




Meta tiết lộ Llama 4 với các mô hình Scout và Maverick Bối cảnh dài, sắp ra mắt tham số 2t sắp ra mắt!
Vào tháng 1 năm 2025, thế giới AI chấn động khi một công ty khởi nghiệp AI Trung Quốc ít được biết đến, DeepSeek, đã thách thức với mô hình suy luận ngôn ngữ mã nguồn mở đột phá của họ, DeepSeek R1. Mô hình này không chỉ vượt qua những gã khổng lồ như Meta mà còn làm điều đó với chi phí chỉ bằng một phần nhỏ—được đồn đại là chỉ vài triệu đô la. Đó là số tiền mà Meta có thể chi chỉ cho một vài lãnh đạo đội AI của họ! Tin tức này đã khiến Meta rơi vào tình trạng rối loạn, đặc biệt khi mô hình Llama mới nhất của họ, phiên bản 3.3, ra mắt chỉ một tháng trước, đã bắt đầu trông có vẻ lỗi thời.
Nhanh chóng tiến đến hôm nay, nhà sáng lập kiêm CEO của Meta, Mark Zuckerberg, đã lên Instagram để công bố ra mắt dòng Llama 4 mới. Dòng này bao gồm Llama 4 Maverick với 400 tỷ tham số và Llama 4 Scout với 109 tỷ tham số, cả hai đều có sẵn để các nhà phát triển tải xuống và bắt đầu thử nghiệm ngay lập tức trên llama.com và Hugging Face. Ngoài ra còn có một cái nhìn sơ lược về một mô hình khổng lồ với 2 nghìn tỷ tham số, Llama 4 Behemoth, vẫn đang trong quá trình huấn luyện, chưa có ngày ra mắt cụ thể.
Khả năng Đa phương thức và Ngữ cảnh Dài
Một trong những đặc điểm nổi bật của các mô hình mới này là tính chất đa phương thức. Chúng không chỉ xử lý văn bản mà còn có thể xử lý video và hình ảnh. Và chúng đi kèm với cửa sổ ngữ cảnh cực kỳ dài—1 triệu token cho Maverick và con số khổng lồ 10 triệu cho Scout. Để dễ hình dung, điều đó tương đương với việc xử lý tới 1.500 và 15.000 trang văn bản trong một lần! Hãy tưởng tượng những khả năng cho các lĩnh vực như y học, khoa học hoặc văn học, nơi cần xử lý và tạo ra lượng thông tin khổng lồ.
Kiến trúc Hỗn hợp Chuyên gia
Cả ba mô hình Llama 4 đều sử dụng kiến trúc "hỗn hợp chuyên gia (MoE)", một kỹ thuật đang tạo sóng gió, được phổ biến bởi các công ty như OpenAI và Mistral. Phương pháp này kết hợp nhiều mô hình nhỏ hơn, chuyên biệt thành một mô hình lớn hơn, hiệu quả hơn. Mỗi mô hình Llama 4 là sự kết hợp của 128 chuyên gia khác nhau, nghĩa là chỉ chuyên gia cần thiết và một chuyên gia chung xử lý mỗi token, giúp các mô hình tiết kiệm chi phí hơn và chạy nhanh hơn. Meta tự hào rằng Llama 4 Maverick có thể chạy trên một máy chủ Nvidia H100 DGX duy nhất, giúp việc triển khai trở nên dễ dàng.
Tiết kiệm Chi phí và Dễ tiếp cận
Meta tập trung vào việc làm cho các mô hình này dễ tiếp cận. Cả Scout và Maverick đều có sẵn để tự lưu trữ, và họ thậm chí đã chia sẻ một số ước tính chi phí hấp dẫn. Chẳng hạn, chi phí suy luận cho Llama 4 Maverick dao động từ 0,19 đến 0,49 đô la mỗi triệu token, một mức giá rất hời so với các mô hình độc quyền khác như GPT-4o. Và nếu bạn muốn sử dụng các mô hình này thông qua nhà cung cấp đám mây, Groq đã bước lên với mức giá cạnh tranh.
