




गैया ने आर्क-एगी से परे ट्रू इंटेलिजेंस फॉर ट्रू इंटेलिजेंस में नए बेंचमार्क का परिचय दिया
इंटेलिजेंस हर जगह है, फिर भी यह सही ढंग से महसूस करता है कि अपने नंगे हाथों से बादल को पकड़ने की कोशिश कर रहा है। हम एक मोटे विचार प्राप्त करने के लिए, कॉलेज प्रवेश परीक्षा जैसे परीक्षण और बेंचमार्क का उपयोग करते हैं। प्रत्येक वर्ष, छात्रों को इन परीक्षणों के लिए रमण, कभी -कभी एक सही 100%भी स्कोर करता है। लेकिन क्या उस सही स्कोर का मतलब है कि वे सभी एक समान स्तर की बुद्धि के अधिकारी हैं या वे अपनी मानसिक क्षमता के चरम पर पहुंच गए हैं? बिल्कुल नहीं। ये बेंचमार्क केवल मोटे अनुमान हैं, न कि किसी की सच्ची क्षमताओं के सटीक संकेतक।
जेनेरिक एआई की दुनिया में, MMLU (बड़े पैमाने पर मल्टीटास्क लैंग्वेज अंडरस्टैंडिंग) जैसे बेंचमार्क विभिन्न शैक्षणिक क्षेत्रों में बहुविकल्पीय प्रश्नों के माध्यम से मॉडल का आकलन करने के लिए गो-टू हैं। जबकि वे आसान तुलना के लिए अनुमति देते हैं, वे वास्तव में बुद्धिमान क्षमताओं के पूर्ण स्पेक्ट्रम पर कब्जा नहीं करते हैं।
उदाहरण के लिए, क्लाउड 3.5 SONNET और GPT-4.5 लें। वे MMLU पर समान रूप से स्कोर कर सकते हैं, सुझाव देते हैं कि वे बराबर हैं। लेकिन जो कोई भी वास्तव में इन मॉडलों का उपयोग करता है वह जानता है कि उनके वास्तविक दुनिया का प्रदर्शन काफी अलग हो सकता है।
एआई में 'बुद्धि' को मापने का क्या मतलब है?
एआरसी-एजीआई बेंचमार्क के हालिया लॉन्च के साथ, सामान्य तर्क और रचनात्मक समस्या-समाधान पर मॉडल का परीक्षण करने के लिए डिज़ाइन किया गया है, एआई में "बुद्धिमत्ता" को मापने के लिए इसका क्या मतलब है, इसके बारे में चर्चा की एक नई लहर है। सभी को अभी तक आर्क-एजी में गोता लगाने का मौका नहीं मिला है, लेकिन उद्योग इस और परीक्षण के लिए अन्य नए दृष्टिकोणों के बारे में चर्चा कर रहा है। प्रत्येक बेंचमार्क की अपनी जगह होती है, और आर्क-एगी सही दिशा में एक कदम है।
एक अन्य रोमांचक विकास 'मानवता की अंतिम परीक्षा' है, जो 3,000 सहकर्मी-समीक्षा, बहु-चरणीय प्रश्नों के साथ एक व्यापक बेंचमार्क है, जो विभिन्न विषयों में फैले हुए हैं। यह एआई सिस्टम को विशेषज्ञ-स्तरीय तर्क के लिए धकेलने का एक महत्वाकांक्षी प्रयास है। शुरुआती परिणाम तेजी से प्रगति दिखाते हैं, ओपनईआई ने कथित तौर पर रिलीज होने के एक महीने बाद 26.6% स्कोर को हिट किया। लेकिन अन्य बेंचमार्क की तरह, यह मुख्य रूप से एक वैक्यूम में ज्ञान और तर्क पर ध्यान केंद्रित करता है, न कि व्यावहारिक, उपकरण-उपयोग करने वाले कौशल पर जो वास्तविक दुनिया एआई अनुप्रयोगों के लिए महत्वपूर्ण हैं।
