
















 Hogar
Hogar
Gaia presenta un nuevo punto de referencia en busca de la verdadera inteligencia más allá de Arc-Agi
La inteligencia está en todas partes, pero medirla con precisión parece como intentar atrapar una nube con las manos. Usamos pruebas y estándares, como los exámenes de ingreso a la universidad, para tener una idea aproximada. Cada año, los estudiantes se preparan intensamente para estas pruebas, a veces logrando un puntaje perfecto del 100%. Pero, ¿ese puntaje perfecto significa que todos tienen el mismo nivel de inteligencia o que han alcanzado el máximo de su potencial mental? Por supuesto que no. Estos estándares son solo estimaciones aproximadas, no indicadores precisos de las verdaderas habilidades de alguien.
En el mundo de la IA generativa, estándares como MMLU (Comprensión Masiva de Tareas Múltiples) han sido los preferidos para evaluar modelos mediante preguntas de opción múltiple en diversas áreas académicas. Aunque permiten comparaciones fáciles, no capturan realmente el espectro completo de las capacidades inteligentes.
Tomemos, por ejemplo, a Claude 3.5 Sonnet y GPT-4.5. Podrían obtener puntajes similares en MMLU, sugiriendo que están a la par. Pero cualquiera que haya usado estos modelos sabe que su desempeño en el mundo real puede ser bastante diferente.
¿Qué significa medir la 'inteligencia' en la IA?
Con el reciente lanzamiento del estándar ARC-AGI, diseñado para probar modelos en razonamiento general y resolución creativa de problemas, ha surgido una nueva ola de discusión sobre qué significa medir la "inteligencia" en la IA. No todos han tenido la oportunidad de explorar ARC-AGI aún, pero la industria está emocionada con este y otros nuevos enfoques de evaluación. Cada estándar tiene su lugar, y ARC-AGI es un paso en la dirección correcta.
Otro desarrollo emocionante es 'El Último Examen de la Humanidad', un estándar integral con 3,000 preguntas revisadas por pares, de múltiples pasos, que abarcan diferentes disciplinas. Es un esfuerzo ambicioso para empujar a los sistemas de IA al razonamiento de nivel experto. Los primeros resultados muestran un progreso rápido, con OpenAI alcanzando un puntaje del 26.6% apenas un mes después de su lanzamiento. Pero, como otros estándares, se centra principalmente en el conocimiento y el razonamiento en un vacío, no en las habilidades prácticas de uso de herramientas que son vitales para las aplicaciones de IA en el mundo real.
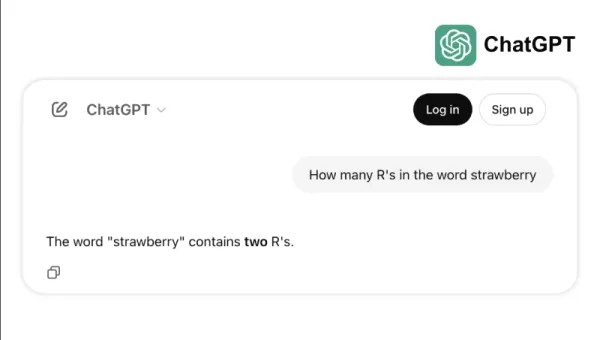
Por ejemplo, algunos modelos líderes tienen dificultades con tareas simples como contar las "r" en "strawberry" o comparar 3.8 con 3.1111. Estos errores, que incluso un niño o una calculadora básica podrían evitar, destacan la brecha entre el éxito en los estándares y la fiabilidad en el mundo real. Es un recordatorio de que la inteligencia no se trata solo de aprobar pruebas; se trata de navegar por la lógica cotidiana con facilidad.
El Nuevo Estándar para Medir la Capacidad de la IA
A medida que los modelos de IA han evolucionado, las limitaciones de los estándares tradicionales se han vuelto más evidentes. Por ejemplo, GPT-4, cuando está equipado con herramientas, solo logra un 15% en las tareas más complejas del mundo real en el estándar GAIA, a pesar de sus altos puntajes en pruebas de opción múltiple.
Esta discrepancia entre el rendimiento en estándares y la capacidad práctica es cada vez más problemática a medida que los sistemas de IA pasan de los laboratorios de investigación a las aplicaciones empresariales. Los estándares tradicionales evalúan qué tan bien un modelo puede recordar información, pero a menudo pasan por alto aspectos clave de la inteligencia, como la capacidad de recopilar datos, ejecutar código, analizar información y crear soluciones en diversos dominios.
Entra GAIA, un nuevo estándar que marca un cambio significativo en la evaluación de la IA. Desarrollado a través de una colaboración entre equipos de Meta-FAIR, Meta-GenAI, HuggingFace y AutoGPT, GAIA incluye 466 preguntas cuidadosamente elaboradas en tres niveles de dificultad. Estas preguntas evalúan una amplia gama de habilidades esenciales para las aplicaciones de IA en el mundo real, incluyendo navegación web, comprensión multimodal, ejecución de código, manejo de archivos y razonamiento complejo.