Suy luận Nâng cao và MetaP
Các mô hình này được xây dựng với trọng tâm là suy luận, lập trình và giải quyết vấn đề. Meta đã sử dụng một số kỹ thuật thông minh trong quá trình huấn luyện để nâng cao các khả năng này, như loại bỏ các gợi ý dễ và sử dụng học tăng cường liên tục với các gợi ý ngày càng khó. Họ cũng giới thiệu MetaP, một kỹ thuật mới cho phép đặt siêu tham số trên một mô hình và áp dụng chúng cho các mô hình khác, tiết kiệm thời gian và tiền bạc. Đây là một bước ngoặt, đặc biệt cho việc huấn luyện những gã khổng lồ như Behemoth, sử dụng 32K GPU và xử lý hơn 30 nghìn tỷ token.
Hiệu suất và So sánh
Vậy, các mô hình này hoạt động thế nào? Zuckerberg đã rõ ràng về tầm nhìn của mình cho AI mã nguồn mở dẫn đầu, và Llama 4 là một bước tiến lớn theo hướng đó. Mặc dù chúng có thể không lập kỷ lục hiệu suất mới trên mọi mặt, nhưng chắc chắn chúng nằm trong top đầu của lớp. Chẳng hạn, Llama 4 Behemoth vượt qua một số đối thủ nặng ký trên một số chuẩn mực, mặc dù vẫn đang đuổi theo DeepSeek R1 và dòng o1 của OpenAI ở một số điểm khác.
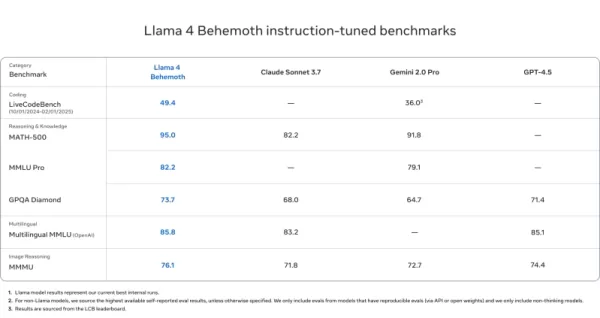
Llama 4 Behemoth
- Vượt qua GPT-4.5, Gemini 2.0 Pro và Claude Sonnet 3.7 trên MATH-500 (95.0), GPQA Diamond (73.7) và MMLU Pro (82.2)
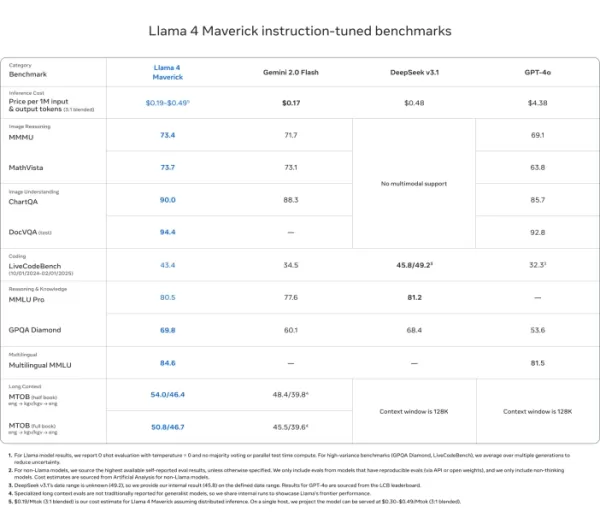
Llama 4 Maverick
- Vượt qua GPT-4o và Gemini 2.0 Flash trên hầu hết các chuẩn mực suy luận đa phương thức như ChartQA, DocVQA, MathVista và MMMU
- Cạnh tranh với DeepSeek v3.1 trong khi sử dụng ít hơn một nửa số tham số hoạt động
- Điểm chuẩn: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
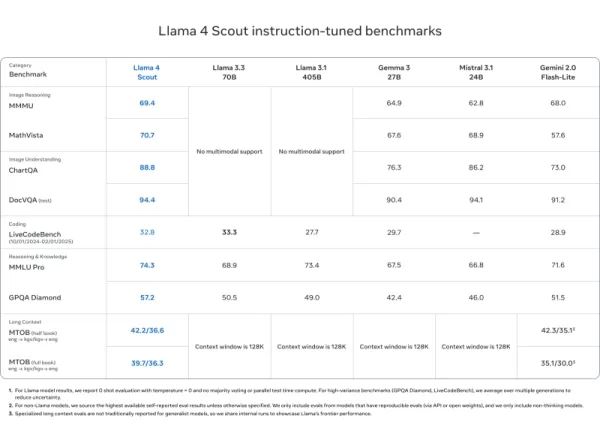
Llama 4 Scout
- So kè hoặc vượt qua các mô hình như Mistral 3.1, Gemini 2.0 Flash-Lite và Gemma 3 trên DocVQA (94.4), MMLU Pro (74.3) và MathVista (70.7)
- Độ dài ngữ cảnh 10 triệu token vô song—lý tưởng cho tài liệu dài và mã nguồn
So sánh với DeepSeek R1
Khi nói đến những đối thủ lớn, Llama 4 Behemoth giữ vững vị trí nhưng chưa thể soán ngôi DeepSeek R1 hay dòng o1 của OpenAI. Nó hơi tụt lại trên MATH-500 và MMLU nhưng dẫn đầu trên GPQA Diamond. Dù vậy, rõ ràng Llama 4 là một đối thủ mạnh trong không gian suy luận.
