




Gaia는 Arc-agi 이상의 True Intelligence를 찾기 위해 새로운 벤치 마크를 소개합니다.
지능은 어디에나 존재하지만, 그것을 정확히 측정하는 것은 맨손으로 구름을 잡으려는 것처럼 느껴집니다. 우리는 대학 입시와 같은 테스트와 벤치마크를 사용해 대략적인 아이디어를 얻습니다. 매년 학생들은 이러한 테스트를 위해 벼락치기를 하고, 때로는 100% 완벽한 점수를 받기도 합니다. 하지만 그 완벽한 점수가 그들이 모두 같은 수준의 지능을 가지고 있거나, 그들의 정신적 잠재력의 정점에 도달했음을 의미할까요? 물론 아닙니다. 이러한 벤치마크는 대략적인 추정치일 뿐, 누군가의 진정한 능력을 정확히 나타내는 지표는 아닙니다.
생성 AI의 세계에서는 MMLU(Massive Multitask Language Understanding)와 같은 벤치마크가 다양한 학문 분야에 걸친 다지선다 질문을 통해 모델을 평가하는 데 주로 사용되었습니다. 이는 쉬운 비교를 가능하게 하지만, 지능적 능력의 전체 스펙트럼을 완전히 포착하지는 못합니다.
예를 들어, Claude 3.5 Sonnet과 GPT-4.5를 살펴보면, 그들은 MMLU에서 비슷한 점수를 받을 수 있어 비슷한 수준으로 보일 수 있습니다. 하지만 이 모델들을 실제로 사용해본 사람은 그들의 실세계 성능이 상당히 다를 수 있다는 것을 압니다.
AI에서 '지능'을 측정한다는 것은 무엇을 의미할까?
최근 ARC-AGI 벤치마크가 출시되면서, 일반적 추론과 창의적 문제 해결을 테스트하기 위해 설계된 이 벤치마크는 AI에서 "지능"을 측정하는 것이 무엇을 의미하는지에 대한 새로운 논의를 불러일으켰습니다. 아직 모두가 ARC-AGI를 깊이 탐구할 기회는 없었지만, 업계는 이와 다른 새로운 테스트 접근법에 대해 떠들썩합니다. 모든 벤치마크는 제자리를 가지고 있으며, ARC-AGI는 올바른 방향으로 나아가는 한 걸음입니다.
또 다른 흥미로운 발전은 3,000개의 동료 검토를 거친 다단계 질문으로 구성된 포괄적인 벤치마크인 'Humanity's Last Exam'입니다. 이는 AI 시스템을 전문가 수준의 추론으로 밀어붙이려는 야심찬 노력입니다. 초기 결과는 빠른 진전을 보여주며, OpenAI는 출시 한 달 만에 26.6%의 점수를 기록했다고 전해집니다. 하지만 다른 벤치마크와 마찬가지로, 이는 주로 지식과 추론에 초점을 맞추며, 실세계 AI 응용에 필수적인 실용적이고 도구를 사용하는 기술에는 집중하지 않습니다.
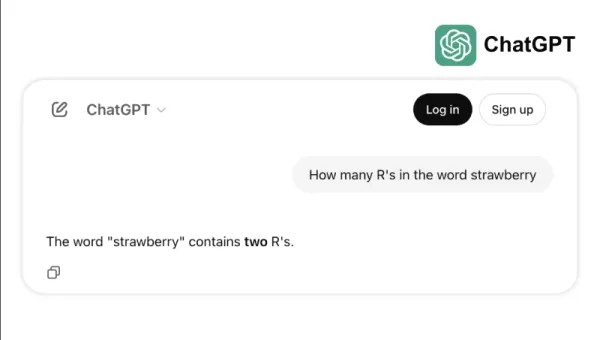
예를 들어, 일부 최고 모델들이 "strawberry"에서 "r"의 개수를 세는 것과 같은 간단한 작업이나 3.8과 3.1111을 비교하는 데 어려움을 겪는 경우를 생각해보세요. 이러한 오류는 어린이나 기본 계산기조차 피할 수 있는 것인데, 이는 벤치마크 성공과 실세계 신뢰성 사이의 간극을 보여줍니다. 이는 지능이 단순히 테스트를 잘 치는 것뿐만 아니라, 일상적인 논리를 쉽게 탐색하는 것에 관한 것임을 상기시킵니다.
