
















 Home
Home
Meta Unveils Llama 4 with Long Context Scout and Maverick Models, 2T Parameter Behemoth Coming Soon!
Back in January 2025, the AI world was rocked when a relatively unknown Chinese AI startup, DeepSeek, threw down the gauntlet with their groundbreaking open-source language reasoning model, DeepSeek R1. This model not only outperformed the likes of Meta but did so at a fraction of the cost—rumored to be as little as a few million dollars. That's the kind of budget Meta might spend on just a couple of its AI team leaders! This news sent Meta into a bit of a frenzy, especially since their latest Llama model, version 3.3, released just the month before, was already looking a bit dated.
Fast forward to today, and Meta's founder and CEO, Mark Zuckerberg, has taken to Instagram to announce the launch of the new Llama 4 series. This series includes the 400-billion parameter Llama 4 Maverick and the 109-billion parameter Llama 4 Scout, both available for developers to download and start tinkering with right away on llama.com and Hugging Face. There's also a sneak peek at a colossal 2-trillion parameter model, Llama 4 Behemoth, still in training, with no release date in sight.
Multimodal and Long-Context Capabilities
One of the standout features of these new models is their multimodal nature. They're not just about text; they can handle video and imagery too. And they come with incredibly long context windows—1 million tokens for Maverick and a whopping 10 million for Scout. To put that in perspective, that's like handling up to 1,500 and 15,000 pages of text in one go! Imagine the possibilities for fields like medicine, science, or literature where you need to process and generate vast amounts of information.
Mixture-of-Experts Architecture
All three Llama 4 models employ the "mixture-of-experts (MoE)" architecture, a technique that's been making waves, popularized by companies like OpenAI and Mistral. This approach combines multiple smaller, specialized models into one larger, more efficient model. Each Llama 4 model is a mix of 128 different experts, which means only the necessary expert and a shared one handle each token, making the models more cost-effective and faster to run. Meta boasts that Llama 4 Maverick can be run on a single Nvidia H100 DGX host, making deployment a breeze.
Cost-Effective and Accessible
Meta is all about making these models accessible. Both Scout and Maverick are available for self-hosting, and they've even shared some enticing cost estimates. For instance, the inference cost for Llama 4 Maverick is between $0.19 and $0.49 per million tokens, which is a steal compared to other proprietary models like GPT-4o. And if you're interested in using these models via a cloud provider, Groq has already stepped up with competitive pricing.
Enhanced Reasoning and MetaP
These models are built with reasoning, coding, and problem-solving in mind. Meta's used some clever techniques during training to boost these capabilities, like removing easy prompts and using continuous reinforcement learning with increasingly difficult prompts. They've also introduced MetaP, a new technique that allows for setting hyperparameters on one model and applying them to others, saving time and money. It's a game-changer, especially for training monsters like Behemoth, which uses 32K GPUs and processes over 30 trillion tokens.
Performance and Comparisons
So, how do these models stack up? Zuckerberg's been clear about his vision for open-source AI leading the charge, and Llama 4 is a big step in that direction. While they might not set new performance records across the board, they're certainly near the top of their class. For instance, Llama 4 Behemoth outperforms some heavy hitters on certain benchmarks, though it's still playing catch-up with DeepSeek R1 and OpenAI's o1 series in others.
