
















 Heim
Heim
Meta enthüllt llama 4 mit langen Kontext -Scout- und Maverick -Modellen, 2T -Parameter -Giganten in Kürze!
Im Januar 2025 wurde die Welt der KI erschüttert, als ein relativ unbekanntes chinesisches KI-Startup, DeepSeek, mit seinem bahnbrechenden Open-Source-Sprachmodell DeepSeek R1 die Herausforderung annahm. Dieses Modell übertraf nicht nur Unternehmen wie Meta, sondern tat dies zu einem Bruchteil der Kosten – Gerüchten zufolge nur wenige Millionen Dollar. Das ist der Betrag, den Meta vielleicht für nur ein paar seiner KI-Teamleiter ausgibt! Diese Nachricht versetzte Meta in einen gewissen Aufruhr, zumal ihr neuestes Llama-Modell, Version 3.3, das erst im Vormonat veröffentlicht wurde, bereits etwas veraltet wirkte.
Schnell vorwärts bis heute: Metas Gründer und CEO, Mark Zuckerberg, hat auf Instagram die Einführung der neuen Llama 4-Serie angekündigt. Diese Serie umfasst das 400-Milliarden-Parameter-Modell Llama 4 Maverick und das 109-Milliarden-Parameter-Modell Llama 4 Scout, die beide sofort für Entwickler auf llama.com und Hugging Face zum Download und Experimentieren verfügbar sind. Es gibt auch einen kleinen Ausblick auf ein kolossales 2-Billionen-Parameter-Modell, Llama 4 Behemoth, das sich noch in der Entwicklung befindet und kein Veröffentlichungsdatum in Sicht hat.
Multimodale und Langkontext-Fähigkeiten
Eine der herausragenden Eigenschaften dieser neuen Modelle ist ihre multimodale Natur. Sie beschränken sich nicht nur auf Text; sie können auch Videos und Bilder verarbeiten. Und sie verfügen über unglaublich lange Kontextfenster – 1 Million Token für Maverick und beeindruckende 10 Millionen für Scout. Um das ins Verhältnis zu setzen: Das entspricht der Verarbeitung von bis zu 1.500 bzw. 15.000 Textseiten auf einmal! Stellen Sie sich die Möglichkeiten für Bereiche wie Medizin, Wissenschaft oder Literatur vor, in denen große Mengen an Informationen verarbeitet und generiert werden müssen.
Mischung-aus-Experten-Architektur
Alle drei Llama 4-Modelle nutzen die „Mixture-of-Experts (MoE)“-Architektur, eine Technik, die Wellen schlägt und von Unternehmen wie OpenAI und Mistral populär gemacht wurde. Dieser Ansatz kombiniert mehrere kleinere, spezialisierte Modelle zu einem größeren, effizienteren Modell. Jedes Llama 4-Modell besteht aus einer Mischung von 128 verschiedenen Experten, was bedeutet, dass nur der benötigte Experte und ein gemeinsamer Experte jedes Token verarbeiten, was die Modelle kostengünstiger und schneller macht. Meta rühmt sich, dass Llama 4 Maverick auf einem einzigen Nvidia H100 DGX-Host betrieben werden kann, was die Bereitstellung erleichtert.
Kostengünstig und zugänglich
Meta legt großen Wert darauf, diese Modelle zugänglich zu machen. Sowohl Scout als auch Maverick sind für das Selbst-Hosting verfügbar, und sie haben sogar einige verlockende Kostenschätzungen geteilt. Zum Beispiel liegen die Inferenzkosten für Llama 4 Maverick zwischen 0,19 $ und 0,49 $ pro Million Token, was im Vergleich zu anderen proprietären Modellen wie GPT-4o ein Schnäppchen ist. Und wenn Sie daran interessiert sind, diese Modelle über einen Cloud-Anbieter zu nutzen, hat Groq bereits wettbewerbsfähige Preise angeboten.
Verbesserte Argumentationsfähigkeiten und MetaP
Diese Modelle sind auf Argumentation, Programmierung und Problemlösung ausgelegt. Meta hat während des Trainings einige clevere Techniken eingesetzt, um diese Fähigkeiten zu steigern, wie das Entfernen einfacher Prompts und die Verwendung von kontinuierlichem Verstärkungslernen mit zunehmend schwierigen Prompts. Sie haben auch MetaP eingeführt, eine neue Technik, die es ermöglicht, Hyperparameter für ein Modell festzulegen und sie auf andere anzuwenden, was Zeit und Geld spart. Das ist ein echter Durchbruch, insbesondere für das Training von Giganten wie Behemoth, das 32.000 GPUs verwendet und über 30 Billionen Token verarbeitet.
