
















 家
家ガイアは、Arc-Agiを超えた真の知性を求めて新しいベンチマークを紹介します
知性はどこにでも存在しますが、それを正確に測定するのは、素手で雲をつかむようなものです。私たちは大学入試のようなテストやベンチマークを使って大まかな見当をつけます。毎年、学生たちはこれらのテストのために詰め込み勉強をし、時には100%の完璧なスコアを獲得します。しかし、その完璧なスコアは、彼らがみな同じレベルの知性を持っていること、あるいは彼らの精神的潜在能力のピークに達したことを意味するのでしょうか?もちろん違います。これらのベンチマークは、誰かの本当の能力を正確に示すものではなく、粗い推定にすぎません。
生成AIの世界では、MMLU(Massive Multitask Language Understanding)のようなベンチマークが、さまざまな学術分野にわたる多肢選択問題を通じてモデルを評価するための標準でした。これらは簡単な比較を可能にしますが、知的能力の全範囲を本当に捉えているわけではありません。
たとえば、Claude 3.5 SonnetとGPT-4.5を取り上げてみましょう。MMLUでのスコアが似ているため、同等の性能を持つように見えます。しかし、これらのモデルを実際に使ったことがある人なら、実世界でのパフォーマンスがかなり異なることを知っています。
AIにおける「知性」の測定とは何か?
最近、ARC-AGIベンチマークが開始され、一般的な推論や創造的な問題解決をテストするために設計されたことで、AIにおける「知性」の測定とは何かをめぐる新たな議論が巻き起こっています。まだ誰もがARC-AGIに深く取り組んだわけではありませんが、業界はこの新しいテストアプローチや他の新しい方法について盛り上がっています。すべてのベンチマークにはそれぞれの役割があり、ARC-AGIは正しい方向への一歩です。
もう一つのエキサイティングな進展は、「Humanity's Last Exam」です。これは、さまざまな分野にわたる3,000の査読済み多段階質問からなる包括的なベンチマークです。AIシステムを専門家レベルの推論に挑戦させる野心的な試みです。初期の結果は急速な進歩を示しており、OpenAIはリリースからわずか1か月で26.6%のスコアを記録したとされています。しかし、他のベンチマークと同様に、これは主に知識と真空状態での推論に焦点を当てており、実世界のAIアプリケーションに不可欠な実際のツール使用スキルには焦点を当てていません。
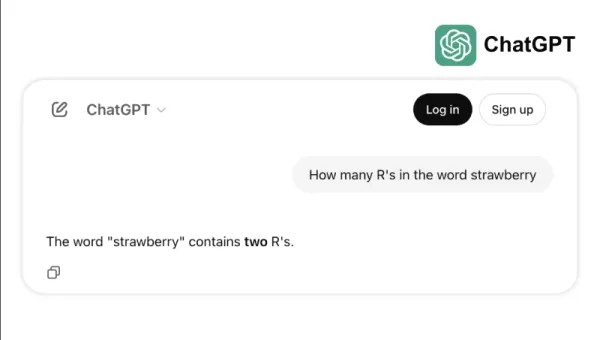
たとえば、トップモデルの一部が「strawberry」の「r」の数を数えるような簡単なタスクや、3.8と3.1111の比較で苦戦する様子を見てみましょう。これらのエラーは、子供や基本的な電卓でも避けられるものであり、ベンチマークの成功と実世界の信頼性の間のギャップを浮き彫りにします。知性とは、テストで高得点を出すことだけでなく、日常の論理を容易に操ることであるということを思い出させます。
AI能力を測定する新しい基準
AIモデルが進化するにつれて、従来のベンチマークの限界がより明らかになってきました。たとえば、ツールを備えたGPT-4は、多肢選択テストで高得点を記録しているにもかかわらず、GAIAベンチマークのより複雑な実世界のタスクでは約15%しかスコアを獲得できません。
ベンチマークのパフォーマンスと実際の能力の間のこの乖離は、AIシステムが研究室からビジネスアプリケーションに移行するにつれてますます問題となっています。従来のベンチマークは、モデルが情報をどれだけ正確に思い出すかをテストしますが、データを収集し、コードを実行し、情報を分析し、さまざまな領域でソリューションを作成する能力など、知性の重要な側面をしばしば見落とします。
そこで登場するのがGAIAです。これはAI評価における大きな変化を示す新しいベンチマークです。Meta-FAIR、Meta-GenAI、HuggingFace、AutoGPTのチームによる協力で開発されたGAIAは、3つの難易度レベルにわたる466の慎重に作成された質問を含んでいます。これらの質問は、ウェブブラウジング、マルチモーダル理解、コード実行、ファイル処理、複雑な推論など、実世界のAIアプリケーションに不可欠な幅広いスキルをテストします。