Las preguntas de nivel 1 generalmente requieren unos 5 pasos y una herramienta para que los humanos las resuelvan. Las preguntas de nivel 2 necesitan de 5 a 10 pasos y múltiples herramientas, mientras que las preguntas de nivel 3 podrían exigir hasta 50 pasos y cualquier cantidad de herramientas. Esta estructura refleja la complejidad de los problemas empresariales reales, donde las soluciones a menudo involucran múltiples acciones y herramientas.
Al centrarse en la flexibilidad en lugar de solo la complejidad, un modelo de IA logró una tasa de precisión del 75% en GAIA, superando a líderes de la industria como Microsoft's Magnetic-1 (38%) y Google's Langfun Agent (49%). Este éxito proviene del uso de una combinación de modelos especializados para la comprensión audiovisual y el razonamiento, con Anthropic's Sonnet 3.5 como el modelo principal.
Este cambio en la evaluación de la IA refleja una tendencia más amplia en la industria: Nos estamos alejando de las aplicaciones SaaS independientes hacia agentes de IA que pueden gestionar múltiples herramientas y flujos de trabajo. A medida que las empresas dependen cada vez más de la IA para abordar tareas complejas de múltiples pasos, estándares como GAIA ofrecen una medida más relevante de la capacidad que las pruebas tradicionales de opción múltiple.
El futuro de la evaluación de la IA no se trata de pruebas de conocimiento aisladas; se trata de evaluaciones integrales de la capacidad de resolución de problemas. GAIA establece un nuevo estándar para medir la capacidad de la IA, uno que se alinea mejor con los desafíos y oportunidades del mundo real en la implementación de la IA.
Sri Ambati es el fundador y CEO de H2O.ai.
Artículo relacionado
 La IA revela agendas ocultas en los contenidos informativos
Los modelos del tipo ChatGPT se están entrenando ahora para descubrir la perspectiva subyacente de un artículo periodístico, incluso cuando ese punto de vista se oculta tras citas, encuadres o una apa
Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para
Recomendaciones de temas especiales relacionados
Negocio
La IA revela agendas ocultas en los contenidos informativos
Los modelos del tipo ChatGPT se están entrenando ahora para descubrir la perspectiva subyacente de un artículo periodístico, incluso cuando ese punto de vista se oculta tras citas, encuadres o una apa
Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (4)
0/500
comentario (4)
0/500
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
La inteligencia está en todas partes, pero medirla con precisión parece como intentar atrapar una nube con las manos. Usamos pruebas y estándares, como los exámenes de ingreso a la universidad, para tener una idea aproximada. Cada año, los estudiantes se preparan intensamente para estas pruebas, a veces logrando un puntaje perfecto del 100%. Pero, ¿ese puntaje perfecto significa que todos tienen el mismo nivel de inteligencia o que han alcanzado el máximo de su potencial mental? Por supuesto que no. Estos estándares son solo estimaciones aproximadas, no indicadores precisos de las verdaderas habilidades de alguien.
En el mundo de la IA generativa, estándares como MMLU (Comprensión Masiva de Tareas Múltiples) han sido los preferidos para evaluar modelos mediante preguntas de opción múltiple en diversas áreas académicas. Aunque permiten comparaciones fáciles, no capturan realmente el espectro completo de las capacidades inteligentes.
Tomemos, por ejemplo, a Claude 3.5 Sonnet y GPT-4.5. Podrían obtener puntajes similares en MMLU, sugiriendo que están a la par. Pero cualquiera que haya usado estos modelos sabe que su desempeño en el mundo real puede ser bastante diferente.
¿Qué significa medir la 'inteligencia' en la IA?
Con el reciente lanzamiento del estándar ARC-AGI, diseñado para probar modelos en razonamiento general y resolución creativa de problemas, ha surgido una nueva ola de discusión sobre qué significa medir la "inteligencia" en la IA. No todos han tenido la oportunidad de explorar ARC-AGI aún, pero la industria está emocionada con este y otros nuevos enfoques de evaluación. Cada estándar tiene su lugar, y ARC-AGI es un paso en la dirección correcta.
Otro desarrollo emocionante es 'El Último Examen de la Humanidad', un estándar integral con 3,000 preguntas revisadas por pares, de múltiples pasos, que abarcan diferentes disciplinas. Es un esfuerzo ambicioso para empujar a los sistemas de IA al razonamiento de nivel experto. Los primeros resultados muestran un progreso rápido, con OpenAI alcanzando un puntaje del 26.6% apenas un mes después de su lanzamiento. Pero, como otros estándares, se centra principalmente en el conocimiento y el razonamiento en un vacío, no en las habilidades prácticas de uso de herramientas que son vitales para las aplicaciones de IA en el mundo real.
