việc điều hướng logic hàng ngày một cách dễ dàng.
Tiêu chuẩn mới để đo khả năng AI
Khi các mô hình AI đã phát triển, những hạn chế của điểm chuẩn truyền thống đã trở nên rõ ràng hơn. Chẳng hạn, GPT-4, khi được trang bị các công cụ, chỉ có điểm khoảng 15% cho các nhiệm vụ trong thế giới thực phức tạp hơn trong điểm chuẩn Gaia, mặc dù điểm số cao trong các bài kiểm tra trắc nghiệm.
Sự khác biệt này giữa hiệu suất điểm chuẩn và khả năng thực tế ngày càng có vấn đề khi chuyển đổi hệ thống AI từ các phòng thí nghiệm nghiên cứu sang các ứng dụng kinh doanh. Kiểm tra điểm chuẩn truyền thống như thế nào một mô hình có thể nhớ lại thông tin nhưng thường bỏ qua các khía cạnh chính của trí thông minh, chẳng hạn như khả năng thu thập dữ liệu, chạy mã, phân tích thông tin và tạo các giải pháp trên các lĩnh vực khác nhau.
Nhập Gaia, một điểm chuẩn mới đánh dấu một sự thay đổi đáng kể trong đánh giá AI. Được phát triển thông qua sự hợp tác giữa các đội từ Meta-Fair, Meta-Genai, Huggingface và Autogpt, Gaia bao gồm 466 câu hỏi được chế tạo tỉ mỉ qua ba cấp độ khó. Những câu hỏi này kiểm tra một loạt các kỹ năng cần thiết cho các ứng dụng AI trong thế giới thực, bao gồm duyệt web, hiểu biết đa phương thức, thực thi mã, xử lý tệp và lý luận phức tạp.
Các câu hỏi cấp 1 thường yêu cầu khoảng 5 bước và một công cụ để con người giải quyết. Câu hỏi cấp 2 cần 5 đến 10 bước và nhiều công cụ, trong khi các câu hỏi cấp 3 có thể yêu cầu lên tới 50 bước và bất kỳ số lượng công cụ nào. Cấu trúc này phản ánh sự phức tạp của các vấn đề kinh doanh thực tế, trong đó các giải pháp thường liên quan đến nhiều hành động và công cụ.
Bằng cách tập trung vào tính linh hoạt thay vì chỉ là sự phức tạp, một mô hình AI đã đạt được tỷ lệ chính xác 75%trên GAIA, vượt trội hơn các nhà lãnh đạo trong ngành như Microsoft's Magic-1 (38%) và tác nhân Langfun của Google (49%). Thành công này xuất phát từ việc sử dụng hỗn hợp các mô hình chuyên dụng để hiểu và lý luận nghe nhìn, với Sonnet 3.5 của Anthropic làm mô hình chính.
Sự thay đổi trong đánh giá AI này phản ánh xu hướng rộng hơn trong ngành: Chúng tôi đang tránh xa các ứng dụng SaaS độc lập sang các tác nhân AI có thể quản lý nhiều công cụ và quy trình công việc. Khi các doanh nghiệp ngày càng phụ thuộc vào AI để giải quyết các nhiệm vụ phức tạp, nhiều bước, các điểm chuẩn như Gaia cung cấp một biện pháp khả năng phù hợp hơn so với các bài kiểm tra trắc nghiệm truyền thống.
Tương lai của đánh giá AI không phải về các bài kiểm tra kiến thức bị cô lập; Đó là về các đánh giá toàn diện về khả năng giải quyết vấn đề. Gaia thiết lập một điểm chuẩn mới để đo khả năng AI, một trong những điều chỉnh tốt hơn với các thách thức và cơ hội triển khai AI trong thế giới thực.
Sri Ambati là người sáng lập và CEO của H2O.AI.
Bài viết liên quan
 谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
Nhận xét (0)
0/200
谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
Nhận xét (0)
0/200
Trí thông minh ở khắp mọi nơi, nhưng việc đánh giá chính xác nó có cảm giác như đang cố gắng bắt một đám mây bằng bàn tay trần của bạn. Chúng tôi sử dụng các bài kiểm tra và điểm chuẩn, như các kỳ thi tuyển sinh đại học, để có được một ý tưởng sơ bộ. Mỗi năm, sinh viên nhồi nhét cho các bài kiểm tra này, đôi khi thậm chí đạt 100%hoàn hảo. Nhưng điểm số hoàn hảo đó có nghĩa là tất cả họ đều sở hữu cùng một mức độ thông minh hay họ đã đạt đến đỉnh điểm của tiềm năng tinh thần? Tất nhiên là không. Những điểm chuẩn này chỉ là ước tính sơ bộ, không phải là các chỉ số chính xác về khả năng thực sự của ai đó.
Trong thế giới của AI thế hệ, các điểm chuẩn như MMLU (hiểu ngôn ngữ đa nhiệm lớn) là cách đánh giá các mô hình thông qua các câu hỏi trắc nghiệm trên các lĩnh vực học thuật khác nhau. Mặc dù chúng cho phép so sánh dễ dàng, nhưng chúng không thực sự nắm bắt được toàn bộ các khả năng thông minh.
Lấy Claude 3.5 Sonnet và GPT-4.5 chẳng hạn. Họ có thể đạt điểm tương tự trên MMLU, cho thấy họ ngang hàng. Nhưng bất cứ ai thực sự đã sử dụng những mô hình này đều biết hiệu suất trong thế giới thực của họ đều có thể khá khác nhau.
Điều đó có nghĩa là gì khi đo 'trí thông minh' trong AI?
