
















 집
집Meta는 긴 상황에 맞는 스카우트와 매버릭 모델로 Llama 4를 공개합니다.
2025년 1월, AI 업계는 비교적 알려지지 않은 중국 AI 스타트업 DeepSeek이 획기적인 오픈소스 언어 추론 모델 DeepSeek R1을 발표하며 큰 충격을 받았다. 이 모델은 Meta를 비롯한 주요 기업들을 능가했을 뿐만 아니라, 그 비용은 불과 몇 백만 달러에 불과한 것으로 알려졌다. 이는 Meta가 AI 팀 리더 몇 명에게 지출하는 예산에 해당하는 금액이다! 이 소식은 Meta를 약간의 혼란에 빠뜨렸다. 특히 그들의 최신 Llama 모델, 버전 3.3이 한 달 전에 출시되었음에도 불구하고 이미 다소 구식으로 보였기 때문이다.
오늘로 빠르게 넘어와, Meta의 창립자이자 CEO인 Mark Zuckerberg는 Instagram을 통해 새로운 Llama 4 시리즈의 출시를 발표했다. 이 시리즈에는 4000억 파라미터의 Llama 4 Maverick과 1090억 파라미터의 Llama 4 Scout이 포함되며, 개발자들은 즉시 llama.com과 Hugging Face에서 다운로드하여 사용해볼 수 있다. 또한, 아직 훈련 중인 거대한 2조 파라미터 모델 Llama 4 Behemoth의 미리보기도 공개되었으나, 출시 날짜는 아직 정해지지 않았다.
다중 모달 및 장문 맥락 기능
이 새로운 모델들의 두드러진 특징 중 하나는 다중 모달 성격이다. 이들은 단순히 텍스트뿐만 아니라 비디오와 이미지도 처리할 수 있다. 또한, Maverick의 경우 100만 토큰, Scout의 경우 놀라운 1000만 토큰의 매우 긴 맥락 창을 제공한다. 이를 직관적으로 설명하자면, 한 번에 최대 1500페이지와 1만 5000페이지의 텍스트를 처리할 수 있는 셈이다! 의학, 과학, 문학 등 방대한 정보를 처리하고 생성해야 하는 분야에서의 가능성을 상상해보라.
전문가 혼합 아키텍처
세 가지 Llama 4 모델 모두 "전문가 혼합(MoE)" 아키텍처를 채택했으며, 이는 OpenAI와 Mistral 같은 회사들이 대중화시킨 기술이다. 이 접근법은 여러 개의 작고 전문화된 모델을 하나로 결합하여 더 효율적인 대형 모델을 만든다. 각 Llama 4 모델은 128개의 서로 다른 전문가로 구성되며, 이는 각 토큰을 필요한 전문가와 공유된 전문가만 처리하여 모델을 더 비용 효율적이고 빠르게 실행할 수 있게 한다. Meta는 Llama 4 Maverick이 단일 Nvidia H100 DGX 호스트에서 실행될 수 있다고 자랑하며, 배포가 매우 쉬워졌다고 밝혔다.
비용 효율적이고 접근 가능
Meta는 이 모델들을 누구나 쉽게 이용할 수 있도록 하는 데 집중하고 있다. Scout과 Maverick은 자체 호스팅이 가능하며, 심지어 매력적인 비용 추정치도 공유했다. 예를 들어, Llama 4 Maverick의 추론 비용은 백만 토큰당 0.19달러에서 0.49달러 사이로, GPT-4o 같은 독점 모델에 비해 매우 저렴하다. 또한, 클라우드 제공자를 통해 이 모델들을 사용하고 싶다면, Groq가 이미 경쟁력 있는 가격을 제시했다.
향상된 추론 및 MetaP
이 모델들은 추론, 코딩, 문제 해결을 염두에 두고 설계되었다. Meta는 훈련 중 쉬운 프롬프트를 제거하고 점점 더 어려운 프롬프트로 연속적인 강화 학습을 사용하는 등 몇 가지 영리한 기술을 사용해 이러한 능력을 강화했다. 또한, 한 모델에서 하이퍼파라미터를 설정하고 이를 다른 모델에 적용할 수 있는 새로운 기술 MetaP를 도입하여 시간과 비용을 절약했다. 이는 32K GPU를 사용하고 30조 토큰 이상을 처리하는 Behemoth 같은 괴물을 훈련시키는 데 특히 획기적이다.
