




मेटा ने लंबे संदर्भ स्काउट और मावेरिक मॉडल के साथ Llama 4 का अनावरण किया, 2T पैरामीटर Behemoth जल्द ही आ रहा है!
जनवरी 2025 में, AI दुनिया में हलचल मच गई जब एक अपेक्षाकृत अज्ञात चीनी AI स्टार्टअप, DeepSeek, ने अपने अभूतपूर्व ओपन-सोर्स भाषा तर्क मॉडल, DeepSeek R1, के साथ चुनौती पेश की। इस मॉडल ने न केवल Meta जैसे दिग्गजों को पीछे छोड़ा, बल्कि यह बहुत कम लागत में किया—ऐसी अफवाह है कि यह केवल कुछ मिलियन डॉलर में हुआ। यह वह बजट है जो Meta शायद अपने AI टीम के कुछ नेताओं पर ही खर्च करता है! इस खबर ने Meta को थोड़ा उन्माद में डाल दिया, खासकर क्योंकि उनका नवीनतम Llama मॉडल, संस्करण 3.3, जो पिछले महीने ही जारी हुआ था, पहले से ही थोड़ा पुराना लगने लगा था।
आज की तारीख तक, Meta के संस्थापक और CEO, मार्क ज़करबर्ग, ने Instagram पर नई Llama 4 श्रृंखला के लॉन्च की घोषणा की है। इस श्रृंखला में 400 अरब पैरामीटर वाला Llama 4 Maverick और 109 अरब पैरामीटर वाला Llama 4 Scout शामिल हैं, जो दोनों डेवलपर्स के लिए तुरंत डाउनलोड और उपयोग शुरू करने के लिए llama.com और Hugging Face पर उपलब्ध हैं। इसके अलावा, 2 ट्रिलियन पैरामीटर वाले विशाल मॉडल, Llama 4 Behemoth, की एक झलक भी दी गई है, जो अभी प्रशिक्षण में है, और इसकी रिलीज़ डेट अभी सामने नहीं आई है।
मल्टीमॉडल और लंबा संदर्भ क्षमता
इन नए मॉडलों की सबसे खास विशेषता उनकी मल्टीमॉडल प्रकृति है। ये केवल टेक्स्ट तक सीमित नहीं हैं; ये वीडियो और छवियों को भी संभाल सकते हैं। और इनके पास अविश्वसनीय रूप से लंबे संदर्भ विंडो हैं— Maverick के लिए 10 लाख टोकन और Scout के लिए आश्चर्यजनक 1 करोड़ टोकन। इसे परिप्रेक्ष्य में देखें, तो यह एक बार में 1,500 और 15,000 पेज टेक्स्ट को संभालने जैसा है! चिकित्सा, विज्ञान, या साहित्य जैसे क्षेत्रों में संभावनाओं की कल्पना करें, जहां आपको विशाल मात्रा में जानकारी को संसाधित और उत्पन्न करने की आवश्यकता होती है।
मिक्सचर-ऑफ-एक्सपर्ट्स आर्किटेक्चर
तीनों Llama 4 मॉडल "मिक्सचर-ऑफ-एक्सपर्ट्स (MoE)" आर्किटेक्चर का उपयोग करते हैं, एक ऐसी तकनीक जो लहरें बना रही है, जिसे OpenAI और Mistral जैसी कंपनियों ने लोकप्रिय बनाया है। यह दृष्टिकोण कई छोटे, विशेष मॉडलों को एक बड़े, अधिक कुशल मॉडल में जोड़ता है। प्रत्येक Llama 4 मॉडल 128 विभिन्न विशेषज्ञों का मिश्रण है, जिसका मतलब है कि प्रत्येक टोकन को केवल आवश्यक विशेषज्ञ और एक साझा विशेषज्ञ द्वारा संभाला जाता है, जिससे मॉडल अधिक लागत-प्रभावी और तेज़ी से चलते हैं। Meta का दावा है कि Llama 4 Maverick को एकल Nvidia H100 DGX होस्ट पर चलाया जा सकता है, जिससे तैनाती आसान हो जाती है।