AI 능력 측정을 위한 새로운 표준
AI 모델이 발전함에 따라 전통적인 벤치마크의 한계가 더욱 명확해졌습니다. 예를 들어, GPT-4는 도구를 사용할 때 GAIA 벤치마크의 더 복잡한 실세계 작업에서 약 15%의 점수만을 기록하며, 다지선다 테스트에서의 높은 점수에도 불구하고 한계를 드러냅니다.
벤치마크 성능과 실제 능력 간의 이러한 불일치는 AI 시스템이 연구실에서 비즈니스 응용으로 전환됨에 따라 점점 더 문제가 됩니다. 전통적인 벤치마크는 모델이 정보를 얼마나 잘 회상하는지를 테스트하지만, 데이터를 수집하고, 코드를 실행하고, 정보를 분석하고, 다양한 도메인에서 솔루션을 만드는 등의 핵심 지능 요소는 종종 간과됩니다.
GAIA는 AI 평가에 있어 중대한 변화를 가져오는 새로운 벤치마크입니다. Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPT 팀의 협력을 통해 개발된 GAIA는 466개의 세심하게 제작된 질문을 세 가지 난이도 수준으로 포함합니다. 이러한 질문들은 웹 브라우징, 다중 모달 이해, 코드 실행, 파일 처리, 복잡한 추론 등 실세계 AI 응용에 필수적인 다양한 기술을 테스트합니다.
레벨 1 질문은 일반적으로 인간이 해결하는 데 약 5단계와 하나의 도구를 필요로 합니다. 레벨 2 질문은 5~10단계와 여러 도구를 요구하며, 레벨 3 질문은 최대 50단계와 다양한 도구를 요구할 수 있습니다. 이 구조는 실제 비즈니스 문제의 복잡성을 반영하며, 솔루션은 종종 여러 행동과 도구를 포함합니다.
복잡성뿐만 아니라 유연성에 초점을 맞춤으로써, 한 AI 모델은 GAIA에서 75%의 정확도를 달성하며 Microsoft의 Magnetic-1(38%)과 Google의 Langfun Agent(49%)와 같은 업계 리더를 능가했습니다. 이 성공은 오디오-비주얼 이해와 추론을 위한 특화된 모델을 혼합하고, Anthropic의 Sonnet 3.5를 메인 모델로 사용한 결과입니다.
AI 평가의 이러한 변화는 업계의 더 넓은 트렌드를 반영합니다: 우리는 독립형 SaaS 애플리케이션에서 여러 도구와 워크플로우를 관리할 수 있는 AI 에이전트로 이동하고 있습니다. 비즈니스가 복잡한 다단계 작업을 처리하기 위해 AI에 점점 더 의존함에 따라, GAIA와 같은 벤치마크는 전통적인 다지선다 테스트보다 더 적절한 능력 측정 기준을 제공합니다.
AI 평가의 미래는 고립된 지식 테스트에 관한 것이 아니라, 문제 해결 능력에 대한 포괄적인 평가에 관한 것입니다. GAIA는 AI 능력을 측정하는 새로운 벤치마크를 설정하며, 이는 AI 배포의 실세계 도전과 기회에 더 잘 맞는 기준입니다.
Sri Ambati는 H2O.ai의 창립자이자 CEO입니다.
관련 기사
 텐서제로, 기업용 LLM 개발 간소화를 위해 730만 달러의 시드 펀딩 유치
AI 애플리케이션을 위한 오픈소스 인프라 제공업체로 떠오르고 있는 TensorZero는 FirstMark Capital이 주도하는 730만 달러의 시드 펀딩을 확보했으며, 베세머 벤처 파트너스, 베드락, DRW, Coalition 및 다수의 업계 엔젤이 참여했습니다.이번 투자는 최근 몇 달 동안 별 수가 3,000개에서 9,700개로 3배 가까이 증가하
Replit CEO, 소프트웨어의 미래 예측: '에이전트가 완전히 사라질 것'
협업형 AI 개발 플랫폼으로 기업이 값비싼 SaaS 구독에서 벗어날 수 있을까요? Replit의 선구적인 CEO Amjad Masad는 "에이전트가 모든 것을 재귀적으로 처리하는" 생태계를 설명하면서 이러한 변화는 이미 진행 중이라고 믿습니다.마사드는 VB 트랜스폼 기조연설에서 Replit의 AI 에이전트를 통해 기술 전문가가 아닌 사용자가 간단한 텍스트
OpenAI, ChatGPT Pro를 o3로 업그레이드하고 월 구독료 $200로 가치 증대
