
















 Home
HomeGAIA Introduces New Benchmark in Quest for True Intelligence Beyond ARC-AGI
Intelligence is everywhere, yet gauging it accurately feels like trying to catch a cloud with your bare hands. We use tests and benchmarks, like college entrance exams, to get a rough idea. Each year, students cram for these tests, sometimes even scoring a perfect 100%. But does that perfect score mean they all possess the same level of intelligence or that they've reached the peak of their mental potential? Of course not. These benchmarks are just rough estimates, not precise indicators of someone's true abilities.
In the world of generative AI, benchmarks such as MMLU (Massive Multitask Language Understanding) have been the go-to for assessing models through multiple-choice questions across various academic fields. While they allow for easy comparisons, they don't really capture the full spectrum of intelligent capabilities.
Take Claude 3.5 Sonnet and GPT-4.5, for example. They might score similarly on MMLU, suggesting they're on par. But anyone who's actually used these models knows their real-world performance can be quite different.
What Does It Mean to Measure 'Intelligence' in AI?
With the recent launch of the ARC-AGI benchmark, designed to test models on general reasoning and creative problem-solving, there's been a fresh wave of discussion about what it means to measure "intelligence" in AI. Not everyone has had a chance to dive into ARC-AGI yet, but the industry is buzzing about this and other new approaches to testing. Every benchmark has its place, and ARC-AGI is a step in the right direction.
Another exciting development is 'Humanity's Last Exam,' a comprehensive benchmark with 3,000 peer-reviewed, multi-step questions spanning different disciplines. It's an ambitious effort to push AI systems to expert-level reasoning. Early results show rapid progress, with OpenAI reportedly hitting a 26.6% score just a month after its release. But like other benchmarks, it focuses mainly on knowledge and reasoning in a vacuum, not on the practical, tool-using skills that are vital for real-world AI applications.
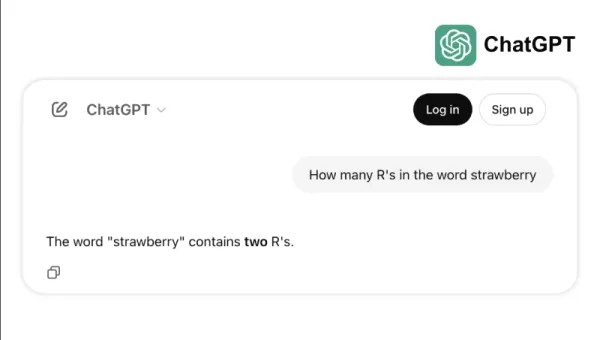
Take, for instance, how some top models struggle with simple tasks like counting the "r"s in "strawberry" or comparing 3.8 to 3.1111. These errors, which even a child or a basic calculator could avoid, highlight the gap between benchmark success and real-world reliability. It's a reminder that intelligence isn't just about acing tests; it's about navigating everyday logic with ease.
The New Standard for Measuring AI Capability
As AI models have evolved, the limitations of traditional benchmarks have become more apparent. For instance, GPT-4, when equipped with tools, only scores about 15% on the more complex, real-world tasks in the GAIA benchmark, despite its high scores on multiple-choice tests.
This discrepancy between benchmark performance and practical capability is increasingly problematic as AI systems transition from research labs to business applications. Traditional benchmarks test how well a model can recall information but often overlook key aspects of intelligence, such as the ability to gather data, run code, analyze information, and create solutions across various domains.
Enter GAIA, a new benchmark that marks a significant shift in AI evaluation. Developed through a collaboration between teams from Meta-FAIR, Meta-GenAI, HuggingFace, and AutoGPT, GAIA includes 466 meticulously crafted questions across three difficulty levels. These questions test a wide range of skills essential for real-world AI applications, including web browsing, multi-modal understanding, code execution, file handling, and complex reasoning.
Level 1 questions typically require about 5 steps and one tool for humans to solve. Level 2 questions need 5 to 10 steps and multiple tools, while Level 3 questions might demand up to 50 steps and any number of tools. This structure reflects the complexity of actual business problems, where solutions often involve multiple actions and tools.
By focusing on flexibility rather than just complexity, an AI model achieved a 75% accuracy rate on GAIA, outperforming industry leaders like Microsoft's Magnetic-1 (38%) and Google's Langfun Agent (49%). This success comes from using a mix of specialized models for audio-visual understanding and reasoning, with Anthropic's Sonnet 3.5 as the main model.
This shift in AI evaluation reflects a broader trend in the industry: We're moving away from standalone SaaS applications towards AI agents that can manage multiple tools and workflows. As businesses increasingly depend on AI to tackle complex, multi-step tasks, benchmarks like GAIA offer a more relevant measure of capability than traditional multiple-choice tests.
The future of AI evaluation isn't about isolated knowledge tests; it's about comprehensive assessments of problem-solving ability. GAIA sets a new benchmark for measuring AI capability—one that aligns better with the real-world challenges and opportunities of AI deployment.
Sri Ambati is the founder and CEO of H2O.ai.
Related article
 AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th
Related Special Topic Recommendations
Business
AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th
Related Special Topic Recommendations
Business
 Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
 10 tools
10 tools
 xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

