
















 Maison
Maison
Meta dévoile Llama 4 avec des modèles Scout et Maverick à long contexte, le géant du paramètre 2T à venir bientôt!
En janvier 2025, le monde de l'IA a été secoué lorsque DeepSeek, une startup chinoise d'IA relativement inconnue, a lancé un défi avec son modèle de raisonnement linguistique open-source révolutionnaire, DeepSeek R1. Ce modèle a non seulement surpassé des géants comme Meta, mais l'a fait à une fraction du coût — on parle de quelques millions de dollars seulement. C'est le genre de budget que Meta pourrait dépenser pour seulement quelques chefs d'équipe IA ! Cette nouvelle a mis Meta dans une certaine frénésie, d'autant plus que leur dernier modèle Llama, version 3.3, sorti juste le mois précédent, semblait déjà un peu dépassé.
Aujourd'hui, le fondateur et PDG de Meta, Mark Zuckerberg, a pris la parole sur Instagram pour annoncer le lancement de la nouvelle série Llama 4. Cette série comprend le Llama 4 Maverick avec 400 milliards de paramètres et le Llama 4 Scout avec 109 milliards de paramètres, tous deux disponibles pour les développeurs à télécharger et à expérimenter immédiatement sur llama.com et Hugging Face. Il y a aussi un aperçu d'un modèle colossal de 2 trillions de paramètres, Llama 4 Behemoth, encore en entraînement, sans date de sortie prévue.
Capacités multimodales et contextes longs
L'une des caractéristiques remarquables de ces nouveaux modèles est leur nature multimodale. Ils ne se limitent pas au texte ; ils peuvent également gérer la vidéo et les images. Et ils disposent de fenêtres de contexte incroyablement longues — 1 million de jetons pour Maverick et pas moins de 10 millions pour Scout. Pour mettre cela en perspective, cela équivaut à traiter jusqu'à 1 500 et 15 000 pages de texte d'un coup ! Imaginez les possibilités pour des domaines comme la médecine, la science ou la littérature où il faut traiter et générer d'énormes quantités d'informations.
Architecture de mélange d'experts
Les trois modèles Llama 4 utilisent l'architecture de "mélange d'experts (MoE)", une technique qui fait des vagues, popularisée par des entreprises comme OpenAI et Mistral. Cette approche combine plusieurs modèles plus petits et spécialisés en un seul modèle plus grand et plus efficace. Chaque modèle Llama 4 est un mélange de 128 experts différents, ce qui signifie que seul l'expert nécessaire et un partagé gèrent chaque jeton, rendant les modèles plus économiques et plus rapides à exécuter. Meta se vante que Llama 4 Maverick peut être exécuté sur un seul hôte Nvidia H100 DGX, facilitant ainsi le déploiement.
Économique et accessible
Meta mise tout sur l'accessibilité de ces modèles. Scout et Maverick sont disponibles pour l'auto-hébergement, et ils ont même partagé des estimations de coûts alléchantes. Par exemple, le coût d'inférence pour Llama 4 Maverick se situe entre 0,19 $ et 0,49 $ par million de jetons, ce qui est une aubaine par rapport à d'autres modèles propriétaires comme GPT-4o. Et si vous souhaitez utiliser ces modèles via un fournisseur de cloud, Groq a déjà proposé des prix compétitifs.
Raisonnement amélioré et MetaP
Ces modèles sont conçus pour le raisonnement, le codage et la résolution de problèmes. Meta a utilisé des techniques astucieuses pendant l'entraînement pour renforcer ces capacités, comme supprimer les invites faciles et utiliser un apprentissage par renforcement continu avec des invites de plus en plus difficiles. Ils ont également introduit MetaP, une nouvelle technique qui permet de définir des hyperparamètres sur un modèle et de les appliquer à d'autres, économisant ainsi du temps et de l'argent. C'est un changement majeur, surtout pour entraîner des monstres comme Behemoth, qui utilise 32 000 GPU et traite plus de 30 trillions de jetons.