लागत-प्रभावी और सुलभ
Meta इन मॉडलों को सुलभ बनाने पर केंद्रित है। Scout और Maverick दोनों स्व-होस्टिंग के लिए उपलब्ध हैं, और उन्होंने कुछ आकर्षक लागत अनुमान भी साझा किए हैं। उदाहरण के लिए, Llama 4 Maverick की अनुमान लागत 0.19 से 0.49 डॉलर प्रति मिलियन टोकन के बीच है, जो GPT-4o जैसे अन्य मालिकाना मॉडलों की तुलना में बहुत सस्ता है। और यदि आप इन मॉडलों को क्लाउड प्रदाता के माध्यम से उपयोग करने में रुचि रखते हैं, तो Groq ने पहले ही प्रतिस्पर्धी मूल्य निर्धारण के साथ कदम बढ़ाया है।
उन्नत तर्क और MetaP
ये मॉडल तर्क, कोडिंग, और समस्या-समाधान को ध्यान में रखकर बनाए गए हैं। Meta ने प्रशिक्षण के दौरान कुछ चतुर तकनीकों का उपयोग किया है, जैसे आसान संकेतों को हटाना और लगातार कठिन संकेतों के साथ सतत सुदृढीकरण शिक्षण का उपयोग करना। उन्होंने MetaP नामक एक नई तकनीक भी पेश की है, जो एक मॉडल पर हाइपरपैरामीटर सेट करने और उन्हें अन्य मॉडलों पर लागू करने की अनुमति देती है, जिससे समय और धन की बचत होती है। यह विशेष रूप से Behemoth जैसे विशाल मॉडलों के प्रशिक्षण के लिए गेम-चेंजर है, जो 32K GPU का उपयोग करता है और 30 ट्रिलियन से अधिक टोकन को संसाधित करता है।
प्रदर्शन और तुलना
तो, ये मॉडल कैसे प्रदर्शन करते हैं? ज़करबर्ग ने ओपन-सोर्स AI के नेतृत्व करने के अपने दृष्टिकोण को स्पष्ट किया है, और Llama 4 इस दिशा में एक बड़ा कदम है। हालांकि वे सभी क्षेत्रों में नए प्रदर्शन रिकॉर्ड स्थापित नहीं कर सकते, लेकिन वे निश्चित रूप से अपनी श्रेणी में शीर्ष पर हैं। उदाहरण के लिए, Llama 4 Behemoth कुछ बेंचमार्क पर कुछ बड़े खिलाड़ियों को पीछे छोड़ता है, हालांकि यह DeepSeek R1 और OpenAI की o1 श्रृंखला के साथ कुछ अन्य में अभी भी पीछे है।
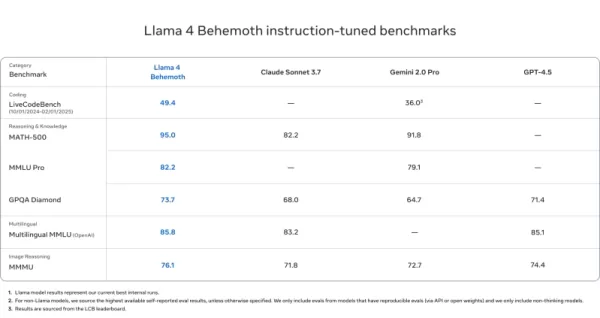
Llama 4 Behemoth
- MATH-500 (95.0), GPQA Diamond (73.7), और MMLU Pro (82.2) पर GPT-4.5, Gemini 2.0 Pro, और Claude Sonnet 3.7 को पीछे छोड़ता है
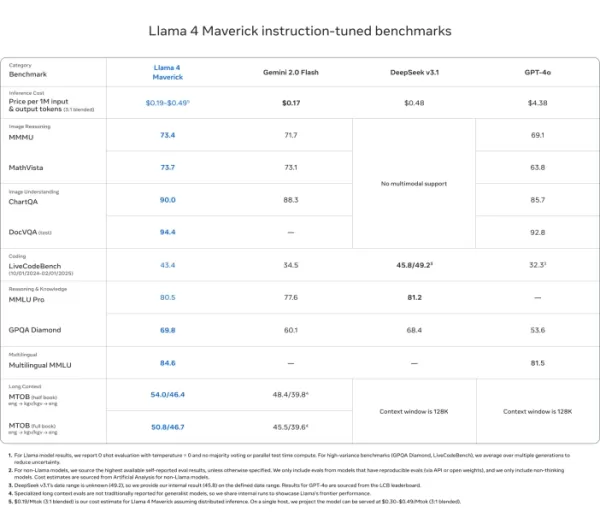
Llama 4 Maverick
- ChartQA, DocVQA, MathVista, और MMMU जैसे अधिकांश मल्टीमॉडल तर्क बेंचमार्क पर GPT-4o और Gemini 2.0 Flash को हराता है
- DeepSeek v3.1 के साथ प्रतिस्पर्धी, जबकि आधे से कम सक्रिय पैरामीटर का उपयोग करता है
- बेंचमार्क स्कोर: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
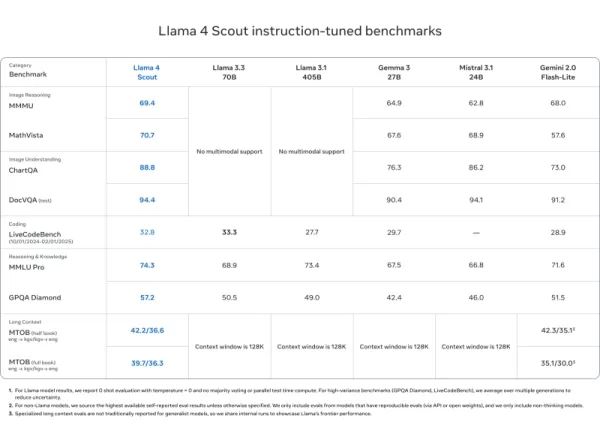
Llama 4 Scout