Chuẩn mực Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
An toàn và Trung lập Chính trị
Meta cũng không quên vấn đề an toàn. Họ đã giới thiệu các công cụ như Llama Guard, Prompt Guard và CyberSecEval để giữ mọi thứ trong tầm kiểm soát. Và họ nhấn mạnh việc giảm thiểu thiên vị chính trị, hướng tới một cách tiếp cận cân bằng hơn, đặc biệt sau khi Zuckerberg bày tỏ sự ủng hộ cho chính trị Cộng hòa sau cuộc bầu cử năm 2024.
Tương Lai với Llama 4
Với Llama 4, Meta đang đẩy nhanh giới hạn của hiệu quả, tính mở và hiệu suất trong AI. Dù bạn muốn xây dựng trợ lý AI cấp doanh nghiệp hay đi sâu vào nghiên cứu AI, Llama 4 cung cấp các tùy chọn mạnh mẽ, linh hoạt, ưu tiên suy luận. Rõ ràng Meta cam kết làm cho AI dễ tiếp cận và có tác động hơn với mọi người.
Bài viết liên quan
 Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Meta Tăng Cường Bảo Mật AI với Công Cụ Llama Nâng Cao
Meta đã phát hành các công cụ bảo mật Llama mới để thúc đẩy phát triển AI và bảo vệ chống lại các mối đe dọa mới nổi.Các công cụ bảo mật mô hình AI Llama nâng cấp này được kết hợp với các tài nguyên m
Nhận xét (25)
0/200
Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Meta Tăng Cường Bảo Mật AI với Công Cụ Llama Nâng Cao
Meta đã phát hành các công cụ bảo mật Llama mới để thúc đẩy phát triển AI và bảo vệ chống lại các mối đe dọa mới nổi.Các công cụ bảo mật mô hình AI Llama nâng cấp này được kết hợp với các tài nguyên m
Nhận xét (25)
0/200
![RogerSanchez]() RogerSanchez
RogerSanchez
 02:53:44 GMT+07:00 Ngày 25 tháng 4 năm 2025
02:53:44 GMT+07:00 Ngày 25 tháng 4 năm 2025
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀


 0
0
![WillieHernández]() WillieHernández
07:21:23 GMT+07:00 Ngày 24 tháng 4 năm 2025
WillieHernández
07:21:23 GMT+07:00 Ngày 24 tháng 4 năm 2025
Llama 4はすごい!長いコンテキストのスカウトやマーベリックモデルは驚異的。2Tパラメータのビーストが出るのを待ちきれない。ただ、設定が少し大変かな。でも、これでAIの未来は明るいね!🚀
0
![GregoryWilson]() GregoryWilson
00:23:39 GMT+07:00 Ngày 23 tháng 4 năm 2025
GregoryWilson
00:23:39 GMT+07:00 Ngày 23 tháng 4 năm 2025
MetaのLlama 4は最高ですね!長いコンテキストをスムーズに処理できるのが本当に便利。マーベリックモデルも面白いけど、2Tパラメータのモデルが来るのが楽しみです!🤩✨
0
![BrianThomas]() BrianThomas
13:27:50 GMT+07:00 Ngày 22 tháng 4 năm 2025
BrianThomas
13:27:50 GMT+07:00 Ngày 22 tháng 4 năm 2025
O Llama 4 da Meta é incrível! A função de contexto longo é uma mão na roda para minhas pesquisas. Os modelos Maverick também são legais, mas estou ansioso pelo modelo de 2T parâmetros. Mal posso esperar para ver o que ele pode fazer! 🤯🚀
0
![JohnGarcia]() JohnGarcia
10:11:00 GMT+07:00 Ngày 22 tháng 4 năm 2025
JohnGarcia
10:11:00 GMT+07:00 Ngày 22 tháng 4 năm 2025
Acabo de enterarme de Llama 4 de Meta y ¡es una locura! ¡2T parámetros! Espero que no sea solo hype, pero si cumple con las expectativas, va a ser increíble. ¿Alguien ya lo ha probado? ¡Quiero saber más! 😎