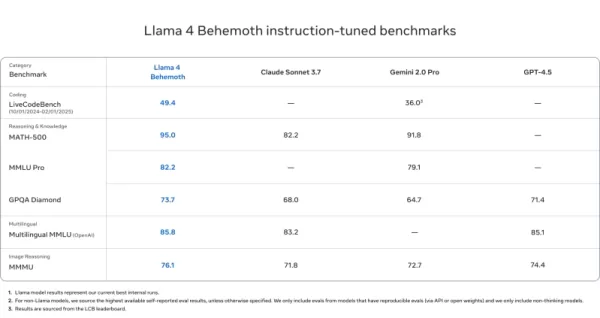
Llama 4 Behemoth
- Outperforms GPT-4.5, Gemini 2.0 Pro, and Claude Sonnet 3.7 on MATH-500 (95.0), GPQA Diamond (73.7), and MMLU Pro (82.2)
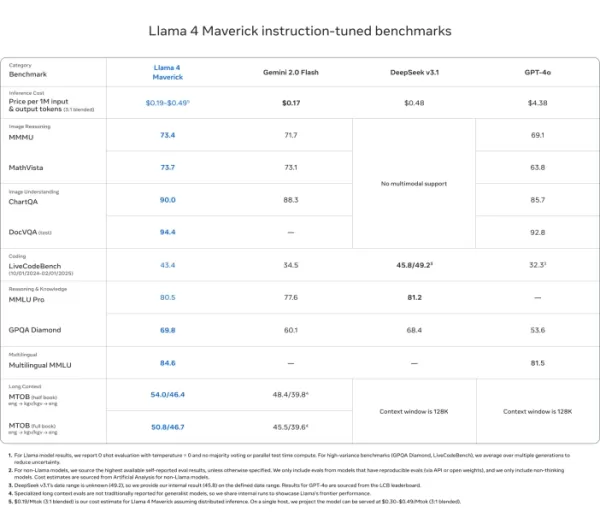
Llama 4 Maverick
- Beats GPT-4o and Gemini 2.0 Flash on most multimodal reasoning benchmarks like ChartQA, DocVQA, MathVista, and MMMU
- Competitive with DeepSeek v3.1 while using less than half the active parameters
- Benchmark scores: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
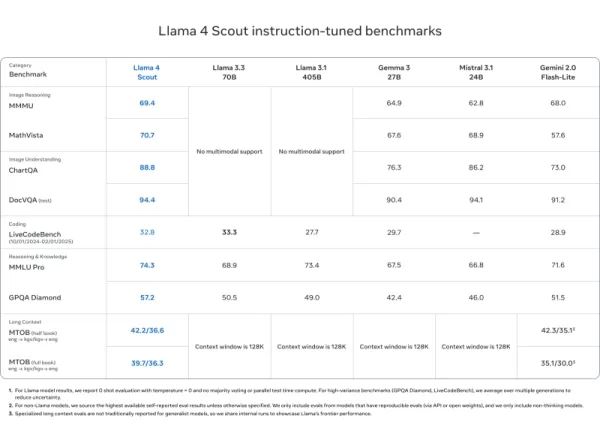
Llama 4 Scout
- Matches or outperforms models like Mistral 3.1, Gemini 2.0 Flash-Lite, and Gemma 3 on DocVQA (94.4), MMLU Pro (74.3), and MathVista (70.7)
- Unmatched 10M token context length—ideal for long documents and codebases
Comparing with DeepSeek R1
When it comes to the big leagues, Llama 4 Behemoth holds its own but doesn't quite dethrone DeepSeek R1 or OpenAI's o1 series. It's slightly behind on MATH-500 and MMLU but ahead on GPQA Diamond. Still, it's clear that Llama 4 is a strong contender in the reasoning space.
Benchmark Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
Safety and Political Neutrality
Meta hasn't forgotten about safety either. They've introduced tools like Llama Guard, Prompt Guard, and CyberSecEval to keep things on the up-and-up. And they're making a point about reducing political bias, aiming for a more balanced approach, especially after Zuckerberg's noted support for Republican politics post-2024 election.
The Future with Llama 4
With Llama 4, Meta is pushing the boundaries of efficiency, openness, and performance in AI. Whether you're looking to build enterprise-level AI assistants or dive deep into AI research, Llama 4 offers powerful, flexible options that prioritize reasoning. It's clear that Meta is committed to making AI more accessible and impactful for everyone.
Related article
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Text-to-speech
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Related Special Topic Recommendations
Text-to-speech
 Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
 10 tools
10 tools
 xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

 Comments (30)
0/500
Comments (30)
0/500
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
Back in January 2025, the AI world was rocked when a relatively unknown Chinese AI startup, DeepSeek, threw down the gauntlet with their groundbreaking open-source language reasoning model, DeepSeek R1. This model not only outperformed the likes of Meta but did so at a fraction of the cost—rumored to be as little as a few million dollars. That's the kind of budget Meta might spend on just a couple of its AI team leaders! This news sent Meta into a bit of a frenzy, especially since their latest Llama model, version 3.3, released just the month before, was already looking a bit dated.
Fast forward to today, and Meta's founder and CEO, Mark Zuckerberg, has taken to Instagram to announce the launch of the new Llama 4 series. This series includes the 400-billion parameter Llama 4 Maverick and the 109-billion parameter Llama 4 Scout, both available for developers to download and start tinkering with right away on llama.com and Hugging Face. There's also a sneak peek at a colossal 2-trillion parameter model, Llama 4 Behemoth, still in training, with no release date in sight.