이번 주에는 마이크로소프트, 구글, 앤트로픽을 비롯한 거대 기술 기업들의 중요한 AI 개발이 있었습니다. OpenAI는 코드명 "io"라는 야심찬 하드웨어 이니셔티브를 위해 65억 달러에 인수한 조니 아이브의 디자인 회사를 넘어서는 획기적인 업데이트를 발표하며 활발한 발표를 마무리했습니다.이 회사는 이전의 GPT-4o 프레임워크에서 고급 추론 모델인 o3로
의견 (2)
0/200
텐서제로, 기업용 LLM 개발 간소화를 위해 730만 달러의 시드 펀딩 유치
AI 애플리케이션을 위한 오픈소스 인프라 제공업체로 떠오르고 있는 TensorZero는 FirstMark Capital이 주도하는 730만 달러의 시드 펀딩을 확보했으며, 베세머 벤처 파트너스, 베드락, DRW, Coalition 및 다수의 업계 엔젤이 참여했습니다.이번 투자는 최근 몇 달 동안 별 수가 3,000개에서 9,700개로 3배 가까이 증가하
Replit CEO, 소프트웨어의 미래 예측: '에이전트가 완전히 사라질 것'
협업형 AI 개발 플랫폼으로 기업이 값비싼 SaaS 구독에서 벗어날 수 있을까요? Replit의 선구적인 CEO Amjad Masad는 "에이전트가 모든 것을 재귀적으로 처리하는" 생태계를 설명하면서 이러한 변화는 이미 진행 중이라고 믿습니다.마사드는 VB 트랜스폼 기조연설에서 Replit의 AI 에이전트를 통해 기술 전문가가 아닌 사용자가 간단한 텍스트
OpenAI, ChatGPT Pro를 o3로 업그레이드하고 월 구독료 $200로 가치 증대
이번 주에는 마이크로소프트, 구글, 앤트로픽을 비롯한 거대 기술 기업들의 중요한 AI 개발이 있었습니다. OpenAI는 코드명 "io"라는 야심찬 하드웨어 이니셔티브를 위해 65억 달러에 인수한 조니 아이브의 디자인 회사를 넘어서는 획기적인 업데이트를 발표하며 활발한 발표를 마무리했습니다.이 회사는 이전의 GPT-4o 프레임워크에서 고급 추론 모델인 o3로
의견 (2)
0/200
![BillyAdams]() BillyAdams
BillyAdams
 2025년 8월 26일 오후 5시 25분 46초 GMT+09:00
2025년 8월 26일 오후 5시 25분 46초 GMT+09:00
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?


 0
0
![GaryThomas]() GaryThomas
2025년 8월 8일 오후 1시 1분 29초 GMT+09:00
GaryThomas
2025년 8월 8일 오후 1시 1분 29초 GMT+09:00
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0
지능은 어디에나 존재하지만, 그것을 정확히 측정하는 것은 맨손으로 구름을 잡으려는 것처럼 느껴집니다. 우리는 대학 입시와 같은 테스트와 벤치마크를 사용해 대략적인 아이디어를 얻습니다. 매년 학생들은 이러한 테스트를 위해 벼락치기를 하고, 때로는 100% 완벽한 점수를 받기도 합니다. 하지만 그 완벽한 점수가 그들이 모두 같은 수준의 지능을 가지고 있거나, 그들의 정신적 잠재력의 정점에 도달했음을 의미할까요? 물론 아닙니다. 이러한 벤치마크는 대략적인 추정치일 뿐, 누군가의 진정한 능력을 정확히 나타내는 지표는 아닙니다.
생성 AI의 세계에서는 MMLU(Massive Multitask Language Understanding)와 같은 벤치마크가 다양한 학문 분야에 걸친 다지선다 질문을 통해 모델을 평가하는 데 주로 사용되었습니다. 이는 쉬운 비교를 가능하게 하지만, 지능적 능력의 전체 스펙트럼을 완전히 포착하지는 못합니다.
예를 들어, Claude 3.5 Sonnet과 GPT-4.5를 살펴보면, 그들은 MMLU에서 비슷한 점수를 받을 수 있어 비슷한 수준으로 보일 수 있습니다. 하지만 이 모델들을 실제로 사용해본 사람은 그들의 실세계 성능이 상당히 다를 수 있다는 것을 압니다.
AI에서 '지능'을 측정한다는 것은 무엇을 의미할까?
