
















 집
집Microsoft 연구, AI 모델의 소프트웨어 디버깅 한계 드러내다
OpenAI, Anthropic 및 기타 주요 AI 연구소의 AI 모델은 코딩 작업에 점점 더 많이 활용되고 있다. Google CEO Sundar Pichai는 10월에 AI가 회사 내 새로운 코드의 25%를 생성한다고 언급했으며, Meta CEO Mark Zuckerberg는 소셜 미디어 대기업 내에서 AI 코딩 도구를 광범위하게 구현하려고 한다.
그러나 최고 성능의 모델조차도 숙련된 개발자들이 쉽게 처리하는 소프트웨어 버그를 수정하는 데 어려움을 겪는다.
Microsoft의 R&D 부서에서 수행한 최근 Microsoft Research 연구에 따르면, Anthropic의 Claude 3.7 Sonnet과 OpenAI의 o3-mini와 같은 모델은 SWE-bench Lite 소프트웨어 개발 벤치마크에서 많은 문제를 해결하지 못한다. 이 결과는 OpenAI와 같은 기업의 야심찬 주장에도 불구하고 AI가 코딩과 같은 분야에서 인간의 전문성을 아직 따라가지 못한다는 점을 강조한다.
연구진은 Python 디버거를 포함한 디버깅 도구를 갖춘 “단일 프롬프트 기반 에이전트”의 기반으로 9개의 모델을 테스트했다. 이 에이전트는 SWE-bench Lite에서 선별된 300개의 소프트웨어 디버깅 과제를 해결해야 했다.
결과는 고급 모델을 사용했음에도 불구하고 에이전트가 과제의 절반 이상을 성공적으로 해결한 경우가 드물다는 것을 보여주었다. Claude 3.7 Sonnet이 48.4%의 성공률로 선두를 달렸으며, OpenAI의 o1이 30.2%, o3-mini가 22.1%로 뒤를 이었다.
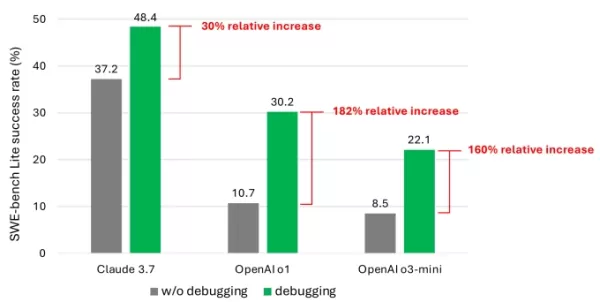
디버깅 도구로 인해 모델이 얻은 성능 향상을 보여주는 연구의 차트. 이미지 제공: Microsoft 실망스러운 결과의 원인은 무엇일까? 일부 모델은 사용 가능한 디버깅 도구를 효과적으로 사용하거나 특정 문제에 적합한 도구를 식별하는 데 어려움을 겪었다. 연구진에 따르면 주요 문제는 충분한 훈련 데이터, 특히 인간의 디버깅 흔적과 같은 “순차적 의사결정 과정”을 포착한 데이터의 부족이었다.
“우리는 이러한 모델을 훈련시키거나 미세 조정하면 디버깅 능력을 개선할 수 있다고 믿는다,”라고 연구진은 썼다. “그러나 이를 위해서는 에이전트가 디버거와 상호작용하여 정보를 수집한 후 수정안을 제안하는 궤적 데이터와 같은 특수 데이터가 필요하다.”
TechCrunch Sessions: AI 참석
OpenAI, Anthropic, Cohere의 연사들이 참여하는 최고의 AI 산업 행사에 자리를 예약하라. 한정된 시간 동안, 전문가 강연, 워크숍, 네트워킹 기회를 포함한 하루 종일 티켓이 단돈 292달러다.
TechCrunch Sessions: AI에서 전시
TC Sessions: AI에서 1,200명 이상의 의사결정자에게 당신의 작업을 선보일 기회를 예약하라. 전시 기회는 5월 9일까지 또는 테이블이 모두 예약될 때까지 가능하다.
이 결과는 놀랍지 않다. 수많은 연구에서 AI가 생성한 코드는 프로그래밍 논리를 이해하는 약점 때문에 보안 결함과 오류를 종종 초래한다고 보여주었다. 잘 알려진 AI 코딩 도구인 Devin의 최근 테스트에서는 20개의 프로그래밍 작업 중 단지 3개만 완료할 수 있었다.