Performance et comparaisons
Alors, comment ces modèles se comparent-ils ? Zuckerberg a été clair sur sa vision de l'IA open-source en tête de file, et Llama 4 est un grand pas dans cette direction. Bien qu'ils ne battent pas de nouveaux records de performance à tous les niveaux, ils sont certainement parmi les meilleurs de leur catégorie. Par exemple, Llama 4 Behemoth surpasse certains poids lourds sur certains benchmarks, bien qu'il soit encore à la traîne derrière DeepSeek R1 et la série o1 d'OpenAI dans d'autres.
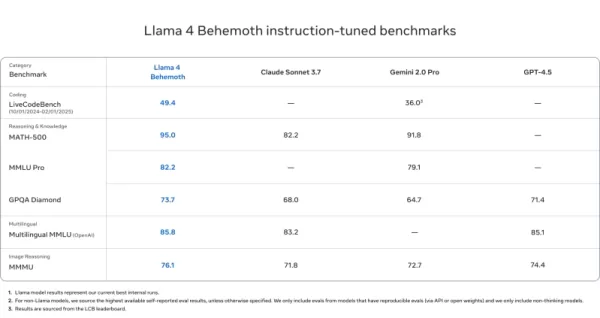
Llama 4 Behemoth
- Surpasse GPT-4.5, Gemini 2.0 Pro et Claude Sonnet 3.7 sur MATH-500 (95,0), GPQA Diamond (73,7) et MMLU Pro (82,2)
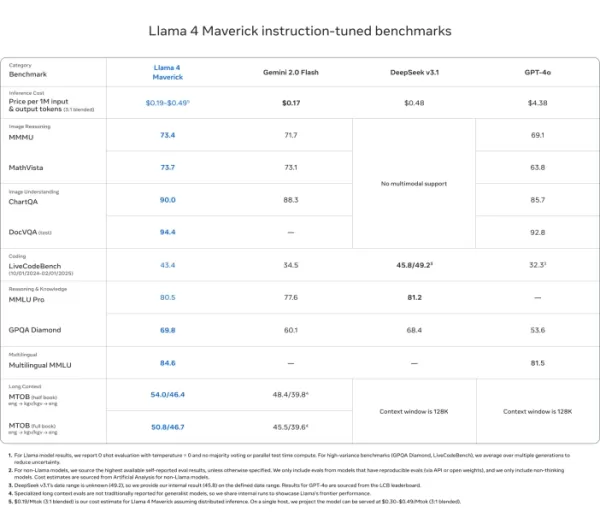
Llama 4 Maverick
- Dépasse GPT-4o et Gemini 2.0 Flash sur la plupart des benchmarks de raisonnement multimodal comme ChartQA, DocVQA, MathVista et MMMU
- Compétitif avec DeepSeek v3.1 tout en utilisant moins de la moitié des paramètres actifs
- Scores de benchmark : ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
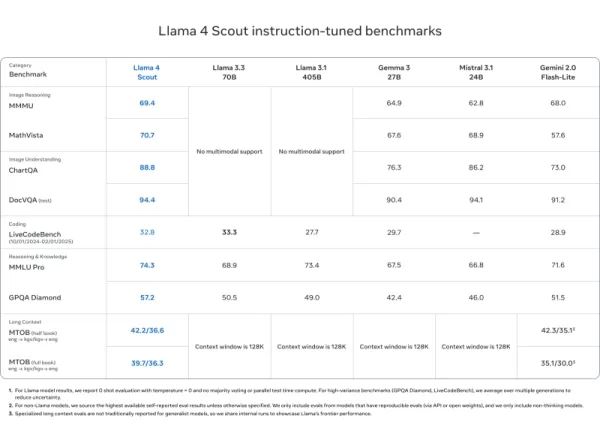
Llama 4 Scout
- Égale ou surpasse des modèles comme Mistral 3.1, Gemini 2.0 Flash-Lite et Gemma 3 sur DocVQA (94,4), MMLU Pro (74,3) et MathVista (70,7)
- Longueur de contexte inégalée de 10 millions de jetons — idéale pour les longs documents et les bases de code
Comparaison avec DeepSeek R1
Dans les grandes ligues, Llama 4 Behemoth tient bon mais ne détrône pas tout à fait DeepSeek R1 ou la série o1 d'OpenAI. Il est légèrement en retard sur MATH-500 et MMLU mais en avance sur GPQA Diamond. Pourtant, il est clair que Llama 4 est un concurrent sérieux dans le domaine du raisonnement.
