
















 Maison
Maison
Gaia introduit une nouvelle référence dans la quête de la véritable intelligence au-delà de l'ARC-AGI
L'intelligence est omniprésente, mais la mesurer précisément revient à essayer d'attraper un nuage à mains nues. Nous utilisons des tests et des benchmarks, comme les examens d'entrée à l'université, pour en avoir une idée approximative. Chaque année, les étudiants se préparent intensément pour ces tests, certains obtenant même un score parfait de 100 %. Mais ce score parfait signifie-t-il qu'ils possèdent tous le même niveau d'intelligence ou qu'ils ont atteint le sommet de leur potentiel mental ? Bien sûr que non. Ces benchmarks ne sont que des estimations approximatives, pas des indicateurs précis des véritables capacités de quelqu'un.
Dans le monde de l'IA générative, des benchmarks comme le MMLU (Massive Multitask Language Understanding) sont devenus la référence pour évaluer les modèles à travers des questions à choix multiples couvrant divers domaines académiques. Bien qu'ils permettent des comparaisons faciles, ils ne capturent pas vraiment l'ensemble des capacités intelligentes.
Prenez Claude 3.5 Sonnet et GPT-4.5, par exemple. Ils pourraient obtenir des scores similaires au MMLU, suggérant qu'ils sont à égalité. Mais quiconque a réellement utilisé ces modèles sait que leurs performances dans le monde réel peuvent être très différentes.
Que signifie mesurer l'« intelligence » dans l'IA ?
Avec le lancement récent du benchmark ARC-AGI, conçu pour tester les modèles sur le raisonnement général et la résolution créative de problèmes, une nouvelle vague de discussions a émergé sur ce que signifie mesurer l'« intelligence » dans l'IA. Tout le monde n'a pas encore eu l'occasion d'explorer ARC-AGI, mais l'industrie est en effervescence à propos de cette approche et d'autres nouvelles méthodes de test. Chaque benchmark a sa place, et ARC-AGI est un pas dans la bonne direction.
Un autre développement passionnant est « Humanity's Last Exam », un benchmark complet comprenant 3 000 questions en plusieurs étapes, validées par des pairs, couvrant différentes disciplines. C'est un effort ambitieux pour pousser les systèmes d'IA à un raisonnement de niveau expert. Les premiers résultats montrent des progrès rapides, avec OpenAI atteignant un score de 26,6 % juste un mois après sa sortie. Mais comme d'autres benchmarks, il se concentre principalement sur la connaissance et le raisonnement dans un vide, et non sur les compétences pratiques d'utilisation d'outils, essentielles pour les applications d'IA dans le monde réel.
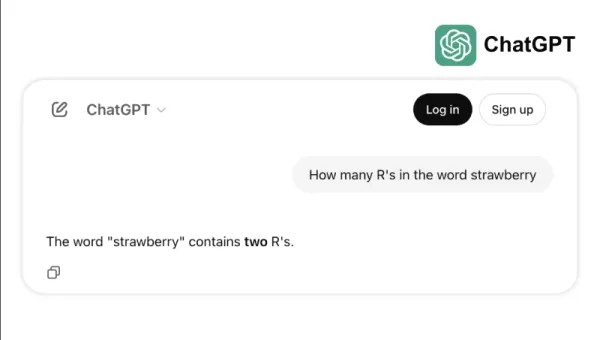
Prenez, par exemple, la difficulté de certains modèles de pointe à accomplir des tâches simples comme compter les « r » dans « strawberry » ou comparer 3,8 à 3,1111. Ces erreurs, qu'un enfant ou une calculatrice basique pourrait éviter, mettent en lumière l'écart entre le succès aux benchmarks et la fiabilité dans le monde réel. Cela rappelle que l'intelligence ne se résume pas à réussir des tests ; il s'agit de naviguer dans la logique quotidienne avec aisance.
La nouvelle norme pour mesurer les capacités de l'IA
À mesure que les modèles d'IA ont évolué, les limites des benchmarks traditionnels sont devenues plus évidentes. Par exemple, GPT-4, lorsqu'il est équipé d'outils, n'obtient qu'environ 15 % sur les tâches plus complexes du monde réel dans le benchmark GAIA, malgré ses scores élevés aux tests à choix multiples.
Cet écart entre les performances aux benchmarks et les capacités pratiques devient de plus en plus problématique à mesure que les systèmes d'IA passent des laboratoires de recherche aux applications commerciales. Les benchmarks traditionnels testent la capacité d'un modèle à se souvenir d'informations, mais négligent souvent des aspects clés de l'intelligence, comme la capacité à collecter des données, exécuter du code, analyser des informations et créer des solutions dans divers domaines.
Voici GAIA, un nouveau benchmark qui marque un changement significatif dans l'évaluation de l'IA. Développé grâce à une collaboration entre les équipes de Meta-FAIR, Meta-GenAI, HuggingFace et AutoGPT, GAIA comprend 466 questions soigneusement conçues, réparties sur trois niveaux de difficulté. Ces questions testent un large éventail de compétences essentielles pour les applications d'IA dans le monde réel, y compris la navigation sur le web, la compréhension multimodale, l'exécution de code, la gestion de fichiers et le raisonnement complexe.