Với sự ra mắt gần đây của chuẩn mực ARC-AGI, được thiết kế để kiểm tra các mô hình về lý luận chung và giải quyết vấn đề sáng tạo, đã có một làn sóng thảo luận mới về ý nghĩa của việc đo lường "trí thông minh" trong AI. Không phải ai cũng có cơ hội đi sâu vào ARC-AGI, nhưng ngành công nghiệp đang xôn xao về điều này và các phương pháp mới để thử nghiệm. Mỗi điểm chuẩn đều có vị trí của nó, và ARC-AGI là một bước đi đúng hướng.
Một sự phát triển thú vị khác là 'Bài kiểm tra cuối cùng của loài người', một điểm chuẩn toàn diện với 3.000 câu hỏi được đánh giá ngang hàng, nhiều bước kéo dài các ngành khác nhau. Đó là một nỗ lực đầy tham vọng để đẩy các hệ thống AI sang lý luận cấp chuyên gia. Kết quả ban đầu cho thấy sự tiến bộ nhanh chóng, với Openai được báo cáo đạt điểm 26,6% chỉ một tháng sau khi phát hành. Nhưng giống như các điểm chuẩn khác, nó tập trung chủ yếu vào kiến thức và lý luận trong chân không, chứ không phải vào các kỹ năng sử dụng công cụ thực tế, rất quan trọng đối với các ứng dụng AI trong thế giới thực.
Lấy ví dụ, làm thế nào một số mô hình hàng đầu đấu tranh với các nhiệm vụ đơn giản như đếm "R" S trong "Dâu" hoặc so sánh 3,8 với 3.1111. Những lỗi này, ngay cả trẻ em hoặc máy tính cơ bản cũng có thể tránh được, làm nổi bật khoảng cách giữa thành công điểm chuẩn và độ tin cậy trong thế giới thực. Đó là một lời nhắc nhở rằng trí thông minh không chỉ là về các bài kiểm tra acing; Đó là về việc điều hướng logic hàng ngày một cách dễ dàng.
Tiêu chuẩn mới để đo khả năng AI
Khi các mô hình AI đã phát triển, những hạn chế của điểm chuẩn truyền thống đã trở nên rõ ràng hơn. Chẳng hạn, GPT-4, khi được trang bị các công cụ, chỉ có điểm khoảng 15% cho các nhiệm vụ trong thế giới thực phức tạp hơn trong điểm chuẩn Gaia, mặc dù điểm số cao trong các bài kiểm tra trắc nghiệm.
Sự khác biệt này giữa hiệu suất điểm chuẩn và khả năng thực tế ngày càng có vấn đề khi chuyển đổi hệ thống AI từ các phòng thí nghiệm nghiên cứu sang các ứng dụng kinh doanh. Kiểm tra điểm chuẩn truyền thống như thế nào một mô hình có thể nhớ lại thông tin nhưng thường bỏ qua các khía cạnh chính của trí thông minh, chẳng hạn như khả năng thu thập dữ liệu, chạy mã, phân tích thông tin và tạo các giải pháp trên các lĩnh vực khác nhau.
Nhập Gaia, một điểm chuẩn mới đánh dấu một sự thay đổi đáng kể trong đánh giá AI. Được phát triển thông qua sự hợp tác giữa các đội từ Meta-Fair, Meta-Genai, Huggingface và Autogpt, Gaia bao gồm 466 câu hỏi được chế tạo tỉ mỉ qua ba cấp độ khó. Những câu hỏi này kiểm tra một loạt các kỹ năng cần thiết cho các ứng dụng AI trong thế giới thực, bao gồm duyệt web, hiểu biết đa phương thức, thực thi mã, xử lý tệp và lý luận phức tạp.
Các câu hỏi cấp 1 thường yêu cầu khoảng 5 bước và một công cụ để con người giải quyết. Câu hỏi cấp 2 cần 5 đến 10 bước và nhiều công cụ, trong khi các câu hỏi cấp 3 có thể yêu cầu lên tới 50 bước và bất kỳ số lượng công cụ nào. Cấu trúc này phản ánh sự phức tạp của các vấn đề kinh doanh thực tế, trong đó các giải pháp thường liên quan đến nhiều hành động và công cụ.
Bằng cách tập trung vào tính linh hoạt thay vì chỉ là sự phức tạp, một mô hình AI đã đạt được tỷ lệ chính xác 75%trên GAIA, vượt trội hơn các nhà lãnh đạo trong ngành như Microsoft's Magic-1 (38%) và tác nhân Langfun của Google (49%). Thành công này xuất phát từ việc sử dụng hỗn hợp các mô hình chuyên dụng để hiểu và lý luận nghe nhìn, với Sonnet 3.5 của Anthropic làm mô hình chính.
Sự thay đổi trong đánh giá AI này phản ánh xu hướng rộng hơn trong ngành: Chúng tôi đang tránh xa các ứng dụng SaaS độc lập sang các tác nhân AI có thể quản lý nhiều công cụ và quy trình công việc. Khi các doanh nghiệp ngày càng phụ thuộc vào AI để giải quyết các nhiệm vụ phức tạp, nhiều bước, các điểm chuẩn như Gaia cung cấp một biện pháp khả năng phù hợp hơn so với các bài kiểm tra trắc nghiệm truyền thống.
Tương lai của đánh giá AI không phải về các bài kiểm tra kiến thức bị cô lập; Đó là về các đánh giá toàn diện về khả năng giải quyết vấn đề. Gaia thiết lập một điểm chuẩn mới để đo khả năng AI, một trong những điều chỉnh tốt hơn với các thách thức và cơ hội triển khai AI trong thế giới thực.
Sri Ambati là người sáng lập và CEO của H2O.AI.










 谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
 深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
 微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代













