
















 首页
首页盖亚(Gaia
智能无处不在,但要精确衡量它却像试图用双手抓住云彩。我们使用考试和基准测试,如大学入学考试,来大致了解情况。每年,学生们为这些考试拼命复习,有时甚至能考到满分100%。但满分是否意味着他们都拥有相同的智能水平,或者已经达到了他们的智力巅峰?当然不是。这些基准测试只是粗略的估计,并非某人真实能力的精确指标。
在生成式AI领域,MMLU(大规模多任务语言理解)等基准测试一直是评估模型的主要方式,通过跨多个学科的单选题进行测试。虽然它们便于比较,但并不能完全捕捉智能能力的全部范围。
以Claude 3.5 Sonnet和GPT-4.5为例,它们在MMLU上的得分可能相近,表明它们水平相当。但实际使用这些模型的人都知道,它们的现实表现可能大不相同。
在AI中衡量“智能”意味着什么?
随着ARC-AGI基准测试的最近推出,旨在测试模型在通用推理和创造性问题解决方面的能力,关于在AI中衡量“智能”的讨论掀起了一股新热潮。并非所有人都已经尝试过ARC-AGI,但业界对这一测试及其他新测试方法的讨论非常热烈。每个基准测试都有其价值,而ARC-AGI是朝着正确方向迈出的一步。
另一个令人兴奋的发展是“人类的最后考试”,这是一个包含3000个经过同行评审的多步骤问题的全面基准测试,涵盖不同学科。这是一个雄心勃勃的努力,旨在推动AI系统达到专家级推理水平。早期结果显示进展迅速,据报道OpenAI在发布仅一个月后就达到了26.6%的得分。但与其他基准测试一样,它主要关注知识和在真空环境中的推理,而非对现实世界AI应用至关重要的实用工具使用技能。
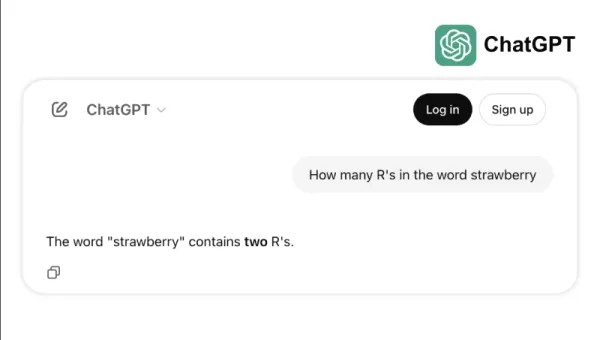
例如,一些顶级模型在简单任务上表现不佳,比如数“strawberry”中的“r”或比较3.8和3.1111。这些错误,即使是孩子或基本计算器都能避免,凸显了基准测试成功与现实世界可靠性之间的差距。这提醒我们,智能不仅仅是考试得高分;它还关乎轻松应对日常逻辑。
衡量AI能力的新标准
随着AI模型的发展,传统基准测试的局限性越来越明显。例如,GPT-4在配备工具时,在GAIA基准测试中更复杂的现实世界任务上仅得15%,尽管它在单选题测试中得分很高。
随着AI系统从研究实验室转向商业应用,基准测试表现与实际能力之间的差距越来越成问题。传统基准测试评估模型的知识回忆能力,但往往忽略了智能的关键方面,如收集数据、运行代码、分析信息以及跨领域创建解决方案的能力。
GAIA是一个标志着AI评估重大转变的新基准测试。由Meta-FAIR、Meta-GenAI、HuggingFace和AutoGPT团队合作开发,GAIA包含466个精心设计的跨三个难度级别的问题。这些问题测试了现实世界AI应用所需的一系列技能,包括网页浏览、多模态理解、代码执行、文件处理和复杂推理。
一级问题通常需要人类大约5个步骤和一种工具来解决。二级问题需要5到10个步骤和多种工具,而三级问题可能需要多达50个步骤和任意数量的工具。这种结构反映了实际商业问题的复杂性,解决方案往往涉及多个动作和工具。
通过专注于灵活性而不仅仅是复杂性,一个AI模型在GAIA上取得了75%的准确率,超过了行业领先者,如微软的Magnetic-1(38%)和谷歌的Langfun Agent(49%)。这一成功得益于使用专门的模型进行音视频理解和推理,以Anthropic的Sonnet 3.5作为主要模型。
AI评估的这种转变反映了行业的一个更广泛趋势:我们正在从独立的SaaS应用转向能够管理多种工具和工作流程的AI代理。随着企业越来越依赖AI来处理复杂的多步骤任务,像GAIA这样的基准测试提供了比传统单选题测试更相关的能力衡量标准。