レベル1の質問は通常、5ステップと1つのツールで人間が解決する必要があります。レベル2の質問は5~10ステップと複数のツールが必要で、レベル3の質問は最大50ステップと任意の数のツールを要求する可能性があります。この構造は、実際のビジネス問題の複雑さを反映しており、解決策にはしばしば複数のアクションとツールが関与します。
複雑さだけでなく柔軟性に焦点を当てることで、あるAIモデルはGAIAで75%の正確率を達成し、MicrosoftのMagnetic-1(38%)やGoogleのLangfun Agent(49%)などの業界リーダーを上回りました。この成功は、オーディオビジュアル理解と推論のための専門モデルの組み合わせを使用し、AnthropicのSonnet 3.5を主要モデルとして採用した結果です。
AI評価のこの変化は、業界全体のより大きなトレンドを反映しています。スタンドアローンのSaaSアプリケーションから、複数のツールとワークフローを管理できるAIエージェントへと移行しています。ビジネスが複雑な多段階タスクを処理するためにAIにますます依存する中、GAIAのようなベンチマークは、従来の多肢選択テストよりも関連性の高い能力の尺度を提供します。
AI評価の未来は、孤立した知識テストではなく、問題解決能力の包括的な評価に関するものです。GAIAは、AI能力を測定するための新しい基準を設定し、AI展開の実世界の課題と機会により良く適合します。
Sri AmbatiはH2O.aiの創設者兼CEOです。
関連記事
 AIがニュースコンテンツに潜む隠された意図を明らかにする
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。 執筆者や発言者の真の立場を把握する能力—
AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
関連特集おすすめ
漫画制作
AIがニュースコンテンツに潜む隠された意図を明らかにする
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。 執筆者や発言者の真の立場を把握する能力—
AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
関連特集おすすめ
漫画制作
 少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
 15 ツール
15 ツール
 xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

 コメント (4)
0/500
コメント (4)
0/500
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
知性はどこにでも存在しますが、それを正確に測定するのは、素手で雲をつかむようなものです。私たちは大学入試のようなテストやベンチマークを使って大まかな見当をつけます。毎年、学生たちはこれらのテストのために詰め込み勉強をし、時には100%の完璧なスコアを獲得します。しかし、その完璧なスコアは、彼らがみな同じレベルの知性を持っていること、あるいは彼らの精神的潜在能力のピークに達したことを意味するのでしょうか?もちろん違います。これらのベンチマークは、誰かの本当の能力を正確に示すものではなく、粗い推定にすぎません。
生成AIの世界では、MMLU(Massive Multitask Language Understanding)のようなベンチマークが、さまざまな学術分野にわたる多肢選択問題を通じてモデルを評価するための標準でした。これらは簡単な比較を可能にしますが、知的能力の全範囲を本当に捉えているわけではありません。
たとえば、Claude 3.5 SonnetとGPT-4.5を取り上げてみましょう。MMLUでのスコアが似ているため、同等の性能を持つように見えます。しかし、これらのモデルを実際に使ったことがある人なら、実世界でのパフォーマンスがかなり異なることを知っています。
AIにおける「知性」の測定とは何か?