- DocVQA (94.4), MMLU Pro (74.3), और MathVista (70.7) पर Mistral 3.1, Gemini 2.0 Flash-Lite, और Gemma 3 जैसे मॉडलों से मेल खाता है या उनसे बेहतर प्रदर्शन करता है
- अनुपम 1 करोड़ टोकन संदर्भ लंबाई—लंबे दस्तावेजों और कोडबेस के लिए आदर्श
DeepSeek R1 के साथ तुलना
जब बात बड़े खिलाड़ियों की आती है, Llama 4 Behemoth अपनी स्थिति बनाए रखता है लेकिन DeepSeek R1 या OpenAI की o1 श्रृंखला को पूरी तरह से पछाड़ नहीं पाता। यह MATH-500 और MMLU पर थोड़ा पीछे है लेकिन GPQA Diamond पर आगे है। फिर भी, यह स्पष्ट है कि Llama 4 तर्क क्षेत्र में एक मजबूत दावेदार है।
बेंचमार्क Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
सुरक्षा और राजनीतिक तटस्थता
Meta ने सुरक्षा को भी नहीं भुलाया है। उन्होंने Llama Guard, Prompt Guard, और CyberSecEval जैसे उपकरण पेश किए हैं ताकि सब कुछ सही रहे। और वे राजनीतिक पक्षपात को कम करने की बात कर रहे हैं, विशेष रूप से 2024 चुनाव के बाद ज़करबर्ग के रिपब्लिकन राजनीति के समर्थन के बाद, एक अधिक संतुलित दृष्टिकोण का लक्ष्य रखते हुए।
Llama 4 के साथ भविष्य
Llama 4 के साथ, Meta AI में दक्षता, खुलेपन, और प्रदर्शन की सीमाओं को आगे बढ़ा रहा है। चाहे आप उद्यम-स्तर के AI सहायकों का निर्माण करना चाहते हों या AI अनुसंधान में गहराई से उतरना चाहते हों, Llama 4 शक्तिशाली, लचीले विकल्प प्रदान करता है जो तर्क को प्राथमिकता देते हैं। यह स्पष्ट है कि Meta AI को सभी के लिए अधिक सुलभ और प्रभावशाली बनाने के लिए प्रतिबद्ध है।
संबंधित लेख
 Google ने उद्यम बाजार में OpenAI के साथ प्रतिस्पर्धा करने के लिए उत्पादन-तैयार Gemini 2.5 AI मॉडल्स का अनावरण किया
Google ने सोमवार को अपनी AI रणनीति को और मजबूत किया, उद्यम उपयोग के लिए अपने उन्नत Gemini 2.5 मॉडल्स को लॉन्च किया और कीमत व प्रदर्शन पर प्रतिस्पर्धा करने के लिए एक लागत-कुशल संस्करण पेश किया।Alphabet
मेटा AI प्रतिभा के लिए उच्च वेतन प्रदान करता है, 100 मिलियन डॉलर के साइनिंग बोनस से इनकार
मेटा अपने नए सुपरइंटेलिजेंस लैब में AI शोधकर्ताओं को आकर्षित करने के लिए लाखों डॉलर के मुआवजे पैकेज प्रदान कर रहा है। हालांकि, एक भर्ती किए गए शोधकर्ता और लीक हुई आंतरिक बैठक की टिप्पणियों के अनुसार,
मेटा ने उन्नत लामा उपकरणों के साथ AI सुरक्षा को बढ़ाया
मेटा ने AI विकास को मजबूत करने और उभरते खतरों से बचाव के लिए नए लामा सुरक्षा उपकरण जारी किए हैं।ये उन्नत लामा AI मॉडल सुरक्षा उपकरण मेटा के नए संसाधनों के साथ जोड़े गए हैं, ताकि साइबरसुरक्षा टीमों को
