
















 Lar
Lar
Meta revela o lhama 4 com modelos de escoteiros e maverick de longa data, 2T parâmetros gigantes em breve!
Em janeiro de 2025, o mundo da IA foi abalado quando uma startup chinesa de IA relativamente desconhecida, DeepSeek, lançou um desafio com seu inovador modelo de raciocínio linguístico de código aberto, DeepSeek R1. Este modelo não apenas superou empresas como a Meta, mas o fez por uma fração do custo — rumores apontam para apenas alguns milhões de dólares. Esse é o tipo de orçamento que a Meta poderia gastar em apenas alguns de seus líderes de equipe de IA! Essa notícia colocou a Meta em um certo frenesi, especialmente porque seu último modelo Llama, versão 3.3, lançado apenas um mês antes, já parecia um pouco ultrapassado.
Avançando para hoje, o fundador e CEO da Meta, Mark Zuckerberg, foi ao Instagram para anunciar o lançamento da nova série Llama 4. Esta série inclui o Llama 4 Maverick, com 400 bilhões de parâmetros, e o Llama 4 Scout, com 109 bilhões de parâmetros, ambos disponíveis para desenvolvedores baixarem e começarem a experimentar imediatamente em llama.com e Hugging Face. Há também uma prévia de um modelo colossal de 2 trilhões de parâmetros, o Llama 4 Behemoth, ainda em treinamento, sem data de lançamento à vista.
Capacidades Multimodais e de Contexto Longo
Uma das características de destaque desses novos modelos é sua natureza multimodal. Eles não se limitam a texto; também podem lidar com vídeo e imagens. E vêm com janelas de contexto incrivelmente longas — 1 milhão de tokens para o Maverick e impressionantes 10 milhões para o Scout. Para colocar em perspectiva, isso é como lidar com até 1.500 e 15.000 páginas de texto de uma só vez! Imagine as possibilidades para áreas como medicina, ciência ou literatura, onde é necessário processar e gerar grandes quantidades de informação.
Arquitetura de Mistura de Especialistas
Todos os três modelos Llama 4 utilizam a arquitetura de "mistura de especialistas (MoE)", uma técnica que tem causado impacto, popularizada por empresas como OpenAI e Mistral. Essa abordagem combina vários modelos menores e especializados em um modelo maior e mais eficiente. Cada modelo Llama 4 é uma combinação de 128 especialistas diferentes, o que significa que apenas o especialista necessário e um compartilhado lidam com cada token, tornando os modelos mais econômicos e rápidos de executar. A Meta afirma que o Llama 4 Maverick pode ser executado em um único host Nvidia H100 DGX, facilitando a implantação.
Econômico e Acessível
A Meta está focada em tornar esses modelos acessíveis. Tanto o Scout quanto o Maverick estão disponíveis para hospedagem própria, e eles até compartilharam algumas estimativas de custo atraentes. Por exemplo, o custo de inferência para o Llama 4 Maverick está entre $0,19 e $0,49 por milhão de tokens, o que é uma pechincha comparado a outros modelos proprietários como o GPT-4o. E se você estiver interessado em usar esses modelos por meio de um provedor de nuvem, a Groq já se apresentou com preços competitivos.
Raciocínio Aprimorado e MetaP
Esses modelos foram construídos com raciocínio, codificação e resolução de problemas em mente. A Meta usou algumas técnicas inteligentes durante o treinamento para aumentar essas capacidades, como remover prompts fáceis e usar aprendizado por reforço contínuo com prompts cada vez mais difíceis. Eles também introduziram o MetaP, uma nova técnica que permite definir hiperparâmetros em um modelo e aplicá-los a outros, economizando tempo e dinheiro. É uma mudança de jogo, especialmente para treinar monstros como o Behemoth, que usa 32 mil GPUs e processa mais de 30 trilhões de tokens.