0
![NicholasLewis]() NicholasLewis
20:31:17 GMT+07:00 Ngày 21 tháng 4 năm 2025
NicholasLewis
20:31:17 GMT+07:00 Ngày 21 tháng 4 năm 2025
Acabei de ouvir sobre o Llama 4 da Meta e parece insano! 2T parâmetros? Isso é um monstro! Mal posso esperar para ver como se compara ao DeepSeek R1. Espero que não seja só hype, mas se corresponder ao burburinho, vai ser 🔥! Alguém já testou?
0
Vào tháng 1 năm 2025, thế giới AI chấn động khi một công ty khởi nghiệp AI Trung Quốc ít được biết đến, DeepSeek, đã thách thức với mô hình suy luận ngôn ngữ mã nguồn mở đột phá của họ, DeepSeek R1. Mô hình này không chỉ vượt qua những gã khổng lồ như Meta mà còn làm điều đó với chi phí chỉ bằng một phần nhỏ—được đồn đại là chỉ vài triệu đô la. Đó là số tiền mà Meta có thể chi chỉ cho một vài lãnh đạo đội AI của họ! Tin tức này đã khiến Meta rơi vào tình trạng rối loạn, đặc biệt khi mô hình Llama mới nhất của họ, phiên bản 3.3, ra mắt chỉ một tháng trước, đã bắt đầu trông có vẻ lỗi thời.
Nhanh chóng tiến đến hôm nay, nhà sáng lập kiêm CEO của Meta, Mark Zuckerberg, đã lên Instagram để công bố ra mắt dòng Llama 4 mới. Dòng này bao gồm Llama 4 Maverick với 400 tỷ tham số và Llama 4 Scout với 109 tỷ tham số, cả hai đều có sẵn để các nhà phát triển tải xuống và bắt đầu thử nghiệm ngay lập tức trên llama.com và Hugging Face. Ngoài ra còn có một cái nhìn sơ lược về một mô hình khổng lồ với 2 nghìn tỷ tham số, Llama 4 Behemoth, vẫn đang trong quá trình huấn luyện, chưa có ngày ra mắt cụ thể.
Khả năng Đa phương thức và Ngữ cảnh Dài
Một trong những đặc điểm nổi bật của các mô hình mới này là tính chất đa phương thức. Chúng không chỉ xử lý văn bản mà còn có thể xử lý video và hình ảnh. Và chúng đi kèm với cửa sổ ngữ cảnh cực kỳ dài—1 triệu token cho Maverick và con số khổng lồ 10 triệu cho Scout. Để dễ hình dung, điều đó tương đương với việc xử lý tới 1.500 và 15.000 trang văn bản trong một lần! Hãy tưởng tượng những khả năng cho các lĩnh vực như y học, khoa học hoặc văn học, nơi cần xử lý và tạo ra lượng thông tin khổng lồ.
Kiến trúc Hỗn hợp Chuyên gia
Cả ba mô hình Llama 4 đều sử dụng kiến trúc "hỗn hợp chuyên gia (MoE)", một kỹ thuật đang tạo sóng gió, được phổ biến bởi các công ty như OpenAI và Mistral. Phương pháp này kết hợp nhiều mô hình nhỏ hơn, chuyên biệt thành một mô hình lớn hơn, hiệu quả hơn. Mỗi mô hình Llama 4 là sự kết hợp của 128 chuyên gia khác nhau, nghĩa là chỉ chuyên gia cần thiết và một chuyên gia chung xử lý mỗi token, giúp các mô hình tiết kiệm chi phí hơn và chạy nhanh hơn. Meta tự hào rằng Llama 4 Maverick có thể chạy trên một máy chủ Nvidia H100 DGX duy nhất, giúp việc triển khai trở nên dễ dàng.