सूचना (25)
0/200
Google ने उद्यम बाजार में OpenAI के साथ प्रतिस्पर्धा करने के लिए उत्पादन-तैयार Gemini 2.5 AI मॉडल्स का अनावरण किया
Google ने सोमवार को अपनी AI रणनीति को और मजबूत किया, उद्यम उपयोग के लिए अपने उन्नत Gemini 2.5 मॉडल्स को लॉन्च किया और कीमत व प्रदर्शन पर प्रतिस्पर्धा करने के लिए एक लागत-कुशल संस्करण पेश किया।Alphabet
मेटा AI प्रतिभा के लिए उच्च वेतन प्रदान करता है, 100 मिलियन डॉलर के साइनिंग बोनस से इनकार
मेटा अपने नए सुपरइंटेलिजेंस लैब में AI शोधकर्ताओं को आकर्षित करने के लिए लाखों डॉलर के मुआवजे पैकेज प्रदान कर रहा है। हालांकि, एक भर्ती किए गए शोधकर्ता और लीक हुई आंतरिक बैठक की टिप्पणियों के अनुसार,
मेटा ने उन्नत लामा उपकरणों के साथ AI सुरक्षा को बढ़ाया
मेटा ने AI विकास को मजबूत करने और उभरते खतरों से बचाव के लिए नए लामा सुरक्षा उपकरण जारी किए हैं।ये उन्नत लामा AI मॉडल सुरक्षा उपकरण मेटा के नए संसाधनों के साथ जोड़े गए हैं, ताकि साइबरसुरक्षा टीमों को
सूचना (25)
0/200
![RogerSanchez]() RogerSanchez
RogerSanchez
 25 अप्रैल 2025 1:23:44 पूर्वाह्न IST
25 अप्रैल 2025 1:23:44 पूर्वाह्न IST
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀


 0
0
![WillieHernández]() WillieHernández
24 अप्रैल 2025 5:51:23 पूर्वाह्न IST
WillieHernández
24 अप्रैल 2025 5:51:23 पूर्वाह्न IST
Llama 4はすごい!長いコンテキストのスカウトやマーベリックモデルは驚異的。2Tパラメータのビーストが出るのを待ちきれない。ただ、設定が少し大変かな。でも、これでAIの未来は明るいね!🚀
0
![GregoryWilson]() GregoryWilson
22 अप्रैल 2025 10:53:39 अपराह्न IST
GregoryWilson
22 अप्रैल 2025 10:53:39 अपराह्न IST
MetaのLlama 4は最高ですね!長いコンテキストをスムーズに処理できるのが本当に便利。マーベリックモデルも面白いけど、2Tパラメータのモデルが来るのが楽しみです!🤩✨
0
![BrianThomas]() BrianThomas
22 अप्रैल 2025 11:57:50 पूर्वाह्न IST
BrianThomas
22 अप्रैल 2025 11:57:50 पूर्वाह्न IST
O Llama 4 da Meta é incrível! A função de contexto longo é uma mão na roda para minhas pesquisas. Os modelos Maverick também são legais, mas estou ansioso pelo modelo de 2T parâmetros. Mal posso esperar para ver o que ele pode fazer! 🤯🚀
0
![JohnGarcia]() JohnGarcia
22 अप्रैल 2025 8:41:00 पूर्वाह्न IST
JohnGarcia
22 अप्रैल 2025 8:41:00 पूर्वाह्न IST
Acabo de enterarme de Llama 4 de Meta y ¡es una locura! ¡2T parámetros! Espero que no sea solo hype, pero si cumple con las expectativas, va a ser increíble. ¿Alguien ya lo ha probado? ¡Quiero saber más! 😎
0
