




Gaia представляет новый эталон в поисках истинного интеллекта за пределами Arc-Agi
Интеллект повсюду, но его точное измерение похоже на попытку поймать облако голыми руками. Мы используем тесты и эталоны, такие как вступительные экзамены в колледж, чтобы получить общее представление. Каждый год студенты готовятся к этим тестам, иногда даже набирая идеальные 100%. Но означает ли этот идеальный результат, что все они обладают одинаковым уровнем интеллекта или что они достигли пика своих умственных способностей? Конечно, нет. Эти эталоны — лишь приблизительные оценки, а не точные индикаторы истинных способностей человека.
В мире генеративного ИИ эталоны, такие как MMLU (Массивное многоцелевое понимание языка), стали основным инструментом для оценки моделей с помощью вопросов с множественным выбором по различным академическим дисциплинам. Хотя они позволяют легко сравнивать, они не охватывают полный спектр интеллектуальных возможностей.
Возьмем, к примеру, Claude 3.5 Sonnet и GPT-4.5. Они могут показать схожие результаты на MMLU, что говорит о том, что они на одном уровне. Но любой, кто действительно использовал эти модели, знает, что их реальная производительность может сильно различаться.
Что значит измерять «интеллект» в ИИ?
С недавним запуском эталона ARC-AGI, предназначенного для тестирования моделей на общее рассуждение и творческое решение проблем, началась новая волна обсуждений о том, что означает измерение «интеллекта» в ИИ. Не все еще успели изучить ARC-AGI, но в индустрии активно обсуждают этот и другие новые подходы к тестированию. Каждый эталон имеет свое место, и ARC-AGI — это шаг в правильном направлении.
Еще одно захватывающее событие — это «Последний экзамен человечества», комплексный эталон с 3000 рецензируемыми многоэтапными вопросами, охватывающими различные дисциплины. Это амбициозная попытка подтолкнуть системы ИИ к рассуждениям на уровне экспертов. Ранние результаты показывают быстрый прогресс: сообщается, что OpenAI достигла результата 26,6% всего через месяц после выпуска. Но, как и другие эталоны, он в основном сосредоточен на знаниях и рассуждениях в вакууме, а не на практических навыках использования инструментов, которые жизненно важны для реальных приложений ИИ.
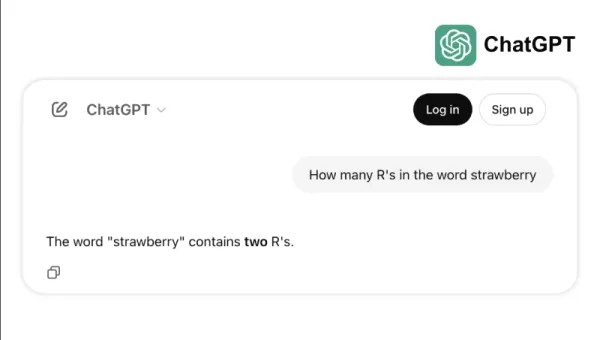
Возьмем, например, как некоторые ведущие модели с трудом справляются с простыми задачами, такими как подсчет букв «р» в слове «клубника» или сравнение чисел 3,8 и 3,1111. Эти ошибки, которых даже ребенок или простой калькулятор могли бы избежать, подчеркивают разрыв между успехом на эталонах и надежностью в реальном мире. Это напоминание о том, что интеллект — это не только успешное прохождение тестов, но и умение легко справляться с повседневной логикой.
Новый стандарт для измерения возможностей ИИ
По мере развития моделей ИИ ограничения традиционных эталонов становятся все более очевидными. Например, GPT-4, оснащенный инструментами, набирает всего около 15% на более сложных задачах реального мира в эталоне GAIA, несмотря на высокие результаты в тестах с множественным выбором.
