
















 家
家メタは、長いコンテキストスカウトとマーベリックモデルでラマ4を発表します。
2025年1月、AI業界は比較的知られていない中国のAIスタートアップ、DeepSeekが革新的なオープンソースの言語推論モデル、DeepSeek R1を発表したことで震撼しました。このモデルはMetaを凌駕するだけでなく、わずか数百万ドルという低コストでそれを実現しました—これはMetaがAIチームのリーダー数人に費やす予算に相当します!このニュースは、Metaが前月にリリースした最新のLlamaモデル、バージョン3.3がすでにやや時代遅れに見えていたこともあり、Metaを少々慌てさせました。
現在に早送りすると、Metaの創設者兼CEOであるマーク・ザッカーバーグはInstagramで新しいLlama 4シリーズの発売を発表しました。このシリーズには、4000億パラメータのLlama 4 Maverickと1090億パラメータのLlama 4 Scoutが含まれており、どちらも開発者がllama.comやHugging Faceで即座にダウンロードして試すことができます。また、2兆パラメータの巨大なモデル、Llama 4 Behemothのプレビューも公開されていますが、これはまだトレーニング中で、リリース日は未定です。
マルチモーダルおよび長コンテキスト機能
これらの新モデルの際立つ特徴の一つは、マルチモーダルな性質です。テキストだけでなく、ビデオや画像も処理できます。さらに、非常に長いコンテキストウィンドウを備えています—Maverickは100万トークン、Scoutに至っては驚異の1000万トークンです。例えるなら、一度に1500ページや1万5000ページのテキストを処理できるということです!医療、科学、文学など、大量の情報を処理・生成する必要がある分野での可能性を想像してみてください。
エキスパート混合アーキテクチャ
Llama 4の3つのモデルはすべて「エキスパート混合(MoE)」アーキテクチャを採用しており、これはOpenAIやMistralなどの企業によって注目を集めている技術です。このアプローチは、複数の小さな専門モデルを1つの大きな効率的なモデルに統合します。各Llama 4モデルは128の異なるエキスパートで構成されており、必要なエキスパートと共有エキスパートのみが各トークンを処理するため、モデルはよりコスト効率が高く、実行速度も速くなります。Metaは、Llama 4 Maverickが単一のNvidia H100 DGXホストで実行可能で、デプロイが容易だと自慢しています。
コスト効率とアクセシビリティ
Metaはこれらのモデルをアクセスしやすくすることに注力しています。ScoutとMaverickはどちらもセルフホスティングが可能で、魅力的なコスト見積もりも公開されています。例えば、Llama 4 Maverickの推論コストは100万トークンあたり0.19ドルから0.49ドルで、GPT-4oなどの他のプロプライエタリモデルと比べると非常に安価です。クラウドプロバイダ経由でこれらのモデルを使用したい場合、Groqはすでに競争力のある価格を提供しています。
強化された推論とMetaP
これらのモデルは推論、コーディング、問題解決を念頭に構築されています。Metaはトレーニング中に簡単なプロンプトを削除し、徐々に難しいプロンプトを用いた継続的な強化学習を使用するなど、巧妙な技術を活用してこれらの能力を強化しました。また、1つのモデルでハイパーパラメータを設定し、他のモデルに適用できる新しい技術、MetaPを導入しました。これは特に、32KのGPUを使用し、30兆トークン以上を処理するBehemothのような巨大モデルのトレーニングにおいて、時間とコストを節約する画期的な技術です。
パフォーマンスと比較
では、これらのモデルはどのように評価されるのでしょうか?ザッカーバーグはオープンソースAIが先導するというビジョンを明確に述べており、Llama 4はその方向への大きな一歩です。すべてのベンチマークで新記録を樹立するわけではありませんが、確かにトップクラスに位置しています。例えば、Llama 4 Behemothは特定のベンチマークで強力な競合を上回っていますが、DeepSeek R1やOpenAIのo1シリーズにはまだ追いついていない部分もあります。
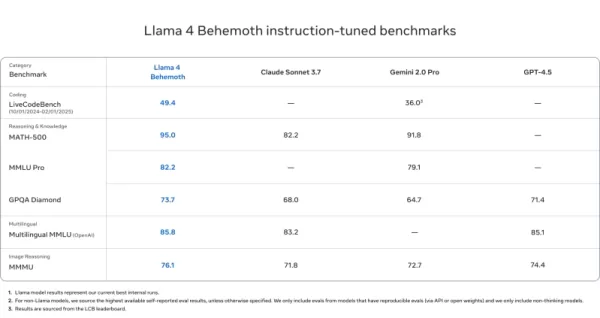
Llama 4 Behemoth
- MATH-500(95.0)、GPQA Diamond(73.7)、MMLU Pro(82.2)でGPT-4.5、Gemini 2.0 Pro、Claude Sonnet 3.7を上回る
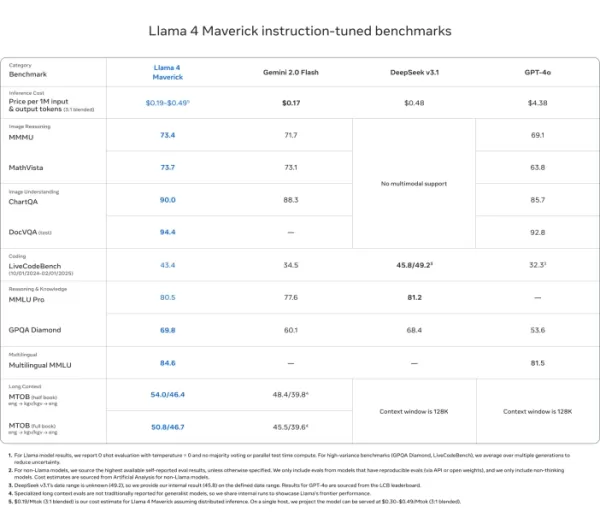
Llama 4 Maverick