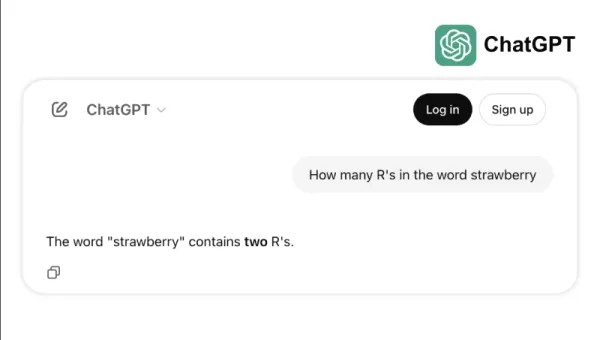
उदाहरण के लिए, कैसे कुछ शीर्ष मॉडल "स्ट्रॉबेरी" में "आर" एस को गिनने या 3.8 से 3.1111 की तुलना करने जैसे सरल कार्यों के साथ संघर्ष करते हैं। ये त्रुटियां, जो एक बच्चा या एक बुनियादी कैलकुलेटर भी बच सकते हैं, बेंचमार्क सफलता और वास्तविक दुनिया की विश्वसनीयता के बीच की खाई को उजागर कर सकते हैं। यह एक अनुस्मारक है कि बुद्धिमत्ता सिर्फ एसिंग परीक्षणों के बारे में नहीं है; यह आसानी से रोजमर्रा के तर्क को नेविगेट करने के बारे में है।
एआई क्षमता को मापने के लिए नया मानक
जैसा कि एआई मॉडल विकसित हुए हैं, पारंपरिक बेंचमार्क की सीमाएं अधिक स्पष्ट हो गई हैं। उदाहरण के लिए, GPT-4, जब उपकरणों से लैस होता है, केवल गैया बेंचमार्क में अधिक जटिल, वास्तविक दुनिया के कार्यों पर लगभग 15% स्कोर करता है, तो बहुविकल्पीय परीक्षणों पर इसके उच्च स्कोर के बावजूद।
बेंचमार्क प्रदर्शन और व्यावहारिक क्षमता के बीच यह विसंगति तेजी से समस्याग्रस्त है क्योंकि अनुसंधान प्रयोगशालाओं से व्यावसायिक अनुप्रयोगों में एआई सिस्टम संक्रमण है। पारंपरिक बेंचमार्क परीक्षण करते हैं कि कोई मॉडल कितनी अच्छी तरह से जानकारी को याद कर सकता है, लेकिन अक्सर बुद्धिमत्ता के प्रमुख पहलुओं को नजरअंदाज कर सकता है, जैसे कि डेटा इकट्ठा करने, कोड चलाने, जानकारी का विश्लेषण करने और विभिन्न डोमेन में समाधान बनाने की क्षमता।
गैया दर्ज करें, एक नया बेंचमार्क जो एआई मूल्यांकन में एक महत्वपूर्ण बदलाव को चिह्नित करता है। मेटा-फेयर, मेटा-गेनाई, हगिंगफेस और ऑटोगेप्ट की टीमों के बीच एक सहयोग के माध्यम से विकसित, गैया में तीन कठिनाई स्तरों में 466 सावधानीपूर्वक तैयार किए गए प्रश्न शामिल हैं। ये प्रश्न वास्तविक दुनिया एआई अनुप्रयोगों के लिए आवश्यक कौशल की एक विस्तृत श्रृंखला का परीक्षण करते हैं, जिसमें वेब ब्राउज़िंग, मल्टी-मोडल समझ, कोड निष्पादन, फ़ाइल हैंडलिंग और जटिल तर्क शामिल हैं।
स्तर 1 के प्रश्नों को आमतौर पर लगभग 5 चरणों और मनुष्यों को हल करने के लिए एक उपकरण की आवश्यकता होती है। स्तर 2 के प्रश्नों को 5 से 10 चरणों और कई उपकरणों की आवश्यकता होती है, जबकि स्तर 3 प्रश्न 50 चरणों और किसी भी संख्या में उपकरण की मांग कर सकते हैं। यह संरचना वास्तविक व्यावसायिक समस्याओं की जटिलता को दर्शाती है, जहां समाधान अक्सर कई क्रियाओं और उपकरणों को शामिल करते हैं।