Microsoft의 연구는 AI 모델이 직면한 이 지속적인 도전에 대한 가장 심층적인 검토 중 하나를 제공한다. AI 기반 코딩 도구에 대한 투자자 관심을 억제할 가능성은 낮지만, 개발자와 그들의 리더들이 코딩 작업에 AI를 크게 의존하는 것을 재고하게 만들 수 있다.
특히, 여러 기술 리더들은 AI가 코딩 직업을 없애줄 것이라는 생각에 반대해 왔다. Microsoft 공동 창립자 Bill Gates, Replit CEO Amjad Masad, Okta CEO Todd McKinnon, IBM CEO Arvind Krishna는 모두 프로그래밍이 직업으로서 지속될 것이라는 자신감을 표명했다.
관련 기사
 카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
관련 특별 주제 추천
챗봇
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
관련 특별 주제 추천
챗봇
 최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
 10 도구
10 도구
 xix.ai
암호
자동화된 단위 테스트를 위한 최고의 AI 도구들: 한 번의 클릭으로 Jest, PyTest, JUnit 테스트 케이스를 생성하세요.
xix.ai
암호
자동화된 단위 테스트를 위한 최고의 AI 도구들: 한 번의 클릭으로 Jest, PyTest, JUnit 테스트 케이스를 생성하세요.
2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai
데이터 분석
최고의 AI 데이터 시각화 도구: 원본 파일에서 대화형 BI 대시보드를 자동 생성
XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
10 도구
xix.ai
소셜 미디어
소셜 미디어용 AI 브랜딩 키트: 모든 채널에서 일관된 브랜드 비주얼 유지
2026년 최고의 소셜 미디어 AI 브랜딩 툴을 만나보세요. XIX.AI가 엄선한 이 목록에는 모든 채널에서 완벽하게 일관된 브랜드 비주얼을 유지할 수 있는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 브랜드의 시각적 경쟁력을 강화해 보세요.
10 도구
xix.ai
챗봇
역할극을 위한 최고의 AI 여자친구 앱 및 AI 동반자 도구 (2026년 가이드)
몰입감 넘치는 역할극과 소통을 위한 2026년 최신 최고 평점 AI 동반자 도구를 만나보세요. XIX.AI가 엄선한 이 가이드에서는 매주 업데이트되는 순위, 무료 및 유료 버전 비교, 실제 사용 후기를 통해 게임의 판도를 바꿀 만큼 강력한 앱들을 소개합니다. 지금 바로 나에게 딱 맞는 앱을 찾아 의미 있는 디지털 동반자 관계를 시작해 보세요.
10 도구
xix.ai
글쓰기
최고의 AI 선협·무협 조력자: 장대한 수련 성장 스토리와 무술 연출을 작성하세요
2026년 최고의 AI 어시스턴트를 만나보세요. 장대한 선협(仙侠) 및 무협(武侠) 이야기를 창작하는 데 도움을 줄 수 있는 도구들입니다. XIX.AI가 엄선한 이 목록에는 수련 과정과 무술 연출을 완벽하게 구현할 수 있는 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 창의력을 마음껏 발휘하고 오늘 바로 집필을 시작해 보세요!
10 도구
xix.ai

