
















 首页
首页Meta揭开了长篇小说侦察兵和特立独行的模型,2T参数庞然大物即将推出!
2025年1月,人工智能界掀起波澜,一家鲜为人知的中国特色人工智能初创公司DeepSeek推出了其开创性的开源语言推理模型DeepSeek R1。该模型不仅性能超越了Meta等公司,而且成本仅为传闻中的几百万美元。相比之下,Meta可能仅在几位人工智能团队领导者身上就花费了这么多!这一消息让Meta有些慌乱,尤其是因为他们上个月刚发布的最新Llama模型3.3版已经显得有些过时。
快进到今天,Meta的创始人兼首席执行官马克·扎克伯格在Instagram上宣布推出新的Llama 4系列。该系列包括4000亿参数的Llama 4 Maverick和1090亿参数的Llama 4 Scout,开发者可立即在llama.com和Hugging Face上下载并开始使用。此外,还有一个正在训练中的庞大2万亿参数模型Llama 4 Behemoth的预览,尚未确定发布日期。
多模态和长上下文能力
这些新模型的突出特点是其多模态特性。它们不仅限于文本,还能处理视频和图像。它们的上下文窗口极长——Maverick为100万令牌,Scout更是高达1000万令牌。换句话说,这相当于一次性处理1500页和15000页的文本!想象一下,这对医学、科学或文学等领域处理和生成大量信息的可能性。
专家混合架构
所有三个Llama 4模型都采用了“专家混合(MoE)”架构,这种技术由OpenAI和Mistral等公司推广,备受关注。该方法将多个较小的专业模型组合成一个更大、更高效的模型。每个Llama 4模型由128个不同的专家组成,这意味着每个令牌仅由必要的专家和一个共享专家处理,使模型更具成本效益且运行更快。Meta宣称Llama 4 Maverick可在单个Nvidia H100 DGX主机上运行,部署非常简便。
成本效益和可访问性
Meta致力于让这些模型易于获取。Scout和Maverick均可用于自托管,他们甚至分享了一些诱人的成本估算。例如,Llama 4 Maverick的推理成本在每百万令牌0.19美元至0.49美元之间,相比其他专有模型如GPT-4o,这非常划算。如果您有兴趣通过云提供商使用这些模型,Groq已经提供了具有竞争力的定价。
增强推理和MetaP
这些模型专为推理、编码和问题解决而设计。Meta在训练中采用了一些巧妙技术来提升这些能力,例如移除简单提示并使用持续强化学习,逐步增加提示难度。他们还引入了MetaP,一种新技术,允许在一个模型上设置超参数并将其应用于其他模型,从而节省时间和成本。这对训练像Behemoth这样使用32K GPU并处理超过30万亿令牌的巨型模型尤为重要。
性能与比较
那么,这些模型表现如何?扎克伯格明确表示,他希望开源人工智能引领潮流,Llama 4是朝着这个方向迈出的一大步。虽然它们可能不会在所有方面都创下新的性能记录,但无疑名列前茅。例如,Llama 4 Behemoth在某些基准测试中超越了一些重量级选手,尽管在其他方面仍需追赶DeepSeek R1和OpenAI的o1系列。
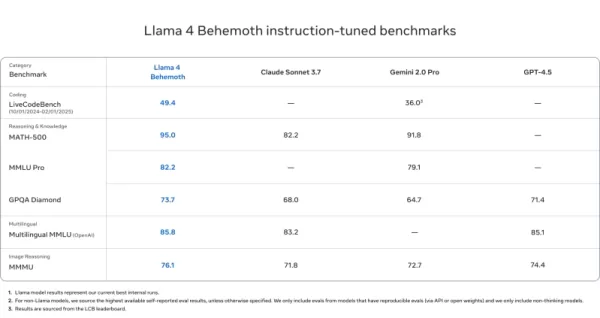
Llama 4 Behemoth
- 在MATH-500(95.0)、GPQA Diamond(73.7)和MMLU Pro(82.2)上超越GPT-4.5、Gemini 2.0 Pro和Claude Sonnet 3.7
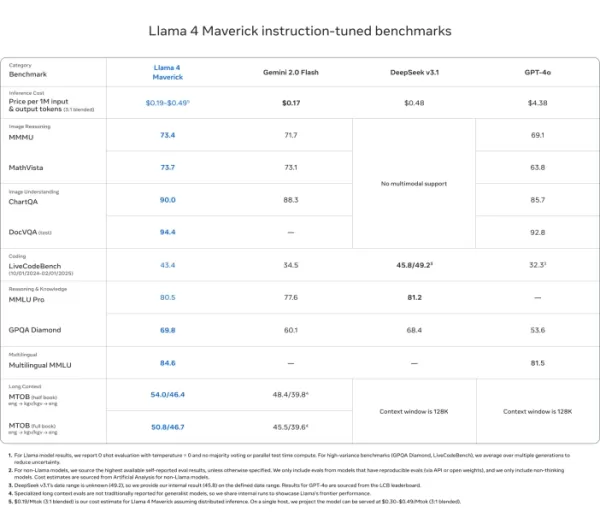
Llama 4 Maverick
- 在ChartQA、DocVQA、MathVista和MMMU等大多数多模态推理基准测试中击败GPT-4o和Gemini 2.0 Flash
- 与DeepSeek v3.1竞争,同时使用的活跃参数不到其一半
- 基准测试得分:ChartQA(90.0)、DocVQA(94.4)、MMLU Pro(80.5)
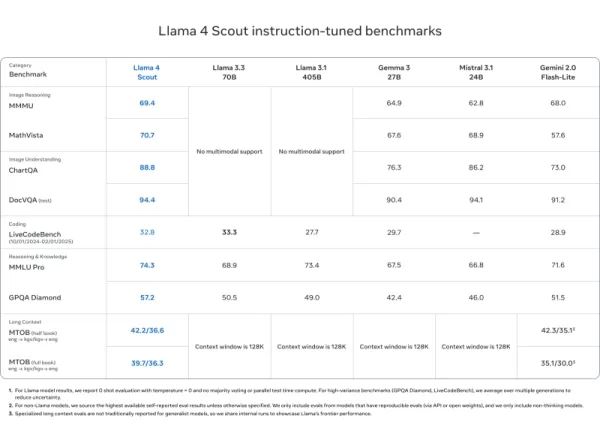
Llama 4 Scout
- 在DocVQA(94.4)、MMLU Pro(74.3)和MathVista(70.7)上匹配或超越Mistral 3.1、Gemini 2.0 Flash-Lite和Gemma 3等模型