Leistung und Vergleiche
Wie schneiden diese Modelle also ab? Zuckerberg hat klar gemacht, dass seine Vision für Open-Source-KI führend ist, und Llama 4 ist ein großer Schritt in diese Richtung. Sie setzen vielleicht nicht überall neue Leistungsrekorde, aber sie gehören sicherlich zur Spitzenklasse. Zum Beispiel übertrifft Llama 4 Behemoth einige Schwergewichte in bestimmten Benchmarks, obwohl es in anderen noch hinter DeepSeek R1 und der o1-Serie von OpenAI zurückliegt.
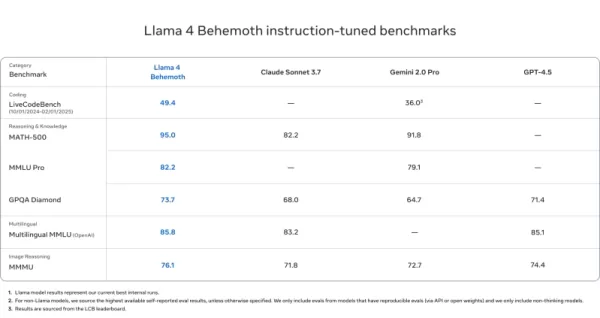
Llama 4 Behemoth
- Übertrifft GPT-4.5, Gemini 2.0 Pro und Claude Sonnet 3.7 bei MATH-500 (95,0), GPQA Diamond (73,7) und MMLU Pro (82,2)
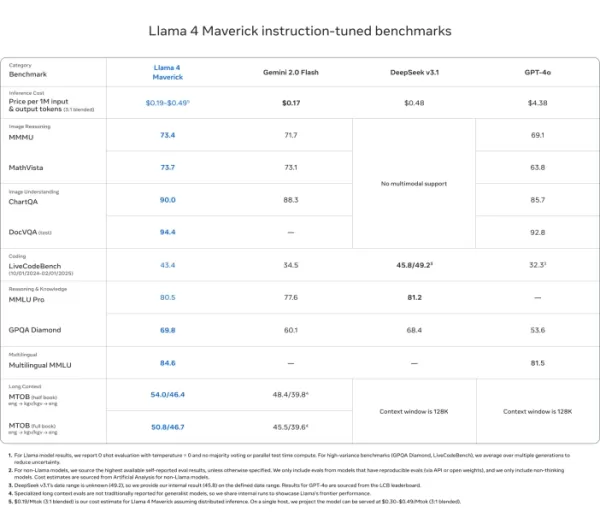
Llama 4 Maverick
- Schlägt GPT-4o und Gemini 2.0 Flash bei den meisten multimodalen Argumentations-Benchmarks wie ChartQA, DocVQA, MathVista und MMMU
- Konkurrenzfähig mit DeepSeek v3.1, während weniger als die Hälfte der aktiven Parameter verwendet werden
- Benchmark-Werte: ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
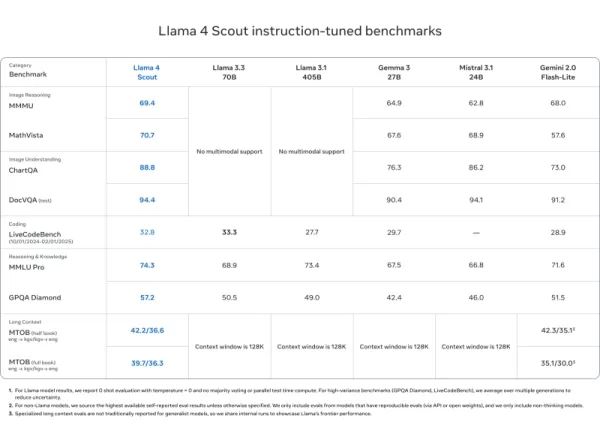
Llama 4 Scout
- Gleicht oder übertrifft Modelle wie Mistral 3.1, Gemini 2.0 Flash-Lite und Gemma 3 bei DocVQA (94,4), MMLU Pro (74,3) und MathVista (70,7)
- Einzigartige Kontextlänge von 10 Millionen Token – ideal für lange Dokumente und Codebasen
Vergleich mit DeepSeek R1
In der obersten Liga hält Llama 4 Behemoth stand, kann aber DeepSeek R1 oder die o1-Serie von OpenAI nicht ganz vom Thron stoßen. Es liegt bei MATH-500 und MMLU leicht zurück, ist aber bei GPQA Diamond vorn. Dennoch ist klar, dass Llama 4 ein starker Konkurrent im Bereich der Argumentation ist.
