




Gaia führt einen neuen Benchmark in der Suche nach wahrer Intelligenz jenseits von Arc-Agi ein
Intelligenz ist überall, doch sie präzise zu messen, fühlt sich an, als wolle man mit bloßen Händen eine Wolke fangen. Wir verwenden Tests und Benchmarks, wie Hochschulaufnahmeprüfungen, um eine grobe Vorstellung zu bekommen. Jedes Jahr lernen Schüler intensiv für diese Tests und erzielen manchmal sogar perfekte 100 %. Aber bedeutet dieser perfekte Score, dass sie alle das gleiche Intelligenzniveau haben oder ihr geistiges Potenzial vollständig ausgeschöpft haben? Natürlich nicht. Diese Benchmarks sind nur grobe Schätzungen, keine präzisen Indikatoren für die wahren Fähigkeiten einer Person.
In der Welt der generativen KI sind Benchmarks wie MMLU (Massive Multitask Language Understanding) die Standardmethode, um Modelle durch Multiple-Choice-Fragen in verschiedenen akademischen Bereichen zu bewerten. Sie ermöglichen einfache Vergleiche, erfassen jedoch nicht das volle Spektrum intelligenter Fähigkeiten.
Nehmen wir zum Beispiel Claude 3.5 Sonnet und GPT-4.5. Sie könnten bei MMLU ähnliche Werte erzielen, was nahelegt, dass sie gleichwertig sind. Doch jeder, der diese Modelle tatsächlich genutzt hat, weiß, dass ihre Leistung in der realen Welt ganz unterschiedlich sein kann.
Was bedeutet es, "Intelligenz" in KI zu messen?
Mit der kürzlichen Einführung des ARC-AGI-Benchmarks, der darauf ausgelegt ist, Modelle in allgemeinem Denken und kreativer Problemlösung zu testen, gibt es eine neue Welle der Diskussion darüber, was es bedeutet, "Intelligenz" in KI zu messen. Noch nicht jeder hatte die Gelegenheit, ARC-AGI auszuprobieren, aber die Branche spricht lebhaft über diesen und andere neue Testansätze. Jeder Benchmark hat seinen Platz, und ARC-AGI ist ein Schritt in die richtige Richtung.
Eine weitere spannende Entwicklung ist "Humanity's Last Exam", ein umfassender Benchmark mit 3.000 von Experten begutachteten, mehrstufigen Fragen aus verschiedenen Disziplinen. Es ist ein ambitionierter Versuch, KI-Systeme zu expertenniveauartigem Denken zu pushen. Erste Ergebnisse zeigen schnelle Fortschritte, wobei OpenAI angeblich einen Monat nach Veröffentlichung 26,6 % erreicht hat. Doch wie andere Benchmarks konzentriert er sich hauptsächlich auf Wissen und Denken im Vakuum, nicht auf praktische, werkzeugbasierte Fähigkeiten, die für reale KI-Anwendungen entscheidend sind.
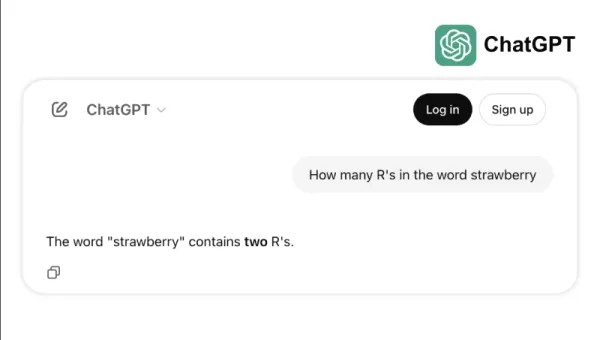
Nehmen wir zum Beispiel, wie einige Top-Modelle bei einfachen Aufgaben wie dem Zählen der "r"s in "strawberry" oder dem Vergleich von 3,8 zu 3,1111 scheitern. Diese Fehler, die selbst ein Kind oder ein einfacher Taschenrechner vermeiden könnte, verdeutlichen die Kluft zwischen Benchmark-Erfolg und realer Zuverlässigkeit. Es erinnert daran, dass Intelligenz nicht nur darin besteht, Tests zu bestehen, sondern alltägliche Logik mühelos zu meistern.