성능 및 비교
그렇다면 이 모델들의 성능은 어떨까? Zuckerberg는 오픈소스 AI가 선두를 달리는 비전을 분명히 했으며, Llama 4는 그 방향으로 큰 걸음을 내디뎠다. 모든 벤치마크에서 새로운 기록을 세우지는 못했지만, 확실히 상위권에 속한다. 예를 들어, Llama 4 Behemoth는 특정 벤치마크에서 일부 강자들을 능가하지만, DeepSeek R1과 OpenAI의 o1 시리즈에는 일부에서 뒤처진다.
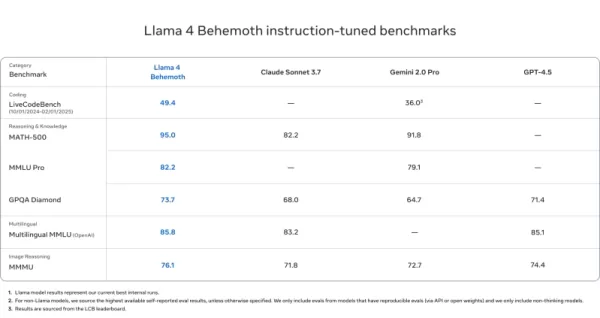
Llama 4 Behemoth
- MATH-500 (95.0), GPQA Diamond (73.7), MMLU Pro (82.2)에서 GPT-4.5, Gemini 2.0 Pro, Claude Sonnet 3.7을 능가
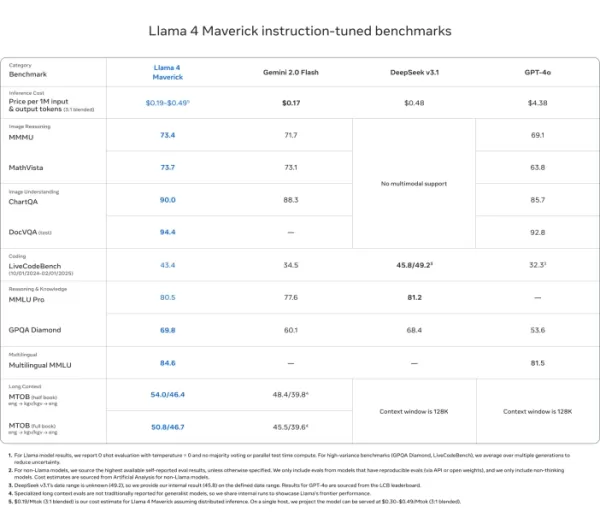
Llama 4 Maverick
- ChartQA, DocVQA, MathVista, MMMU와 같은 대부분의 다중 모달 추론 벤치마크에서 GPT-4o와 Gemini 2.0 Flash를 능가
- 활성 파라미터의 절반 이하를 사용하면서도 DeepSeek v3.1과 경쟁
- 벤치마크 점수: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
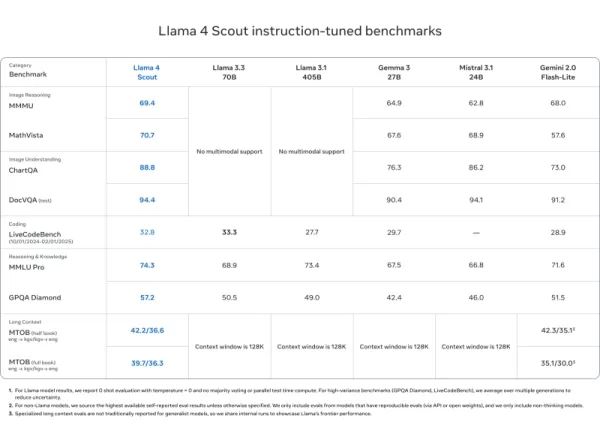
Llama 4 Scout
- DocVQA (94.4), MMLU Pro (74.3), MathVista (70.7)에서 Mistral 3.1, Gemini 2.0 Flash-Lite, Gemma 3 같은 모델들과 동등하거나 능가
- 비교할 수 없는 1000만 토큰 맥락 길이—긴 문서와 코드베이스에 이상적
DeepSeek R1과의 비교
최고 무대에서 Llama 4 Behemoth는 제 몫을 하지만 DeepSeek R1이나 OpenAI의 o1 시리즈를 완전히 제치지는 못한다. MATH-500과 MMLU에서는 약간 뒤처지지만, GPQA Diamond에서는 앞선다. 그래도 Llama 4가 추론 분야에서 강력한 경쟁자임은 분명하다.