केवल जटिलता के बजाय लचीलेपन पर ध्यान केंद्रित करके, एक एआई मॉडल ने GAIA पर 75%सटीकता दर हासिल की, जो Microsoft के चुंबकीय -1 (38%) और Google के लैंगफुन एजेंट (49%) जैसे उद्योग के नेताओं से बेहतर प्रदर्शन कर रहा था। यह सफलता ऑडियो-विजुअल समझ और तर्क के लिए विशेष मॉडल के मिश्रण का उपयोग करने से आती है, मुख्य मॉडल के रूप में एन्थ्रोपिक के सॉनेट 3.5 के साथ।
एआई मूल्यांकन में यह बदलाव उद्योग में एक व्यापक प्रवृत्ति को दर्शाता है: हम एआई एजेंटों की ओर स्टैंडअलोन सास अनुप्रयोगों से दूर जा रहे हैं जो कई उपकरणों और वर्कफ़्लो का प्रबंधन कर सकते हैं। चूंकि व्यवसाय तेजी से कॉम्प्लेक्स, मल्टी-स्टेप कार्यों से निपटने के लिए एआई पर निर्भर करते हैं, गिया जैसे बेंचमार्क पारंपरिक बहुविकल्पीय परीक्षणों की तुलना में क्षमता का अधिक प्रासंगिक उपाय प्रदान करते हैं।
एआई मूल्यांकन का भविष्य पृथक ज्ञान परीक्षणों के बारे में नहीं है; यह समस्या-समाधान क्षमता के व्यापक आकलन के बारे में है। गैया एआई क्षमता को मापने के लिए एक नया बेंचमार्क सेट करता है-एक जो वास्तविक दुनिया की चुनौतियों और एआई तैनाती के अवसरों के साथ बेहतर संरेखित करता है।
श्री अंबाती H2O.AI के संस्थापक और सीईओ हैं।
संबंधित लेख
 谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
सूचना (0)
0/200
谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
सूचना (0)
0/200
इंटेलिजेंस हर जगह है, फिर भी यह सही ढंग से महसूस करता है कि अपने नंगे हाथों से बादल को पकड़ने की कोशिश कर रहा है। हम एक मोटे विचार प्राप्त करने के लिए, कॉलेज प्रवेश परीक्षा जैसे परीक्षण और बेंचमार्क का उपयोग करते हैं। प्रत्येक वर्ष, छात्रों को इन परीक्षणों के लिए रमण, कभी -कभी एक सही 100%भी स्कोर करता है। लेकिन क्या उस सही स्कोर का मतलब है कि वे सभी एक समान स्तर की बुद्धि के अधिकारी हैं या वे अपनी मानसिक क्षमता के चरम पर पहुंच गए हैं? बिल्कुल नहीं। ये बेंचमार्क केवल मोटे अनुमान हैं, न कि किसी की सच्ची क्षमताओं के सटीक संकेतक।
जेनेरिक एआई की दुनिया में, MMLU (बड़े पैमाने पर मल्टीटास्क लैंग्वेज अंडरस्टैंडिंग) जैसे बेंचमार्क विभिन्न शैक्षणिक क्षेत्रों में बहुविकल्पीय प्रश्नों के माध्यम से मॉडल का आकलन करने के लिए गो-टू हैं। जबकि वे आसान तुलना के लिए अनुमति देते हैं, वे वास्तव में बुद्धिमान क्षमताओं के पूर्ण स्पेक्ट्रम पर कब्जा नहीं करते हैं।
उदाहरण के लिए, क्लाउड 3.5 SONNET और GPT-4.5 लें। वे MMLU पर समान रूप से स्कोर कर सकते हैं, सुझाव देते हैं कि वे बराबर हैं। लेकिन जो कोई भी वास्तव में इन मॉडलों का उपयोग करता है वह जानता है कि उनके वास्तविक दुनिया का प्रदर्शन काफी अलग हो सकता है।
एआई में 'बुद्धि' को मापने का क्या मतलब है?