Это несоответствие между производительностью на эталонах и практическими возможностями становится все более проблематичным по мере перехода систем ИИ из исследовательских лабораторий в бизнес-приложения. Традиционные эталоны тестируют, насколько хорошо модель может вспомнить информацию, но часто упускают ключевые аспекты интеллекта, такие как способность собирать данные, выполнять код, анализировать информацию и создавать решения в различных областях.
Появился GAIA, новый эталон, который знаменует значительный сдвиг в оценке ИИ. Разработанный в сотрудничестве между командами Meta-FAIR, Meta-GenAI, HuggingFace и AutoGPT, GAIA включает 466 тщательно разработанных вопросов на трех уровнях сложности. Эти вопросы тестируют широкий спектр навыков, необходимых для реальных приложений ИИ, включая веб-поиск, мультимодальное понимание, выполнение кода, работу с файлами и сложные рассуждения.
Вопросы уровня 1 обычно требуют около 5 шагов и одного инструмента для решения человеком. Вопросы уровня 2 требуют от 5 до 10 шагов и нескольких инструментов, а вопросы уровня 3 могут потребовать до 50 шагов и любого количества инструментов. Эта структура отражает сложность реальных бизнес-проблем, где решения часто включают множество действий и инструментов.
Сосредоточившись на гибкости, а не только на сложности, одна модель ИИ достигла точности 75% на GAIA, превзойдя лидеров отрасли, таких как Microsoft Magnetic-1 (38%) и Google Langfun Agent (49%). Этот успех достигнут благодаря использованию комбинации специализированных моделей для аудиовизуального понимания и рассуждений, с Anthropic Sonnet 3.5 в качестве основной модели.
Этот сдвиг в оценке ИИ отражает более широкую тенденцию в индустрии: мы отходим от автономных SaaS-приложений к агентам ИИ, которые могут управлять несколькими инструментами и рабочими процессами. По мере того как бизнес все больше полагается на ИИ для решения сложных многоэтапных задач, эталоны, такие как GAIA, предлагают более релевантную меру возможностей, чем традиционные тесты с множественным выбором.
Будущее оценки ИИ — это не изолированные тесты знаний; это комплексные оценки способности решать проблемы. GAIA устанавливает новый эталон для измерения возможностей ИИ — тот, который лучше соответствует реальным вызовам и возможностям внедрения ИИ.
Сри Амбати — основатель и генеральный директор H2O.ai.
Связанная статья
 TensorZero получила $7,3M начального финансирования для упрощения разработки корпоративных LLM
TensorZero, новый поставщик инфраструктуры с открытым исходным кодом для приложений искусственного интеллекта, получил $7,3 млн начального финансирования под руководством FirstMark Capital, при участи
Генеральный директор Replit прогнозирует будущее программного обеспечения: "Агенты все ниже и ниже
Могут ли совместные платформы для разработки ИИ позволить предприятиям отказаться от дорогостоящих SaaS-подписок? Генеральный директор Replit Амджад Масад считает, что такая трансформация уже происход
OpenAI обновляет ChatGPT Pro до версии o3, повышая ценность ежемесячной подписки стоимостью $200
На этой неделе технологические гиганты, включая Microsoft, Google и Anthropic, представили значительные разработки в области ИИ. OpenAI завершает шквал анонсов собственными революционными обновлениями
Комментарии (2)
TensorZero получила $7,3M начального финансирования для упрощения разработки корпоративных LLM
TensorZero, новый поставщик инфраструктуры с открытым исходным кодом для приложений искусственного интеллекта, получил $7,3 млн начального финансирования под руководством FirstMark Capital, при участи
Генеральный директор Replit прогнозирует будущее программного обеспечения: "Агенты все ниже и ниже
Могут ли совместные платформы для разработки ИИ позволить предприятиям отказаться от дорогостоящих SaaS-подписок? Генеральный директор Replit Амджад Масад считает, что такая трансформация уже происход
OpenAI обновляет ChatGPT Pro до версии o3, повышая ценность ежемесячной подписки стоимостью $200
На этой неделе технологические гиганты, включая Microsoft, Google и Anthropic, представили значительные разработки в области ИИ. OpenAI завершает шквал анонсов собственными революционными обновлениями
Комментарии (2)
![BillyAdams]() BillyAdams
BillyAdams
 26 августа 2025 г., 11:25:46 GMT+03:00
26 августа 2025 г., 11:25:46 GMT+03:00
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?


