
















 Lar
LarGaia apresenta um novo benchmark em busca por verdadeira inteligência além do Arc-Agi
A inteligência está em toda parte, mas avaliá-la com precisão é como tentar agarrar uma nuvem com as mãos. Usamos testes e benchmarks, como exames de admissão universitária, para ter uma ideia aproximada. A cada ano, estudantes se preparam intensamente para esses testes, às vezes alcançando uma pontuação perfeita de 100%. Mas essa pontuação perfeita significa que todos possuem o mesmo nível de inteligência ou que atingiram o auge de seu potencial mental? Claro que não. Esses benchmarks são apenas estimativas aproximadas, não indicadores precisos das verdadeiras habilidades de alguém.
No mundo da IA generativa, benchmarks como o MMLU (Massive Multitask Language Understanding) têm sido a referência para avaliar modelos por meio de questões de múltipla escolha em várias áreas acadêmicas. Embora permitam comparações fáceis, eles não capturam realmente o espectro completo das capacidades inteligentes.
Tomemos como exemplo Claude 3.5 Sonnet e GPT-4.5. Eles podem ter pontuações semelhantes no MMLU, sugerindo que estão no mesmo nível. Mas qualquer pessoa que tenha usado esses modelos sabe que seu desempenho no mundo real pode ser bastante diferente.
O que significa medir 'inteligência' em IA?
Com o recente lançamento do benchmark ARC-AGI, projetado para testar modelos em raciocínio geral e resolução criativa de problemas, houve uma nova onda de discussões sobre o que significa medir "inteligência" em IA. Nem todos tiveram a chance de explorar o ARC-AGI ainda, mas a indústria está agitada com esse e outros novos métodos de teste. Cada benchmark tem seu lugar, e o ARC-AGI é um passo na direção certa.
Outro desenvolvimento empolgante é o 'Humanity's Last Exam', um benchmark abrangente com 3.000 questões revisadas por pares, em várias etapas, abrangendo diferentes disciplinas. É um esforço ambicioso para levar os sistemas de IA ao raciocínio em nível de especialista. Resultados iniciais mostram progresso rápido, com a OpenAI supostamente alcançando uma pontuação de 26,6% apenas um mês após seu lançamento. Mas, como outros benchmarks, ele foca principalmente em conhecimento e raciocínio em um vácuo, não nas habilidades práticas de uso de ferramentas, vitais para aplicações de IA no mundo real.
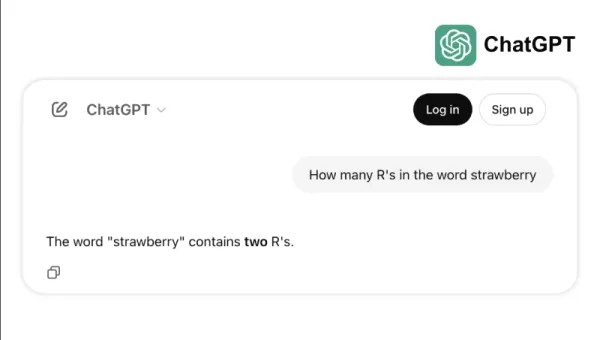
Por exemplo, alguns modelos de ponta têm dificuldade com tarefas simples, como contar os "r"s em "strawberry" ou comparar 3,8 com 3,1111. Esses erros, que até uma criança ou uma calculadora básica poderiam evitar, destacam a lacuna entre o sucesso em benchmarks e a confiabilidade no mundo real. É um lembrete de que inteligência não se trata apenas de passar em testes; é sobre navegar pela lógica cotidiana com facilidade.
O novo padrão para medir a capacidade da IA
À medida que os modelos de IA evoluíram, as limitações dos benchmarks tradicionais tornaram-se mais evidentes. Por exemplo, o GPT-4, quando equipado com ferramentas, pontua apenas cerca de 15% nas tarefas mais complexas do mundo real no benchmark GAIA, apesar de suas altas pontuações em testes de múltipla escolha.
Essa discrepância entre o desempenho em benchmarks e a capacidade prática é cada vez mais problemática à medida que os sistemas de IA passam de laboratórios de pesquisa para aplicações empresariais. Benchmarks tradicionais testam o quão bem um modelo pode recordar informações, mas muitas vezes ignoram aspectos-chave da inteligência, como a capacidade de coletar dados, executar código, analisar informações e criar soluções em vários domínios.
Entra em cena o GAIA, um novo benchmark que marca uma mudança significativa na avaliação de IA. Desenvolvido por meio de uma colaboração entre equipes da Meta-FAIR, Meta-GenAI, HuggingFace e AutoGPT, o GAIA inclui 466 questões cuidadosamente elaboradas em três níveis de dificuldade. Essas questões testam uma ampla gama de habilidades essenciais para aplicações de IA no mundo real, incluindo navegação na web, entendimento multimodal, execução de código, manipulação de arquivos e raciocínio complexo.