एआरसी-एजीआई बेंचमार्क के हालिया लॉन्च के साथ, सामान्य तर्क और रचनात्मक समस्या-समाधान पर मॉडल का परीक्षण करने के लिए डिज़ाइन किया गया है, एआई में "बुद्धिमत्ता" को मापने के लिए इसका क्या मतलब है, इसके बारे में चर्चा की एक नई लहर है। सभी को अभी तक आर्क-एजी में गोता लगाने का मौका नहीं मिला है, लेकिन उद्योग इस और परीक्षण के लिए अन्य नए दृष्टिकोणों के बारे में चर्चा कर रहा है। प्रत्येक बेंचमार्क की अपनी जगह होती है, और आर्क-एगी सही दिशा में एक कदम है।
एक अन्य रोमांचक विकास 'मानवता की अंतिम परीक्षा' है, जो 3,000 सहकर्मी-समीक्षा, बहु-चरणीय प्रश्नों के साथ एक व्यापक बेंचमार्क है, जो विभिन्न विषयों में फैले हुए हैं। यह एआई सिस्टम को विशेषज्ञ-स्तरीय तर्क के लिए धकेलने का एक महत्वाकांक्षी प्रयास है। शुरुआती परिणाम तेजी से प्रगति दिखाते हैं, ओपनईआई ने कथित तौर पर रिलीज होने के एक महीने बाद 26.6% स्कोर को हिट किया। लेकिन अन्य बेंचमार्क की तरह, यह मुख्य रूप से एक वैक्यूम में ज्ञान और तर्क पर ध्यान केंद्रित करता है, न कि व्यावहारिक, उपकरण-उपयोग करने वाले कौशल पर जो वास्तविक दुनिया एआई अनुप्रयोगों के लिए महत्वपूर्ण हैं।
उदाहरण के लिए, कैसे कुछ शीर्ष मॉडल "स्ट्रॉबेरी" में "आर" एस को गिनने या 3.8 से 3.1111 की तुलना करने जैसे सरल कार्यों के साथ संघर्ष करते हैं। ये त्रुटियां, जो एक बच्चा या एक बुनियादी कैलकुलेटर भी बच सकते हैं, बेंचमार्क सफलता और वास्तविक दुनिया की विश्वसनीयता के बीच की खाई को उजागर कर सकते हैं। यह एक अनुस्मारक है कि बुद्धिमत्ता सिर्फ एसिंग परीक्षणों के बारे में नहीं है; यह आसानी से रोजमर्रा के तर्क को नेविगेट करने के बारे में है।
एआई क्षमता को मापने के लिए नया मानक
जैसा कि एआई मॉडल विकसित हुए हैं, पारंपरिक बेंचमार्क की सीमाएं अधिक स्पष्ट हो गई हैं। उदाहरण के लिए, GPT-4, जब उपकरणों से लैस होता है, केवल गैया बेंचमार्क में अधिक जटिल, वास्तविक दुनिया के कार्यों पर लगभग 15% स्कोर करता है, तो बहुविकल्पीय परीक्षणों पर इसके उच्च स्कोर के बावजूद।
बेंचमार्क प्रदर्शन और व्यावहारिक क्षमता के बीच यह विसंगति तेजी से समस्याग्रस्त है क्योंकि अनुसंधान प्रयोगशालाओं से व्यावसायिक अनुप्रयोगों में एआई सिस्टम संक्रमण है। पारंपरिक बेंचमार्क परीक्षण करते हैं कि कोई मॉडल कितनी अच्छी तरह से जानकारी को याद कर सकता है, लेकिन अक्सर बुद्धिमत्ता के प्रमुख पहलुओं को नजरअंदाज कर सकता है, जैसे कि डेटा इकट्ठा करने, कोड चलाने, जानकारी का विश्लेषण करने और विभिन्न डोमेन में समाधान बनाने की क्षमता।
गैया दर्ज करें, एक नया बेंचमार्क जो एआई मूल्यांकन में एक महत्वपूर्ण बदलाव को चिह्नित करता है। मेटा-फेयर, मेटा-गेनाई, हगिंगफेस और ऑटोगेप्ट की टीमों के बीच एक सहयोग के माध्यम से विकसित, गैया में तीन कठिनाई स्तरों में 466 सावधानीपूर्वक तैयार किए गए प्रश्न शामिल हैं। ये प्रश्न वास्तविक दुनिया एआई अनुप्रयोगों के लिए आवश्यक कौशल की एक विस्तृत श्रृंखला का परीक्षण करते हैं, जिसमें वेब ब्राउज़िंग, मल्टी-मोडल समझ, कोड निष्पादन, फ़ाइल हैंडलिंग और जटिल तर्क शामिल हैं।