 0
0
![GaryThomas]() GaryThomas
8 августа 2025 г., 7:01:29 GMT+03:00
GaryThomas
8 августа 2025 г., 7:01:29 GMT+03:00
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0
Интеллект повсюду, но его точное измерение похоже на попытку поймать облако голыми руками. Мы используем тесты и эталоны, такие как вступительные экзамены в колледж, чтобы получить общее представление. Каждый год студенты готовятся к этим тестам, иногда даже набирая идеальные 100%. Но означает ли этот идеальный результат, что все они обладают одинаковым уровнем интеллекта или что они достигли пика своих умственных способностей? Конечно, нет. Эти эталоны — лишь приблизительные оценки, а не точные индикаторы истинных способностей человека.
В мире генеративного ИИ эталоны, такие как MMLU (Массивное многоцелевое понимание языка), стали основным инструментом для оценки моделей с помощью вопросов с множественным выбором по различным академическим дисциплинам. Хотя они позволяют легко сравнивать, они не охватывают полный спектр интеллектуальных возможностей.
Возьмем, к примеру, Claude 3.5 Sonnet и GPT-4.5. Они могут показать схожие результаты на MMLU, что говорит о том, что они на одном уровне. Но любой, кто действительно использовал эти модели, знает, что их реальная производительность может сильно различаться.
Что значит измерять «интеллект» в ИИ?
С недавним запуском эталона ARC-AGI, предназначенного для тестирования моделей на общее рассуждение и творческое решение проблем, началась новая волна обсуждений о том, что означает измерение «интеллекта» в ИИ. Не все еще успели изучить ARC-AGI, но в индустрии активно обсуждают этот и другие новые подходы к тестированию. Каждый эталон имеет свое место, и ARC-AGI — это шаг в правильном направлении.
Еще одно захватывающее событие — это «Последний экзамен человечества», комплексный эталон с 3000 рецензируемыми многоэтапными вопросами, охватывающими различные дисциплины. Это амбициозная попытка подтолкнуть системы ИИ к рассуждениям на уровне экспертов. Ранние результаты показывают быстрый прогресс: сообщается, что OpenAI достигла результата 26,6% всего через месяц после выпуска. Но, как и другие эталоны, он в основном сосредоточен на знаниях и рассуждениях в вакууме, а не на практических навыках использования инструментов, которые жизненно важны для реальных приложений ИИ.
Возьмем, например, как некоторые ведущие модели с трудом справляются с простыми задачами, такими как подсчет букв «р» в слове «клубника» или сравнение чисел 3,8 и 3,1111. Эти ошибки, которых даже ребенок или простой калькулятор могли бы избежать, подчеркивают разрыв между успехом на эталонах и надежностью в реальном мире. Это напоминание о том, что интеллект — это не только успешное прохождение тестов, но и умение легко справляться с повседневной логикой.
Новый стандарт для измерения возможностей ИИ
По мере развития моделей ИИ ограничения традиционных эталонов становятся все более очевидными. Например, GPT-4, оснащенный инструментами, набирает всего около 15% на более сложных задачах реального мира в эталоне GAIA, несмотря на высокие результаты в тестах с множественным выбором.
Это несоответствие между производительностью на эталонах и практическими возможностями становится все более проблематичным по мере перехода систем ИИ из исследовательских лабораторий в бизнес-приложения. Традиционные эталоны тестируют, насколько хорошо модель может вспомнить информацию, но часто упускают ключевые аспекты интеллекта, такие как способность собирать данные, выполнять код, анализировать информацию и создавать решения в различных областях.