Desempenho e Comparações
Então, como esses modelos se saem? Zuckerberg foi claro sobre sua visão de que a IA de código aberto liderará o caminho, e o Llama 4 é um grande passo nessa direção. Embora eles não estabeleçam novos recordes de desempenho em todas as áreas, estão certamente entre os melhores de sua classe. Por exemplo, o Llama 4 Behemoth supera alguns gigantes em certos benchmarks, embora ainda esteja tentando alcançar o DeepSeek R1 e a série o1 da OpenAI em outros.
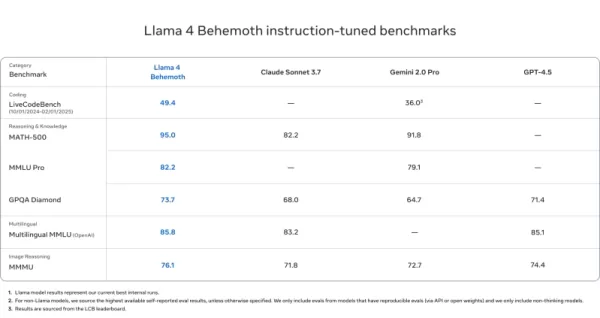
Llama 4 Behemoth
- Supera GPT-4.5, Gemini 2.0 Pro e Claude Sonnet 3.7 em MATH-500 (95,0), GPQA Diamond (73,7) e MMLU Pro (82,2)
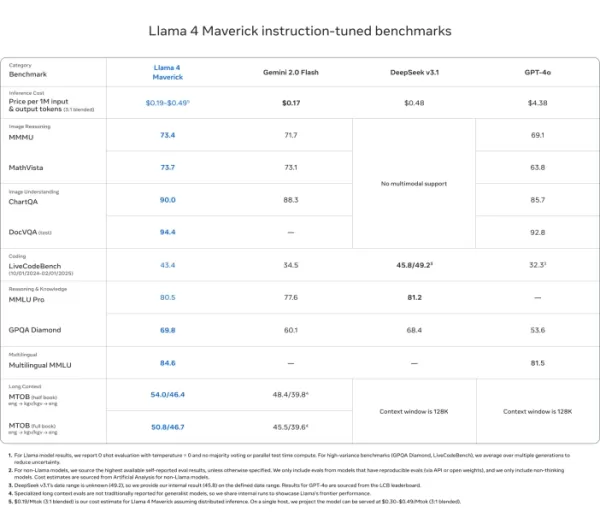
Llama 4 Maverick
- Supera GPT-4o e Gemini 2.0 Flash na maioria dos benchmarks de raciocínio multimodal, como ChartQA, DocVQA, MathVista e MMMU
- Competitivo com DeepSeek v3.1 enquanto usa menos da metade dos parâmetros ativos
- Pontuações de benchmark: ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
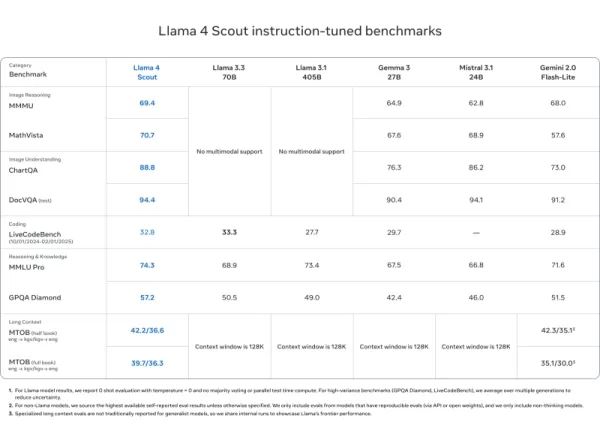
Llama 4 Scout
- Iguala ou supera modelos como Mistral 3.1, Gemini 2.0 Flash-Lite e Gemma 3 em DocVQA (94,4), MMLU Pro (74,3) e MathVista (70,7)
- Comprimento de contexto incomparável de 10 milhões de tokens — ideal para documentos longos e bases de código
Comparando com DeepSeek R1
Quando se trata das grandes ligas, o Llama 4 Behemoth se mantém firme, mas não desbanca completamente o DeepSeek R1 ou a série o1 da OpenAI. Está ligeiramente atrás em MATH-500 e MMLU, mas à frente em GPQA Diamond. Ainda assim, está claro que o Llama 4 é um forte concorrente no espaço de raciocínio.