स्तर 1 के प्रश्नों को आमतौर पर लगभग 5 चरणों और मनुष्यों को हल करने के लिए एक उपकरण की आवश्यकता होती है। स्तर 2 के प्रश्नों को 5 से 10 चरणों और कई उपकरणों की आवश्यकता होती है, जबकि स्तर 3 प्रश्न 50 चरणों और किसी भी संख्या में उपकरण की मांग कर सकते हैं। यह संरचना वास्तविक व्यावसायिक समस्याओं की जटिलता को दर्शाती है, जहां समाधान अक्सर कई क्रियाओं और उपकरणों को शामिल करते हैं।
केवल जटिलता के बजाय लचीलेपन पर ध्यान केंद्रित करके, एक एआई मॉडल ने GAIA पर 75%सटीकता दर हासिल की, जो Microsoft के चुंबकीय -1 (38%) और Google के लैंगफुन एजेंट (49%) जैसे उद्योग के नेताओं से बेहतर प्रदर्शन कर रहा था। यह सफलता ऑडियो-विजुअल समझ और तर्क के लिए विशेष मॉडल के मिश्रण का उपयोग करने से आती है, मुख्य मॉडल के रूप में एन्थ्रोपिक के सॉनेट 3.5 के साथ।
एआई मूल्यांकन में यह बदलाव उद्योग में एक व्यापक प्रवृत्ति को दर्शाता है: हम एआई एजेंटों की ओर स्टैंडअलोन सास अनुप्रयोगों से दूर जा रहे हैं जो कई उपकरणों और वर्कफ़्लो का प्रबंधन कर सकते हैं। चूंकि व्यवसाय तेजी से कॉम्प्लेक्स, मल्टी-स्टेप कार्यों से निपटने के लिए एआई पर निर्भर करते हैं, गिया जैसे बेंचमार्क पारंपरिक बहुविकल्पीय परीक्षणों की तुलना में क्षमता का अधिक प्रासंगिक उपाय प्रदान करते हैं।
एआई मूल्यांकन का भविष्य पृथक ज्ञान परीक्षणों के बारे में नहीं है; यह समस्या-समाधान क्षमता के व्यापक आकलन के बारे में है। गैया एआई क्षमता को मापने के लिए एक नया बेंचमार्क सेट करता है-एक जो वास्तविक दुनिया की चुनौतियों और एआई तैनाती के अवसरों के साथ बेहतर संरेखित करता है।
श्री अंबाती H2O.AI के संस्थापक और सीईओ हैं।










 谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
谷歌AI躍升內幕:Gemini 2.5 思維更深、表達更智能且編碼更快
谷歌朝著通用AI助手的願景邁進一步在今年的Google I/O大會上,該公司揭示了其Gemini 2.5系列的重大升級,特別是在多個維度上提升其能力。最新的版本——Gemini 2.5 Flash和2.5 Pro——現在比以往更加聰明和高效。這些進步使谷歌更接近實現其創造通用AI助手的願景,這個助手能夠無縫理解情境、計劃並執行任務。### Gemini 2.
 深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
深度認知發布開源AI模型,已名列前茅
深度思睿推出革命性的人工智能模型旧金山一家尖端的人工智能研究初创公司深度思睿(Deep Cogito)正式发布了其首批开源大型语言模型(LLMs),命名为思睿v1。这些模型经过微调自Meta的Llama 3.2,具备混合推理能力,能够快速响应或进行内省思考——这一功能让人联想到OpenAI的“o”系列和DeepSeek R1。深度思睿旨在通过在其模型中促进迭
 微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代
微軟在Build 2025大會上宣布推出超過50款AI工具打造『主動網路』
微軟於Build大會揭開開放式自主網路願景今天早上,微軟在其年度Build大會上發表了一項大膽宣言:「開放式自主網路」的黎明已經到來。在超過50項公告的廣泛陣容中,這家科技巨頭概述了一項全面策略,將自己置於這個轉型運動的核心位置。從GitHub到Azure,從Windows到Microsoft 365,每條產品線都收到了旨在推動AI代理技術進步的更新。這些代