최근 ARC-AGI 벤치마크가 출시되면서, 일반적 추론과 창의적 문제 해결을 테스트하기 위해 설계된 이 벤치마크는 AI에서 "지능"을 측정하는 것이 무엇을 의미하는지에 대한 새로운 논의를 불러일으켰습니다. 아직 모두가 ARC-AGI를 깊이 탐구할 기회는 없었지만, 업계는 이와 다른 새로운 테스트 접근법에 대해 떠들썩합니다. 모든 벤치마크는 제자리를 가지고 있으며, ARC-AGI는 올바른 방향으로 나아가는 한 걸음입니다.
또 다른 흥미로운 발전은 3,000개의 동료 검토를 거친 다단계 질문으로 구성된 포괄적인 벤치마크인 'Humanity's Last Exam'입니다. 이는 AI 시스템을 전문가 수준의 추론으로 밀어붙이려는 야심찬 노력입니다. 초기 결과는 빠른 진전을 보여주며, OpenAI는 출시 한 달 만에 26.6%의 점수를 기록했다고 전해집니다. 하지만 다른 벤치마크와 마찬가지로, 이는 주로 지식과 추론에 초점을 맞추며, 실세계 AI 응용에 필수적인 실용적이고 도구를 사용하는 기술에는 집중하지 않습니다.
예를 들어, 일부 최고 모델들이 "strawberry"에서 "r"의 개수를 세는 것과 같은 간단한 작업이나 3.8과 3.1111을 비교하는 데 어려움을 겪는 경우를 생각해보세요. 이러한 오류는 어린이나 기본 계산기조차 피할 수 있는 것인데, 이는 벤치마크 성공과 실세계 신뢰성 사이의 간극을 보여줍니다. 이는 지능이 단순히 테스트를 잘 치는 것뿐만 아니라, 일상적인 논리를 쉽게 탐색하는 것에 관한 것임을 상기시킵니다.
AI 능력 측정을 위한 새로운 표준
AI 모델이 발전함에 따라 전통적인 벤치마크의 한계가 더욱 명확해졌습니다. 예를 들어, GPT-4는 도구를 사용할 때 GAIA 벤치마크의 더 복잡한 실세계 작업에서 약 15%의 점수만을 기록하며, 다지선다 테스트에서의 높은 점수에도 불구하고 한계를 드러냅니다.
벤치마크 성능과 실제 능력 간의 이러한 불일치는 AI 시스템이 연구실에서 비즈니스 응용으로 전환됨에 따라 점점 더 문제가 됩니다. 전통적인 벤치마크는 모델이 정보를 얼마나 잘 회상하는지를 테스트하지만, 데이터를 수집하고, 코드를 실행하고, 정보를 분석하고, 다양한 도메인에서 솔루션을 만드는 등의 핵심 지능 요소는 종종 간과됩니다.
GAIA는 AI 평가에 있어 중대한 변화를 가져오는 새로운 벤치마크입니다. Meta-FAIR, Meta-GenAI, HuggingFace, AutoGPT 팀의 협력을 통해 개발된 GAIA는 466개의 세심하게 제작된 질문을 세 가지 난이도 수준으로 포함합니다. 이러한 질문들은 웹 브라우징, 다중 모달 이해, 코드 실행, 파일 처리, 복잡한 추론 등 실세계 AI 응용에 필수적인 다양한 기술을 테스트합니다.
레벨 1 질문은 일반적으로 인간이 해결하는 데 약 5단계와 하나의 도구를 필요로 합니다. 레벨 2 질문은 5~10단계와 여러 도구를 요구하며, 레벨 3 질문은 최대 50단계와 다양한 도구를 요구할 수 있습니다. 이 구조는 실제 비즈니스 문제의 복잡성을 반영하며, 솔루션은 종종 여러 행동과 도구를 포함합니다.
복잡성뿐만 아니라 유연성에 초점을 맞춤으로써, 한 AI 모델은 GAIA에서 75%의 정확도를 달성하며 Microsoft의 Magnetic-1(38%)과 Google의 Langfun Agent(49%)와 같은 업계 리더를 능가했습니다. 이 성공은 오디오-비주얼 이해와 추론을 위한 특화된 모델을 혼합하고, Anthropic의 Sonnet 3.5를 메인 모델로 사용한 결과입니다.
AI 평가의 이러한 변화는 업계의 더 넓은 트렌드를 반영합니다: 우리는 독립형 SaaS 애플리케이션에서 여러 도구와 워크플로우를 관리할 수 있는 AI 에이전트로 이동하고 있습니다. 비즈니스가 복잡한 다단계 작업을 처리하기 위해 AI에 점점 더 의존함에 따라, GAIA와 같은 벤치마크는 전통적인 다지선다 테스트보다 더 적절한 능력 측정 기준을 제공합니다.