AI评估的未来不是孤立的知识测试;它是对问题解决能力的全面评估。GAIA为衡量AI能力设定了一个新基准——一个更符合AI部署现实挑战和机遇的基准。
斯里·安巴蒂是H2O.ai的创始人和首席执行官。
相关文章
 人工智能揭示新闻内容中的隐藏议程
ChatGPT类模型正被训练以揭示新闻报道背后的潜在立场——即便这种观点被引语、叙事框架或(有时虚伪的)中立表象所掩盖。通过将文章拆解为标题、导语和引语等段落,新型系统能识别长篇专业新闻报道中的偏见。 这种洞悉作者或发言者真实立场的技术(学术文献中称为立场检测),正攻克语言解读中最复杂的难题之一:从可能刻意设计来掩盖或模糊意图的内容中辨别真实意图。从乔纳森·斯威夫特的《一个谦卑的建议》到当代政治表
Anthropic的Claude 4.1在编程基准测试中表现优异,领先于即将发布的GPT-5
周一,Anthropic公司发布了其旗舰人工智能模型的增强版,为软件工程任务的性能树立了新标杆。此次发布使这家人工智能初创企业得以捍卫其在利润丰厚的编码领域的优势地位,同时为应对OpenAI即将带来的新竞争做好准备。新版Claude Opus 4.1模型在SWE-bench认证测试中斩获74.5%的得分,该测试是评估AI系统解决实际软件问题能力的权威基准。这一成绩超越了OpenAI o3模型的69
Nvidia 推出可切换推理的开源人工智能模型 Nemotron-Nano-9B-v2
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参
相关专题推荐
商业
人工智能揭示新闻内容中的隐藏议程
ChatGPT类模型正被训练以揭示新闻报道背后的潜在立场——即便这种观点被引语、叙事框架或(有时虚伪的)中立表象所掩盖。通过将文章拆解为标题、导语和引语等段落,新型系统能识别长篇专业新闻报道中的偏见。 这种洞悉作者或发言者真实立场的技术(学术文献中称为立场检测),正攻克语言解读中最复杂的难题之一:从可能刻意设计来掩盖或模糊意图的内容中辨别真实意图。从乔纳森·斯威夫特的《一个谦卑的建议》到当代政治表
Anthropic的Claude 4.1在编程基准测试中表现优异,领先于即将发布的GPT-5
周一,Anthropic公司发布了其旗舰人工智能模型的增强版,为软件工程任务的性能树立了新标杆。此次发布使这家人工智能初创企业得以捍卫其在利润丰厚的编码领域的优势地位,同时为应对OpenAI即将带来的新竞争做好准备。新版Claude Opus 4.1模型在SWE-bench认证测试中斩获74.5%的得分,该测试是评估AI系统解决实际软件问题能力的权威基准。这一成绩超越了OpenAI o3模型的69
Nvidia 推出可切换推理的开源人工智能模型 Nemotron-Nano-9B-v2
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (4)
0/500
评论 (4)
0/500
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
智能无处不在,但要精确衡量它却像试图用双手抓住云彩。我们使用考试和基准测试,如大学入学考试,来大致了解情况。每年,学生们为这些考试拼命复习,有时甚至能考到满分100%。但满分是否意味着他们都拥有相同的智能水平,或者已经达到了他们的智力巅峰?当然不是。这些基准测试只是粗略的估计,并非某人真实能力的精确指标。
在生成式AI领域,MMLU(大规模多任务语言理解)等基准测试一直是评估模型的主要方式,通过跨多个学科的单选题进行测试。虽然它们便于比较,但并不能完全捕捉智能能力的全部范围。
以Claude 3.5 Sonnet和GPT-4.5为例,它们在MMLU上的得分可能相近,表明它们水平相当。但实际使用这些模型的人都知道,它们的现实表现可能大不相同。
在AI中衡量“智能”意味着什么?