Les questions de niveau 1 nécessitent généralement environ 5 étapes et un outil pour être résolues par des humains. Les questions de niveau 2 nécessitent de 5 à 10 étapes et plusieurs outils, tandis que les questions de niveau 3 peuvent exiger jusqu'à 50 étapes et un nombre quelconque d'outils. Cette structure reflète la complexité des problèmes commerciaux réels, où les solutions impliquent souvent plusieurs actions et outils.
En se concentrant sur la flexibilité plutôt que sur la simple complexité, un modèle d'IA a atteint un taux de précision de 75 % sur GAIA, surpassant les leaders de l'industrie comme Microsoft's Magnetic-1 (38 %) et Google's Langfun Agent (49 %). Ce succès provient de l'utilisation d'un mélange de modèles spécialisés pour la compréhension audiovisuelle et le raisonnement, avec Anthropic's Sonnet 3.5 comme modèle principal.
Ce changement dans l'évaluation de l'IA reflète une tendance plus large dans l'industrie : nous nous éloignons des applications SaaS autonomes vers des agents d'IA capables de gérer plusieurs outils et flux de travail. À mesure que les entreprises dépendent de plus en plus de l'IA pour relever des défis complexes et multi-étapes, des benchmarks comme GAIA offrent une mesure plus pertinente des capacités que les tests à choix multiples traditionnels.
L'avenir de l'évaluation de l'IA ne repose pas sur des tests de connaissances isolés ; il s'agit d'évaluations complètes des capacités de résolution de problèmes. GAIA établit une nouvelle norme pour mesurer les capacités de l'IA, une norme qui s'aligne mieux avec les défis et opportunités réels du déploiement de l'IA.
Sri Ambati est le fondateur et PDG de H2O.ai.
Article connexe
 L'IA révèle les intentions cachées dans les contenus d'actualité
Les modèles de type ChatGPT sont désormais entraînés à mettre au jour le point de vue sous-jacent d'un article d'actualité, même lorsque celui-ci est dissimulé derrière des citations, un cadrage ou un
Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour
Recommandations de sujets spéciaux liés
Entreprise
L'IA révèle les intentions cachées dans les contenus d'actualité
Les modèles de type ChatGPT sont désormais entraînés à mettre au jour le point de vue sous-jacent d'un article d'actualité, même lorsque celui-ci est dissimulé derrière des citations, un cadrage ou un
Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (4)
commentaires (4)
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
L'intelligence est omniprésente, mais la mesurer précisément revient à essayer d'attraper un nuage à mains nues. Nous utilisons des tests et des benchmarks, comme les examens d'entrée à l'université, pour en avoir une idée approximative. Chaque année, les étudiants se préparent intensément pour ces tests, certains obtenant même un score parfait de 100 %. Mais ce score parfait signifie-t-il qu'ils possèdent tous le même niveau d'intelligence ou qu'ils ont atteint le sommet de leur potentiel mental ? Bien sûr que non. Ces benchmarks ne sont que des estimations approximatives, pas des indicateurs précis des véritables capacités de quelqu'un.
Dans le monde de l'IA générative, des benchmarks comme le MMLU (Massive Multitask Language Understanding) sont devenus la référence pour évaluer les modèles à travers des questions à choix multiples couvrant divers domaines académiques. Bien qu'ils permettent des comparaisons faciles, ils ne capturent pas vraiment l'ensemble des capacités intelligentes.
Prenez Claude 3.5 Sonnet et GPT-4.5, par exemple. Ils pourraient obtenir des scores similaires au MMLU, suggérant qu'ils sont à égalité. Mais quiconque a réellement utilisé ces modèles sait que leurs performances dans le monde réel peuvent être très différentes.
Que signifie mesurer l'« intelligence » dans l'IA ?
Avec le lancement récent du benchmark ARC-AGI, conçu pour tester les modèles sur le raisonnement général et la résolution créative de problèmes, une nouvelle vague de discussions a émergé sur ce que signifie mesurer l'« intelligence » dans l'IA. Tout le monde n'a pas encore eu l'occasion d'explorer ARC-AGI, mais l'industrie est en effervescence à propos de cette approche et d'autres nouvelles méthodes de test. Chaque benchmark a sa place, et ARC-AGI est un pas dans la bonne direction.
Un autre développement passionnant est « Humanity's Last Exam », un benchmark complet comprenant 3 000 questions en plusieurs étapes, validées par des pairs, couvrant différentes disciplines. C'est un effort ambitieux pour pousser les systèmes d'IA à un raisonnement de niveau expert. Les premiers résultats montrent des progrès rapides, avec OpenAI atteignant un score de 26,6 % juste un mois après sa sortie. Mais comme d'autres benchmarks, il se concentre principalement sur la connaissance et le raisonnement dans un vide, et non sur les compétences pratiques d'utilisation d'outils, essentielles pour les applications d'IA dans le monde réel.