Der neue Standard zur Messung von KI-Fähigkeiten
Mit der Weiterentwicklung von KI-Modellen sind die Grenzen traditioneller Benchmarks immer offensichtlicher geworden. Zum Beispiel erreicht GPT-4, wenn es mit Werkzeugen ausgestattet ist, nur etwa 15 % bei komplexeren, realen Aufgaben im GAIA-Benchmark, trotz hoher Punktzahlen bei Multiple-Choice-Tests.
Diese Diskrepanz zwischen Benchmark-Leistung und praktischer Fähigkeit wird zunehmend problematisch, da KI-Systeme von Forschungslaboren zu Geschäftsanwendungen übergehen. Traditionelle Benchmarks testen, wie gut ein Modell Informationen abrufen kann, übersehen jedoch oft Schlüsselaspekte der Intelligenz, wie die Fähigkeit, Daten zu sammeln, Code auszuführen, Informationen zu analysieren und Lösungen in verschiedenen Bereichen zu entwickeln.
Hier kommt GAIA ins Spiel, ein neuer Benchmark, der einen bedeutenden Wandel in der KI-Bewertung markiert. Entwickelt durch eine Zusammenarbeit von Teams aus Meta-FAIR, Meta-GenAI, HuggingFace und AutoGPT, umfasst GAIA 466 sorgfältig gestaltete Fragen auf drei Schwierigkeitsstufen. Diese Fragen testen eine Vielzahl von Fähigkeiten, die für reale KI-Anwendungen entscheidend sind, einschließlich Webbrowsing, multimodalem Verständnis, Codeausführung, Dateihandling und komplexem Denken.
Fragen der Stufe 1 erfordern typischerweise etwa 5 Schritte und ein Werkzeug, um von Menschen gelöst zu werden. Fragen der Stufe 2 benötigen 5 bis 10 Schritte und mehrere Werkzeuge, während Fragen der Stufe 3 bis zu 50 Schritte und beliebig viele Werkzeuge verlangen können. Diese Struktur spiegelt die Komplexität realer Geschäftsprobleme wider, bei denen Lösungen oft mehrere Aktionen und Werkzeuge umfassen.
Indem ein KI-Modell mit Fokus auf Flexibilität statt nur Komplexität eine Genauigkeitsrate von 75 % auf GAIA erreichte, übertraf es Branchenführer wie Microsofts Magnetic-1 (38 %) und Googles Langfun Agent (49 %). Dieser Erfolg resultiert aus der Nutzung einer Mischung aus spezialisierten Modellen für audiovisuelles Verständnis und Denken, mit Anthropics Sonnet 3.5 als Hauptmodell.
Dieser Wandel in der KI-Bewertung spiegelt einen breiteren Trend in der Branche wider: Wir bewegen uns weg von eigenständigen SaaS-Anwendungen hin zu KI-Agenten, die mehrere Werkzeuge und Arbeitsabläufe verwalten können. Da Unternehmen zunehmend auf KI angewiesen sind, um komplexe, mehrstufige Aufgaben zu bewältigen, bieten Benchmarks wie GAIA eine relevantere Messgröße für Fähigkeiten als traditionelle Multiple-Choice-Tests.
Die Zukunft der KI-Bewertung dreht sich nicht um isolierte Wissenstests; es geht um umfassende Bewertungen der Problemlösungsfähigkeit. GAIA setzt einen neuen Maßstab für die Messung von KI-Fähigkeiten – einen, der besser mit den realen Herausforderungen und Möglichkeiten der KI-Einführung übereinstimmt.
Sri Ambati ist der Gründer und CEO von H2O.ai.