 의견 (6)
0/500
의견 (6)
0/500
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
OpenAI, Anthropic 및 기타 주요 AI 연구소의 AI 모델은 코딩 작업에 점점 더 많이 활용되고 있다. Google CEO Sundar Pichai는 10월에 AI가 회사 내 새로운 코드의 25%를 생성한다고 언급했으며, Meta CEO Mark Zuckerberg는 소셜 미디어 대기업 내에서 AI 코딩 도구를 광범위하게 구현하려고 한다.
그러나 최고 성능의 모델조차도 숙련된 개발자들이 쉽게 처리하는 소프트웨어 버그를 수정하는 데 어려움을 겪는다.
Microsoft의 R&D 부서에서 수행한 최근 Microsoft Research 연구에 따르면, Anthropic의 Claude 3.7 Sonnet과 OpenAI의 o3-mini와 같은 모델은 SWE-bench Lite 소프트웨어 개발 벤치마크에서 많은 문제를 해결하지 못한다. 이 결과는 OpenAI와 같은 기업의 야심찬 주장에도 불구하고 AI가 코딩과 같은 분야에서 인간의 전문성을 아직 따라가지 못한다는 점을 강조한다.
연구진은 Python 디버거를 포함한 디버깅 도구를 갖춘 “단일 프롬프트 기반 에이전트”의 기반으로 9개의 모델을 테스트했다. 이 에이전트는 SWE-bench Lite에서 선별된 300개의 소프트웨어 디버깅 과제를 해결해야 했다.
결과는 고급 모델을 사용했음에도 불구하고 에이전트가 과제의 절반 이상을 성공적으로 해결한 경우가 드물다는 것을 보여주었다. Claude 3.7 Sonnet이 48.4%의 성공률로 선두를 달렸으며, OpenAI의 o1이 30.2%, o3-mini가 22.1%로 뒤를 이었다.
실망스러운 결과의 원인은 무엇일까? 일부 모델은 사용 가능한 디버깅 도구를 효과적으로 사용하거나 특정 문제에 적합한 도구를 식별하는 데 어려움을 겪었다. 연구진에 따르면 주요 문제는 충분한 훈련 데이터, 특히 인간의 디버깅 흔적과 같은 “순차적 의사결정 과정”을 포착한 데이터의 부족이었다.
“우리는 이러한 모델을 훈련시키거나 미세 조정하면 디버깅 능력을 개선할 수 있다고 믿는다,”라고 연구진은 썼다. “그러나 이를 위해서는 에이전트가 디버거와 상호작용하여 정보를 수집한 후 수정안을 제안하는 궤적 데이터와 같은 특수 데이터가 필요하다.”
TechCrunch Sessions: AI 참석
OpenAI, Anthropic, Cohere의 연사들이 참여하는 최고의 AI 산업 행사에 자리를 예약하라. 한정된 시간 동안, 전문가 강연, 워크숍, 네트워킹 기회를 포함한 하루 종일 티켓이 단돈 292달러다.
TechCrunch Sessions: AI에서 전시
TC Sessions: AI에서 1,200명 이상의 의사결정자에게 당신의 작업을 선보일 기회를 예약하라. 전시 기회는 5월 9일까지 또는 테이블이 모두 예약될 때까지 가능하다.
이 결과는 놀랍지 않다. 수많은 연구에서 AI가 생성한 코드는 프로그래밍 논리를 이해하는 약점 때문에 보안 결함과 오류를 종종 초래한다고 보여주었다. 잘 알려진 AI 코딩 도구인 Devin의 최근 테스트에서는 20개의 프로그래밍 작업 중 단지 3개만 완료할 수 있었다.
Microsoft의 연구는 AI 모델이 직면한 이 지속적인 도전에 대한 가장 심층적인 검토 중 하나를 제공한다. AI 기반 코딩 도구에 대한 투자자 관심을 억제할 가능성은 낮지만, 개발자와 그들의 리더들이 코딩 작업에 AI를 크게 의존하는 것을 재고하게 만들 수 있다.
특히, 여러 기술 리더들은 AI가 코딩 직업을 없애줄 것이라는 생각에 반대해 왔다. Microsoft 공동 창립자 Bill Gates, Replit CEO Amjad Masad, Okta CEO Todd McKinnon, IBM CEO Arvind Krishna는 모두 프로그래밍이 직업으로서 지속될 것이라는 자신감을 표명했다.









 카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
 배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
 유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
10 도구
xix.ai

2026년 최고의 소셜 미디어 AI 브랜딩 툴을 만나보세요. XIX.AI가 엄선한 이 목록에는 모든 채널에서 완벽하게 일관된 브랜드 비주얼을 유지할 수 있는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 브랜드의 시각적 경쟁력을 강화해 보세요.
10 도구
xix.ai

몰입감 넘치는 역할극과 소통을 위한 2026년 최신 최고 평점 AI 동반자 도구를 만나보세요. XIX.AI가 엄선한 이 가이드에서는 매주 업데이트되는 순위, 무료 및 유료 버전 비교, 실제 사용 후기를 통해 게임의 판도를 바꿀 만큼 강력한 앱들을 소개합니다. 지금 바로 나에게 딱 맞는 앱을 찾아 의미 있는 디지털 동반자 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 어시스턴트를 만나보세요. 장대한 선협(仙侠) 및 무협(武侠) 이야기를 창작하는 데 도움을 줄 수 있는 도구들입니다. XIX.AI가 엄선한 이 목록에는 수련 과정과 무술 연출을 완벽하게 구현할 수 있는 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 창의력을 마음껏 발휘하고 오늘 바로 집필을 시작해 보세요!
10 도구
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