Prenez, par exemple, la difficulté de certains modèles de pointe à accomplir des tâches simples comme compter les « r » dans « strawberry » ou comparer 3,8 à 3,1111. Ces erreurs, qu'un enfant ou une calculatrice basique pourrait éviter, mettent en lumière l'écart entre le succès aux benchmarks et la fiabilité dans le monde réel. Cela rappelle que l'intelligence ne se résume pas à réussir des tests ; il s'agit de naviguer dans la logique quotidienne avec aisance.
La nouvelle norme pour mesurer les capacités de l'IA
À mesure que les modèles d'IA ont évolué, les limites des benchmarks traditionnels sont devenues plus évidentes. Par exemple, GPT-4, lorsqu'il est équipé d'outils, n'obtient qu'environ 15 % sur les tâches plus complexes du monde réel dans le benchmark GAIA, malgré ses scores élevés aux tests à choix multiples.
Cet écart entre les performances aux benchmarks et les capacités pratiques devient de plus en plus problématique à mesure que les systèmes d'IA passent des laboratoires de recherche aux applications commerciales. Les benchmarks traditionnels testent la capacité d'un modèle à se souvenir d'informations, mais négligent souvent des aspects clés de l'intelligence, comme la capacité à collecter des données, exécuter du code, analyser des informations et créer des solutions dans divers domaines.
Voici GAIA, un nouveau benchmark qui marque un changement significatif dans l'évaluation de l'IA. Développé grâce à une collaboration entre les équipes de Meta-FAIR, Meta-GenAI, HuggingFace et AutoGPT, GAIA comprend 466 questions soigneusement conçues, réparties sur trois niveaux de difficulté. Ces questions testent un large éventail de compétences essentielles pour les applications d'IA dans le monde réel, y compris la navigation sur le web, la compréhension multimodale, l'exécution de code, la gestion de fichiers et le raisonnement complexe.
Les questions de niveau 1 nécessitent généralement environ 5 étapes et un outil pour être résolues par des humains. Les questions de niveau 2 nécessitent de 5 à 10 étapes et plusieurs outils, tandis que les questions de niveau 3 peuvent exiger jusqu'à 50 étapes et un nombre quelconque d'outils. Cette structure reflète la complexité des problèmes commerciaux réels, où les solutions impliquent souvent plusieurs actions et outils.
En se concentrant sur la flexibilité plutôt que sur la simple complexité, un modèle d'IA a atteint un taux de précision de 75 % sur GAIA, surpassant les leaders de l'industrie comme Microsoft's Magnetic-1 (38 %) et Google's Langfun Agent (49 %). Ce succès provient de l'utilisation d'un mélange de modèles spécialisés pour la compréhension audiovisuelle et le raisonnement, avec Anthropic's Sonnet 3.5 comme modèle principal.
Ce changement dans l'évaluation de l'IA reflète une tendance plus large dans l'industrie : nous nous éloignons des applications SaaS autonomes vers des agents d'IA capables de gérer plusieurs outils et flux de travail. À mesure que les entreprises dépendent de plus en plus de l'IA pour relever des défis complexes et multi-étapes, des benchmarks comme GAIA offrent une mesure plus pertinente des capacités que les tests à choix multiples traditionnels.
L'avenir de l'évaluation de l'IA ne repose pas sur des tests de connaissances isolés ; il s'agit d'évaluations complètes des capacités de résolution de problèmes. GAIA établit une nouvelle norme pour mesurer les capacités de l'IA, une norme qui s'aligne mieux avec les défis et opportunités réels du déploiement de l'IA.
Sri Ambati est le fondateur et PDG de H2O.ai.










 L'IA révèle les intentions cachées dans les contenus d'actualité
Les modèles de type ChatGPT sont désormais entraînés à mettre au jour le point de vue sous-jacent d'un article d'actualité, même lorsque celui-ci est dissimulé derrière des citations, un cadrage ou un
L'IA révèle les intentions cachées dans les contenus d'actualité
Les modèles de type ChatGPT sont désormais entraînés à mettre au jour le point de vue sous-jacent d'un article d'actualité, même lorsque celui-ci est dissimulé derrière des citations, un cadrage ou un
 Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
Claude 4.1 d'Anthropic surpasse les benchmarks de codage avant le lancement de GPT-5
Anthropic a dévoilé lundi une version améliorée de son modèle d'IA haut de gamme, établissant ainsi une nouvelle référence en matière de performances pour les tâches d'ingénierie logicielle. Ce lancem
 Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour
Nvidia dévoile le modèle d'IA open-source Nemotron-Nano-9B-v2, doté d'une fonction de raisonnement à double sens
Les petits modèles linguistiques font des vagues. Après le lancement du modèle de vision de la taille d'une montre connectée par Liquid AI, une spin-off du MIT, et de l'offre de Google pour

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