Benchmark Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95,0 97,3 96,4 GPQA Diamond 73,7 71,5 75,7 MMLU 82,2 90,8 91,8
Sécurité et neutralité politique
Meta n'a pas non plus oublié la sécurité. Ils ont introduit des outils comme Llama Guard, Prompt Guard et CyberSecEval pour maintenir les choses dans les normes. Et ils insistent sur la réduction des biais politiques, visant une approche plus équilibrée, surtout après le soutien noté de Zuckerberg pour la politique républicaine après l'élection de 2024.
L'avenir avec Llama 4
Avec Llama 4, Meta repousse les limites de l'efficacité, de l'ouverture et de la performance en IA. Que vous cherchiez à construire des assistants IA de niveau entreprise ou à plonger dans la recherche en IA, Llama 4 offre des options puissantes et flexibles qui privilégient le raisonnement. Il est clair que Meta s'engage à rendre l'IA plus accessible et impactante pour tous.
Article connexe
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Recommandations de sujets spéciaux liés
Entreprise
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
 10 outils
10 outils
 xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

 commentaires (30)
commentaires (30)
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
En janvier 2025, le monde de l'IA a été secoué lorsque DeepSeek, une startup chinoise d'IA relativement inconnue, a lancé un défi avec son modèle de raisonnement linguistique open-source révolutionnaire, DeepSeek R1. Ce modèle a non seulement surpassé des géants comme Meta, mais l'a fait à une fraction du coût — on parle de quelques millions de dollars seulement. C'est le genre de budget que Meta pourrait dépenser pour seulement quelques chefs d'équipe IA ! Cette nouvelle a mis Meta dans une certaine frénésie, d'autant plus que leur dernier modèle Llama, version 3.3, sorti juste le mois précédent, semblait déjà un peu dépassé.
Aujourd'hui, le fondateur et PDG de Meta, Mark Zuckerberg, a pris la parole sur Instagram pour annoncer le lancement de la nouvelle série Llama 4. Cette série comprend le Llama 4 Maverick avec 400 milliards de paramètres et le Llama 4 Scout avec 109 milliards de paramètres, tous deux disponibles pour les développeurs à télécharger et à expérimenter immédiatement sur llama.com et Hugging Face. Il y a aussi un aperçu d'un modèle colossal de 2 trillions de paramètres, Llama 4 Behemoth, encore en entraînement, sans date de sortie prévue.
Capacités multimodales et contextes longs
L'une des caractéristiques remarquables de ces nouveaux modèles est leur nature multimodale. Ils ne se limitent pas au texte ; ils peuvent également gérer la vidéo et les images. Et ils disposent de fenêtres de contexte incroyablement longues — 1 million de jetons pour Maverick et pas moins de 10 millions pour Scout. Pour mettre cela en perspective, cela équivaut à traiter jusqu'à 1 500 et 15 000 pages de texte d'un coup ! Imaginez les possibilités pour des domaines comme la médecine, la science ou la littérature où il faut traiter et générer d'énormes quantités d'informations.
Architecture de mélange d'experts
Les trois modèles Llama 4 utilisent l'architecture de "mélange d'experts (MoE)", une technique qui fait des vagues, popularisée par des entreprises comme OpenAI et Mistral. Cette approche combine plusieurs modèles plus petits et spécialisés en un seul modèle plus grand et plus efficace. Chaque modèle Llama 4 est un mélange de 128 experts différents, ce qui signifie que seul l'expert nécessaire et un partagé gèrent chaque jeton, rendant les modèles plus économiques et plus rapides à exécuter. Meta se vante que Llama 4 Maverick peut être exécuté sur un seul hôte Nvidia H100 DGX, facilitant ainsi le déploiement.
Économique et accessible
Meta mise tout sur l'accessibilité de ces modèles. Scout et Maverick sont disponibles pour l'auto-hébergement, et ils ont même partagé des estimations de coûts alléchantes. Par exemple, le coût d'inférence pour Llama 4 Maverick se situe entre 0,19 $ et 0,49 $ par million de jetons, ce qui est une aubaine par rapport à d'autres modèles propriétaires comme GPT-4o. Et si vous souhaitez utiliser ces modèles via un fournisseur de cloud, Groq a déjà proposé des prix compétitifs.