Por ejemplo, algunos modelos líderes tienen dificultades con tareas simples como contar las "r" en "strawberry" o comparar 3.8 con 3.1111. Estos errores, que incluso un niño o una calculadora básica podrían evitar, destacan la brecha entre el éxito en los estándares y la fiabilidad en el mundo real. Es un recordatorio de que la inteligencia no se trata solo de aprobar pruebas; se trata de navegar por la lógica cotidiana con facilidad.
El Nuevo Estándar para Medir la Capacidad de la IA
A medida que los modelos de IA han evolucionado, las limitaciones de los estándares tradicionales se han vuelto más evidentes. Por ejemplo, GPT-4, cuando está equipado con herramientas, solo logra un 15% en las tareas más complejas del mundo real en el estándar GAIA, a pesar de sus altos puntajes en pruebas de opción múltiple.
Esta discrepancia entre el rendimiento en estándares y la capacidad práctica es cada vez más problemática a medida que los sistemas de IA pasan de los laboratorios de investigación a las aplicaciones empresariales. Los estándares tradicionales evalúan qué tan bien un modelo puede recordar información, pero a menudo pasan por alto aspectos clave de la inteligencia, como la capacidad de recopilar datos, ejecutar código, analizar información y crear soluciones en diversos dominios.
Entra GAIA, un nuevo estándar que marca un cambio significativo en la evaluación de la IA. Desarrollado a través de una colaboración entre equipos de Meta-FAIR, Meta-GenAI, HuggingFace y AutoGPT, GAIA incluye 466 preguntas cuidadosamente elaboradas en tres niveles de dificultad. Estas preguntas evalúan una amplia gama de habilidades esenciales para las aplicaciones de IA en el mundo real, incluyendo navegación web, comprensión multimodal, ejecución de código, manejo de archivos y razonamiento complejo.
Las preguntas de nivel 1 generalmente requieren unos 5 pasos y una herramienta para que los humanos las resuelvan. Las preguntas de nivel 2 necesitan de 5 a 10 pasos y múltiples herramientas, mientras que las preguntas de nivel 3 podrían exigir hasta 50 pasos y cualquier cantidad de herramientas. Esta estructura refleja la complejidad de los problemas empresariales reales, donde las soluciones a menudo involucran múltiples acciones y herramientas.
Al centrarse en la flexibilidad en lugar de solo la complejidad, un modelo de IA logró una tasa de precisión del 75% en GAIA, superando a líderes de la industria como Microsoft's Magnetic-1 (38%) y Google's Langfun Agent (49%). Este éxito proviene del uso de una combinación de modelos especializados para la comprensión audiovisual y el razonamiento, con Anthropic's Sonnet 3.5 como el modelo principal.
Este cambio en la evaluación de la IA refleja una tendencia más amplia en la industria: Nos estamos alejando de las aplicaciones SaaS independientes hacia agentes de IA que pueden gestionar múltiples herramientas y flujos de trabajo. A medida que las empresas dependen cada vez más de la IA para abordar tareas complejas de múltiples pasos, estándares como GAIA ofrecen una medida más relevante de la capacidad que las pruebas tradicionales de opción múltiple.
El futuro de la evaluación de la IA no se trata de pruebas de conocimiento aisladas; se trata de evaluaciones integrales de la capacidad de resolución de problemas. GAIA establece un nuevo estándar para medir la capacidad de la IA, uno que se alinea mejor con los desafíos y oportunidades del mundo real en la implementación de la IA.
Sri Ambati es el fundador y CEO de H2O.ai.










 La IA revela agendas ocultas en los contenidos informativos
Los modelos del tipo ChatGPT se están entrenando ahora para descubrir la perspectiva subyacente de un artículo periodístico, incluso cuando ese punto de vista se oculta tras citas, encuadres o una apa
La IA revela agendas ocultas en los contenidos informativos
Los modelos del tipo ChatGPT se están entrenando ahora para descubrir la perspectiva subyacente de un artículo periodístico, incluso cuando ese punto de vista se oculta tras citas, encuadres o una apa
 Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
Claude 4.1 de Anthropic supera en rendimiento a GPT-5 en pruebas de codificación antes de su lanzamiento
Anthropic presentó el lunes una versión mejorada de su modelo de IA de primera línea, estableciendo un nuevo punto de referencia en cuanto al rendimiento en tareas de ingeniería de software. El lanzam
 Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para
Nvidia presenta el modelo de IA de código abierto Nemotron-Nano-9B-v2 con razonamiento conmutable
Los modelos de lenguaje pequeños están causando sensación. Tras el debut del modelo de visión del tamaño de un reloj inteligente de Liquid AI, una empresa derivada del MIT, y la oferta de Google para

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