Multimodal and Long-Context Capabilities
One of the standout features of these new models is their multimodal nature. They're not just about text; they can handle video and imagery too. And they come with incredibly long context windows—1 million tokens for Maverick and a whopping 10 million for Scout. To put that in perspective, that's like handling up to 1,500 and 15,000 pages of text in one go! Imagine the possibilities for fields like medicine, science, or literature where you need to process and generate vast amounts of information.
Mixture-of-Experts Architecture
All three Llama 4 models employ the "mixture-of-experts (MoE)" architecture, a technique that's been making waves, popularized by companies like OpenAI and Mistral. This approach combines multiple smaller, specialized models into one larger, more efficient model. Each Llama 4 model is a mix of 128 different experts, which means only the necessary expert and a shared one handle each token, making the models more cost-effective and faster to run. Meta boasts that Llama 4 Maverick can be run on a single Nvidia H100 DGX host, making deployment a breeze.
Cost-Effective and Accessible
Meta is all about making these models accessible. Both Scout and Maverick are available for self-hosting, and they've even shared some enticing cost estimates. For instance, the inference cost for Llama 4 Maverick is between $0.19 and $0.49 per million tokens, which is a steal compared to other proprietary models like GPT-4o. And if you're interested in using these models via a cloud provider, Groq has already stepped up with competitive pricing.
Enhanced Reasoning and MetaP
These models are built with reasoning, coding, and problem-solving in mind. Meta's used some clever techniques during training to boost these capabilities, like removing easy prompts and using continuous reinforcement learning with increasingly difficult prompts. They've also introduced MetaP, a new technique that allows for setting hyperparameters on one model and applying them to others, saving time and money. It's a game-changer, especially for training monsters like Behemoth, which uses 32K GPUs and processes over 30 trillion tokens.
Performance and Comparisons
So, how do these models stack up? Zuckerberg's been clear about his vision for open-source AI leading the charge, and Llama 4 is a big step in that direction. While they might not set new performance records across the board, they're certainly near the top of their class. For instance, Llama 4 Behemoth outperforms some heavy hitters on certain benchmarks, though it's still playing catch-up with DeepSeek R1 and OpenAI's o1 series in others.
Llama 4 Behemoth
- Outperforms GPT-4.5, Gemini 2.0 Pro, and Claude Sonnet 3.7 on MATH-500 (95.0), GPQA Diamond (73.7), and MMLU Pro (82.2)
Llama 4 Maverick
- Beats GPT-4o and Gemini 2.0 Flash on most multimodal reasoning benchmarks like ChartQA, DocVQA, MathVista, and MMMU
- Competitive with DeepSeek v3.1 while using less than half the active parameters
- Benchmark scores: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
Llama 4 Scout
- Matches or outperforms models like Mistral 3.1, Gemini 2.0 Flash-Lite, and Gemma 3 on DocVQA (94.4), MMLU Pro (74.3), and MathVista (70.7)
- Unmatched 10M token context length—ideal for long documents and codebases
Comparing with DeepSeek R1
When it comes to the big leagues, Llama 4 Behemoth holds its own but doesn't quite dethrone DeepSeek R1 or OpenAI's o1 series. It's slightly behind on MATH-500 and MMLU but ahead on GPQA Diamond. Still, it's clear that Llama 4 is a strong contender in the reasoning space.
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
Safety and Political Neutrality
Meta hasn't forgotten about safety either. They've introduced tools like Llama Guard, Prompt Guard, and CyberSecEval to keep things on the up-and-up. And they're making a point about reducing political bias, aiming for a more balanced approach, especially after Zuckerberg's noted support for Republican politics post-2024 election.
The Future with Llama 4
With Llama 4, Meta is pushing the boundaries of efficiency, openness, and performance in AI. Whether you're looking to build enterprise-level AI assistants or dive deep into AI research, Llama 4 offers powerful, flexible options that prioritize reasoning. It's clear that Meta is committed to making AI more accessible and impactful for everyone.










 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
 Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
Meta AI now responds to buyer messages on Facebook Marketplace
Facebook Marketplace introduces new Meta AI features, including automated replies to buyer inquiries, the company announced Thursday. The platform also leverages AI to accelerate item listings, summarize seller profiles, and now lets sellers offer sh
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