Raisonnement amélioré et MetaP
Ces modèles sont conçus pour le raisonnement, le codage et la résolution de problèmes. Meta a utilisé des techniques astucieuses pendant l'entraînement pour renforcer ces capacités, comme supprimer les invites faciles et utiliser un apprentissage par renforcement continu avec des invites de plus en plus difficiles. Ils ont également introduit MetaP, une nouvelle technique qui permet de définir des hyperparamètres sur un modèle et de les appliquer à d'autres, économisant ainsi du temps et de l'argent. C'est un changement majeur, surtout pour entraîner des monstres comme Behemoth, qui utilise 32 000 GPU et traite plus de 30 trillions de jetons.
Performance et comparaisons
Alors, comment ces modèles se comparent-ils ? Zuckerberg a été clair sur sa vision de l'IA open-source en tête de file, et Llama 4 est un grand pas dans cette direction. Bien qu'ils ne battent pas de nouveaux records de performance à tous les niveaux, ils sont certainement parmi les meilleurs de leur catégorie. Par exemple, Llama 4 Behemoth surpasse certains poids lourds sur certains benchmarks, bien qu'il soit encore à la traîne derrière DeepSeek R1 et la série o1 d'OpenAI dans d'autres.
Llama 4 Behemoth
- Surpasse GPT-4.5, Gemini 2.0 Pro et Claude Sonnet 3.7 sur MATH-500 (95,0), GPQA Diamond (73,7) et MMLU Pro (82,2)
Llama 4 Maverick
- Dépasse GPT-4o et Gemini 2.0 Flash sur la plupart des benchmarks de raisonnement multimodal comme ChartQA, DocVQA, MathVista et MMMU
- Compétitif avec DeepSeek v3.1 tout en utilisant moins de la moitié des paramètres actifs
- Scores de benchmark : ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
Llama 4 Scout
- Égale ou surpasse des modèles comme Mistral 3.1, Gemini 2.0 Flash-Lite et Gemma 3 sur DocVQA (94,4), MMLU Pro (74,3) et MathVista (70,7)
- Longueur de contexte inégalée de 10 millions de jetons — idéale pour les longs documents et les bases de code
Comparaison avec DeepSeek R1
Dans les grandes ligues, Llama 4 Behemoth tient bon mais ne détrône pas tout à fait DeepSeek R1 ou la série o1 d'OpenAI. Il est légèrement en retard sur MATH-500 et MMLU mais en avance sur GPQA Diamond. Pourtant, il est clair que Llama 4 est un concurrent sérieux dans le domaine du raisonnement.
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95,0 | 97,3 | 96,4 |
| GPQA Diamond | 73,7 | 71,5 | 75,7 |
| MMLU | 82,2 | 90,8 | 91,8 |
Sécurité et neutralité politique
Meta n'a pas non plus oublié la sécurité. Ils ont introduit des outils comme Llama Guard, Prompt Guard et CyberSecEval pour maintenir les choses dans les normes. Et ils insistent sur la réduction des biais politiques, visant une approche plus équilibrée, surtout après le soutien noté de Zuckerberg pour la politique républicaine après l'élection de 2024.
L'avenir avec Llama 4
Avec Llama 4, Meta repousse les limites de l'efficacité, de l'ouverture et de la performance en IA. Que vous cherchiez à construire des assistants IA de niveau entreprise ou à plonger dans la recherche en IA, Llama 4 offre des options puissantes et flexibles qui privilégient le raisonnement. Il est clair que Meta s'engage à rendre l'IA plus accessible et impactante pour tous.










 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
Meta AI répond désormais aux messages des acheteurs sur Facebook Marketplace
Facebook Marketplace lance de nouvelles fonctionnalités basées sur l'IA de Meta, notamment des réponses automatiques aux demandes des acheteurs, a annoncé jeudi l'entreprise. La plateforme u
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