벤치마크 Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
안전성 및 정치적 중립성
Meta는 안전성도 잊지 않았다. Llama Guard, Prompt Guard, CyberSecEval 같은 도구를 도입해 올바른 방향으로 유지하고 있다. 또한, 2024년 선거 이후 Zuckerberg의 공화당 정치에 대한 지지 발언 이후 정치적 편향을 줄이고 더 균형 잡힌 접근을 목표로 하고 있다.
Llama 4의 미래
Llama 4로 Meta는 AI의 효율성, 개방성, 성능의 경계를 넓히고 있다. 엔터프라이즈급 AI 어시스턴트를 구축하거나 AI 연구에 깊이 파고들고 싶다면, Llama 4는 추론을 우선시하는 강력하고 유연한 옵션을 제공한다. Meta가 AI를 모두에게 더 접근 가능하고 영향력 있게 만들기 위해 헌신하고 있음은 분명하다.
관련 기사
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
관련 특별 주제 추천
암호
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
관련 특별 주제 추천
암호
 최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
 10 도구
10 도구
 xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

 의견 (30)
0/500
의견 (30)
0/500
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
2025년 1월, AI 업계는 비교적 알려지지 않은 중국 AI 스타트업 DeepSeek이 획기적인 오픈소스 언어 추론 모델 DeepSeek R1을 발표하며 큰 충격을 받았다. 이 모델은 Meta를 비롯한 주요 기업들을 능가했을 뿐만 아니라, 그 비용은 불과 몇 백만 달러에 불과한 것으로 알려졌다. 이는 Meta가 AI 팀 리더 몇 명에게 지출하는 예산에 해당하는 금액이다! 이 소식은 Meta를 약간의 혼란에 빠뜨렸다. 특히 그들의 최신 Llama 모델, 버전 3.3이 한 달 전에 출시되었음에도 불구하고 이미 다소 구식으로 보였기 때문이다.
오늘로 빠르게 넘어와, Meta의 창립자이자 CEO인 Mark Zuckerberg는 Instagram을 통해 새로운 Llama 4 시리즈의 출시를 발표했다. 이 시리즈에는 4000억 파라미터의 Llama 4 Maverick과 1090억 파라미터의 Llama 4 Scout이 포함되며, 개발자들은 즉시 llama.com과 Hugging Face에서 다운로드하여 사용해볼 수 있다. 또한, 아직 훈련 중인 거대한 2조 파라미터 모델 Llama 4 Behemoth의 미리보기도 공개되었으나, 출시 날짜는 아직 정해지지 않았다.
다중 모달 및 장문 맥락 기능
이 새로운 모델들의 두드러진 특징 중 하나는 다중 모달 성격이다. 이들은 단순히 텍스트뿐만 아니라 비디오와 이미지도 처리할 수 있다. 또한, Maverick의 경우 100만 토큰, Scout의 경우 놀라운 1000만 토큰의 매우 긴 맥락 창을 제공한다. 이를 직관적으로 설명하자면, 한 번에 최대 1500페이지와 1만 5000페이지의 텍스트를 처리할 수 있는 셈이다! 의학, 과학, 문학 등 방대한 정보를 처리하고 생성해야 하는 분야에서의 가능성을 상상해보라.
전문가 혼합 아키텍처
세 가지 Llama 4 모델 모두 "전문가 혼합(MoE)" 아키텍처를 채택했으며, 이는 OpenAI와 Mistral 같은 회사들이 대중화시킨 기술이다. 이 접근법은 여러 개의 작고 전문화된 모델을 하나로 결합하여 더 효율적인 대형 모델을 만든다. 각 Llama 4 모델은 128개의 서로 다른 전문가로 구성되며, 이는 각 토큰을 필요한 전문가와 공유된 전문가만 처리하여 모델을 더 비용 효율적이고 빠르게 실행할 수 있게 한다. Meta는 Llama 4 Maverick이 단일 Nvidia H100 DGX 호스트에서 실행될 수 있다고 자랑하며, 배포가 매우 쉬워졌다고 밝혔다.
비용 효율적이고 접근 가능
Meta는 이 모델들을 누구나 쉽게 이용할 수 있도록 하는 데 집중하고 있다. Scout과 Maverick은 자체 호스팅이 가능하며, 심지어 매력적인 비용 추정치도 공유했다. 예를 들어, Llama 4 Maverick의 추론 비용은 백만 토큰당 0.19달러에서 0.49달러 사이로, GPT-4o 같은 독점 모델에 비해 매우 저렴하다. 또한, 클라우드 제공자를 통해 이 모델들을 사용하고 싶다면, Groq가 이미 경쟁력 있는 가격을 제시했다.
