
















 首頁
首頁蓋亞(Gaia
智能無處不在,但要精確衡量卻像徒手捕捉雲朵。我們使用考試和基準測試,例如大學入學考試,來粗略估計。每年,學生們為這些考試刻苦準備,有些甚至獲得滿分100%。但滿分是否意味著他們擁有相同的智能水平,或已達到心智潛能的頂峰?當然不是。這些基準只是粗略估計,並非某人真實能力的精確指標。
在生成式AI的世界中,MMLU(大規模多任務語言理解)等基準一直是通過多選題評估模型的首選,涵蓋多個學術領域。雖然它們便於比較,但無法完全捕捉智能能力的全部範圍。
以Claude 3.5 Sonnet和GPT-4.5為例,它們在MMLU上的得分可能相近,顯示它們不相上下。但實際使用這些模型的人都知道,它們在現實世界的表現可能大不相同。
衡量AI的「智能」意味著什麼?
隨著ARC-AGI基準的近期推出,旨在測試模型的通用推理和創意問題解決能力,關於AI「智能」測量的討論掀起新熱潮。雖然還不是每個人都體驗過ARC-AGI,但業界對此及其他新測試方法的討論熱烈。每個基準都有其價值,ARC-AGI是朝正確方向邁出的一步。
另一個令人興奮的發展是「人類的最後考試」,這是一個包含3,000道經過同行評審的多步驟問題的綜合基準,涵蓋不同學科。這是推動AI系統達到專家級推理的雄心勃勃努力。早期結果顯示進展迅速,據報導OpenAI在發布一個月後達到26.6%的得分。但與其他基準一樣,它主要聚焦於知識和孤立環境中的推理,而非對現實世界AI應用至關重要的實用工具使用技能。
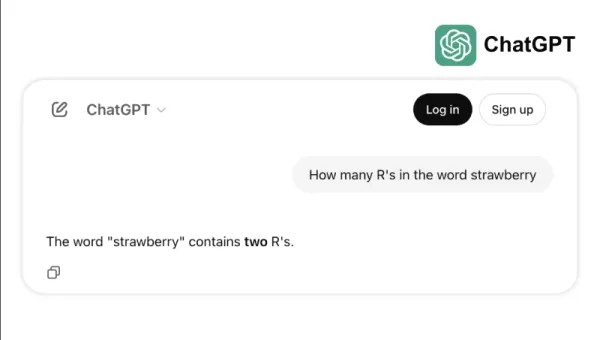
例如,一些頂尖模型在簡單任務上表現不佳,例如數「strawberry」中的「r」或比較3.8與3.1111。這些錯誤,即便是孩子或基本計算器也能避免,凸顯了基準成功與現實世界可靠性的差距。這提醒我們,智能不僅僅是考試得高分,而是輕鬆應對日常邏輯。
衡量AI能力的新標準
隨著AI模型的發展,傳統基準的局限性日益顯現。例如,GPT-4在配備工具時,於GAIA基準的更複雜現實世界任務中僅得分約15%,儘管其在多選題測試中得分很高。
基準表現與實際能力之間的差距在AI系統從研究實驗室轉向商業應用時愈發成問題。傳統基準測試模型的知識回憶能力,但常忽略智能的關鍵面向,例如收集數據、執行程式碼、分析資訊及跨領域創造解決方案的能力。
GAIA的出現標誌著AI評估的重大轉變。該基準由Meta-FAIR、Meta-GenAI、HuggingFace和AutoGPT團隊合作開發,包含466道精心設計的問題,分為三個難度等級。這些問題測試現實世界AI應用所需的多種技能,包括網頁瀏覽、多模態理解、程式碼執行、檔案處理和複雜推理。
第一級問題通常需要人類約5個步驟和一種工具來解決。第二級問題需要5至10個步驟和多種工具,而第三級問題可能需要多達50個步驟和任意數量的工具。這種結構反映了實際商業問題的複雜性,解決方案通常涉及多個動作和工具。
通過專注於靈活性而非僅僅複雜性,一個AI模型在GAIA上達到了75%的準確率,超越了業界領先者如Microsoft的Magnetic-1(38%)和Google的Langfun Agent(49%)。這一成功來自於使用專門的視聽理解和推理模型組合,以Anthropic的Sonnet 3.5為主要模型。
AI評估的轉變反映了業界的更廣泛趨勢:我們正從獨立的SaaS應用轉向能夠管理多種工具和工作流程的AI代理。隨著企業越來越依賴AI處理複雜的多步驟任務,GAIA等基準提供了比傳統多選題測試更相關的能力衡量標準。
AI評估的未來不再是孤立的知識測試,而是對問題解決能力的全面評估。GAIA為衡量AI能力設立了新標準——一個更符合AI部署現實挑戰與機遇的基準。
Sri Ambati 是 H2O.ai 的創始人兼首席執行官。
相關文章
 人工智慧揭露新聞內容中的隱藏議程
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。 這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。從喬納森·斯威夫特的《一個謙卑的建議》
Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
相關專題推薦
漫畫創作
人工智慧揭露新聞內容中的隱藏議程
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。 這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。從喬納森·斯威夫特的《一個謙卑的建議》
Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
相關專題推薦
漫畫創作
 少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
 15 個工具
15 個工具
 xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