 Comments (4)
0/500
Comments (4)
0/500
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
Intelligence is everywhere, yet gauging it accurately feels like trying to catch a cloud with your bare hands. We use tests and benchmarks, like college entrance exams, to get a rough idea. Each year, students cram for these tests, sometimes even scoring a perfect 100%. But does that perfect score mean they all possess the same level of intelligence or that they've reached the peak of their mental potential? Of course not. These benchmarks are just rough estimates, not precise indicators of someone's true abilities.
In the world of generative AI, benchmarks such as MMLU (Massive Multitask Language Understanding) have been the go-to for assessing models through multiple-choice questions across various academic fields. While they allow for easy comparisons, they don't really capture the full spectrum of intelligent capabilities.
Take Claude 3.5 Sonnet and GPT-4.5, for example. They might score similarly on MMLU, suggesting they're on par. But anyone who's actually used these models knows their real-world performance can be quite different.
What Does It Mean to Measure 'Intelligence' in AI?
With the recent launch of the ARC-AGI benchmark, designed to test models on general reasoning and creative problem-solving, there's been a fresh wave of discussion about what it means to measure "intelligence" in AI. Not everyone has had a chance to dive into ARC-AGI yet, but the industry is buzzing about this and other new approaches to testing. Every benchmark has its place, and ARC-AGI is a step in the right direction.
Another exciting development is 'Humanity's Last Exam,' a comprehensive benchmark with 3,000 peer-reviewed, multi-step questions spanning different disciplines. It's an ambitious effort to push AI systems to expert-level reasoning. Early results show rapid progress, with OpenAI reportedly hitting a 26.6% score just a month after its release. But like other benchmarks, it focuses mainly on knowledge and reasoning in a vacuum, not on the practical, tool-using skills that are vital for real-world AI applications.
Take, for instance, how some top models struggle with simple tasks like counting the "r"s in "strawberry" or comparing 3.8 to 3.1111. These errors, which even a child or a basic calculator could avoid, highlight the gap between benchmark success and real-world reliability. It's a reminder that intelligence isn't just about acing tests; it's about navigating everyday logic with ease.
The New Standard for Measuring AI Capability
As AI models have evolved, the limitations of traditional benchmarks have become more apparent. For instance, GPT-4, when equipped with tools, only scores about 15% on the more complex, real-world tasks in the GAIA benchmark, despite its high scores on multiple-choice tests.
This discrepancy between benchmark performance and practical capability is increasingly problematic as AI systems transition from research labs to business applications. Traditional benchmarks test how well a model can recall information but often overlook key aspects of intelligence, such as the ability to gather data, run code, analyze information, and create solutions across various domains.
Enter GAIA, a new benchmark that marks a significant shift in AI evaluation. Developed through a collaboration between teams from Meta-FAIR, Meta-GenAI, HuggingFace, and AutoGPT, GAIA includes 466 meticulously crafted questions across three difficulty levels. These questions test a wide range of skills essential for real-world AI applications, including web browsing, multi-modal understanding, code execution, file handling, and complex reasoning.
Level 1 questions typically require about 5 steps and one tool for humans to solve. Level 2 questions need 5 to 10 steps and multiple tools, while Level 3 questions might demand up to 50 steps and any number of tools. This structure reflects the complexity of actual business problems, where solutions often involve multiple actions and tools.
By focusing on flexibility rather than just complexity, an AI model achieved a 75% accuracy rate on GAIA, outperforming industry leaders like Microsoft's Magnetic-1 (38%) and Google's Langfun Agent (49%). This success comes from using a mix of specialized models for audio-visual understanding and reasoning, with Anthropic's Sonnet 3.5 as the main model.
This shift in AI evaluation reflects a broader trend in the industry: We're moving away from standalone SaaS applications towards AI agents that can manage multiple tools and workflows. As businesses increasingly depend on AI to tackle complex, multi-step tasks, benchmarks like GAIA offer a more relevant measure of capability than traditional multiple-choice tests.
The future of AI evaluation isn't about isolated knowledge tests; it's about comprehensive assessments of problem-solving ability. GAIA sets a new benchmark for measuring AI capability—one that aligns better with the real-world challenges and opportunities of AI deployment.
Sri Ambati is the founder and CEO of H2O.ai.










 AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
AI Reveals Hidden Agendas in News Content
ChatGPT-style models are now being trained to uncover the underlying perspective of a news article—even when that viewpoint is concealed beneath quotes, framing, or a veneer of (sometimes insincere) neutrality. By breaking articles into segments like
 Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
Anthropic's Claude 4.1 Outperforms on Coding Benchmarks Ahead of GPT-5 Launch
Anthropic unveiled an enhanced version of its premier AI model on Monday, setting a new benchmark for performance on software engineering tasks. The rollout positions the AI startup to defend its stronghold in the lucrative coding sector, anticipatin
 Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th
Nvidia Unveils Open-Source AI Model Nemotron-Nano-9B-v2 with Toggleable Reasoning
Small language models are making waves. Following the debut of MIT spinoff Liquid AI's smartwatch-sized vision model and Google's smartphone-ready offering, Nvidia is now entering the scene with its own slimmed-down contender: Nemotron-Nano-9B-V2. Th

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