Tiết kiệm Chi phí và Dễ tiếp cận
Meta tập trung vào việc làm cho các mô hình này dễ tiếp cận. Cả Scout và Maverick đều có sẵn để tự lưu trữ, và họ thậm chí đã chia sẻ một số ước tính chi phí hấp dẫn. Chẳng hạn, chi phí suy luận cho Llama 4 Maverick dao động từ 0,19 đến 0,49 đô la mỗi triệu token, một mức giá rất hời so với các mô hình độc quyền khác như GPT-4o. Và nếu bạn muốn sử dụng các mô hình này thông qua nhà cung cấp đám mây, Groq đã bước lên với mức giá cạnh tranh.
Suy luận Nâng cao và MetaP
Các mô hình này được xây dựng với trọng tâm là suy luận, lập trình và giải quyết vấn đề. Meta đã sử dụng một số kỹ thuật thông minh trong quá trình huấn luyện để nâng cao các khả năng này, như loại bỏ các gợi ý dễ và sử dụng học tăng cường liên tục với các gợi ý ngày càng khó. Họ cũng giới thiệu MetaP, một kỹ thuật mới cho phép đặt siêu tham số trên một mô hình và áp dụng chúng cho các mô hình khác, tiết kiệm thời gian và tiền bạc. Đây là một bước ngoặt, đặc biệt cho việc huấn luyện những gã khổng lồ như Behemoth, sử dụng 32K GPU và xử lý hơn 30 nghìn tỷ token.
Hiệu suất và So sánh
Vậy, các mô hình này hoạt động thế nào? Zuckerberg đã rõ ràng về tầm nhìn của mình cho AI mã nguồn mở dẫn đầu, và Llama 4 là một bước tiến lớn theo hướng đó. Mặc dù chúng có thể không lập kỷ lục hiệu suất mới trên mọi mặt, nhưng chắc chắn chúng nằm trong top đầu của lớp. Chẳng hạn, Llama 4 Behemoth vượt qua một số đối thủ nặng ký trên một số chuẩn mực, mặc dù vẫn đang đuổi theo DeepSeek R1 và dòng o1 của OpenAI ở một số điểm khác.
Llama 4 Behemoth
- Vượt qua GPT-4.5, Gemini 2.0 Pro và Claude Sonnet 3.7 trên MATH-500 (95.0), GPQA Diamond (73.7) và MMLU Pro (82.2)
Llama 4 Maverick
- Vượt qua GPT-4o và Gemini 2.0 Flash trên hầu hết các chuẩn mực suy luận đa phương thức như ChartQA, DocVQA, MathVista và MMMU
- Cạnh tranh với DeepSeek v3.1 trong khi sử dụng ít hơn một nửa số tham số hoạt động
- Điểm chuẩn: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
Llama 4 Scout
- So kè hoặc vượt qua các mô hình như Mistral 3.1, Gemini 2.0 Flash-Lite và Gemma 3 trên DocVQA (94.4), MMLU Pro (74.3) và MathVista (70.7)
- Độ dài ngữ cảnh 10 triệu token vô song—lý tưởng cho tài liệu dài và mã nguồn
So sánh với DeepSeek R1
Khi nói đến những đối thủ lớn, Llama 4 Behemoth giữ vững vị trí nhưng chưa thể soán ngôi DeepSeek R1 hay dòng o1 của OpenAI. Nó hơi tụt lại trên MATH-500 và MMLU nhưng dẫn đầu trên GPQA Diamond. Dù vậy, rõ ràng Llama 4 là một đối thủ mạnh trong không gian suy luận.
| Chuẩn mực | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
An toàn và Trung lập Chính trị
Meta cũng không quên vấn đề an toàn. Họ đã giới thiệu các công cụ như Llama Guard, Prompt Guard và CyberSecEval để giữ mọi thứ trong tầm kiểm soát. Và họ nhấn mạnh việc giảm thiểu thiên vị chính trị, hướng tới một cách tiếp cận cân bằng hơn, đặc biệt sau khi Zuckerberg bày tỏ sự ủng hộ cho chính trị Cộng hòa sau cuộc bầu cử năm 2024.