Verwandter Artikel
 TensorZero sichert $7.3M Seed Funding zur Vereinfachung der LLM-Entwicklung für Unternehmen
TensorZero, ein aufstrebender Open-Source-Infrastrukturanbieter für KI-Anwendungen, hat sich eine Startfinanzierung in Höhe von 7,3 Millionen US-Dollar unter der Leitung von FirstMark Capital gesicher
Der CEO von Replit prognostiziert die Software-Zukunft: "Agenten auf dem Weg nach unten".
Könnten kollaborative KI-Entwicklungsplattformen es Unternehmen ermöglichen, sich von kostspieligen SaaS-Abonnements zu befreien? Der visionäre CEO von Replit, Amjad Masad, glaubt, dass dieser Wandel
OpenAI wertet ChatGPT Pro auf o3 auf und steigert den Wert des $200 Monatsabonnements
Diese Woche gab es bedeutende KI-Entwicklungen von Tech-Giganten wie Microsoft, Google und Anthropic. OpenAI schließt den Reigen der Ankündigungen mit seinen eigenen bahnbrechenden Updates ab, die übe
Kommentare (2)
0/200
TensorZero sichert $7.3M Seed Funding zur Vereinfachung der LLM-Entwicklung für Unternehmen
TensorZero, ein aufstrebender Open-Source-Infrastrukturanbieter für KI-Anwendungen, hat sich eine Startfinanzierung in Höhe von 7,3 Millionen US-Dollar unter der Leitung von FirstMark Capital gesicher
Der CEO von Replit prognostiziert die Software-Zukunft: "Agenten auf dem Weg nach unten".
Könnten kollaborative KI-Entwicklungsplattformen es Unternehmen ermöglichen, sich von kostspieligen SaaS-Abonnements zu befreien? Der visionäre CEO von Replit, Amjad Masad, glaubt, dass dieser Wandel
OpenAI wertet ChatGPT Pro auf o3 auf und steigert den Wert des $200 Monatsabonnements
Diese Woche gab es bedeutende KI-Entwicklungen von Tech-Giganten wie Microsoft, Google und Anthropic. OpenAI schließt den Reigen der Ankündigungen mit seinen eigenen bahnbrechenden Updates ab, die übe
Kommentare (2)
0/200
![BillyAdams]() BillyAdams
BillyAdams
 26. August 2025 10:25:46 MESZ
26. August 2025 10:25:46 MESZ
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?


 0
0
![GaryThomas]() GaryThomas
8. August 2025 06:01:29 MESZ
GaryThomas
8. August 2025 06:01:29 MESZ
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0
Intelligenz ist überall, doch sie präzise zu messen, fühlt sich an, als wolle man mit bloßen Händen eine Wolke fangen. Wir verwenden Tests und Benchmarks, wie Hochschulaufnahmeprüfungen, um eine grobe Vorstellung zu bekommen. Jedes Jahr lernen Schüler intensiv für diese Tests und erzielen manchmal sogar perfekte 100 %. Aber bedeutet dieser perfekte Score, dass sie alle das gleiche Intelligenzniveau haben oder ihr geistiges Potenzial vollständig ausgeschöpft haben? Natürlich nicht. Diese Benchmarks sind nur grobe Schätzungen, keine präzisen Indikatoren für die wahren Fähigkeiten einer Person.
In der Welt der generativen KI sind Benchmarks wie MMLU (Massive Multitask Language Understanding) die Standardmethode, um Modelle durch Multiple-Choice-Fragen in verschiedenen akademischen Bereichen zu bewerten. Sie ermöglichen einfache Vergleiche, erfassen jedoch nicht das volle Spektrum intelligenter Fähigkeiten.
Nehmen wir zum Beispiel Claude 3.5 Sonnet und GPT-4.5. Sie könnten bei MMLU ähnliche Werte erzielen, was nahelegt, dass sie gleichwertig sind. Doch jeder, der diese Modelle tatsächlich genutzt hat, weiß, dass ihre Leistung in der realen Welt ganz unterschiedlich sein kann.