Benchmark Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95,0 97,3 96,4 GPQA Diamond 73,7 71,5 75,7 MMLU 82,2 90,8 91,8
Sicherheit und politische Neutralität
Meta hat auch die Sicherheit nicht vergessen. Sie haben Tools wie Llama Guard, Prompt Guard und CyberSecEval eingeführt, um alles im Rahmen zu halten. Und sie legen Wert darauf, politische Voreingenommenheit zu reduzieren, mit dem Ziel eines ausgewogeneren Ansatzes, insbesondere nach Zuckerbergs bekannter Unterstützung für republikanische Politik nach der Wahl 2024.
Die Zukunft mit Llama 4
Mit Llama 4 verschiebt Meta die Grenzen von Effizienz, Offenheit und Leistung in der KI. Egal, ob Sie KI-Assistenten auf Unternehmensebene entwickeln oder tief in die KI-Forschung eintauchen möchten, Llama 4 bietet leistungsstarke, flexible Optionen, die die Argumentation in den Vordergrund stellen. Es ist klar, dass Meta entschlossen ist, KI für alle zugänglicher und wirkungsvoller zu machen.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Empfehlungen zu verwandten Spezialthemen
Code
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Empfehlungen zu verwandten Spezialthemen
Code
 Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
 10 Tools
10 Tools
 xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

 Kommentare (30)
Kommentare (30)
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
Im Januar 2025 wurde die Welt der KI erschüttert, als ein relativ unbekanntes chinesisches KI-Startup, DeepSeek, mit seinem bahnbrechenden Open-Source-Sprachmodell DeepSeek R1 die Herausforderung annahm. Dieses Modell übertraf nicht nur Unternehmen wie Meta, sondern tat dies zu einem Bruchteil der Kosten – Gerüchten zufolge nur wenige Millionen Dollar. Das ist der Betrag, den Meta vielleicht für nur ein paar seiner KI-Teamleiter ausgibt! Diese Nachricht versetzte Meta in einen gewissen Aufruhr, zumal ihr neuestes Llama-Modell, Version 3.3, das erst im Vormonat veröffentlicht wurde, bereits etwas veraltet wirkte.
Schnell vorwärts bis heute: Metas Gründer und CEO, Mark Zuckerberg, hat auf Instagram die Einführung der neuen Llama 4-Serie angekündigt. Diese Serie umfasst das 400-Milliarden-Parameter-Modell Llama 4 Maverick und das 109-Milliarden-Parameter-Modell Llama 4 Scout, die beide sofort für Entwickler auf llama.com und Hugging Face zum Download und Experimentieren verfügbar sind. Es gibt auch einen kleinen Ausblick auf ein kolossales 2-Billionen-Parameter-Modell, Llama 4 Behemoth, das sich noch in der Entwicklung befindet und kein Veröffentlichungsdatum in Sicht hat.
Multimodale und Langkontext-Fähigkeiten
Eine der herausragenden Eigenschaften dieser neuen Modelle ist ihre multimodale Natur. Sie beschränken sich nicht nur auf Text; sie können auch Videos und Bilder verarbeiten. Und sie verfügen über unglaublich lange Kontextfenster – 1 Million Token für Maverick und beeindruckende 10 Millionen für Scout. Um das ins Verhältnis zu setzen: Das entspricht der Verarbeitung von bis zu 1.500 bzw. 15.000 Textseiten auf einmal! Stellen Sie sich die Möglichkeiten für Bereiche wie Medizin, Wissenschaft oder Literatur vor, in denen große Mengen an Informationen verarbeitet und generiert werden müssen.
Mischung-aus-Experten-Architektur
Alle drei Llama 4-Modelle nutzen die „Mixture-of-Experts (MoE)“-Architektur, eine Technik, die Wellen schlägt und von Unternehmen wie OpenAI und Mistral populär gemacht wurde. Dieser Ansatz kombiniert mehrere kleinere, spezialisierte Modelle zu einem größeren, effizienteren Modell. Jedes Llama 4-Modell besteht aus einer Mischung von 128 verschiedenen Experten, was bedeutet, dass nur der benötigte Experte und ein gemeinsamer Experte jedes Token verarbeiten, was die Modelle kostengünstiger und schneller macht. Meta rühmt sich, dass Llama 4 Maverick auf einem einzigen Nvidia H100 DGX-Host betrieben werden kann, was die Bereitstellung erleichtert.