Tương Lai với Llama 4
Với Llama 4, Meta đang đẩy nhanh giới hạn của hiệu quả, tính mở và hiệu suất trong AI. Dù bạn muốn xây dựng trợ lý AI cấp doanh nghiệp hay đi sâu vào nghiên cứu AI, Llama 4 cung cấp các tùy chọn mạnh mẽ, linh hoạt, ưu tiên suy luận. Rõ ràng Meta cam kết làm cho AI dễ tiếp cận và có tác động hơn với mọi người.










 Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
Google Ra Mắt Các Mô Hình AI Gemini 2.5 Sẵn Sàng Sản Xuất để Cạnh Tranh với OpenAI trên Thị Trường Doanh Nghiệp
Google tăng cường chiến lược AI vào thứ Hai, ra mắt các mô hình Gemini 2.5 tiên tiến cho doanh nghiệp và giới thiệu biến thể tiết kiệm chi phí để cạnh tranh về giá và hiệu suất.Công ty thuộc sở hữu củ
 Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Meta Tăng Cường Bảo Mật AI với Công Cụ Llama Nâng Cao
Meta đã phát hành các công cụ bảo mật Llama mới để thúc đẩy phát triển AI và bảo vệ chống lại các mối đe dọa mới nổi.Các công cụ bảo mật mô hình AI Llama nâng cấp này được kết hợp với các tài nguyên m
02:53:44 GMT+07:00 Ngày 25 tháng 4 năm 2025
Meta cung cấp lương cao cho nhân tài AI, phủ nhận tiền thưởng ký hợp đồng 100 triệu USD
Meta đang thu hút các nhà nghiên cứu AI đến phòng thí nghiệm siêu trí tuệ mới của mình với các gói lương thưởng trị giá hàng triệu USD. Tuy nhiên, các tuyên bố về tiền thưởng ký hợp đồng 100 triệu USD
Meta Tăng Cường Bảo Mật AI với Công Cụ Llama Nâng Cao
Meta đã phát hành các công cụ bảo mật Llama mới để thúc đẩy phát triển AI và bảo vệ chống lại các mối đe dọa mới nổi.Các công cụ bảo mật mô hình AI Llama nâng cấp này được kết hợp với các tài nguyên m
02:53:44 GMT+07:00 Ngày 25 tháng 4 năm 2025
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
0
07:21:23 GMT+07:00 Ngày 24 tháng 4 năm 2025
Llama 4はすごい!長いコンテキストのスカウトやマーベリックモデルは驚異的。2Tパラメータのビーストが出るのを待ちきれない。ただ、設定が少し大変かな。でも、これでAIの未来は明るいね!🚀
0
00:23:39 GMT+07:00 Ngày 23 tháng 4 năm 2025
MetaのLlama 4は最高ですね!長いコンテキストをスムーズに処理できるのが本当に便利。マーベリックモデルも面白いけど、2Tパラメータのモデルが来るのが楽しみです!🤩✨
0
13:27:50 GMT+07:00 Ngày 22 tháng 4 năm 2025
O Llama 4 da Meta é incrível! A função de contexto longo é uma mão na roda para minhas pesquisas. Os modelos Maverick também são legais, mas estou ansioso pelo modelo de 2T parâmetros. Mal posso esperar para ver o que ele pode fazer! 🤯🚀
0
10:11:00 GMT+07:00 Ngày 22 tháng 4 năm 2025
Acabo de enterarme de Llama 4 de Meta y ¡es una locura! ¡2T parámetros! Espero que no sea solo hype, pero si cumple con las expectativas, va a ser increíble. ¿Alguien ya lo ha probado? ¡Quiero saber más! 😎
0
20:31:17 GMT+07:00 Ngày 21 tháng 4 năm 2025
Acabei de ouvir sobre o Llama 4 da Meta e parece insano! 2T parâmetros? Isso é um monstro! Mal posso esperar para ver como se compara ao DeepSeek R1. Espero que não seja só hype, mas se corresponder ao burburinho, vai ser 🔥! Alguém já testou?
0