Появился GAIA, новый эталон, который знаменует значительный сдвиг в оценке ИИ. Разработанный в сотрудничестве между командами Meta-FAIR, Meta-GenAI, HuggingFace и AutoGPT, GAIA включает 466 тщательно разработанных вопросов на трех уровнях сложности. Эти вопросы тестируют широкий спектр навыков, необходимых для реальных приложений ИИ, включая веб-поиск, мультимодальное понимание, выполнение кода, работу с файлами и сложные рассуждения.
Вопросы уровня 1 обычно требуют около 5 шагов и одного инструмента для решения человеком. Вопросы уровня 2 требуют от 5 до 10 шагов и нескольких инструментов, а вопросы уровня 3 могут потребовать до 50 шагов и любого количества инструментов. Эта структура отражает сложность реальных бизнес-проблем, где решения часто включают множество действий и инструментов.
Сосредоточившись на гибкости, а не только на сложности, одна модель ИИ достигла точности 75% на GAIA, превзойдя лидеров отрасли, таких как Microsoft Magnetic-1 (38%) и Google Langfun Agent (49%). Этот успех достигнут благодаря использованию комбинации специализированных моделей для аудиовизуального понимания и рассуждений, с Anthropic Sonnet 3.5 в качестве основной модели.
Этот сдвиг в оценке ИИ отражает более широкую тенденцию в индустрии: мы отходим от автономных SaaS-приложений к агентам ИИ, которые могут управлять несколькими инструментами и рабочими процессами. По мере того как бизнес все больше полагается на ИИ для решения сложных многоэтапных задач, эталоны, такие как GAIA, предлагают более релевантную меру возможностей, чем традиционные тесты с множественным выбором.
Будущее оценки ИИ — это не изолированные тесты знаний; это комплексные оценки способности решать проблемы. GAIA устанавливает новый эталон для измерения возможностей ИИ — тот, который лучше соответствует реальным вызовам и возможностям внедрения ИИ.
Сри Амбати — основатель и генеральный директор H2O.ai.










 TensorZero получила $7,3M начального финансирования для упрощения разработки корпоративных LLM
TensorZero, новый поставщик инфраструктуры с открытым исходным кодом для приложений искусственного интеллекта, получил $7,3 млн начального финансирования под руководством FirstMark Capital, при участи
TensorZero получила $7,3M начального финансирования для упрощения разработки корпоративных LLM
TensorZero, новый поставщик инфраструктуры с открытым исходным кодом для приложений искусственного интеллекта, получил $7,3 млн начального финансирования под руководством FirstMark Capital, при участи
 Генеральный директор Replit прогнозирует будущее программного обеспечения: "Агенты все ниже и ниже
Могут ли совместные платформы для разработки ИИ позволить предприятиям отказаться от дорогостоящих SaaS-подписок? Генеральный директор Replit Амджад Масад считает, что такая трансформация уже происход
Генеральный директор Replit прогнозирует будущее программного обеспечения: "Агенты все ниже и ниже
Могут ли совместные платформы для разработки ИИ позволить предприятиям отказаться от дорогостоящих SaaS-подписок? Генеральный директор Replit Амджад Масад считает, что такая трансформация уже происход
 OpenAI обновляет ChatGPT Pro до версии o3, повышая ценность ежемесячной подписки стоимостью $200
На этой неделе технологические гиганты, включая Microsoft, Google и Anthropic, представили значительные разработки в области ИИ. OpenAI завершает шквал анонсов собственными революционными обновлениями
26 августа 2025 г., 11:25:46 GMT+03:00
OpenAI обновляет ChatGPT Pro до версии o3, повышая ценность ежемесячной подписки стоимостью $200
На этой неделе технологические гиганты, включая Microsoft, Google и Anthropic, представили значительные разработки в области ИИ. OpenAI завершает шквал анонсов собственными революционными обновлениями
26 августа 2025 г., 11:25:46 GMT+03:00
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
0
8 августа 2025 г., 7:01:29 GMT+03:00
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0