- 无与伦比的1000万令牌上下文长度——非常适合长文档和代码库
与DeepSeek R1的比较
在顶级竞争中,Llama 4 Behemoth表现出色,但尚未完全超越DeepSeek R1或OpenAI的o1系列。它在MATH-500和MMLU上略逊一筹,但在GPQA Diamond上领先。即便如此,Llama 4显然是推理领域的强劲竞争者。
基准测试 Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
安全性和政治中立性
Meta也没有忽视安全性。他们推出了Llama Guard、Prompt Guard和CyberSecEval等工具以确保安全。他们还强调减少政治偏见,致力于更平衡的方法,特别是在扎克伯格在2024年选举后表示支持共和党政治之后。
Llama 4的未来
通过Llama 4,Meta正在推动人工智能的效率、开放性和性能的边界。无论您是想构建企业级人工智能助手还是深入研究人工智能,Llama 4都提供了强大而灵活的选择,优先考虑推理能力。显然,Meta致力于让人工智能对每个人更易获取且更具影响力。
相关文章
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
相关专题推荐
写作
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
相关专题推荐
写作
 顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
 10 个工具
10 个工具
 xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai
代码
最佳 AI 代码审查工具:自动确保代码符合规范,并重构遗留代码库文件
在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai
文字转语音
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

 评论 (30)
0/500
评论 (30)
0/500
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
2025年1月,人工智能界掀起波澜,一家鲜为人知的中国特色人工智能初创公司DeepSeek推出了其开创性的开源语言推理模型DeepSeek R1。该模型不仅性能超越了Meta等公司,而且成本仅为传闻中的几百万美元。相比之下,Meta可能仅在几位人工智能团队领导者身上就花费了这么多!这一消息让Meta有些慌乱,尤其是因为他们上个月刚发布的最新Llama模型3.3版已经显得有些过时。
快进到今天,Meta的创始人兼首席执行官马克·扎克伯格在Instagram上宣布推出新的Llama 4系列。该系列包括4000亿参数的Llama 4 Maverick和1090亿参数的Llama 4 Scout,开发者可立即在llama.com和Hugging Face上下载并开始使用。此外,还有一个正在训练中的庞大2万亿参数模型Llama 4 Behemoth的预览,尚未确定发布日期。
多模态和长上下文能力
这些新模型的突出特点是其多模态特性。它们不仅限于文本,还能处理视频和图像。它们的上下文窗口极长——Maverick为100万令牌,Scout更是高达1000万令牌。换句话说,这相当于一次性处理1500页和15000页的文本!想象一下,这对医学、科学或文学等领域处理和生成大量信息的可能性。
专家混合架构
所有三个Llama 4模型都采用了“专家混合(MoE)”架构,这种技术由OpenAI和Mistral等公司推广,备受关注。该方法将多个较小的专业模型组合成一个更大、更高效的模型。每个Llama 4模型由128个不同的专家组成,这意味着每个令牌仅由必要的专家和一个共享专家处理,使模型更具成本效益且运行更快。Meta宣称Llama 4 Maverick可在单个Nvidia H100 DGX主机上运行,部署非常简便。
成本效益和可访问性