As questões de Nível 1 geralmente requerem cerca de 5 etapas e uma ferramenta para serem resolvidas por humanos. As questões de Nível 2 exigem de 5 a 10 etapas e várias ferramentas, enquanto as questões de Nível 3 podem exigir até 50 etapas e qualquer número de ferramentas. Essa estrutura reflete a complexidade dos problemas empresariais reais, onde as soluções muitas vezes envolvem múltiplas ações e ferramentas.
Ao focar na flexibilidade, em vez de apenas na complexidade, um modelo de IA alcançou uma taxa de precisão de 75% no GAIA, superando líderes da indústria como o Magnetic-1 da Microsoft (38%) e o Langfun Agent do Google (49%). Esse sucesso vem do uso de uma combinação de modelos especializados para entendimento audiovisual e raciocínio, com o Sonnet 3.5 da Anthropic como o modelo principal.
Essa mudança na avaliação de IA reflete uma tendência mais ampla na indústria: estamos nos afastando de aplicações SaaS autônomas em direção a agentes de IA que podem gerenciar várias ferramentas e fluxos de trabalho. À medida que as empresas dependem cada vez mais da IA para enfrentar tarefas complexas em várias etapas, benchmarks como o GAIA oferecem uma medida mais relevante de capacidade do que os testes tradicionais de múltipla escolha.
O futuro da avaliação de IA não está em testes de conhecimento isolados; está em avaliações abrangentes da capacidade de resolução de problemas. O GAIA estabelece um novo padrão para medir a capacidade da IA — um que se alinha melhor com os desafios e oportunidades do mundo real na implementação de IA.
Sri Ambati é o fundador e CEO da H2O.ai.
Artigo relacionado
 A IA revela agendas ocultas no conteúdo noticioso
Modelos do tipo ChatGPT estão agora sendo treinados para revelar a perspectiva subjacente de uma notícia — mesmo quando esse ponto de vista está oculto por citações, enquadramento ou uma aparência de
Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog
Recomendações de tópicos especiais relacionados
Negócios
A IA revela agendas ocultas no conteúdo noticioso
Modelos do tipo ChatGPT estão agora sendo treinados para revelar a perspectiva subjacente de uma notícia — mesmo quando esse ponto de vista está oculto por citações, enquadramento ou uma aparência de
Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (4)
Comentários (4)
![SamuelRamirez]()
Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
![ThomasLewis]()
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
![BillyAdams]()
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
![GaryThomas]()
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.
A inteligência está em toda parte, mas avaliá-la com precisão é como tentar agarrar uma nuvem com as mãos. Usamos testes e benchmarks, como exames de admissão universitária, para ter uma ideia aproximada. A cada ano, estudantes se preparam intensamente para esses testes, às vezes alcançando uma pontuação perfeita de 100%. Mas essa pontuação perfeita significa que todos possuem o mesmo nível de inteligência ou que atingiram o auge de seu potencial mental? Claro que não. Esses benchmarks são apenas estimativas aproximadas, não indicadores precisos das verdadeiras habilidades de alguém.
No mundo da IA generativa, benchmarks como o MMLU (Massive Multitask Language Understanding) têm sido a referência para avaliar modelos por meio de questões de múltipla escolha em várias áreas acadêmicas. Embora permitam comparações fáceis, eles não capturam realmente o espectro completo das capacidades inteligentes.
Tomemos como exemplo Claude 3.5 Sonnet e GPT-4.5. Eles podem ter pontuações semelhantes no MMLU, sugerindo que estão no mesmo nível. Mas qualquer pessoa que tenha usado esses modelos sabe que seu desempenho no mundo real pode ser bastante diferente.
O que significa medir 'inteligência' em IA?
Com o recente lançamento do benchmark ARC-AGI, projetado para testar modelos em raciocínio geral e resolução criativa de problemas, houve uma nova onda de discussões sobre o que significa medir "inteligência" em IA. Nem todos tiveram a chance de explorar o ARC-AGI ainda, mas a indústria está agitada com esse e outros novos métodos de teste. Cada benchmark tem seu lugar, e o ARC-AGI é um passo na direção certa.
Outro desenvolvimento empolgante é o 'Humanity's Last Exam', um benchmark abrangente com 3.000 questões revisadas por pares, em várias etapas, abrangendo diferentes disciplinas. É um esforço ambicioso para levar os sistemas de IA ao raciocínio em nível de especialista. Resultados iniciais mostram progresso rápido, com a OpenAI supostamente alcançando uma pontuação de 26,6% apenas um mês após seu lançamento. Mas, como outros benchmarks, ele foca principalmente em conhecimento e raciocínio em um vácuo, não nas habilidades práticas de uso de ferramentas, vitais para aplicações de IA no mundo real.
Por exemplo, alguns modelos de ponta têm dificuldade com tarefas simples, como contar os "r"s em "strawberry" ou comparar 3,8 com 3,1111. Esses erros, que até uma criança ou uma calculadora básica poderiam evitar, destacam a lacuna entre o sucesso em benchmarks e a confiabilidade no mundo real. É um lembrete de que inteligência não se trata apenas de passar em testes; é sobre navegar pela lógica cotidiana com facilidade.