 評論 (4)
0/500
評論 (4)
0/500
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
智能無處不在,但要精確衡量卻像徒手捕捉雲朵。我們使用考試和基準測試,例如大學入學考試,來粗略估計。每年,學生們為這些考試刻苦準備,有些甚至獲得滿分100%。但滿分是否意味著他們擁有相同的智能水平,或已達到心智潛能的頂峰?當然不是。這些基準只是粗略估計,並非某人真實能力的精確指標。
在生成式AI的世界中,MMLU(大規模多任務語言理解)等基準一直是通過多選題評估模型的首選,涵蓋多個學術領域。雖然它們便於比較,但無法完全捕捉智能能力的全部範圍。
以Claude 3.5 Sonnet和GPT-4.5為例,它們在MMLU上的得分可能相近,顯示它們不相上下。但實際使用這些模型的人都知道,它們在現實世界的表現可能大不相同。
衡量AI的「智能」意味著什麼?
隨著ARC-AGI基準的近期推出,旨在測試模型的通用推理和創意問題解決能力,關於AI「智能」測量的討論掀起新熱潮。雖然還不是每個人都體驗過ARC-AGI,但業界對此及其他新測試方法的討論熱烈。每個基準都有其價值,ARC-AGI是朝正確方向邁出的一步。
另一個令人興奮的發展是「人類的最後考試」,這是一個包含3,000道經過同行評審的多步驟問題的綜合基準,涵蓋不同學科。這是推動AI系統達到專家級推理的雄心勃勃努力。早期結果顯示進展迅速,據報導OpenAI在發布一個月後達到26.6%的得分。但與其他基準一樣,它主要聚焦於知識和孤立環境中的推理,而非對現實世界AI應用至關重要的實用工具使用技能。
例如,一些頂尖模型在簡單任務上表現不佳,例如數「strawberry」中的「r」或比較3.8與3.1111。這些錯誤,即便是孩子或基本計算器也能避免,凸顯了基準成功與現實世界可靠性的差距。這提醒我們,智能不僅僅是考試得高分,而是輕鬆應對日常邏輯。
衡量AI能力的新標準
隨著AI模型的發展,傳統基準的局限性日益顯現。例如,GPT-4在配備工具時,於GAIA基準的更複雜現實世界任務中僅得分約15%,儘管其在多選題測試中得分很高。
基準表現與實際能力之間的差距在AI系統從研究實驗室轉向商業應用時愈發成問題。傳統基準測試模型的知識回憶能力,但常忽略智能的關鍵面向,例如收集數據、執行程式碼、分析資訊及跨領域創造解決方案的能力。
GAIA的出現標誌著AI評估的重大轉變。該基準由Meta-FAIR、Meta-GenAI、HuggingFace和AutoGPT團隊合作開發,包含466道精心設計的問題,分為三個難度等級。這些問題測試現實世界AI應用所需的多種技能,包括網頁瀏覽、多模態理解、程式碼執行、檔案處理和複雜推理。
第一級問題通常需要人類約5個步驟和一種工具來解決。第二級問題需要5至10個步驟和多種工具,而第三級問題可能需要多達50個步驟和任意數量的工具。這種結構反映了實際商業問題的複雜性,解決方案通常涉及多個動作和工具。
通過專注於靈活性而非僅僅複雜性,一個AI模型在GAIA上達到了75%的準確率,超越了業界領先者如Microsoft的Magnetic-1(38%)和Google的Langfun Agent(49%)。這一成功來自於使用專門的視聽理解和推理模型組合,以Anthropic的Sonnet 3.5為主要模型。
AI評估的轉變反映了業界的更廣泛趨勢:我們正從獨立的SaaS應用轉向能夠管理多種工具和工作流程的AI代理。隨著企業越來越依賴AI處理複雜的多步驟任務,GAIA等基準提供了比傳統多選題測試更相關的能力衡量標準。
AI評估的未來不再是孤立的知識測試,而是對問題解決能力的全面評估。GAIA為衡量AI能力設立了新標準——一個更符合AI部署現實挑戰與機遇的基準。
Sri Ambati 是 H2O.ai 的創始人兼首席執行官。










 人工智慧揭露新聞內容中的隱藏議程
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。 這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。從喬納森·斯威夫特的《一個謙卑的建議》
人工智慧揭露新聞內容中的隱藏議程
ChatGPT風格的模型現正接受訓練,以揭示新聞文章背後的潛在觀點——即使該觀點被隱藏在引語、框架或(有時虛偽的)中立表象之下。透過將文章拆解為標題、導語和引語等段落,新型系統能識別長篇專業新聞報導中的偏見。 這種掌握作者或發言者真實立場的能力——學術文獻中稱為立場檢測——正挑戰語言解讀中最複雜的難題之一:從可能刻意設計用以隱藏或模糊意圖的內容中辨識真實意圖。從喬納森·斯威夫特的《一個謙卑的建議》
 Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
Anthropic的Claude 4.1在編碼基準測試中表現優異,搶先GPT-5發布
Anthropic於週一發布其旗艦人工智慧模型的升級版本,為軟體工程任務的效能樹立新標竿。此舉使這家人工智慧新創企業得以捍衛其在利潤豐厚的編碼領域的霸主地位,同時預見來自OpenAI的全新競爭挑戰。新版Claude Opus 4.1模型在SWE-bench Verified測試中獲得74.5%的分數,該測試是評估AI系統解決真實世界軟體問題能力的權威基準。此成績超越OpenAI o3模型的69.1
 Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百
Nvidia 推出具備可切換推理功能的開放原始碼 AI 模型 Nemotron-Nano-9B-v2
小型語言模型正掀起波瀾。 繼麻省理工學院衍生公司Liquid AI推出智慧手錶尺寸的視覺模型,以及Google推出適用於智慧型手機的產品後,Nvidia如今也以精簡版競爭者Nemotron-Nano-9B-V2進軍市場。此新型號在關鍵基準測試中領先同級產品,並引入獨特功能:使用者可啟用或停用AI「推理」機制——此機制實質上是在提供最終答案前進行自我檢查的流程。儘管90億參數規模仍高於近期報導的數百

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