Benchmark Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95,0 97,3 96,4 GPQA Diamond 73,7 71,5 75,7 MMLU 82,2 90,8 91,8
Segurança e Neutralidade Política
A Meta também não esqueceu da segurança. Eles introduziram ferramentas como Llama Guard, Prompt Guard e CyberSecEval para manter tudo em ordem. E estão destacando a redução de vieses políticos, buscando uma abordagem mais equilibrada, especialmente após o apoio notado de Zuckerberg à política republicana após a eleição de 2024.
O Futuro com Llama 4
Com o Llama 4, a Meta está expandindo os limites da eficiência, abertura e desempenho em IA. Seja para construir assistentes de IA de nível empresarial ou mergulhar fundo na pesquisa de IA, o Llama 4 oferece opções poderosas e flexíveis que priorizam o raciocínio. Está claro que a Meta está comprometida em tornar a IA mais acessível e impactante para todos.
Artigo relacionado
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Recomendações de tópicos especiais relacionados
Negócios
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Recomendações de tópicos especiais relacionados
Negócios
 Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

 Comentários (30)
Comentários (30)
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
Em janeiro de 2025, o mundo da IA foi abalado quando uma startup chinesa de IA relativamente desconhecida, DeepSeek, lançou um desafio com seu inovador modelo de raciocínio linguístico de código aberto, DeepSeek R1. Este modelo não apenas superou empresas como a Meta, mas o fez por uma fração do custo — rumores apontam para apenas alguns milhões de dólares. Esse é o tipo de orçamento que a Meta poderia gastar em apenas alguns de seus líderes de equipe de IA! Essa notícia colocou a Meta em um certo frenesi, especialmente porque seu último modelo Llama, versão 3.3, lançado apenas um mês antes, já parecia um pouco ultrapassado.
Avançando para hoje, o fundador e CEO da Meta, Mark Zuckerberg, foi ao Instagram para anunciar o lançamento da nova série Llama 4. Esta série inclui o Llama 4 Maverick, com 400 bilhões de parâmetros, e o Llama 4 Scout, com 109 bilhões de parâmetros, ambos disponíveis para desenvolvedores baixarem e começarem a experimentar imediatamente em llama.com e Hugging Face. Há também uma prévia de um modelo colossal de 2 trilhões de parâmetros, o Llama 4 Behemoth, ainda em treinamento, sem data de lançamento à vista.
Capacidades Multimodais e de Contexto Longo
Uma das características de destaque desses novos modelos é sua natureza multimodal. Eles não se limitam a texto; também podem lidar com vídeo e imagens. E vêm com janelas de contexto incrivelmente longas — 1 milhão de tokens para o Maverick e impressionantes 10 milhões para o Scout. Para colocar em perspectiva, isso é como lidar com até 1.500 e 15.000 páginas de texto de uma só vez! Imagine as possibilidades para áreas como medicina, ciência ou literatura, onde é necessário processar e gerar grandes quantidades de informação.
Arquitetura de Mistura de Especialistas
Todos os três modelos Llama 4 utilizam a arquitetura de "mistura de especialistas (MoE)", uma técnica que tem causado impacto, popularizada por empresas como OpenAI e Mistral. Essa abordagem combina vários modelos menores e especializados em um modelo maior e mais eficiente. Cada modelo Llama 4 é uma combinação de 128 especialistas diferentes, o que significa que apenas o especialista necessário e um compartilhado lidam com cada token, tornando os modelos mais econômicos e rápidos de executar. A Meta afirma que o Llama 4 Maverick pode ser executado em um único host Nvidia H100 DGX, facilitando a implantação.