- ChartQA、DocVQA、MathVista、MMMUなどのほとんどのマルチモーダル推論ベンチマークでGPT-4oやGemini 2.0 Flashを上回る
- DeepSeek v3.1と競合しながら、アクティブパラメータを半分以下に抑える
- ベンチマークスコア:ChartQA(90.0)、DocVQA(94.4)、MMLU Pro(80.5)
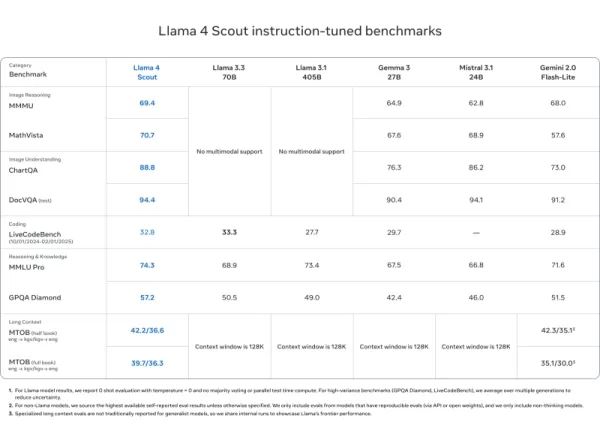
Llama 4 Scout
- DocVQA(94.4)、MMLU Pro(74.3)、MathVista(70.7)でMistral 3.1、Gemini 2.0 Flash-Lite、Gemma 3と同等またはそれ以上
- 比類のない1000万トークンのコンテキスト長—長編ドキュメントやコードベースに最適
DeepSeek R1との比較
トップリーグにおいては、Llama 4 Behemothは善戦していますが、DeepSeek R1やOpenAIのo1シリーズを完全に超えることはできません。MATH-500やMMLUではわずかに遅れていますが、GPQA Diamondではリードしています。それでも、Llama 4が推論分野で強力な競争相手であることは明らかです。
ベンチマーク Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
安全性と政治的中立性
Metaは安全性も忘れていません。Llama Guard、Prompt Guard、CyberSecEvalなどのツールを導入して、適切な運用を確保しています。また、2024年選挙後のザッカーバーグの共和党支持の表明を受けて、特に政治的バイアスを減らし、よりバランスの取れたアプローチを目指しています。
Llama 4の未来
Llama 4により、MetaはAIの効率性、開放性、パフォーマンスの限界を押し広げています。エンタープライズレベルのAIアシスタントを構築したい場合や、AI研究に深く取り組みたい場合、Llama 4は推論を優先した強力で柔軟なオプションを提供します。MetaがAIをよりアクセスしやすく、影響力のあるものにするために尽力していることは明らかです。
関連記事
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
関連特集おすすめ
仕事
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
関連特集おすすめ
仕事
 AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
 10 ツール
10 ツール
 xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

 コメント (30)
0/500
コメント (30)
0/500
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
2025年1月、AI業界は比較的知られていない中国のAIスタートアップ、DeepSeekが革新的なオープンソースの言語推論モデル、DeepSeek R1を発表したことで震撼しました。このモデルはMetaを凌駕するだけでなく、わずか数百万ドルという低コストでそれを実現しました—これはMetaがAIチームのリーダー数人に費やす予算に相当します!このニュースは、Metaが前月にリリースした最新のLlamaモデル、バージョン3.3がすでにやや時代遅れに見えていたこともあり、Metaを少々慌てさせました。
現在に早送りすると、Metaの創設者兼CEOであるマーク・ザッカーバーグはInstagramで新しいLlama 4シリーズの発売を発表しました。このシリーズには、4000億パラメータのLlama 4 Maverickと1090億パラメータのLlama 4 Scoutが含まれており、どちらも開発者がllama.comやHugging Faceで即座にダウンロードして試すことができます。また、2兆パラメータの巨大なモデル、Llama 4 Behemothのプレビューも公開されていますが、これはまだトレーニング中で、リリース日は未定です。
マルチモーダルおよび長コンテキスト機能
これらの新モデルの際立つ特徴の一つは、マルチモーダルな性質です。テキストだけでなく、ビデオや画像も処理できます。さらに、非常に長いコンテキストウィンドウを備えています—Maverickは100万トークン、Scoutに至っては驚異の1000万トークンです。例えるなら、一度に1500ページや1万5000ページのテキストを処理できるということです!医療、科学、文学など、大量の情報を処理・生成する必要がある分野での可能性を想像してみてください。
エキスパート混合アーキテクチャ