Meta致力于让这些模型易于获取。Scout和Maverick均可用于自托管,他们甚至分享了一些诱人的成本估算。例如,Llama 4 Maverick的推理成本在每百万令牌0.19美元至0.49美元之间,相比其他专有模型如GPT-4o,这非常划算。如果您有兴趣通过云提供商使用这些模型,Groq已经提供了具有竞争力的定价。
增强推理和MetaP
这些模型专为推理、编码和问题解决而设计。Meta在训练中采用了一些巧妙技术来提升这些能力,例如移除简单提示并使用持续强化学习,逐步增加提示难度。他们还引入了MetaP,一种新技术,允许在一个模型上设置超参数并将其应用于其他模型,从而节省时间和成本。这对训练像Behemoth这样使用32K GPU并处理超过30万亿令牌的巨型模型尤为重要。
性能与比较
那么,这些模型表现如何?扎克伯格明确表示,他希望开源人工智能引领潮流,Llama 4是朝着这个方向迈出的一大步。虽然它们可能不会在所有方面都创下新的性能记录,但无疑名列前茅。例如,Llama 4 Behemoth在某些基准测试中超越了一些重量级选手,尽管在其他方面仍需追赶DeepSeek R1和OpenAI的o1系列。
Llama 4 Behemoth
- 在MATH-500(95.0)、GPQA Diamond(73.7)和MMLU Pro(82.2)上超越GPT-4.5、Gemini 2.0 Pro和Claude Sonnet 3.7
Llama 4 Maverick
- 在ChartQA、DocVQA、MathVista和MMMU等大多数多模态推理基准测试中击败GPT-4o和Gemini 2.0 Flash
- 与DeepSeek v3.1竞争,同时使用的活跃参数不到其一半
- 基准测试得分:ChartQA(90.0)、DocVQA(94.4)、MMLU Pro(80.5)
Llama 4 Scout
- 在DocVQA(94.4)、MMLU Pro(74.3)和MathVista(70.7)上匹配或超越Mistral 3.1、Gemini 2.0 Flash-Lite和Gemma 3等模型
- 无与伦比的1000万令牌上下文长度——非常适合长文档和代码库
与DeepSeek R1的比较
在顶级竞争中,Llama 4 Behemoth表现出色,但尚未完全超越DeepSeek R1或OpenAI的o1系列。它在MATH-500和MMLU上略逊一筹,但在GPQA Diamond上领先。即便如此,Llama 4显然是推理领域的强劲竞争者。
| 基准测试 | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
安全性和政治中立性
Meta也没有忽视安全性。他们推出了Llama Guard、Prompt Guard和CyberSecEval等工具以确保安全。他们还强调减少政治偏见,致力于更平衡的方法,特别是在扎克伯格在2024年选举后表示支持共和党政治之后。
Llama 4的未来
通过Llama 4,Meta正在推动人工智能的效率、开放性和性能的边界。无论您是想构建企业级人工智能助手还是深入研究人工智能,Llama 4都提供了强大而灵活的选择,优先考虑推理能力。显然,Meta致力于让人工智能对每个人更易获取且更具影响力。










 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
 Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
Meta AI 现已在 Facebook Marketplace 上回复买家消息
Facebook周四宣布,Facebook Marketplace推出了新的Meta AI功能,包括对买家咨询的自动回复。该平台还利用AI加速商品上架、总结卖家资料,并允许卖家在商品列表中提供配送服务。鉴于卖家通常会收到大量买家咨询,Facebook正通过由Meta AI驱动的自动回复功能简化这一流程。当买家询问商品库存情况时,卖家可利用Meta AI根据商品详情(如描述、库存、自提地点和价格)自
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