Econômico e Acessível
A Meta está focada em tornar esses modelos acessíveis. Tanto o Scout quanto o Maverick estão disponíveis para hospedagem própria, e eles até compartilharam algumas estimativas de custo atraentes. Por exemplo, o custo de inferência para o Llama 4 Maverick está entre $0,19 e $0,49 por milhão de tokens, o que é uma pechincha comparado a outros modelos proprietários como o GPT-4o. E se você estiver interessado em usar esses modelos por meio de um provedor de nuvem, a Groq já se apresentou com preços competitivos.
Raciocínio Aprimorado e MetaP
Esses modelos foram construídos com raciocínio, codificação e resolução de problemas em mente. A Meta usou algumas técnicas inteligentes durante o treinamento para aumentar essas capacidades, como remover prompts fáceis e usar aprendizado por reforço contínuo com prompts cada vez mais difíceis. Eles também introduziram o MetaP, uma nova técnica que permite definir hiperparâmetros em um modelo e aplicá-los a outros, economizando tempo e dinheiro. É uma mudança de jogo, especialmente para treinar monstros como o Behemoth, que usa 32 mil GPUs e processa mais de 30 trilhões de tokens.
Desempenho e Comparações
Então, como esses modelos se saem? Zuckerberg foi claro sobre sua visão de que a IA de código aberto liderará o caminho, e o Llama 4 é um grande passo nessa direção. Embora eles não estabeleçam novos recordes de desempenho em todas as áreas, estão certamente entre os melhores de sua classe. Por exemplo, o Llama 4 Behemoth supera alguns gigantes em certos benchmarks, embora ainda esteja tentando alcançar o DeepSeek R1 e a série o1 da OpenAI em outros.
Llama 4 Behemoth
- Supera GPT-4.5, Gemini 2.0 Pro e Claude Sonnet 3.7 em MATH-500 (95,0), GPQA Diamond (73,7) e MMLU Pro (82,2)
Llama 4 Maverick
- Supera GPT-4o e Gemini 2.0 Flash na maioria dos benchmarks de raciocínio multimodal, como ChartQA, DocVQA, MathVista e MMMU
- Competitivo com DeepSeek v3.1 enquanto usa menos da metade dos parâmetros ativos
- Pontuações de benchmark: ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
Llama 4 Scout
- Iguala ou supera modelos como Mistral 3.1, Gemini 2.0 Flash-Lite e Gemma 3 em DocVQA (94,4), MMLU Pro (74,3) e MathVista (70,7)
- Comprimento de contexto incomparável de 10 milhões de tokens — ideal para documentos longos e bases de código
Comparando com DeepSeek R1
Quando se trata das grandes ligas, o Llama 4 Behemoth se mantém firme, mas não desbanca completamente o DeepSeek R1 ou a série o1 da OpenAI. Está ligeiramente atrás em MATH-500 e MMLU, mas à frente em GPQA Diamond. Ainda assim, está claro que o Llama 4 é um forte concorrente no espaço de raciocínio.
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95,0 | 97,3 | 96,4 |
| GPQA Diamond | 73,7 | 71,5 | 75,7 |
| MMLU | 82,2 | 90,8 | 91,8 |
Segurança e Neutralidade Política
A Meta também não esqueceu da segurança. Eles introduziram ferramentas como Llama Guard, Prompt Guard e CyberSecEval para manter tudo em ordem. E estão destacando a redução de vieses políticos, buscando uma abordagem mais equilibrada, especialmente após o apoio notado de Zuckerberg à política republicana após a eleição de 2024.
O Futuro com Llama 4
Com o Llama 4, a Meta está expandindo os limites da eficiência, abertura e desempenho em IA. Seja para construir assistentes de IA de nível empresarial ou mergulhar fundo na pesquisa de IA, o Llama 4 oferece opções poderosas e flexíveis que priorizam o raciocínio. Está claro que a Meta está comprometida em tornar a IA mais acessível e impactante para todos.










 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
 A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