Was bedeutet es, "Intelligenz" in KI zu messen?
Mit der kürzlichen Einführung des ARC-AGI-Benchmarks, der darauf ausgelegt ist, Modelle in allgemeinem Denken und kreativer Problemlösung zu testen, gibt es eine neue Welle der Diskussion darüber, was es bedeutet, "Intelligenz" in KI zu messen. Noch nicht jeder hatte die Gelegenheit, ARC-AGI auszuprobieren, aber die Branche spricht lebhaft über diesen und andere neue Testansätze. Jeder Benchmark hat seinen Platz, und ARC-AGI ist ein Schritt in die richtige Richtung.
Eine weitere spannende Entwicklung ist "Humanity's Last Exam", ein umfassender Benchmark mit 3.000 von Experten begutachteten, mehrstufigen Fragen aus verschiedenen Disziplinen. Es ist ein ambitionierter Versuch, KI-Systeme zu expertenniveauartigem Denken zu pushen. Erste Ergebnisse zeigen schnelle Fortschritte, wobei OpenAI angeblich einen Monat nach Veröffentlichung 26,6 % erreicht hat. Doch wie andere Benchmarks konzentriert er sich hauptsächlich auf Wissen und Denken im Vakuum, nicht auf praktische, werkzeugbasierte Fähigkeiten, die für reale KI-Anwendungen entscheidend sind.
Nehmen wir zum Beispiel, wie einige Top-Modelle bei einfachen Aufgaben wie dem Zählen der "r"s in "strawberry" oder dem Vergleich von 3,8 zu 3,1111 scheitern. Diese Fehler, die selbst ein Kind oder ein einfacher Taschenrechner vermeiden könnte, verdeutlichen die Kluft zwischen Benchmark-Erfolg und realer Zuverlässigkeit. Es erinnert daran, dass Intelligenz nicht nur darin besteht, Tests zu bestehen, sondern alltägliche Logik mühelos zu meistern.
Der neue Standard zur Messung von KI-Fähigkeiten
Mit der Weiterentwicklung von KI-Modellen sind die Grenzen traditioneller Benchmarks immer offensichtlicher geworden. Zum Beispiel erreicht GPT-4, wenn es mit Werkzeugen ausgestattet ist, nur etwa 15 % bei komplexeren, realen Aufgaben im GAIA-Benchmark, trotz hoher Punktzahlen bei Multiple-Choice-Tests.
Diese Diskrepanz zwischen Benchmark-Leistung und praktischer Fähigkeit wird zunehmend problematisch, da KI-Systeme von Forschungslaboren zu Geschäftsanwendungen übergehen. Traditionelle Benchmarks testen, wie gut ein Modell Informationen abrufen kann, übersehen jedoch oft Schlüsselaspekte der Intelligenz, wie die Fähigkeit, Daten zu sammeln, Code auszuführen, Informationen zu analysieren und Lösungen in verschiedenen Bereichen zu entwickeln.
Hier kommt GAIA ins Spiel, ein neuer Benchmark, der einen bedeutenden Wandel in der KI-Bewertung markiert. Entwickelt durch eine Zusammenarbeit von Teams aus Meta-FAIR, Meta-GenAI, HuggingFace und AutoGPT, umfasst GAIA 466 sorgfältig gestaltete Fragen auf drei Schwierigkeitsstufen. Diese Fragen testen eine Vielzahl von Fähigkeiten, die für reale KI-Anwendungen entscheidend sind, einschließlich Webbrowsing, multimodalem Verständnis, Codeausführung, Dateihandling und komplexem Denken.
Fragen der Stufe 1 erfordern typischerweise etwa 5 Schritte und ein Werkzeug, um von Menschen gelöst zu werden. Fragen der Stufe 2 benötigen 5 bis 10 Schritte und mehrere Werkzeuge, während Fragen der Stufe 3 bis zu 50 Schritte und beliebig viele Werkzeuge verlangen können. Diese Struktur spiegelt die Komplexität realer Geschäftsprobleme wider, bei denen Lösungen oft mehrere Aktionen und Werkzeuge umfassen.