AI 평가의 미래는 고립된 지식 테스트에 관한 것이 아니라, 문제 해결 능력에 대한 포괄적인 평가에 관한 것입니다. GAIA는 AI 능력을 측정하는 새로운 벤치마크를 설정하며, 이는 AI 배포의 실세계 도전과 기회에 더 잘 맞는 기준입니다.
Sri Ambati는 H2O.ai의 창립자이자 CEO입니다.










 텐서제로, 기업용 LLM 개발 간소화를 위해 730만 달러의 시드 펀딩 유치
AI 애플리케이션을 위한 오픈소스 인프라 제공업체로 떠오르고 있는 TensorZero는 FirstMark Capital이 주도하는 730만 달러의 시드 펀딩을 확보했으며, 베세머 벤처 파트너스, 베드락, DRW, Coalition 및 다수의 업계 엔젤이 참여했습니다.이번 투자는 최근 몇 달 동안 별 수가 3,000개에서 9,700개로 3배 가까이 증가하
텐서제로, 기업용 LLM 개발 간소화를 위해 730만 달러의 시드 펀딩 유치
AI 애플리케이션을 위한 오픈소스 인프라 제공업체로 떠오르고 있는 TensorZero는 FirstMark Capital이 주도하는 730만 달러의 시드 펀딩을 확보했으며, 베세머 벤처 파트너스, 베드락, DRW, Coalition 및 다수의 업계 엔젤이 참여했습니다.이번 투자는 최근 몇 달 동안 별 수가 3,000개에서 9,700개로 3배 가까이 증가하
 Replit CEO, 소프트웨어의 미래 예측: '에이전트가 완전히 사라질 것'
협업형 AI 개발 플랫폼으로 기업이 값비싼 SaaS 구독에서 벗어날 수 있을까요? Replit의 선구적인 CEO Amjad Masad는 "에이전트가 모든 것을 재귀적으로 처리하는" 생태계를 설명하면서 이러한 변화는 이미 진행 중이라고 믿습니다.마사드는 VB 트랜스폼 기조연설에서 Replit의 AI 에이전트를 통해 기술 전문가가 아닌 사용자가 간단한 텍스트
Replit CEO, 소프트웨어의 미래 예측: '에이전트가 완전히 사라질 것'
협업형 AI 개발 플랫폼으로 기업이 값비싼 SaaS 구독에서 벗어날 수 있을까요? Replit의 선구적인 CEO Amjad Masad는 "에이전트가 모든 것을 재귀적으로 처리하는" 생태계를 설명하면서 이러한 변화는 이미 진행 중이라고 믿습니다.마사드는 VB 트랜스폼 기조연설에서 Replit의 AI 에이전트를 통해 기술 전문가가 아닌 사용자가 간단한 텍스트
 OpenAI, ChatGPT Pro를 o3로 업그레이드하고 월 구독료 $200로 가치 증대
이번 주에는 마이크로소프트, 구글, 앤트로픽을 비롯한 거대 기술 기업들의 중요한 AI 개발이 있었습니다. OpenAI는 코드명 "io"라는 야심찬 하드웨어 이니셔티브를 위해 65억 달러에 인수한 조니 아이브의 디자인 회사를 넘어서는 획기적인 업데이트를 발표하며 활발한 발표를 마무리했습니다.이 회사는 이전의 GPT-4o 프레임워크에서 고급 추론 모델인 o3로
2025년 8월 26일 오후 5시 25분 46초 GMT+09:00
OpenAI, ChatGPT Pro를 o3로 업그레이드하고 월 구독료 $200로 가치 증대
이번 주에는 마이크로소프트, 구글, 앤트로픽을 비롯한 거대 기술 기업들의 중요한 AI 개발이 있었습니다. OpenAI는 코드명 "io"라는 야심찬 하드웨어 이니셔티브를 위해 65억 달러에 인수한 조니 아이브의 디자인 회사를 넘어서는 획기적인 업데이트를 발표하며 활발한 발표를 마무리했습니다.이 회사는 이전의 GPT-4o 프레임워크에서 고급 추론 모델인 o3로
2025년 8월 26일 오후 5시 25분 46초 GMT+09:00
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
0
2025년 8월 8일 오후 1시 1분 29초 GMT+09:00
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0