![NicholasLewis]() NicholasLewis
21 अप्रैल 2025 7:01:17 अपराह्न IST
NicholasLewis
21 अप्रैल 2025 7:01:17 अपराह्न IST
Acabei de ouvir sobre o Llama 4 da Meta e parece insano! 2T parâmetros? Isso é um monstro! Mal posso esperar para ver como se compara ao DeepSeek R1. Espero que não seja só hype, mas se corresponder ao burburinho, vai ser 🔥! Alguém já testou?
0
जनवरी 2025 में, AI दुनिया में हलचल मच गई जब एक अपेक्षाकृत अज्ञात चीनी AI स्टार्टअप, DeepSeek, ने अपने अभूतपूर्व ओपन-सोर्स भाषा तर्क मॉडल, DeepSeek R1, के साथ चुनौती पेश की। इस मॉडल ने न केवल Meta जैसे दिग्गजों को पीछे छोड़ा, बल्कि यह बहुत कम लागत में किया—ऐसी अफवाह है कि यह केवल कुछ मिलियन डॉलर में हुआ। यह वह बजट है जो Meta शायद अपने AI टीम के कुछ नेताओं पर ही खर्च करता है! इस खबर ने Meta को थोड़ा उन्माद में डाल दिया, खासकर क्योंकि उनका नवीनतम Llama मॉडल, संस्करण 3.3, जो पिछले महीने ही जारी हुआ था, पहले से ही थोड़ा पुराना लगने लगा था।
आज की तारीख तक, Meta के संस्थापक और CEO, मार्क ज़करबर्ग, ने Instagram पर नई Llama 4 श्रृंखला के लॉन्च की घोषणा की है। इस श्रृंखला में 400 अरब पैरामीटर वाला Llama 4 Maverick और 109 अरब पैरामीटर वाला Llama 4 Scout शामिल हैं, जो दोनों डेवलपर्स के लिए तुरंत डाउनलोड और उपयोग शुरू करने के लिए llama.com और Hugging Face पर उपलब्ध हैं। इसके अलावा, 2 ट्रिलियन पैरामीटर वाले विशाल मॉडल, Llama 4 Behemoth, की एक झलक भी दी गई है, जो अभी प्रशिक्षण में है, और इसकी रिलीज़ डेट अभी सामने नहीं आई है।
मल्टीमॉडल और लंबा संदर्भ क्षमता
इन नए मॉडलों की सबसे खास विशेषता उनकी मल्टीमॉडल प्रकृति है। ये केवल टेक्स्ट तक सीमित नहीं हैं; ये वीडियो और छवियों को भी संभाल सकते हैं। और इनके पास अविश्वसनीय रूप से लंबे संदर्भ विंडो हैं— Maverick के लिए 10 लाख टोकन और Scout के लिए आश्चर्यजनक 1 करोड़ टोकन। इसे परिप्रेक्ष्य में देखें, तो यह एक बार में 1,500 और 15,000 पेज टेक्स्ट को संभालने जैसा है! चिकित्सा, विज्ञान, या साहित्य जैसे क्षेत्रों में संभावनाओं की कल्पना करें, जहां आपको विशाल मात्रा में जानकारी को संसाधित और उत्पन्न करने की आवश्यकता होती है।
मिक्सचर-ऑफ-एक्सपर्ट्स आर्किटेक्चर