随着ARC-AGI基准测试的最近推出,旨在测试模型在通用推理和创造性问题解决方面的能力,关于在AI中衡量“智能”的讨论掀起了一股新热潮。并非所有人都已经尝试过ARC-AGI,但业界对这一测试及其他新测试方法的讨论非常热烈。每个基准测试都有其价值,而ARC-AGI是朝着正确方向迈出的一步。
另一个令人兴奋的发展是“人类的最后考试”,这是一个包含3000个经过同行评审的多步骤问题的全面基准测试,涵盖不同学科。这是一个雄心勃勃的努力,旨在推动AI系统达到专家级推理水平。早期结果显示进展迅速,据报道OpenAI在发布仅一个月后就达到了26.6%的得分。但与其他基准测试一样,它主要关注知识和在真空环境中的推理,而非对现实世界AI应用至关重要的实用工具使用技能。
例如,一些顶级模型在简单任务上表现不佳,比如数“strawberry”中的“r”或比较3.8和3.1111。这些错误,即使是孩子或基本计算器都能避免,凸显了基准测试成功与现实世界可靠性之间的差距。这提醒我们,智能不仅仅是考试得高分;它还关乎轻松应对日常逻辑。
衡量AI能力的新标准
随着AI模型的发展,传统基准测试的局限性越来越明显。例如,GPT-4在配备工具时,在GAIA基准测试中更复杂的现实世界任务上仅得15%,尽管它在单选题测试中得分很高。
随着AI系统从研究实验室转向商业应用,基准测试表现与实际能力之间的差距越来越成问题。传统基准测试评估模型的知识回忆能力,但往往忽略了智能的关键方面,如收集数据、运行代码、分析信息以及跨领域创建解决方案的能力。
GAIA是一个标志着AI评估重大转变的新基准测试。由Meta-FAIR、Meta-GenAI、HuggingFace和AutoGPT团队合作开发,GAIA包含466个精心设计的跨三个难度级别的问题。这些问题测试了现实世界AI应用所需的一系列技能,包括网页浏览、多模态理解、代码执行、文件处理和复杂推理。
一级问题通常需要人类大约5个步骤和一种工具来解决。二级问题需要5到10个步骤和多种工具,而三级问题可能需要多达50个步骤和任意数量的工具。这种结构反映了实际商业问题的复杂性,解决方案往往涉及多个动作和工具。
通过专注于灵活性而不仅仅是复杂性,一个AI模型在GAIA上取得了75%的准确率,超过了行业领先者,如微软的Magnetic-1(38%)和谷歌的Langfun Agent(49%)。这一成功得益于使用专门的模型进行音视频理解和推理,以Anthropic的Sonnet 3.5作为主要模型。
AI评估的这种转变反映了行业的一个更广泛趋势:我们正在从独立的SaaS应用转向能够管理多种工具和工作流程的AI代理。随着企业越来越依赖AI来处理复杂的多步骤任务,像GAIA这样的基准测试提供了比传统单选题测试更相关的能力衡量标准。
AI评估的未来不是孤立的知识测试;它是对问题解决能力的全面评估。GAIA为衡量AI能力设定了一个新基准——一个更符合AI部署现实挑战和机遇的基准。
斯里·安巴蒂是H2O.ai的创始人和首席执行官。










 人工智能揭示新闻内容中的隐藏议程
ChatGPT类模型正被训练以揭示新闻报道背后的潜在立场——即便这种观点被引语、叙事框架或(有时虚伪的)中立表象所掩盖。通过将文章拆解为标题、导语和引语等段落,新型系统能识别长篇专业新闻报道中的偏见。 这种洞悉作者或发言者真实立场的技术(学术文献中称为立场检测),正攻克语言解读中最复杂的难题之一:从可能刻意设计来掩盖或模糊意图的内容中辨别真实意图。从乔纳森·斯威夫特的《一个谦卑的建议》到当代政治表
人工智能揭示新闻内容中的隐藏议程
ChatGPT类模型正被训练以揭示新闻报道背后的潜在立场——即便这种观点被引语、叙事框架或(有时虚伪的)中立表象所掩盖。通过将文章拆解为标题、导语和引语等段落,新型系统能识别长篇专业新闻报道中的偏见。 这种洞悉作者或发言者真实立场的技术(学术文献中称为立场检测),正攻克语言解读中最复杂的难题之一:从可能刻意设计来掩盖或模糊意图的内容中辨别真实意图。从乔纳森·斯威夫特的《一个谦卑的建议》到当代政治表
 Anthropic的Claude 4.1在编程基准测试中表现优异,领先于即将发布的GPT-5
周一,Anthropic公司发布了其旗舰人工智能模型的增强版,为软件工程任务的性能树立了新标杆。此次发布使这家人工智能初创企业得以捍卫其在利润丰厚的编码领域的优势地位,同时为应对OpenAI即将带来的新竞争做好准备。新版Claude Opus 4.1模型在SWE-bench认证测试中斩获74.5%的得分,该测试是评估AI系统解决实际软件问题能力的权威基准。这一成绩超越了OpenAI o3模型的69
Anthropic的Claude 4.1在编程基准测试中表现优异,领先于即将发布的GPT-5
周一,Anthropic公司发布了其旗舰人工智能模型的增强版,为软件工程任务的性能树立了新标杆。此次发布使这家人工智能初创企业得以捍卫其在利润丰厚的编码领域的优势地位,同时为应对OpenAI即将带来的新竞争做好准备。新版Claude Opus 4.1模型在SWE-bench认证测试中斩获74.5%的得分,该测试是评估AI系统解决实际软件问题能力的权威基准。这一成绩超越了OpenAI o3模型的69
 Nvidia 推出可切换推理的开源人工智能模型 Nemotron-Nano-9B-v2
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参
Nvidia 推出可切换推理的开源人工智能模型 Nemotron-Nano-9B-v2
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