最近、ARC-AGIベンチマークが開始され、一般的な推論や創造的な問題解決をテストするために設計されたことで、AIにおける「知性」の測定とは何かをめぐる新たな議論が巻き起こっています。まだ誰もがARC-AGIに深く取り組んだわけではありませんが、業界はこの新しいテストアプローチや他の新しい方法について盛り上がっています。すべてのベンチマークにはそれぞれの役割があり、ARC-AGIは正しい方向への一歩です。
もう一つのエキサイティングな進展は、「Humanity's Last Exam」です。これは、さまざまな分野にわたる3,000の査読済み多段階質問からなる包括的なベンチマークです。AIシステムを専門家レベルの推論に挑戦させる野心的な試みです。初期の結果は急速な進歩を示しており、OpenAIはリリースからわずか1か月で26.6%のスコアを記録したとされています。しかし、他のベンチマークと同様に、これは主に知識と真空状態での推論に焦点を当てており、実世界のAIアプリケーションに不可欠な実際のツール使用スキルには焦点を当てていません。
たとえば、トップモデルの一部が「strawberry」の「r」の数を数えるような簡単なタスクや、3.8と3.1111の比較で苦戦する様子を見てみましょう。これらのエラーは、子供や基本的な電卓でも避けられるものであり、ベンチマークの成功と実世界の信頼性の間のギャップを浮き彫りにします。知性とは、テストで高得点を出すことだけでなく、日常の論理を容易に操ることであるということを思い出させます。
AI能力を測定する新しい基準
AIモデルが進化するにつれて、従来のベンチマークの限界がより明らかになってきました。たとえば、ツールを備えたGPT-4は、多肢選択テストで高得点を記録しているにもかかわらず、GAIAベンチマークのより複雑な実世界のタスクでは約15%しかスコアを獲得できません。
ベンチマークのパフォーマンスと実際の能力の間のこの乖離は、AIシステムが研究室からビジネスアプリケーションに移行するにつれてますます問題となっています。従来のベンチマークは、モデルが情報をどれだけ正確に思い出すかをテストしますが、データを収集し、コードを実行し、情報を分析し、さまざまな領域でソリューションを作成する能力など、知性の重要な側面をしばしば見落とします。
そこで登場するのがGAIAです。これはAI評価における大きな変化を示す新しいベンチマークです。Meta-FAIR、Meta-GenAI、HuggingFace、AutoGPTのチームによる協力で開発されたGAIAは、3つの難易度レベルにわたる466の慎重に作成された質問を含んでいます。これらの質問は、ウェブブラウジング、マルチモーダル理解、コード実行、ファイル処理、複雑な推論など、実世界のAIアプリケーションに不可欠な幅広いスキルをテストします。
レベル1の質問は通常、5ステップと1つのツールで人間が解決する必要があります。レベル2の質問は5~10ステップと複数のツールが必要で、レベル3の質問は最大50ステップと任意の数のツールを要求する可能性があります。この構造は、実際のビジネス問題の複雑さを反映しており、解決策にはしばしば複数のアクションとツールが関与します。
複雑さだけでなく柔軟性に焦点を当てることで、あるAIモデルはGAIAで75%の正確率を達成し、MicrosoftのMagnetic-1(38%)やGoogleのLangfun Agent(49%)などの業界リーダーを上回りました。この成功は、オーディオビジュアル理解と推論のための専門モデルの組み合わせを使用し、AnthropicのSonnet 3.5を主要モデルとして採用した結果です。
AI評価のこの変化は、業界全体のより大きなトレンドを反映しています。スタンドアローンのSaaSアプリケーションから、複数のツールとワークフローを管理できるAIエージェントへと移行しています。ビジネスが複雑な多段階タスクを処理するためにAIにますます依存する中、GAIAのようなベンチマークは、従来の多肢選択テストよりも関連性の高い能力の尺度を提供します。
AI評価の未来は、孤立した知識テストではなく、問題解決能力の包括的な評価に関するものです。GAIAは、AI能力を測定するための新しい基準を設定し、AI展開の実世界の課題と機会により良く適合します。
Sri AmbatiはH2O.aiの創設者兼CEOです。










 AIがニュースコンテンツに潜む隠された意図を明らかにする
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。 執筆者や発言者の真の立場を把握する能力—
AIがニュースコンテンツに潜む隠された意図を明らかにする
ChatGPTスタイルのモデルは現在、ニュース記事の根底にある視点を解明するよう訓練されている——たとえその視点が引用文やフレームワーク、あるいは(時に不誠実な)中立性の覆いの下に隠されていても。見出し、リード文、引用文といったセグメントに記事を分割することで、新たなシステムは長文のプロフェッショナルなジャーナリズムにおいても偏りを識別することを学習する。 執筆者や発言者の真の立場を把握する能力—
 AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
AnthropicのClaude 4.1、GPT-5発表前にコーディングベンチマークで優れた性能を発揮
アンソロピックは月曜日、主力AIモデルの強化版を発表し、ソフトウェアエンジニアリングタスクにおける性能の新たな基準を打ち立てた。この展開により、AIスタートアップは収益性の高いコーディング分野での強固な地位を防衛する態勢を整え、OpenAIからの新たな競争を予期している。新モデル「Claude Opus 4.1」は、AIシステムの現実的なソフトウェア課題解決能力を評価する主要ベンチマーク「SWE-
 Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して
Nvidia、トグル可能な推論機能を備えたオープンソースAIモデル「Nemotron-Nano-9B-v2」を発表
小型言語モデルが注目を集めている。 MITスピンオフ企業Liquid AIのスマートウォッチサイズ視覚モデルやGoogleのスマートフォン対応モデルの登場に続き、Nvidiaも独自の軽量モデル「Nemotron-Nano-9B-V2」で参入した。この新モデルは主要ベンチマークで同クラスをリードし、AIの「推論」機能(最終回答前の自己チェックプロセス)をユーザーが有効/無効にできる独自機能を導入して

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