तीनों Llama 4 मॉडल "मिक्सचर-ऑफ-एक्सपर्ट्स (MoE)" आर्किटेक्चर का उपयोग करते हैं, एक ऐसी तकनीक जो लहरें बना रही है, जिसे OpenAI और Mistral जैसी कंपनियों ने लोकप्रिय बनाया है। यह दृष्टिकोण कई छोटे, विशेष मॉडलों को एक बड़े, अधिक कुशल मॉडल में जोड़ता है। प्रत्येक Llama 4 मॉडल 128 विभिन्न विशेषज्ञों का मिश्रण है, जिसका मतलब है कि प्रत्येक टोकन को केवल आवश्यक विशेषज्ञ और एक साझा विशेषज्ञ द्वारा संभाला जाता है, जिससे मॉडल अधिक लागत-प्रभावी और तेज़ी से चलते हैं। Meta का दावा है कि Llama 4 Maverick को एकल Nvidia H100 DGX होस्ट पर चलाया जा सकता है, जिससे तैनाती आसान हो जाती है।
लागत-प्रभावी और सुलभ
Meta इन मॉडलों को सुलभ बनाने पर केंद्रित है। Scout और Maverick दोनों स्व-होस्टिंग के लिए उपलब्ध हैं, और उन्होंने कुछ आकर्षक लागत अनुमान भी साझा किए हैं। उदाहरण के लिए, Llama 4 Maverick की अनुमान लागत 0.19 से 0.49 डॉलर प्रति मिलियन टोकन के बीच है, जो GPT-4o जैसे अन्य मालिकाना मॉडलों की तुलना में बहुत सस्ता है। और यदि आप इन मॉडलों को क्लाउड प्रदाता के माध्यम से उपयोग करने में रुचि रखते हैं, तो Groq ने पहले ही प्रतिस्पर्धी मूल्य निर्धारण के साथ कदम बढ़ाया है।
उन्नत तर्क और MetaP
ये मॉडल तर्क, कोडिंग, और समस्या-समाधान को ध्यान में रखकर बनाए गए हैं। Meta ने प्रशिक्षण के दौरान कुछ चतुर तकनीकों का उपयोग किया है, जैसे आसान संकेतों को हटाना और लगातार कठिन संकेतों के साथ सतत सुदृढीकरण शिक्षण का उपयोग करना। उन्होंने MetaP नामक एक नई तकनीक भी पेश की है, जो एक मॉडल पर हाइपरपैरामीटर सेट करने और उन्हें अन्य मॉडलों पर लागू करने की अनुमति देती है, जिससे समय और धन की बचत होती है। यह विशेष रूप से Behemoth जैसे विशाल मॉडलों के प्रशिक्षण के लिए गेम-चेंजर है, जो 32K GPU का उपयोग करता है और 30 ट्रिलियन से अधिक टोकन को संसाधित करता है।
प्रदर्शन और तुलना
तो, ये मॉडल कैसे प्रदर्शन करते हैं? ज़करबर्ग ने ओपन-सोर्स AI के नेतृत्व करने के अपने दृष्टिकोण को स्पष्ट किया है, और Llama 4 इस दिशा में एक बड़ा कदम है। हालांकि वे सभी क्षेत्रों में नए प्रदर्शन रिकॉर्ड स्थापित नहीं कर सकते, लेकिन वे निश्चित रूप से अपनी श्रेणी में शीर्ष पर हैं। उदाहरण के लिए, Llama 4 Behemoth कुछ बेंचमार्क पर कुछ बड़े खिलाड़ियों को पीछे छोड़ता है, हालांकि यह DeepSeek R1 और OpenAI की o1 श्रृंखला के साथ कुछ अन्य में अभी भी पीछे है।
Llama 4 Behemoth
- MATH-500 (95.0), GPQA Diamond (73.7), और MMLU Pro (82.2) पर GPT-4.5, Gemini 2.0 Pro, और Claude Sonnet 3.7 को पीछे छोड़ता है
Llama 4 Maverick
- ChartQA, DocVQA, MathVista, और MMMU जैसे अधिकांश मल्टीमॉडल तर्क बेंचमार्क पर GPT-4o और Gemini 2.0 Flash को हराता है
- DeepSeek v3.1 के साथ प्रतिस्पर्धी, जबकि आधे से कम सक्रिय पैरामीटर का उपयोग करता है