Indem ein KI-Modell mit Fokus auf Flexibilität statt nur Komplexität eine Genauigkeitsrate von 75 % auf GAIA erreichte, übertraf es Branchenführer wie Microsofts Magnetic-1 (38 %) und Googles Langfun Agent (49 %). Dieser Erfolg resultiert aus der Nutzung einer Mischung aus spezialisierten Modellen für audiovisuelles Verständnis und Denken, mit Anthropics Sonnet 3.5 als Hauptmodell.
Dieser Wandel in der KI-Bewertung spiegelt einen breiteren Trend in der Branche wider: Wir bewegen uns weg von eigenständigen SaaS-Anwendungen hin zu KI-Agenten, die mehrere Werkzeuge und Arbeitsabläufe verwalten können. Da Unternehmen zunehmend auf KI angewiesen sind, um komplexe, mehrstufige Aufgaben zu bewältigen, bieten Benchmarks wie GAIA eine relevantere Messgröße für Fähigkeiten als traditionelle Multiple-Choice-Tests.
Die Zukunft der KI-Bewertung dreht sich nicht um isolierte Wissenstests; es geht um umfassende Bewertungen der Problemlösungsfähigkeit. GAIA setzt einen neuen Maßstab für die Messung von KI-Fähigkeiten – einen, der besser mit den realen Herausforderungen und Möglichkeiten der KI-Einführung übereinstimmt.
Sri Ambati ist der Gründer und CEO von H2O.ai.










 TensorZero sichert $7.3M Seed Funding zur Vereinfachung der LLM-Entwicklung für Unternehmen
TensorZero, ein aufstrebender Open-Source-Infrastrukturanbieter für KI-Anwendungen, hat sich eine Startfinanzierung in Höhe von 7,3 Millionen US-Dollar unter der Leitung von FirstMark Capital gesicher
TensorZero sichert $7.3M Seed Funding zur Vereinfachung der LLM-Entwicklung für Unternehmen
TensorZero, ein aufstrebender Open-Source-Infrastrukturanbieter für KI-Anwendungen, hat sich eine Startfinanzierung in Höhe von 7,3 Millionen US-Dollar unter der Leitung von FirstMark Capital gesicher
 Der CEO von Replit prognostiziert die Software-Zukunft: "Agenten auf dem Weg nach unten".
Könnten kollaborative KI-Entwicklungsplattformen es Unternehmen ermöglichen, sich von kostspieligen SaaS-Abonnements zu befreien? Der visionäre CEO von Replit, Amjad Masad, glaubt, dass dieser Wandel
Der CEO von Replit prognostiziert die Software-Zukunft: "Agenten auf dem Weg nach unten".
Könnten kollaborative KI-Entwicklungsplattformen es Unternehmen ermöglichen, sich von kostspieligen SaaS-Abonnements zu befreien? Der visionäre CEO von Replit, Amjad Masad, glaubt, dass dieser Wandel
 OpenAI wertet ChatGPT Pro auf o3 auf und steigert den Wert des $200 Monatsabonnements
Diese Woche gab es bedeutende KI-Entwicklungen von Tech-Giganten wie Microsoft, Google und Anthropic. OpenAI schließt den Reigen der Ankündigungen mit seinen eigenen bahnbrechenden Updates ab, die übe
26. August 2025 10:25:46 MESZ
OpenAI wertet ChatGPT Pro auf o3 auf und steigert den Wert des $200 Monatsabonnements
Diese Woche gab es bedeutende KI-Entwicklungen von Tech-Giganten wie Microsoft, Google und Anthropic. OpenAI schließt den Reigen der Ankündigungen mit seinen eigenen bahnbrechenden Updates ab, die übe
26. August 2025 10:25:46 MESZ
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
0
8. August 2025 06:01:29 MESZ
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
0