Kostengünstig und zugänglich
Meta legt großen Wert darauf, diese Modelle zugänglich zu machen. Sowohl Scout als auch Maverick sind für das Selbst-Hosting verfügbar, und sie haben sogar einige verlockende Kostenschätzungen geteilt. Zum Beispiel liegen die Inferenzkosten für Llama 4 Maverick zwischen 0,19 $ und 0,49 $ pro Million Token, was im Vergleich zu anderen proprietären Modellen wie GPT-4o ein Schnäppchen ist. Und wenn Sie daran interessiert sind, diese Modelle über einen Cloud-Anbieter zu nutzen, hat Groq bereits wettbewerbsfähige Preise angeboten.
Verbesserte Argumentationsfähigkeiten und MetaP
Diese Modelle sind auf Argumentation, Programmierung und Problemlösung ausgelegt. Meta hat während des Trainings einige clevere Techniken eingesetzt, um diese Fähigkeiten zu steigern, wie das Entfernen einfacher Prompts und die Verwendung von kontinuierlichem Verstärkungslernen mit zunehmend schwierigen Prompts. Sie haben auch MetaP eingeführt, eine neue Technik, die es ermöglicht, Hyperparameter für ein Modell festzulegen und sie auf andere anzuwenden, was Zeit und Geld spart. Das ist ein echter Durchbruch, insbesondere für das Training von Giganten wie Behemoth, das 32.000 GPUs verwendet und über 30 Billionen Token verarbeitet.
Leistung und Vergleiche
Wie schneiden diese Modelle also ab? Zuckerberg hat klar gemacht, dass seine Vision für Open-Source-KI führend ist, und Llama 4 ist ein großer Schritt in diese Richtung. Sie setzen vielleicht nicht überall neue Leistungsrekorde, aber sie gehören sicherlich zur Spitzenklasse. Zum Beispiel übertrifft Llama 4 Behemoth einige Schwergewichte in bestimmten Benchmarks, obwohl es in anderen noch hinter DeepSeek R1 und der o1-Serie von OpenAI zurückliegt.
Llama 4 Behemoth
- Übertrifft GPT-4.5, Gemini 2.0 Pro und Claude Sonnet 3.7 bei MATH-500 (95,0), GPQA Diamond (73,7) und MMLU Pro (82,2)
Llama 4 Maverick
- Schlägt GPT-4o und Gemini 2.0 Flash bei den meisten multimodalen Argumentations-Benchmarks wie ChartQA, DocVQA, MathVista und MMMU
- Konkurrenzfähig mit DeepSeek v3.1, während weniger als die Hälfte der aktiven Parameter verwendet werden
- Benchmark-Werte: ChartQA (90,0), DocVQA (94,4), MMLU Pro (80,5)
Llama 4 Scout
- Gleicht oder übertrifft Modelle wie Mistral 3.1, Gemini 2.0 Flash-Lite und Gemma 3 bei DocVQA (94,4), MMLU Pro (74,3) und MathVista (70,7)
- Einzigartige Kontextlänge von 10 Millionen Token – ideal für lange Dokumente und Codebasen
Vergleich mit DeepSeek R1
In der obersten Liga hält Llama 4 Behemoth stand, kann aber DeepSeek R1 oder die o1-Serie von OpenAI nicht ganz vom Thron stoßen. Es liegt bei MATH-500 und MMLU leicht zurück, ist aber bei GPQA Diamond vorn. Dennoch ist klar, dass Llama 4 ein starker Konkurrent im Bereich der Argumentation ist.
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95,0 | 97,3 | 96,4 |
| GPQA Diamond | 73,7 | 71,5 | 75,7 |
| MMLU | 82,2 | 90,8 | 91,8 |
Sicherheit und politische Neutralität
Meta hat auch die Sicherheit nicht vergessen. Sie haben Tools wie Llama Guard, Prompt Guard und CyberSecEval eingeführt, um alles im Rahmen zu halten. Und sie legen Wert darauf, politische Voreingenommenheit zu reduzieren, mit dem Ziel eines ausgewogeneren Ansatzes, insbesondere nach Zuckerbergs bekannter Unterstützung für republikanische Politik nach der Wahl 2024.
Die Zukunft mit Llama 4
Mit Llama 4 verschiebt Meta die Grenzen von Effizienz, Offenheit und Leistung in der KI. Egal, ob Sie KI-Assistenten auf Unternehmensebene entwickeln oder tief in die KI-Forschung eintauchen möchten, Llama 4 bietet leistungsstarke, flexible Optionen, die die Argumentation in den Vordergrund stellen. Es ist klar, dass Meta entschlossen ist, KI für alle zugänglicher und wirkungsvoller zu machen.










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