- बेंचमार्क स्कोर: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
Llama 4 Scout
- DocVQA (94.4), MMLU Pro (74.3), और MathVista (70.7) पर Mistral 3.1, Gemini 2.0 Flash-Lite, और Gemma 3 जैसे मॉडलों से मेल खाता है या उनसे बेहतर प्रदर्शन करता है
- अनुपम 1 करोड़ टोकन संदर्भ लंबाई—लंबे दस्तावेजों और कोडबेस के लिए आदर्श
DeepSeek R1 के साथ तुलना
जब बात बड़े खिलाड़ियों की आती है, Llama 4 Behemoth अपनी स्थिति बनाए रखता है लेकिन DeepSeek R1 या OpenAI की o1 श्रृंखला को पूरी तरह से पछाड़ नहीं पाता। यह MATH-500 और MMLU पर थोड़ा पीछे है लेकिन GPQA Diamond पर आगे है। फिर भी, यह स्पष्ट है कि Llama 4 तर्क क्षेत्र में एक मजबूत दावेदार है।
| बेंचमार्क | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
सुरक्षा और राजनीतिक तटस्थता
Meta ने सुरक्षा को भी नहीं भुलाया है। उन्होंने Llama Guard, Prompt Guard, और CyberSecEval जैसे उपकरण पेश किए हैं ताकि सब कुछ सही रहे। और वे राजनीतिक पक्षपात को कम करने की बात कर रहे हैं, विशेष रूप से 2024 चुनाव के बाद ज़करबर्ग के रिपब्लिकन राजनीति के समर्थन के बाद, एक अधिक संतुलित दृष्टिकोण का लक्ष्य रखते हुए।
Llama 4 के साथ भविष्य
Llama 4 के साथ, Meta AI में दक्षता, खुलेपन, और प्रदर्शन की सीमाओं को आगे बढ़ा रहा है। चाहे आप उद्यम-स्तर के AI सहायकों का निर्माण करना चाहते हों या AI अनुसंधान में गहराई से उतरना चाहते हों, Llama 4 शक्तिशाली, लचीले विकल्प प्रदान करता है जो तर्क को प्राथमिकता देते हैं। यह स्पष्ट है कि Meta AI को सभी के लिए अधिक सुलभ और प्रभावशाली बनाने के लिए प्रतिबद्ध है।










 Google ने उद्यम बाजार में OpenAI के साथ प्रतिस्पर्धा करने के लिए उत्पादन-तैयार Gemini 2.5 AI मॉडल्स का अनावरण किया
Google ने सोमवार को अपनी AI रणनीति को और मजबूत किया, उद्यम उपयोग के लिए अपने उन्नत Gemini 2.5 मॉडल्स को लॉन्च किया और कीमत व प्रदर्शन पर प्रतिस्पर्धा करने के लिए एक लागत-कुशल संस्करण पेश किया।Alphabet
Google ने उद्यम बाजार में OpenAI के साथ प्रतिस्पर्धा करने के लिए उत्पादन-तैयार Gemini 2.5 AI मॉडल्स का अनावरण किया
Google ने सोमवार को अपनी AI रणनीति को और मजबूत किया, उद्यम उपयोग के लिए अपने उन्नत Gemini 2.5 मॉडल्स को लॉन्च किया और कीमत व प्रदर्शन पर प्रतिस्पर्धा करने के लिए एक लागत-कुशल संस्करण पेश किया।Alphabet
 मेटा AI प्रतिभा के लिए उच्च वेतन प्रदान करता है, 100 मिलियन डॉलर के साइनिंग बोनस से इनकार