Llama 4の3つのモデルはすべて「エキスパート混合(MoE)」アーキテクチャを採用しており、これはOpenAIやMistralなどの企業によって注目を集めている技術です。このアプローチは、複数の小さな専門モデルを1つの大きな効率的なモデルに統合します。各Llama 4モデルは128の異なるエキスパートで構成されており、必要なエキスパートと共有エキスパートのみが各トークンを処理するため、モデルはよりコスト効率が高く、実行速度も速くなります。Metaは、Llama 4 Maverickが単一のNvidia H100 DGXホストで実行可能で、デプロイが容易だと自慢しています。
コスト効率とアクセシビリティ
Metaはこれらのモデルをアクセスしやすくすることに注力しています。ScoutとMaverickはどちらもセルフホスティングが可能で、魅力的なコスト見積もりも公開されています。例えば、Llama 4 Maverickの推論コストは100万トークンあたり0.19ドルから0.49ドルで、GPT-4oなどの他のプロプライエタリモデルと比べると非常に安価です。クラウドプロバイダ経由でこれらのモデルを使用したい場合、Groqはすでに競争力のある価格を提供しています。
強化された推論とMetaP
これらのモデルは推論、コーディング、問題解決を念頭に構築されています。Metaはトレーニング中に簡単なプロンプトを削除し、徐々に難しいプロンプトを用いた継続的な強化学習を使用するなど、巧妙な技術を活用してこれらの能力を強化しました。また、1つのモデルでハイパーパラメータを設定し、他のモデルに適用できる新しい技術、MetaPを導入しました。これは特に、32KのGPUを使用し、30兆トークン以上を処理するBehemothのような巨大モデルのトレーニングにおいて、時間とコストを節約する画期的な技術です。
パフォーマンスと比較
では、これらのモデルはどのように評価されるのでしょうか?ザッカーバーグはオープンソースAIが先導するというビジョンを明確に述べており、Llama 4はその方向への大きな一歩です。すべてのベンチマークで新記録を樹立するわけではありませんが、確かにトップクラスに位置しています。例えば、Llama 4 Behemothは特定のベンチマークで強力な競合を上回っていますが、DeepSeek R1やOpenAIのo1シリーズにはまだ追いついていない部分もあります。
Llama 4 Behemoth
- MATH-500(95.0)、GPQA Diamond(73.7)、MMLU Pro(82.2)でGPT-4.5、Gemini 2.0 Pro、Claude Sonnet 3.7を上回る
Llama 4 Maverick
- ChartQA、DocVQA、MathVista、MMMUなどのほとんどのマルチモーダル推論ベンチマークでGPT-4oやGemini 2.0 Flashを上回る
- DeepSeek v3.1と競合しながら、アクティブパラメータを半分以下に抑える
- ベンチマークスコア:ChartQA(90.0)、DocVQA(94.4)、MMLU Pro(80.5)
Llama 4 Scout
- DocVQA(94.4)、MMLU Pro(74.3)、MathVista(70.7)でMistral 3.1、Gemini 2.0 Flash-Lite、Gemma 3と同等またはそれ以上
- 比類のない1000万トークンのコンテキスト長—長編ドキュメントやコードベースに最適
DeepSeek R1との比較
トップリーグにおいては、Llama 4 Behemothは善戦していますが、DeepSeek R1やOpenAIのo1シリーズを完全に超えることはできません。MATH-500やMMLUではわずかに遅れていますが、GPQA Diamondではリードしています。それでも、Llama 4が推論分野で強力な競争相手であることは明らかです。
| ベンチマーク | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
安全性と政治的中立性
Metaは安全性も忘れていません。Llama Guard、Prompt Guard、CyberSecEvalなどのツールを導入して、適切な運用を確保しています。また、2024年選挙後のザッカーバーグの共和党支持の表明を受けて、特に政治的バイアスを減らし、よりバランスの取れたアプローチを目指しています。
Llama 4の未来
Llama 4により、MetaはAIの効率性、開放性、パフォーマンスの限界を押し広げています。エンタープライズレベルのAIアシスタントを構築したい場合や、AI研究に深く取り組みたい場合、Llama 4は推論を優先した強力で柔軟なオプションを提供します。MetaがAIをよりアクセスしやすく、影響力のあるものにするために尽力していることは明らかです。










 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