O novo padrão para medir a capacidade da IA
À medida que os modelos de IA evoluíram, as limitações dos benchmarks tradicionais tornaram-se mais evidentes. Por exemplo, o GPT-4, quando equipado com ferramentas, pontua apenas cerca de 15% nas tarefas mais complexas do mundo real no benchmark GAIA, apesar de suas altas pontuações em testes de múltipla escolha.
Essa discrepância entre o desempenho em benchmarks e a capacidade prática é cada vez mais problemática à medida que os sistemas de IA passam de laboratórios de pesquisa para aplicações empresariais. Benchmarks tradicionais testam o quão bem um modelo pode recordar informações, mas muitas vezes ignoram aspectos-chave da inteligência, como a capacidade de coletar dados, executar código, analisar informações e criar soluções em vários domínios.
Entra em cena o GAIA, um novo benchmark que marca uma mudança significativa na avaliação de IA. Desenvolvido por meio de uma colaboração entre equipes da Meta-FAIR, Meta-GenAI, HuggingFace e AutoGPT, o GAIA inclui 466 questões cuidadosamente elaboradas em três níveis de dificuldade. Essas questões testam uma ampla gama de habilidades essenciais para aplicações de IA no mundo real, incluindo navegação na web, entendimento multimodal, execução de código, manipulação de arquivos e raciocínio complexo.
As questões de Nível 1 geralmente requerem cerca de 5 etapas e uma ferramenta para serem resolvidas por humanos. As questões de Nível 2 exigem de 5 a 10 etapas e várias ferramentas, enquanto as questões de Nível 3 podem exigir até 50 etapas e qualquer número de ferramentas. Essa estrutura reflete a complexidade dos problemas empresariais reais, onde as soluções muitas vezes envolvem múltiplas ações e ferramentas.
Ao focar na flexibilidade, em vez de apenas na complexidade, um modelo de IA alcançou uma taxa de precisão de 75% no GAIA, superando líderes da indústria como o Magnetic-1 da Microsoft (38%) e o Langfun Agent do Google (49%). Esse sucesso vem do uso de uma combinação de modelos especializados para entendimento audiovisual e raciocínio, com o Sonnet 3.5 da Anthropic como o modelo principal.
Essa mudança na avaliação de IA reflete uma tendência mais ampla na indústria: estamos nos afastando de aplicações SaaS autônomas em direção a agentes de IA que podem gerenciar várias ferramentas e fluxos de trabalho. À medida que as empresas dependem cada vez mais da IA para enfrentar tarefas complexas em várias etapas, benchmarks como o GAIA oferecem uma medida mais relevante de capacidade do que os testes tradicionais de múltipla escolha.
O futuro da avaliação de IA não está em testes de conhecimento isolados; está em avaliações abrangentes da capacidade de resolução de problemas. O GAIA estabelece um novo padrão para medir a capacidade da IA — um que se alinha melhor com os desafios e oportunidades do mundo real na implementação de IA.
Sri Ambati é o fundador e CEO da H2O.ai.










 A IA revela agendas ocultas no conteúdo noticioso
Modelos do tipo ChatGPT estão agora sendo treinados para revelar a perspectiva subjacente de uma notícia — mesmo quando esse ponto de vista está oculto por citações, enquadramento ou uma aparência de
A IA revela agendas ocultas no conteúdo noticioso
Modelos do tipo ChatGPT estão agora sendo treinados para revelar a perspectiva subjacente de uma notícia — mesmo quando esse ponto de vista está oculto por citações, enquadramento ou uma aparência de
 Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
Claude 4.1 da Anthropic supera benchmarks de codificação antes do lançamento do GPT-5
A Anthropic revelou na segunda-feira uma versão aprimorada de seu principal modelo de IA, estabelecendo um novo padrão de referência para o desempenho em tarefas de engenharia de software. O lançament
 Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog
Nvidia revela modelo de IA de código aberto Nemotron-Nano-9B-v2 com raciocínio alternável
Os modelos de linguagem pequenos estão causando impacto. Após o lançamento do modelo de visão do tamanho de um smartwatch da Liquid AI, uma spin-off do MIT, e da oferta pronta para smartphones do Goog

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Interesting benchmark! But I wonder if focusing too much on benchmarks might lead to AI that's just good at passing tests, not truly understanding the world. Reminds me of students who ace exams but struggle with real-life problems. 🤔
このGAIAベンチマークは確かに面白いですね。AIの知性を測る方法はもっと多様なはず。人間だってテストだけでは測れないんだから、AIにも同様に自分たちの理解できる尺度が適しているのかな?実は市場競争ばかり意識すると、基準が歪んでしまうんじゃないかと心配😅
This GAIA benchmark sounds intriguing! Makes me wonder if we’re finally getting closer to measuring true intelligence or just chasing fancier numbers. 🤔 What’s next, AI acing philosophy exams?
This GAIA benchmark sounds intriguing! 🤔 It’s like trying to measure a rainbow with a ruler—cool concept, but can it really capture true intelligence? I wonder how it compares to ARC-AGI in practical applications.