मेटा अपने नए सुपरइंटेलिजेंस लैब में AI शोधकर्ताओं को आकर्षित करने के लिए लाखों डॉलर के मुआवजे पैकेज प्रदान कर रहा है। हालांकि, एक भर्ती किए गए शोधकर्ता और लीक हुई आंतरिक बैठक की टिप्पणियों के अनुसार,
मेटा ने उन्नत लामा उपकरणों के साथ AI सुरक्षा को बढ़ाया
मेटा ने AI विकास को मजबूत करने और उभरते खतरों से बचाव के लिए नए लामा सुरक्षा उपकरण जारी किए हैं।ये उन्नत लामा AI मॉडल सुरक्षा उपकरण मेटा के नए संसाधनों के साथ जोड़े गए हैं, ताकि साइबरसुरक्षा टीमों को
25 अप्रैल 2025 1:23:44 पूर्वाह्न IST
मेटा AI प्रतिभा के लिए उच्च वेतन प्रदान करता है, 100 मिलियन डॉलर के साइनिंग बोनस से इनकार
मेटा अपने नए सुपरइंटेलिजेंस लैब में AI शोधकर्ताओं को आकर्षित करने के लिए लाखों डॉलर के मुआवजे पैकेज प्रदान कर रहा है। हालांकि, एक भर्ती किए गए शोधकर्ता और लीक हुई आंतरिक बैठक की टिप्पणियों के अनुसार,
मेटा ने उन्नत लामा उपकरणों के साथ AI सुरक्षा को बढ़ाया
मेटा ने AI विकास को मजबूत करने और उभरते खतरों से बचाव के लिए नए लामा सुरक्षा उपकरण जारी किए हैं।ये उन्नत लामा AI मॉडल सुरक्षा उपकरण मेटा के नए संसाधनों के साथ जोड़े गए हैं, ताकि साइबरसुरक्षा टीमों को
25 अप्रैल 2025 1:23:44 पूर्वाह्न IST
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
0
24 अप्रैल 2025 5:51:23 पूर्वाह्न IST
Llama 4はすごい!長いコンテキストのスカウトやマーベリックモデルは驚異的。2Tパラメータのビーストが出るのを待ちきれない。ただ、設定が少し大変かな。でも、これでAIの未来は明るいね!🚀
0
22 अप्रैल 2025 10:53:39 अपराह्न IST
MetaのLlama 4は最高ですね!長いコンテキストをスムーズに処理できるのが本当に便利。マーベリックモデルも面白いけど、2Tパラメータのモデルが来るのが楽しみです!🤩✨
0
22 अप्रैल 2025 11:57:50 पूर्वाह्न IST
O Llama 4 da Meta é incrível! A função de contexto longo é uma mão na roda para minhas pesquisas. Os modelos Maverick também são legais, mas estou ansioso pelo modelo de 2T parâmetros. Mal posso esperar para ver o que ele pode fazer! 🤯🚀
0
22 अप्रैल 2025 8:41:00 पूर्वाह्न IST
Acabo de enterarme de Llama 4 de Meta y ¡es una locura! ¡2T parámetros! Espero que no sea solo hype, pero si cumple con las expectativas, va a ser increíble. ¿Alguien ya lo ha probado? ¡Quiero saber más! 😎
0
21 अप्रैल 2025 7:01:17 अपराह्न IST
Acabei de ouvir sobre o Llama 4 da Meta e parece insano! 2T parâmetros? Isso é um monstro! Mal posso esperar para ver como se compara ao DeepSeek R1. Espero que não seja só hype, mas se corresponder ao burburinho, vai ser 🔥! Alguém já testou?
0