향상된 추론 및 MetaP
이 모델들은 추론, 코딩, 문제 해결을 염두에 두고 설계되었다. Meta는 훈련 중 쉬운 프롬프트를 제거하고 점점 더 어려운 프롬프트로 연속적인 강화 학습을 사용하는 등 몇 가지 영리한 기술을 사용해 이러한 능력을 강화했다. 또한, 한 모델에서 하이퍼파라미터를 설정하고 이를 다른 모델에 적용할 수 있는 새로운 기술 MetaP를 도입하여 시간과 비용을 절약했다. 이는 32K GPU를 사용하고 30조 토큰 이상을 처리하는 Behemoth 같은 괴물을 훈련시키는 데 특히 획기적이다.
성능 및 비교
그렇다면 이 모델들의 성능은 어떨까? Zuckerberg는 오픈소스 AI가 선두를 달리는 비전을 분명히 했으며, Llama 4는 그 방향으로 큰 걸음을 내디뎠다. 모든 벤치마크에서 새로운 기록을 세우지는 못했지만, 확실히 상위권에 속한다. 예를 들어, Llama 4 Behemoth는 특정 벤치마크에서 일부 강자들을 능가하지만, DeepSeek R1과 OpenAI의 o1 시리즈에는 일부에서 뒤처진다.
Llama 4 Behemoth
- MATH-500 (95.0), GPQA Diamond (73.7), MMLU Pro (82.2)에서 GPT-4.5, Gemini 2.0 Pro, Claude Sonnet 3.7을 능가
Llama 4 Maverick
- ChartQA, DocVQA, MathVista, MMMU와 같은 대부분의 다중 모달 추론 벤치마크에서 GPT-4o와 Gemini 2.0 Flash를 능가
- 활성 파라미터의 절반 이하를 사용하면서도 DeepSeek v3.1과 경쟁
- 벤치마크 점수: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
Llama 4 Scout
- DocVQA (94.4), MMLU Pro (74.3), MathVista (70.7)에서 Mistral 3.1, Gemini 2.0 Flash-Lite, Gemma 3 같은 모델들과 동등하거나 능가
- 비교할 수 없는 1000만 토큰 맥락 길이—긴 문서와 코드베이스에 이상적
DeepSeek R1과의 비교
최고 무대에서 Llama 4 Behemoth는 제 몫을 하지만 DeepSeek R1이나 OpenAI의 o1 시리즈를 완전히 제치지는 못한다. MATH-500과 MMLU에서는 약간 뒤처지지만, GPQA Diamond에서는 앞선다. 그래도 Llama 4가 추론 분야에서 강력한 경쟁자임은 분명하다.
| 벤치마크 | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
안전성 및 정치적 중립성
Meta는 안전성도 잊지 않았다. Llama Guard, Prompt Guard, CyberSecEval 같은 도구를 도입해 올바른 방향으로 유지하고 있다. 또한, 2024년 선거 이후 Zuckerberg의 공화당 정치에 대한 지지 발언 이후 정치적 편향을 줄이고 더 균형 잡힌 접근을 목표로 하고 있다.
Llama 4의 미래
Llama 4로 Meta는 AI의 효율성, 개방성, 성능의 경계를 넓히고 있다. 엔터프라이즈급 AI 어시스턴트를 구축하거나 AI 연구에 깊이 파고들고 싶다면, Llama 4는 추론을 우선시하는 강력하고 유연한 옵션을 제공한다. Meta가 AI를 모두에게 더 접근 가능하고 영향력 있게 만들기 위해 헌신하고 있음은 분명하다.










 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
메타 AI가 이제 페이스북 마켓플레이스에서 구매자의 메시지에 응답합니다
페이스북 마켓플레이스가 구매자 문의에 대한 자동 응답 기능을 포함한 새로운 메타 AI 기능을 도입한다고 목요일 회사 측이 발표했다. 또한 이 플랫폼은 AI를 활용해 상품 등록을 가속화하고 판매자 프로필을 요약하며, 이제 판매자가 상품 목록에 배송 옵션을 제공할 수 있도록 지원한다.판매자들은 종종 수많은 구매자 문의를 받기 때문에, 페이스북은 메타 AI 기반
 오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













